App per la prenotazione delle attrezzature: evita i conflitti e monitora le restituzioni
Progetta un'app per la prenotazione delle attrezzature che eviti le doppie prenotazioni, registri restituzioni e danni e metta in manutenzione i beni difettosi.
Scoprite i passaggi per creare un'applicazione voice-to-text affidabile, esplorando le più recenti tecnologie di riconoscimento vocale, i suggerimenti per la progettazione UI/UX e le migliori pratiche per la scalabilità e le prestazioni.

Le app Voice-to-text convertono il linguaggio parlato in testo scritto grazie a una tecnologia avanzata di riconoscimento vocale. Queste applicazioni hanno rivoluzionato il modo di comunicare, fornendo metodi più veloci e convenienti per la comunicazione, servizi di trascrizione e persino assistenza per le persone con disabilità. Lo sviluppo di un'applicazione voice-to-text affidabile ed efficiente implica la comprensione del funzionamento del riconoscimento vocale, la selezione delle piattaforme e degli SDK appropriati e l'implementazione di principi di progettazione UI/UX di facile utilizzo.
Nel corso degli anni, la tecnologia voice-to-text è diventata sempre più precisa e sofisticata, grazie ai rapidi progressi dell' intelligenza artificiale (AI), dell'elaborazione del linguaggio naturale (NLP) e del deep learning. Queste applicazioni si trovano in diversi settori, tra cui la trascrizione medica, l'assistenza clienti, il giornalismo e l'istruzione. Dagli assistenti virtuali come Siri, Google Assistant e Alexa ai servizi di trascrizione come Otter.ai, le app voice-to-text sono parte integrante dell'ambiente digitale moderno.
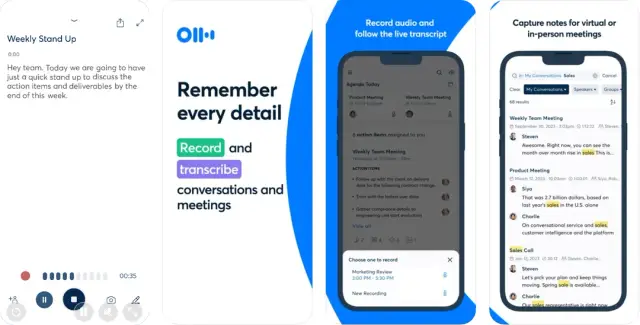
La tecnologia di riconoscimento vocale è alla base delle app voice-to-text. Comprende varie tecniche e algoritmi che consentono ai sistemi informatici di tradurre il parlato umano in dati testuali. Il processo prevede in genere le seguenti fasi:
Quando si sviluppa un'applicazione voice-to-text, una delle decisioni cruciali da prendere è la scelta delle piattaforme e degli SDK (Software Development Kit) giusti per implementare le funzioni di riconoscimento vocale. Esistono diverse opzioni disponibili sul mercato, ognuna con i propri vantaggi e svantaggi. Ecco alcune scelte popolari da considerare:
Quando scegliete una piattaforma o un SDK per la vostra applicazione voice-to-text, considerate fattori quali il supporto linguistico, la precisione del riconoscimento, il prezzo e le possibilità di integrazione. Può anche essere utile valutare le prestazioni e la scalabilità offerte da ciascuna opzione e se sono in linea con i requisiti specifici della vostra applicazione.
Un'altra opzione valida è quella di utilizzare una piattaforma no-code come AppMaster per sviluppare la vostra applicazione voice-to-text. A seconda delle capacità della piattaforma e del supporto all'integrazione di SDK e API per il riconoscimento vocale, è possibile creare e distribuire l'applicazione con facilità, mantenendo alti livelli di funzionalità e prestazioni. Con AppMasterè inoltre possibile accelerare il processo di sviluppo sfruttando componenti e modelli precostituiti, il che la rende una scelta interessante per lo sviluppo rapido di applicazioni.
La progettazione di un' interfaccia utente intuitiva è un elemento cruciale nello sviluppo di un'applicazione voice-to-text efficace. Un'interfaccia utente ben realizzata non solo migliora l'esperienza dell'utente finale, ma facilita anche la facilità d'uso e le prestazioni ottimali dell'app. Ecco alcuni elementi chiave da considerare quando si progetta l'interfaccia utente della vostra app voice-to-text:
L'interfaccia utente deve essere pulita, semplice e facile da navigare. Evitate di ingombrare l'interfaccia con elementi non necessari o strutture di navigazione complesse. Gli utenti devono essere in grado di accedere alle funzionalità principali dell'applicazione con il minimo sforzo. Assicuratevi che tutti i pulsanti, le funzioni e le caratteristiche siano chiaramente etichettati e facilmente accessibili.
Incorporate un feedback visivo per le azioni dell'utente, come ad esempio la selezione del pulsante del microfono per avviare la registrazione di un input vocale. Questo aiuta gli utenti a capire quando l'applicazione sta elaborando attivamente il loro discorso e quando devono apportare modifiche, come parlare più chiaramente o più lentamente. La fornitura di un feedback in tempo reale, tramite barre di avanzamento o testo, sullo stato di elaborazione e trascrizione aumenta la fiducia degli utenti nella funzionalità dell'applicazione.
Le app Voice-to-text possono essere particolarmente utili per gli utenti con disabilità, come quelli con problemi di linguaggio o di udito. Assicuratevi che la vostra app sia accessibile seguendo le migliori pratiche per la progettazione dell'accessibilità nelle app, come l'uso di un contrasto sufficiente tra testo e sfondo, l'offerta di dimensioni dei caratteri regolabili e la fornitura di alternative per i contenuti testuali, come le descrizioni delle immagini.
L'applicazione voice-to-text deve funzionare senza problemi su diversi dispositivi, come smartphone, tablet e desktop. Progettate l'interfaccia in modo che sia reattiva e adattabile, assicurando che tutti gli elementi si scalino e si riorganizzino in modo appropriato su schermi di diverse dimensioni e risoluzioni.
Una volta progettata un'interfaccia utente intuitiva, il passo successivo è l'implementazione della funzionalità principale dell'applicazione voice-to-text. Si tratta di integrare le tecnologie di riconoscimento vocale e di garantire una conversione accurata dell'input vocale in testo. Ecco alcune linee guida da seguire per l'implementazione di questa funzionalità:
Scegliete un SDK (Software Development Kit) o un'API (Application Programming Interface) di riconoscimento vocale che si allinei al meglio con i requisiti e la piattaforma della vostra applicazione. Alcune opzioni popolari sono Speech-to-Text di Google, Speech Recognition di Apple, Speech to Text di IBM Watson e Speech-to-Text di Microsoft. Queste piattaforme offrono potenti capacità di riconoscimento vocale e supportano più lingue, consentendo di implementare nella vostra applicazione un'accurata funzionalità voice-to-text.
Assicuratevi che la vostra app riconosca diverse lingue e accenti utilizzando piattaforme di riconoscimento vocale con supporto multilingue. Questo amplierà la base di utenti della vostra app e ne migliorerà l'usabilità per gli utenti con competenze linguistiche diverse. Inoltre, consentite agli utenti di selezionare manualmente la lingua e il dialetto che preferiscono all'interno dell'app per migliorare la precisione.
Incorporate nella vostra applicazione meccanismi efficaci di gestione degli errori per gestire i casi in cui il riconoscimento vocale fallisce o produce risultati errati. Fornite agli utenti la possibilità di correggere manualmente le imprecisioni e chiedete loro di ripetere l'input vocale, se necessario. Inoltre, implementate una corretta gestione delle eccezioni per affrontare i problemi tecnici e mantenere la stabilità dell'applicazione durante i processi di riconoscimento vocale.
Dopo aver incorporato la funzionalità voice-to-text nella vostra applicazione, è essenziale testare e mettere a punto le prestazioni per garantire precisione, efficienza e facilità d'uso. Ecco alcuni aspetti chiave su cui concentrarsi durante i test:
Valutate le prestazioni delle capacità di riconoscimento vocale della vostra applicazione con un'ampia gamma di campioni vocali. I test dovrebbero includere variazioni di lingue, dialetti, accenti, stili di voce e fattori ambientali, come i livelli di rumore di fondo. Questo aiuterà a identificare eventuali problemi e aree in cui la funzionalità voice-to-text potrebbe essere ottimizzata.
Valutate le prestazioni della vostra applicazione su vari dispositivi e sistemi operativi, monitorando metriche come il tempo di risposta, l'utilizzo della memoria e il consumo di energia di elaborazione. Identificate eventuali colli di bottiglia e ottimizzate le prestazioni dell'app per garantire agli utenti un'esperienza fluida e senza interruzioni, indipendentemente dal dispositivo o dalla piattaforma.
Effettuate test con un gruppo eterogeneo di utenti, attingendo al loro feedback e alle loro esperienze per migliorare la funzionalità, l'usabilità e le prestazioni dell'applicazione. Risolvete eventuali problemi dell'interfaccia utente, ottimizzate l'algoritmo di riconoscimento vocale e apportate tutte le modifiche necessarie per migliorare l'esperienza complessiva dell'utente.
Le applicazioni voice-to-text devono essere migliorate e aggiornate in modo iterativo sulla base del feedback degli utenti, delle tecnologie attuali e delle best practice del settore. Valutate continuamente le prestazioni dell'applicazione, apportando le modifiche necessarie per tenere il passo con le richieste e le aspettative degli utenti.
Concentrandosi sulla progettazione di un'interfaccia utente intuitiva, sull'implementazione di potenti funzionalità voice-to-text e sulla verifica e messa a punto rigorosa delle prestazioni dell'applicazione, è possibile sviluppare un'applicazione voice-to-text altamente efficace e di facile utilizzo, in grado di soddisfare le esigenze del pubblico di riferimento. La realizzazione della vostra applicazione può essere semplificata grazie all'uso di potenti piattaformeno-code come AppMaster, consentendovi di concentrarvi sul perfezionamento dell'esperienza utente e della funzionalità.
Lo sviluppo di un'applicazione voice-to-text che sia scalabile e compatibile è fondamentale per il successo del prodotto. Per essere certi che l'applicazione possa sopportare carichi di lavoro elevati e fornire un'esperienza utente eccellente su piattaforme e dispositivi diversi, seguite le seguenti linee guida.
La scalabilità si riferisce alla capacità dell'applicazione di gestire un numero crescente di utenti, richieste o dati senza compromettere le prestazioni. Quando progettate la vostra applicazione voice-to-text per la scalabilità, tenete conto dei seguenti punti:
Per assicurarvi che la vostra applicazione voice-to-text sia compatibile con diversi dispositivi, sistemi operativi e piattaforme, seguite queste linee guida:
Per massimizzare la qualità della vostra applicazione voice-to-text, attenetevi alle seguenti best practice:
Seguendo queste best practice e garantendo scalabilità e compatibilità, è possibile creare un'applicazione voice-to-text affidabile e di alta qualità, in grado di servire un'ampia gamma di utenti e casi d'uso.
Un'applicazione voice-to-text è un software che converte il linguaggio parlato in testo scritto utilizzando la tecnologia di riconoscimento vocale. Queste applicazioni possono essere utilizzate per servizi di trascrizione, messaggistica, funzioni di accessibilità e altro ancora.
La tecnologia di riconoscimento vocale utilizza tecniche come l'elaborazione del linguaggio naturale (NLP), l'apprendimento profondo e l'intelligenza artificiale (AI) per convertire le parole pronunciate in testo. Le SDK e le API fornite da piattaforme come Apple, Google e Microsoft possono essere utilizzate per implementare le funzioni di riconoscimento vocale nelle app voice-to-text.
Lo sviluppo di un'applicazione voice-to-text implica la comprensione della tecnologia di riconoscimento vocale, la selezione delle piattaforme e degli SDK appropriati, la progettazione di un'interfaccia utente intuitiva, l'implementazione delle funzionalità voice-to-text, la verifica e la messa a punto delle prestazioni e la garanzia di scalabilità e compatibilità tra piattaforme diverse.
Alcune best practice includono l'attenzione a un'interfaccia utente intuitiva, l'implementazione di una corretta gestione degli errori, l'ottimizzazione per lingue e accenti diversi, l'offerta di una modalità vivavoce, l'accessibilità dell'app agli utenti disabili e il miglioramento proattivo delle prestazioni dell'app attraverso il feedback degli utenti e i test.
Per garantire la scalabilità, progettate l'architettura dell'app per gestire carichi di lavoro elevati e utilizzare in modo efficiente le risorse di sistema. Per la compatibilità, utilizzare framework multipiattaforma o creare build separate per ogni piattaforma e testare l'applicazione su diversi dispositivi e sistemi operativi.
Sì, è possibile utilizzare una piattaforma no-code come AppMaster per sviluppare un'applicazione voice-to-text. A seconda delle capacità della piattaforma e delle integrazioni con SDK e API per il riconoscimento vocale, è possibile creare e distribuire l'applicazione con facilità, mantenendo un alto livello di funzionalità e prestazioni.



Sperimenta con AppMaster con un piano gratuito.
Quando sarai pronto potrai scegliere l'abbonamento appropriato.


