Ứng dụng đặt thiết bị: ngăn xung đột và theo dõi việc trả
Lập kế hoạch cho ứng dụng đặt thiết bị giúp ngăn việc đặt trùng, ghi nhận trả và hư hỏng, đồng thời đưa thiết bị lỗi vào trạng thái tạm giữ để bảo trì.
Khám phá các bước để tạo ứng dụng chuyển giọng nói thành văn bản đáng tin cậy, khám phá các công nghệ nhận dạng giọng nói mới nhất, mẹo thiết kế UI/UX và các phương pháp hay nhất để tăng khả năng mở rộng và hiệu suất.

Các ứng dụng chuyển giọng nói thành văn bản chuyển đổi ngôn ngữ nói thành văn bản viết bằng công nghệ nhận dạng giọng nói tiên tiến. Các ứng dụng này đã cách mạng hóa cách chúng ta giao tiếp, cung cấp các phương thức giao tiếp nhanh hơn và thuận tiện hơn, các dịch vụ sao chép và thậm chí hỗ trợ cho người khuyết tật. Việc phát triển ứng dụng chuyển giọng nói thành văn bản đáng tin cậy và hiệu quả bao gồm việc hiểu cách hoạt động của tính năng nhận dạng giọng nói, chọn nền tảng và SDK phù hợp cũng như triển khai các nguyên tắc thiết kế UI/UX thân thiện với người dùng.
Trong những năm qua, công nghệ chuyển giọng nói thành văn bản ngày càng trở nên chính xác và tinh vi, được thúc đẩy bởi những tiến bộ nhanh chóng trong Trí tuệ nhân tạo (AI) , Xử lý ngôn ngữ tự nhiên (NLP) và Học sâu. Bạn có thể tìm thấy các ứng dụng này trong nhiều ngành khác nhau, bao gồm sao chép y tế, hỗ trợ khách hàng, báo chí và giáo dục. Từ các trợ lý ảo như Siri, Google Assistant và Alexa đến các dịch vụ sao chép như Otter.ai, các ứng dụng chuyển giọng nói thành văn bản đều không thể thiếu trong môi trường kỹ thuật số hiện đại.
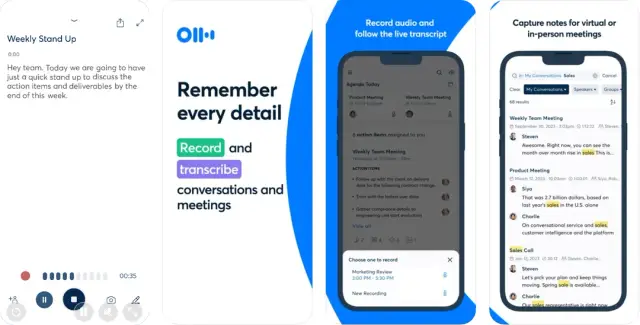
Công nghệ nhận dạng giọng nói là nền tảng của các ứng dụng chuyển giọng nói thành văn bản. Nó liên quan đến các kỹ thuật và thuật toán khác nhau cho phép các hệ thống máy tính dịch lời nói của con người thành dữ liệu văn bản. Quá trình này thường bao gồm các bước sau:
Khi phát triển ứng dụng chuyển giọng nói thành văn bản, một trong những quyết định quan trọng cần đưa ra là chọn đúng nền tảng và SDK (Bộ công cụ phát triển phần mềm) để triển khai các tính năng nhận dạng giọng nói. Có một số tùy chọn có sẵn trên thị trường, mỗi tùy chọn đều có những lợi ích và hạn chế riêng. Dưới đây là một số lựa chọn phổ biến để xem xét:
Khi chọn nền tảng hoặc SDK cho ứng dụng chuyển giọng nói thành văn bản của bạn, hãy xem xét các yếu tố như hỗ trợ ngôn ngữ, độ chính xác của nhận dạng, giá cả và khả năng tích hợp. Cũng có thể hữu ích khi đánh giá hiệu suất và khả năng mở rộng được cung cấp bởi mỗi tùy chọn và liệu chúng có phù hợp với các yêu cầu cụ thể của ứng dụng của bạn hay không.
Một tùy chọn khả thi khác là sử dụng nền tảng không có mã như AppMaster để phát triển ứng dụng chuyển giọng nói thành văn bản của bạn. Tùy thuộc vào khả năng của nền tảng và hỗ trợ tích hợp cho SDK và API nhận dạng giọng nói, bạn có thể tạo và triển khai ứng dụng của mình một cách dễ dàng trong khi vẫn duy trì mức độ cao về chức năng và hiệu suất. Với AppMaster, bạn cũng có thể tăng tốc quá trình phát triển bằng cách tận dụng các thành phần và mẫu dựng sẵn, khiến nó trở thành lựa chọn hấp dẫn để phát triển ứng dụng nhanh chóng.
Thiết kế giao diện người dùng trực quan là một yếu tố quan trọng trong việc phát triển ứng dụng chuyển giọng nói thành văn bản hiệu quả. Giao diện người dùng được thiết kế tốt không chỉ cải thiện trải nghiệm của người dùng cuối mà còn tạo điều kiện dễ sử dụng và hiệu suất ứng dụng tối ưu. Dưới đây là một số yếu tố chính cần xem xét khi thiết kế giao diện người dùng cho ứng dụng chuyển giọng nói thành văn bản của bạn:
Giao diện người dùng phải sạch sẽ, đơn giản và dễ điều hướng. Tránh làm lộn xộn giao diện với các yếu tố không cần thiết hoặc cấu trúc điều hướng phức tạp. Người dùng sẽ có thể truy cập chức năng cốt lõi của ứng dụng với nỗ lực tối thiểu. Đảm bảo rằng tất cả các nút, chức năng và tính năng được dán nhãn rõ ràng và dễ dàng truy cập.
Kết hợp phản hồi trực quan cho hành động của người dùng, chẳng hạn như chọn nút micrô để bắt đầu ghi âm đầu vào bằng giọng nói. Điều này giúp người dùng biết khi nào ứng dụng đang tích cực xử lý lời nói của họ và khi nào họ cần thực hiện các điều chỉnh, chẳng hạn như nói rõ ràng hơn hoặc chậm hơn. Việc cung cấp phản hồi theo thời gian thực, thông qua thanh tiến trình hoặc văn bản, về trạng thái xử lý và sao chép giúp tăng sự tin tưởng của người dùng đối với chức năng của ứng dụng.
Các ứng dụng chuyển giọng nói thành văn bản có thể đặc biệt có lợi cho người dùng khuyết tật, chẳng hạn như những người khiếm thính hoặc khiếm thính. Đảm bảo rằng ứng dụng của bạn có thể truy cập được bằng cách làm theo các phương pháp hay nhất về thiết kế trợ năng trong ứng dụng, chẳng hạn như sử dụng đủ độ tương phản giữa văn bản và nền, cung cấp kích thước phông chữ có thể điều chỉnh và cung cấp các lựa chọn thay thế cho nội dung văn bản, chẳng hạn như mô tả hình ảnh.
Ứng dụng chuyển giọng nói thành văn bản của bạn sẽ hoạt động trơn tru trên nhiều loại thiết bị, chẳng hạn như điện thoại thông minh, máy tính bảng và máy tính để bàn. Thiết kế giao diện để đáp ứng và thích ứng, đảm bảo rằng tất cả các thành phần đều có tỷ lệ và sắp xếp lại phù hợp trên các kích thước và độ phân giải màn hình khác nhau.
Khi bạn đã thiết kế giao diện người dùng trực quan, bước tiếp theo là triển khai chức năng cốt lõi của ứng dụng chuyển giọng nói thành văn bản. Điều này liên quan đến việc tích hợp các công nghệ nhận dạng giọng nói và đảm bảo chuyển đổi chính xác đầu vào giọng nói thành văn bản. Dưới đây là một số nguyên tắc cần tuân theo khi triển khai chức năng này:
Chọn SDK nhận dạng giọng nói (Bộ công cụ phát triển phần mềm) hoặc API (Giao diện lập trình ứng dụng) phù hợp nhất với yêu cầu và nền tảng ứng dụng của bạn. Một số tùy chọn phổ biến là Speech-to-Text của Google, Speech Recognition của Apple, Speech to Text của IBM Watson và Speech-to-Text của Microsoft. Các nền tảng này cung cấp khả năng nhận dạng giọng nói mạnh mẽ và hỗ trợ nhiều ngôn ngữ, cho phép bạn triển khai chức năng chuyển giọng nói thành văn bản chính xác trong ứng dụng của mình.
Đảm bảo ứng dụng của bạn nhận dạng được nhiều ngôn ngữ và giọng khác nhau bằng cách sử dụng các nền tảng nhận dạng giọng nói có hỗ trợ đa ngôn ngữ. Điều này sẽ mở rộng cơ sở người dùng ứng dụng của bạn và nâng cao khả năng sử dụng ứng dụng cho người dùng có trình độ ngôn ngữ đa dạng. Ngoài ra, cho phép người dùng chọn thủ công ngôn ngữ và phương ngữ ưa thích của họ trong ứng dụng để cải thiện độ chính xác.
Kết hợp các cơ chế xử lý lỗi hiệu quả trong ứng dụng của bạn để xử lý các trường hợp nhận dạng giọng nói không thành công hoặc tạo ra kết quả không chính xác. Cung cấp cho người dùng tùy chọn sửa lỗi không chính xác theo cách thủ công và nhắc họ lặp lại cách nhập giọng nói nếu cần. Ngoài ra, hãy triển khai xử lý ngoại lệ thích hợp để giải quyết các sự cố kỹ thuật và duy trì tính ổn định của ứng dụng trong quá trình nhận dạng giọng nói.
Sau khi kết hợp chức năng chuyển giọng nói thành văn bản vào ứng dụng của bạn, điều cần thiết là kiểm tra và tinh chỉnh hiệu suất của nó để đảm bảo độ chính xác, hiệu quả và dễ sử dụng. Dưới đây là một số khía cạnh chính cần tập trung vào trong quá trình thử nghiệm :
Đánh giá hiệu suất khả năng nhận dạng giọng nói của ứng dụng của bạn với nhiều mẫu giọng nói. Thử nghiệm nên bao gồm sự khác biệt về ngôn ngữ, phương ngữ, giọng, phong cách nói và các yếu tố môi trường, chẳng hạn như mức độ tiếng ồn xung quanh. Điều này sẽ giúp xác định bất kỳ sự cố tiềm ẩn nào và các khu vực mà chức năng chuyển giọng nói thành văn bản có thể được tối ưu hóa.
Đánh giá hiệu suất của ứng dụng trên nhiều thiết bị và hệ điều hành khác nhau bằng cách theo dõi các số liệu như thời gian phản hồi, mức sử dụng bộ nhớ và mức tiêu thụ năng lượng xử lý. Xác định bất kỳ tắc nghẽn hiệu quả nào và tối ưu hóa hiệu suất của ứng dụng để đảm bảo trải nghiệm mượt mà và liền mạch cho người dùng bất kể thiết bị hoặc nền tảng của họ.
Tiến hành thử nghiệm người dùng với một nhóm người dùng đa dạng, dựa trên phản hồi và trải nghiệm của họ để cải thiện chức năng, khả năng sử dụng và hiệu suất của ứng dụng. Giải quyết mọi vấn đề về giao diện người dùng, tối ưu hóa thuật toán nhận dạng giọng nói và thực hiện mọi điều chỉnh cần thiết để nâng cao trải nghiệm tổng thể của người dùng.
Các ứng dụng chuyển giọng nói thành văn bản nên được cải tiến và cập nhật lặp đi lặp lại dựa trên phản hồi của người dùng, công nghệ hiện tại và các phương pháp hay nhất trong ngành. Liên tục đánh giá hiệu suất của ứng dụng, thực hiện các điều chỉnh cần thiết để đáp ứng nhu cầu và mong đợi của người dùng.
Bằng cách tập trung vào thiết kế giao diện người dùng trực quan, triển khai chức năng chuyển giọng nói thành văn bản mạnh mẽ, đồng thời kiểm tra nghiêm ngặt và tinh chỉnh hiệu suất của ứng dụng, bạn có thể phát triển ứng dụng chuyển giọng nói thành văn bản hiệu quả cao và thân thiện với người dùng, đáp ứng nhu cầu của khán giả mục tiêu của bạn. Việc đưa ứng dụng của bạn vào cuộc sống có thể được sắp xếp hợp lý thông qua việc sử dụng các nền tảng no-code mạnh mẽ như AppMaster, cho phép bạn tập trung vào việc hoàn thiện chức năng và trải nghiệm người dùng.
Việc phát triển một ứng dụng chuyển giọng nói thành văn bản vừa có khả năng mở rộng vừa tương thích là rất quan trọng để có một sản phẩm thành công. Để đảm bảo rằng ứng dụng của bạn có thể chịu được khối lượng công việc lớn và cung cấp trải nghiệm tuyệt vời cho người dùng trên các nền tảng và thiết bị khác nhau, hãy làm theo các nguyên tắc này.
Khả năng mở rộng đề cập đến khả năng ứng dụng của bạn xử lý số lượng người dùng, yêu cầu hoặc dữ liệu ngày càng tăng mà không ảnh hưởng đến hiệu suất. Hãy xem xét các điểm sau khi thiết kế ứng dụng chuyển giọng nói thành văn bản của bạn để có khả năng mở rộng:
Để đảm bảo rằng ứng dụng chuyển giọng nói thành văn bản của bạn tương thích trên nhiều thiết bị, hệ điều hành và nền tảng khác nhau, hãy làm theo các nguyên tắc sau:
Để tối đa hóa chất lượng của ứng dụng chuyển giọng nói thành văn bản của bạn, hãy tuân thủ các phương pháp hay nhất sau:
Bằng cách làm theo các phương pháp hay nhất này và đảm bảo khả năng mở rộng cũng như khả năng tương thích, bạn có thể xây dựng một ứng dụng chuyển giọng nói thành văn bản chất lượng cao và đáng tin cậy phục vụ nhiều người dùng và nhiều trường hợp sử dụng.
Ứng dụng chuyển giọng nói thành văn bản là một ứng dụng phần mềm chuyển đổi ngôn ngữ nói thành văn bản viết bằng công nghệ nhận dạng giọng nói. Các ứng dụng này có thể được sử dụng cho các dịch vụ sao chép, nhắn tin, tính năng trợ năng, v.v.
Công nghệ nhận dạng giọng nói sử dụng các kỹ thuật như Xử lý ngôn ngữ tự nhiên (NLP), Học sâu và Trí tuệ nhân tạo (AI) để chuyển lời nói thành văn bản. SDK và API do các nền tảng như Apple, Google và Microsoft cung cấp có thể được sử dụng để triển khai các tính năng nhận dạng giọng nói trong ứng dụng chuyển giọng nói thành văn bản.
Phát triển ứng dụng chuyển giọng nói thành văn bản liên quan đến việc hiểu công nghệ nhận dạng giọng nói, chọn nền tảng và SDK phù hợp, thiết kế giao diện người dùng trực quan, triển khai chức năng chuyển giọng nói thành văn bản, thử nghiệm và tinh chỉnh hiệu suất, đồng thời đảm bảo khả năng mở rộng và khả năng tương thích trên các nền tảng khác nhau.
Một số phương pháp hay nhất bao gồm tập trung vào giao diện người dùng trực quan, triển khai xử lý lỗi thích hợp, tối ưu hóa cho các ngôn ngữ và giọng khác nhau, cung cấp chế độ rảnh tay, giúp người dùng khuyết tật có thể truy cập ứng dụng và chủ động cải thiện hiệu suất ứng dụng thông qua phản hồi và thử nghiệm của người dùng.
Để đảm bảo khả năng mở rộng, hãy thiết kế kiến trúc ứng dụng để xử lý khối lượng công việc lớn và sử dụng hiệu quả tài nguyên hệ thống. Để tương thích, hãy sử dụng các khung đa nền tảng hoặc tạo các bản dựng riêng cho từng nền tảng và thử nghiệm ứng dụng trên nhiều thiết bị và hệ điều hành khác nhau.
Có, bạn có thể sử dụng nền tảng không cần mã như AppMaster để phát triển ứng dụng chuyển giọng nói thành văn bản. Tùy thuộc vào khả năng của nền tảng và khả năng tích hợp với SDK và API nhận dạng giọng nói, bạn có thể tạo và triển khai ứng dụng một cách dễ dàng trong khi vẫn duy trì mức độ cao về chức năng và hiệu suất.



Thử nghiệm với AppMaster với gói miễn phí.
Khi bạn sẵn sàng, bạn có thể chọn đăng ký phù hợp.


