


Equipment reservation app: prevent conflicts and track returns
Plan an equipment reservation app that prevents double bookings, records returns and damage, and places faulty items on maintenance hold.
Discover the steps to creating a reliable voice-to-text app, exploring the latest speech recognition technologies, tips for UI/UX design, and best practices for scalability and performance.

Voice-to-text apps convert spoken language into written text using advanced speech recognition technology. These apps have revolutionized the way we communicate, providing faster and more convenient methods for communication, transcription services, and even assistance for people with disabilities. Developing a reliable and efficient voice-to-text app involves understanding how speech recognition works, selecting the appropriate platforms and SDKs, and implementing user-friendly UI/UX design principles.
Over the years, voice-to-text technology has become increasingly accurate and sophisticated, spurred by rapid advancements in Artificial Intelligence (AI), Natural Language Processing (NLP), and Deep Learning. These apps can be found across various industries, including medical transcription, customer support, journalism, and education. From virtual assistants like Siri, Google Assistant, and Alexa to transcription services like Otter.ai, voice-to-text apps are integral to the modern digital environment.
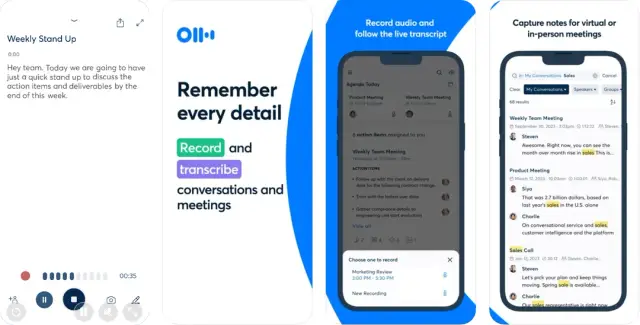
Speech recognition technology is the foundation of voice-to-text apps. It involves various techniques and algorithms that enable computer systems to translate human speech into textual data. The process typically involves the following steps:
When developing a voice-to-text app, one of the critical decisions to make is selecting the right platforms and SDKs (Software Development Kits) for implementing speech recognition features. There are several options available in the market, each with its own benefits and drawbacks. Here are some popular choices to consider:
When choosing a platform or SDK for your voice-to-text app, consider factors such as language support, recognition accuracy, pricing, and integration possibilities. It may also be helpful to evaluate the performance and scalability offered by each option, and whether they align with your app's specific requirements.
Another viable option is to use a no-code platform like AppMaster to develop your voice-to-text app. Depending on the platform's capabilities and integration support for speech recognition SDKs and APIs, you can create and deploy your app with ease while maintaining high levels of functionality and performance. With AppMaster, you can also accelerate the development process by leveraging pre-built components and templates, making it an attractive choice for rapid app development.
Designing an intuitive user interface is a crucial element in developing an effective voice-to-text app. A well-crafted UI not only improves the end-user experience but also facilitates ease of use and optimal app performance. Here are some key elements to consider when designing the user interface for your voice-to-text app:
The UI should be clean, simple, and easy to navigate. Avoid cluttering the interface with unnecessary elements or complex navigation structures. Users should be able to access the core functionality of the app with minimal effort. Ensure that all buttons, functions, and features are clearly labeled and easily accessible.
Incorporate visual feedback for user actions, such as selecting a microphone button to start recording voice input. This helps users understand when the app is actively processing their speech and when they need to make adjustments, like speaking more clearly or slowly. Providing real-time feedback, through progress bars or text, on the processing and transcription status increases user confidence in the app's functionality.
Voice-to-text apps can be particularly beneficial for users with disabilities, such as those with speech or hearing impairments. Ensure that your app is accessible by following best practices for accessibility in-app design, such as using sufficient contrast between text and background, offering adjustable font sizes, and providing alternatives for text content, like image descriptions.
Your voice-to-text app should work seamlessly on a variety of devices, such as smartphones, tablets, and desktops. Design the interface to be responsive and adaptive, ensuring that all elements scale and reorganize appropriately across different screen sizes and resolutions.
Once you have designed an intuitive user interface, the next step is to implement the core functionality of the voice-to-text app. This involves integrating speech recognition technologies and ensuring accurate conversion of speech input into text. Here are some guidelines to follow when implementing this functionality:
Select a speech recognition SDK (Software Development Kit) or API (Application Programming Interface) that best aligns with your app's requirements and platform. Some popular options are Google's Speech-to-Text, Apple's Speech Recognition, IBM Watson's Speech to Text, and Microsoft's Speech-to-Text. These platforms provide powerful speech recognition capabilities and support multiple languages, allowing you to implement accurate voice-to-text functionality in your app.
Ensure your app recognizes various languages and accents by utilizing speech recognition platforms with multilingual support. This will broaden your app's user base and enhance its usability for users with diverse language proficiencies. Additionally, allow users to manually select their preferred language and dialect within the app for improved accuracy.
Incorporate effective error handling mechanisms within your app to handle instances where speech recognition fails or produces incorrect results. Provide users with the option to manually correct inaccuracies and prompt them to repeat speech input if necessary. Additionally, implement proper exception handling to tackle technical issues and maintain app stability during speech recognition processes.
After incorporating the voice-to-text functionality into your app, it's essential to test and fine-tune its performance to ensure accuracy, efficiency, and ease of use. Here are some key aspects to focus on during testing:
Assess the performance of your app's speech recognition capabilities with a wide range of voice samples. Testing should include variation in languages, dialects, accents, speaking styles, and environmental factors, such as background noise levels. This will help identify any potential issues and areas where the voice-to-text functionality could be optimized.
Evaluate your app's performance across various devices and operating systems by monitoring metrics like response time, memory usage, and processing power consumption. Identify any efficiency bottlenecks and optimize your app's performance to ensure a smooth and seamless experience for users regardless of their device or platform.
Conduct user testing with a diverse set of users, drawing on their feedback and experiences to improve your app's functionality, usability, and performance. Address any UI issues, optimize the speech recognition algorithm, and make any necessary adjustments to enhance the overall user experience.
Voice-to-text apps should be iteratively improved and updated based on user feedback, current technologies, and industry best practices. Continuously evaluate your app's performance, making adjustments as needed to keep up with user demands and expectations.
By focusing on designing an intuitive user interface, implementing powerful voice-to-text functionality, and rigorously testing and fine-tuning your app's performance, you can develop a highly effective and user-friendly voice-to-text app that meets the needs of your target audience. Bringing your app to life can be streamlined through the use of powerful no-code platforms like AppMaster, allowing you to focus on perfecting the user experience and functionality.
Developing a voice-to-text app that is both scalable and compatible is crucial for a successful product. To make sure that your app can withstand high workloads and provide an excellent user experience across different platforms and devices, follow these guidelines.
Scalability refers to your app's ability to handle a growing number of users, requests, or data without compromising on performance. Consider the following points when designing your voice-to-text app for scalability:
To make sure that your voice-to-text app is compatible across various devices, operating systems, and platforms, follow these guidelines:
To maximize the quality of your voice-to-text app, adhere to these best practices:
By following these best practices and ensuring scalability and compatibility, you can build a reliable and high-quality voice-to-text app that serves a wide range of users and use-cases.
A voice-to-text app is a software application that converts spoken language into written text using speech recognition technology. These apps can be used for transcription services, messaging, accessibility features, and more.
Speech recognition technology uses techniques like Natural Language Processing (NLP), Deep Learning, and Artificial Intelligence (AI) to convert spoken words into text. SDKs and APIs provided by platforms like Apple, Google, and Microsoft can be used to implement speech recognition features in voice-to-text apps.
Developing a voice-to-text app involves understanding speech recognition technology, selecting appropriate platforms and SDKs, designing an intuitive user interface, implementing voice-to-text functionality, testing and fine-tuning performance, and ensuring scalability and compatibility across different platforms.
Some best practices include focusing on an intuitive user interface, implementing proper error handling, optimizing for different languages and accents, providing a hands-free mode, making the app accessible to users with disabilities, and proactively improving app performance through user feedback and testing.
To ensure scalability, design the app architecture to handle high workloads and efficiently use system resources. For compatibility, use cross-platform frameworks or create separate builds for each platform, and test the app on various devices and operating systems.
Yes, you can use a no-code platform like AppMaster to develop a voice-to-text app. Depending on the platform's capabilities and integrations with speech recognition SDKs and APIs, you can create and deploy the app with ease while maintaining a high level of functionality and performance.
Experiment with AppMaster with free plan.
When you will be ready you can choose the proper subscription.


