App de reserva de equipamentos: evite conflitos e acompanhe as devoluções
Planeje um app de reserva de equipamentos que evite reservas duplicadas, registre devoluções e danos e coloque itens com problemas em manutenção.
Aprenda a importância das filas de mensagens em sistemas distribuídos e compare os principais recursos, vantagens e desvantagens de duas tecnologias populares: RabbitMQ e Apache Kafka.

Os sistemas distribuídos são construídos com múltiplos componentes interconectados, muitas vezes espalhados por vários nós ou servidores, para obter tolerância a falhas, balanceamento de carga e maior capacidade de resposta. Um aspeto crucial para garantir o bom funcionamento dos sistemas distribuídos é a gestão e a orquestração eficazes da comunicação entre componentes. É aqui que as filas de mensagens se tornam essenciais.
As filas de mensagens são mecanismos de comunicação que permitem a troca fiável e assíncrona de mensagens entre diferentes componentes de um sistema distribuído. Estes mecanismos mantêm a consistência, a disponibilidade e a tolerância à partição, garantindo que as mensagens são processadas pela ordem correcta e podem sobreviver a falhas. Estes mecanismos satisfazem os requisitos essenciais dos sistemas distribuídos, tais como
Atualmente, estão disponíveis várias tecnologias de enfileiramento de mensagens, cada uma com os seus pontos fortes e fracos. Duas das soluções populares de enfileiramento de mensagens são o RabbitMQ e o Apache Kafka. Nas seções a seguir, apresentaremos brevemente o RabbitMQ e o Apache Kafka antes de comparar seus recursos, vantagens e desvantagens.
O RabbitMQ é um software de corretor de mensagens de código aberto que implementa o Protocolo Avançado de Enfileiramento de Mensagens (AMQP). Ele facilita a comunicação escalável, confiável e de alto desempenho entre diferentes componentes e sistemas.
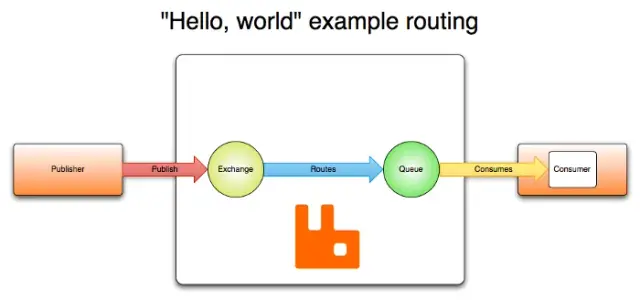
O RabbitMQ é conhecido pela sua estabilidade e é amplamente utilizado em vários sectores, tais como serviços financeiros, comércio eletrónico e IoT. A arquitetura do RabbitMQ é baseada no conceito de trocas e filas. Quando uma mensagem é enviada (por um produtor), ela é encaminhada para uma troca, que então encaminha a mensagem para uma ou mais filas com base em regras de roteamento predefinidas. Os consumidores, que são componentes interessados em processar essas mensagens, subscrevem as filas e consomem as mensagens em conformidade.
O Apache Kafka é uma plataforma de fluxo distribuído concebida para o envio de mensagens de elevado débito, tolerante a falhas e escalável, bem como para o processamento de fluxos de dados em tempo real. O Kafka é adequado para lidar com grandes quantidades de eventos, fornecendo serviços de mensagens de baixa latência e actuando como um sistema de armazenamento central para registos e eventos.
A arquitetura do Kafka difere significativamente da do RabbitMQ, uma vez que utiliza uma arquitetura distribuída baseada em registos. No Kafka, as mensagens são organizadas em tópicos e divididas em partições. Os produtores enviam mensagens para tópicos específicos, enquanto os consumidores se inscrevem em tópicos para recuperar mensagens. Cada partição funciona como um log ordenado e garante que as mensagens sejam processadas na ordem em que são produzidas.
Nas próximas secções, vamos aprofundar a comparação entre o RabbitMQ e o Apache Kafka, examinando as suas principais características, vantagens e desvantagens.
Compreender os principais recursos do RabbitMQ e do Apache Kafka ajudará a decidir ao escolher a tecnologia de mensagens certa para seu sistema distribuído. Vamos comparar alguns recursos essenciais de ambos os sistemas.
Fonte da imagem: RabbitMQ
Vamos examinar as vantagens e desvantagens de usar o RabbitMQ como seu sistema de fila de mensagens.
Aqui estão algumas vantagens e desvantagens de usar o Apache Kafka como seu sistema de mensagens.
Entender os casos de uso do RabbitMQ e do Apache Kafka é essencial para escolher sua aplicação específica. Aqui, exploraremos diferentes casos de uso em que cada tecnologia se destaca.

A integração do RabbitMQ e do Apache Kafka com aplicativos do AppMaster.io pode ajudar a otimizar a comunicação entre sistemas distribuídos enquanto usa os recursos de desenvolvimento sem código do AppMaster. Veja como é possível obter uma integração perfeita com AppMaster:
Ao integrar o RabbitMQ ou o Apache Kafka com seus aplicativos AppMaster.io, você poderá aproveitar os recursos de desenvolvimento do no-code enquanto emprega a distribuição e o processamento ideais de mensagens em seus sistemas distribuídos. Essa poderosa combinação pode levar a aplicativos mais eficientes, econômicos e escalonáveis.
As filas de mensagens são mecanismos de comunicação que permitem a troca de mensagens entre sistemas distribuídos. Proporcionam tolerância a falhas, equilíbrio de carga e garantem que as mensagens são processadas pela ordem correcta. São essenciais em sistemas distribuídos porque ajudam a manter a consistência, a disponibilidade e a tolerância a partições.
O RabbitMQ é um software corretor de mensagens de código aberto que implementa o Protocolo Avançado de Enfileiramento de Mensagens (AMQP). Foi concebido para ser fiável e oferece várias funcionalidades, como a persistência de mensagens, confirmações e confirmações do editor.
O Apache Kafka é uma plataforma de fluxo distribuído que permite o envio de mensagens e o processamento de fluxos de dados em tempo real com elevado débito, tolerância a falhas e escalabilidade. Utiliza tópicos e partições para encaminhar e armazenar mensagens e destaca-se no processamento e transmissão de dados em grande escala.
O RabbitMQ é baseado no protocolo AMQP e usa trocas e filas para rotear mensagens. O Apache Kafka, por outro lado, utiliza uma arquitetura distribuída baseada em registos. Utiliza tópicos e partições para encaminhar e armazenar mensagens.
O RabbitMQ oferece fortes garantias de entrega de mensagens, boas opções de roteamento e ferramentas de gerenciamento úteis. No entanto, ele pode ter dificuldades com a escalabilidade horizontal, o que pode ser uma limitação para aplicações de alto rendimento.
O Apache Kafka oferece alta taxa de transferência, baixa latência e excelente escalabilidade. Ele também tem suporte integrado para processamento de fluxo de dados. No entanto, a configuração e o gerenciamento do Kafka podem ser complexos, e seus recursos avançados podem ser excessivos para casos de uso simples.
O RabbitMQ é adequado para aplicativos que exigem alta confiabilidade de mensagens, opções avançadas de roteamento e recursos avançados de gerenciamento. Os exemplos incluem serviços financeiros, aplicativos IoT e sistemas de processamento de dados em tempo real de menor escala.
O Apache Kafka destaca-se em aplicações de streaming e processamento de dados de grande escala e elevado débito. Os exemplos incluem análises em tempo real, sistemas de monitorização e entrega de registos distribuídos.
Sim, o AppMaster.io permite-lhe integrar sistemas de mensagens de terceiros, incluindo o RabbitMQ e o Apache Kafka, nas suas aplicações. Pode aproveitar o código gerado pelo AppMaster para introduzir filas de mensagens nos seus projectos sem problemas.



Experimente o AppMaster com plano gratuito.
Quando estiver pronto, você poderá escolher a assinatura adequada.


