Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
Poznaj znaczenie kolejek komunikatów w systemach rozproszonych i porównaj kluczowe funkcje, zalety i wady dwóch popularnych technologii: RabbitMQ i Apache Kafka.

Systemy rozproszone są zbudowane z wielu połączonych ze sobą komponentów, często obejmujących kilka węzłów lub serwerów, w celu osiągnięcia odporności na awarie, równoważenia obciążenia i zwiększonej szybkości reakcji. Jednym z kluczowych aspektów zapewnienia sprawnego funkcjonowania systemów rozproszonych jest efektywne zarządzanie i orkiestracja komunikacji między komponentami. W tym miejscu kolejki komunikatów stają się niezbędne.
Kolejki komunikatów to mechanizmy komunikacyjne, które umożliwiają niezawodną i asynchroniczną wymianę komunikatów pomiędzy różnymi komponentami w ramach systemu rozproszonego. Mechanizmy te utrzymują spójność, dostępność i tolerancję partycji, zapewniając, że wiadomości są przetwarzane we właściwej kolejności i mogą przetrwać awarie. Spełniają one podstawowe wymagania systemów rozproszonych, takie jak
Obecnie dostępne są różne technologie kolejkowania komunikatów, z których każda ma swoje mocne i słabe strony. Dwa z popularnych rozwiązań kolejkowania wiadomości to RabbitMQ i Apache Kafka. W poniższych sekcjach pokrótce przedstawimy RabbitMQ i Apache Kafka, a następnie porównamy ich funkcje, zalety i wady.
RabbitMQ to oprogramowanie typu open source do obsługi wiadomości, które implementuje protokół AMQP (Advanced Message Queuing Protocol). Ułatwia skalowalną, niezawodną i wydajną komunikację między różnymi komponentami i systemami.
RabbitMQ jest znany ze swojej stabilności i jest szeroko stosowany w różnych branżach, takich jak usługi finansowe, handel elektroniczny i IoT. Architektura RabbitMQ opiera się na koncepcji giełd i kolejek. Gdy wiadomość jest wysyłana (przez producenta), jest ona przekazywana do giełdy, która następnie kieruje ją do jednej lub więcej kolejek w oparciu o predefiniowane reguły routingu. Konsumenci, którzy są komponentami zainteresowanymi przetwarzaniem tych wiadomości, subskrybują kolejki i odpowiednio konsumują wiadomości.
Apache Kafka to rozproszona platforma strumieniowa zaprojektowana do wysokowydajnego, odpornego na błędy i skalowalnego przesyłania wiadomości i przetwarzania strumieni danych w czasie rzeczywistym. Kafka doskonale nadaje się do obsługi ogromnych ilości zdarzeń, zapewniając usługi przesyłania wiadomości o niskich opóźnieniach i działając jako centralny system przechowywania dzienników i zdarzeń.
Architektura Kafki znacznie różni się od architektury RabbitMQ, ponieważ wykorzystuje rozproszoną architekturę opartą na dziennikach. W Kafce wiadomości są zorganizowane w tematy, a następnie podzielone na partycje. Producenci wysyłają wiadomości do określonych tematów, podczas gdy konsumenci subskrybują tematy w celu pobierania wiadomości. Każda partycja działa jak uporządkowany dziennik i zapewnia, że wiadomości są przetwarzane w kolejności ich generowania.
W następnych sekcjach zagłębimy się w porównanie RabbitMQ i Apache Kafka, analizując ich kluczowe cechy, zalety i wady.
Zrozumienie kluczowych cech RabbitMQ i Apache Kafka pomoże ci podjąć decyzję przy wyborze odpowiedniej technologii przesyłania wiadomości dla twojego systemu rozproszonego. Porównajmy kilka podstawowych cech obu systemów.
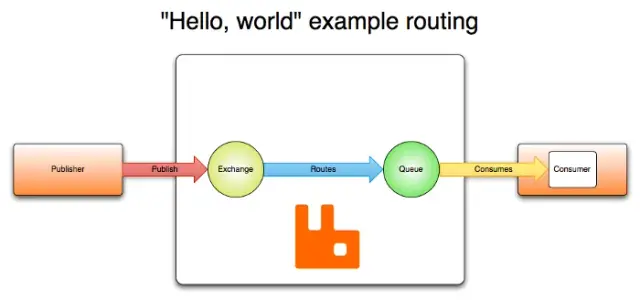
Źródło obrazu: RabbitMQ
Przeanalizujmy zalety i wady korzystania z RabbitMQ jako systemu kolejkowania wiadomości.
Oto kilka zalet i wad korzystania z Apache Kafka jako systemu przesyłania wiadomości.
Zrozumienie przypadków użycia RabbitMQ i Apache Kafka jest niezbędne do wyboru konkretnej aplikacji. Tutaj zbadamy różne przypadki użycia, w których każda technologia się wyróżnia.

Integracja RabbitMQ i Apache Kafka z aplikacjami AppMaster. io może pomóc zoptymalizować komunikację między systemami rozproszonymi przy jednoczesnym wykorzystaniu możliwości programowania bez kodu AppMaster. Oto jak osiągnąć płynną integrację z AppMaster:
Integrując RabbitMQ lub Apache Kafka z aplikacjami AppMaster.io, można korzystać z funkcji programistycznych no-code przy jednoczesnym zastosowaniu optymalnej dystrybucji i przetwarzania wiadomości w systemach rozproszonych. To potężne połączenie może prowadzić do bardziej wydajnych, opłacalnych i skalowalnych aplikacji.
Kolejki komunikatów to mechanizmy komunikacyjne, które umożliwiają wymianę komunikatów między systemami rozproszonymi. Zapewniają one odporność na błędy, równoważenie obciążenia i gwarantują, że wiadomości są przetwarzane we właściwej kolejności. Są one niezbędne w systemach rozproszonych, ponieważ pomagają utrzymać spójność, dostępność i tolerancję partycji.
RabbitMQ to oprogramowanie typu open source do obsługi wiadomości, które implementuje protokół AMQP (Advanced Message Queuing Protocol). Został zaprojektowany z myślą o niezawodności i oferuje różne funkcje, takie jak trwałość wiadomości, potwierdzenia i potwierdzenia wydawców.
Apache Kafka to rozproszona platforma streamingowa, która umożliwia wysokowydajne, odporne na błędy i skalowalne przesyłanie wiadomości i przetwarzanie strumieni danych w czasie rzeczywistym. Wykorzystuje ona tematy i partycje do kierowania i przechowywania wiadomości, a także doskonale sprawdza się w przetwarzaniu i przesyłaniu strumieniowym danych na dużą skalę.
RabbitMQ opiera się na protokole AMQP i wykorzystuje wymiany i kolejki do routingu wiadomości. Z kolei Apache Kafka wykorzystuje rozproszoną architekturę opartą na dziennikach. Używa tematów i partycji do kierowania i przechowywania wiadomości.
RabbitMQ oferuje silne gwarancje dostarczania wiadomości, dobre opcje routingu i przydatne narzędzia do zarządzania. Może jednak zmagać się z poziomą skalowalnością, co może być ograniczeniem dla aplikacji o wysokiej przepustowości.
Apache Kafka zapewnia wysoką przepustowość, niskie opóźnienia i doskonałą skalowalność. Posiada również wbudowaną obsługę przetwarzania strumieni danych. Konfiguracja i zarządzanie Kafką może być jednak skomplikowane, a jej zaawansowane funkcje mogą być zbyt rozbudowane dla prostych przypadków użycia.
RabbitMQ doskonale nadaje się do aplikacji, które wymagają wysokiej niezawodności wiadomości, zaawansowanych opcji routingu i bogatych funkcji zarządzania. Przykłady obejmują usługi finansowe, aplikacje IoT i mniejsze systemy przetwarzania danych w czasie rzeczywistym.
Apache Kafka doskonale sprawdza się w wielkoskalowym przetwarzaniu danych o wysokiej przepustowości i aplikacjach strumieniowych. Przykłady obejmują analitykę w czasie rzeczywistym, systemy monitorowania i rozproszone dostarczanie dzienników.
Tak, AppMaster.io umożliwia integrację systemów przesyłania wiadomości innych firm, w tym RabbitMQ i Apache Kafka, z aplikacjami. Możesz wykorzystać kod wygenerowany przez AppMaster, aby płynnie wprowadzić kolejki komunikatów do swoich projektów.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


