


Equipment reservation app: prevent conflicts and track returns
Plan an equipment reservation app that prevents double bookings, records returns and damage, and places faulty items on maintenance hold.
Learn the importance of message queues in distributed systems and compare the key features, Advantages, and disadvantages of two popular technologies: RabbitMQ and Apache Kafka.

Distributed systems are built with multiple interconnected components, often spanning across several nodes or servers, to achieve fault tolerance, load balancing, and increased responsiveness. One crucial aspect of ensuring the smooth functioning of distributed systems is the effective management and orchestration of inter-component communication. This is where message queues become essential.
Message queues are communication mechanisms that enable the reliable and asynchronous exchange of messages between different components within a distributed system. These mechanisms maintain consistency, availability, and partition tolerance by ensuring that messages are processed in the right order and can survive failures. They cater to essential requirements of distributed systems, such as:
Various message queuing technologies are available today, each with its strengths and weaknesses. Two of the popular message queuing solutions are RabbitMQ and Apache Kafka. In the following sections, we'll briefly introduce RabbitMQ and Apache Kafka before comparing their features, advantages, and disadvantages.
RabbitMQ is an open-source message-broker software that implements the Advanced Message Queuing Protocol (AMQP). It facilitates scalable, reliable, and high-performing communication between different components and systems.
RabbitMQ is known for its stability, and it's widely used in various industries, such as financial services, e-commerce, and IoT. RabbitMQ's architecture is based on the concept of exchanges and queues. When a message is sent (by a producer), it is forwarded to an exchange, which then routes the message to one or more queues based on predefined routing rules. Consumers, which are components interested in processing those messages, subscribe to queues and consume messages accordingly.
Apache Kafka is a distributed streaming platform designed for high-throughput, fault-tolerant, and scalable messaging and processing of real-time data streams. Kafka is well-suited for handling massive amounts of events, providing low-latency messaging services and acting as a central storage system for logs and events.
Kafka's architecture differs significantly from RabbitMQ's, as it utilizes a distributed log-based architecture. In Kafka, messages are organized in topics, and further divided into partitions. Producers send messages to specific topics, while consumers subscribe to topics to retrieve messages. Each partition acts as an ordered log and ensures that messages are processed in the order they are produced.
In the next sections, we'll dive deeper into comparing RabbitMQ and Apache Kafka by examining their key features, advantages, and disadvantages.
Understanding the key features of RabbitMQ and Apache Kafka will help you decide when choosing the right messaging technology for your distributed system. Let's compare some essential features of both systems.
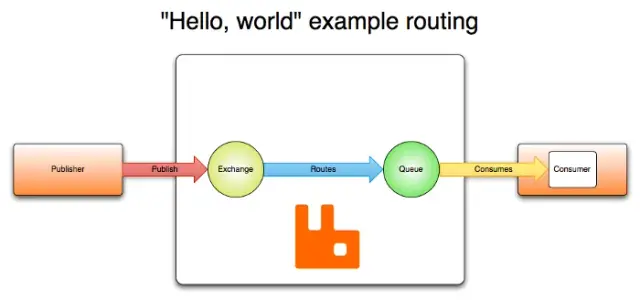
Image source: RabbitMQ
Let's examine the advantages and disadvantages of using RabbitMQ as your message queue system.
Here are some advantages and disadvantages of using Apache Kafka as your messaging system.
Understanding the use cases of RabbitMQ and Apache Kafka is essential for choosing your specific application. Here, we'll explore different use cases where each technology excels.

Integrating RabbitMQ and Apache Kafka with AppMaster.io applications can help optimize communication between distributed systems while using AppMaster's no-code development capabilities. Here's how you can achieve seamless integration with AppMaster:
By integrating RabbitMQ or Apache Kafka with your AppMaster.io applications, you'll be able to take advantage of no-code development features while employing optimal distribution and processing of messages within your distributed systems. This powerful combination can lead to more efficient, cost-effective, and scalable applications.
Message queues are communication mechanisms that enable the exchange of messages between distributed systems. They provide fault tolerance, load balancing, and ensure that messages are processed in the correct order. They are essential in distributed systems because they help maintain consistency, availability, and partition tolerance.
RabbitMQ is an open-source message-broker software that implements the Advanced Message Queuing Protocol (AMQP). It is designed for reliability and offers various features, such as message persistence, acknowledgments, and publisher confirms.
Apache Kafka is a distributed streaming platform that enables high-throughput, fault-tolerant, and scalable messaging and processing of real-time data streams. It uses topics and partitions to route and store messages, and it excels in large-scale data processing and streaming.
RabbitMQ is based on the AMQP protocol and uses exchanges and queues for routing messages. Apache Kafka, on the other hand, utilizes a distributed log-based architecture. It uses topics and partitions to route and store messages.
RabbitMQ offers strong message delivery guarantees, good routing options, and useful management tools. However, it can struggle with horizontal scalability, which might be a limitation for high-throughput applications.
Apache Kafka provides high throughput, low latency, and excellent scalability. It also has built-in support for data stream processing. However, Kafka's configuration and management can be complex, and its advanced features might be overkill for simple use cases.
RabbitMQ is well-suited for applications that require high message reliability, advanced routing options, and rich management features. Examples include financial services, IoT applications, and smaller-scale real-time data processing systems.
Apache Kafka excels in large-scale, high-throughput data processing and streaming applications. Examples include real-time analytics, monitoring systems, and distributed log delivery.
Yes, AppMaster.io allows you to integrate third-party messaging systems, including RabbitMQ and Apache Kafka, into your applications. You can leverage AppMaster-generated code to seamlessly introduce message queues into your projects.
Experiment with AppMaster with free plan.
When you will be ready you can choose the proper subscription.


