
Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
Ta dogłębna analiza modeli danych w DBMS pomoże Ci zrozumieć znaczenie tych struktur w systemach zarządzania bazami danych, ich typy, zastosowania i kluczowe zasady.

Model danych to strukturalna reprezentacja elementów danych, ich relacji i ograniczeń w systemie zarządzania bazami danych (DBMS) . Służy jako plan projektowania i wdrażania systemów baz danych, umożliwiając programistom i administratorom baz danych efektywne organizowanie, przechowywanie i zarządzanie danymi.
Modele danych usprawniają podejmowanie decyzji i komunikację pomiędzy członkami zespołu, służąc jako narzędzie wizualne i koncepcyjne podczas programowania. U podstaw modelu danych leży zdefiniowanie struktury danych, w tym jej organizacji i relacji. Ponadto umożliwia kategoryzację i reprezentację wymagań przechowywanych danych oraz utrzymanie integralności danych, umożliwiając bardziej efektywną i spójną manipulację danymi i ich wyszukiwanie.
Modele danych odgrywają kluczową rolę w systemach zarządzania bazami danych, ponieważ:
Na przestrzeni lat opracowano kilka typów modeli danych. Każdy typ ma swój własny zestaw zalet i wad, a ich przydatność zależy od konkretnego przypadku użycia. Główne typy modeli danych to:
Zrozumienie funkcji i ograniczeń każdego modelu danych jest niezbędne do wybrania najbardziej odpowiedniego modelu dla konkretnego systemu bazy danych. Przyjrzyjmy się bliżej każdemu z tych typów.
Hierarchiczny model danych jest jednym z najwcześniejszych modeli baz danych, opracowanym w latach sześćdziesiątych XX wieku. Reprezentuje dane przy użyciu struktur przypominających drzewo, przy czym każdy węzeł zawiera jeden węzeł nadrzędny i wiele węzłów podrzędnych. Model ten dobrze nadaje się do relacji jeden do wielu (1:N), gdzie jednostka nadrzędna jest powiązana z wieloma jednostkami podrzędnymi.
Model hierarchiczny charakteryzuje się prostotą i łatwością wdrożenia. Mimo to stwarza pewne ograniczenia w przypadku złożonych relacji i nadmiarowości danych. Przyjrzyjmy się bliżej kluczowym cechom, zaletom i wadom modelu hierarchicznego.
Model danych sieciowych powstał pod koniec lat 60. XX wieku jako ewolucja modelu hierarchicznego. Rozszerza model hierarchiczny, umożliwiając węzłowi posiadanie wielu węzłów nadrzędnych i podrzędnych. Ta elastyczność umożliwia modelowi danych sieciowych reprezentowanie relacji wiele do wielu (M:N), dzięki czemu nadaje się do bardziej złożonych struktur danych.
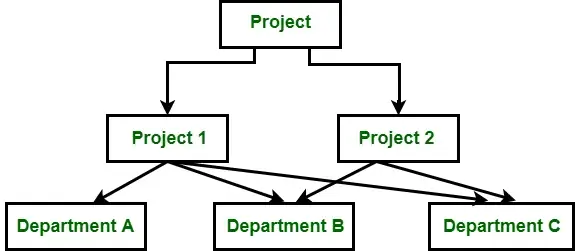
Źródło obrazu: GeeksforGeeks
Zwiększone możliwości modelowania i elastyczność wiążą się z pewnymi kosztami w postaci złożoności i wydajności. Niemniej jednak model sieci ma swoje zalety i nadal jest używany w określonych zastosowaniach. Przyjrzyjmy się bliżej cechom, zaletom i wadom modelu sieciowego.
Relacyjny model danych został wprowadzony przez dr Edgara F. Codda w 1970 roku jako sposób na uproszczenie reprezentacji relacji między danymi. Model relacyjny przedstawia dane jako relacje, które zasadniczo są tabelami z wierszami i kolumnami. Każdy wiersz, zwany także krotką, reprezentuje pojedynczy rekord danych, natomiast każda kolumna odpowiada atrybutowi typu danych.
Model relacyjny pozwala na łatwą manipulację danymi i jest szeroko stosowany ze względu na swoją intuicyjność, elastyczność i obsługę strukturalnego języka zapytań (SQL) . Wśród licznych zalet modelu relacyjnego nacisk położony jest na integralność danych oraz łatwość odpytywania i modyfikowania danych przy użyciu języka SQL. Przyjrzyjmy się bliżej cechom, zaletom i wadom modelu relacyjnego.
Każdy z hierarchicznych, sieciowych i relacyjnych modeli danych ma unikalne cechy, zalety i ograniczenia. Wybór modelu danych zależy od konkretnych wymagań, złożoności i relacji zarządzanych danych.
Model relacji między jednostkami (model ER) to koncepcyjny model danych, który reprezentuje dane jako jednostki i ich relacje. Podstawowym celem modelu ER jest zapewnienie jasnej, prostej i graficznej reprezentacji wymagań organizacji dotyczących danych poprzez identyfikację jej komponentów, takich jak encje, atrybuty i relacje.
W modelu ER jednostka to obiekt lub koncepcja ze świata rzeczywistego, którą chcesz reprezentować w bazie danych, na przykład osoba, przedmiot lub wydarzenie. Każda jednostka ma zestaw atrybutów opisujących jej cechy lub właściwości. Na przykład w jednostce klienta atrybuty mogą obejmować imię i nazwisko, adres, numer telefonu itp. Relacja w modelu ER to powiązanie między dwiema lub większą liczbą jednostek. W modelu ER istnieją trzy typy relacji: jeden do jednego, jeden do wielu i wiele do wielu. Prawidłowe modelowanie relacji jest niezbędne, aby zapewnić integralność danych i efektywne wykorzystanie bazy danych.
Diagram relacji encji (ERD) to popularny sposób wizualizacji komponentów i ich relacji w modelu ER. ERD to graficzna reprezentacja wykorzystująca symbole do oznaczenia jednostek, atrybutów i relacji. Diagram ten pomaga projektantom baz danych szybko zrozumieć wymagania organizacji dotyczące danych i przełożyć je na odpowiedni projekt fizycznej bazy danych.
Obiektowy model danych to nowsze osiągnięcie w zakresie modelowania danych, które łączy koncepcje baz danych i programowania. W tym modelu dane są reprezentowane jako obiekty, a relacje są ustanawiane za pomocą technik programowania obiektowego (OOP), takich jak dziedziczenie, enkapsulacja i polimorfizm.
W obiektowym modelu danych obiekt jest instancją klasy , a klasa jest planem definiującym strukturę i zachowanie obiektów. Każdy obiekt hermetyzuje swój stan poprzez atrybuty , a swoje zachowanie poprzez metody . Jedną z najważniejszych zalet obiektowego modelu danych jest obsługa dziedziczenia . Dziedziczenie pozwala klasie dziedziczyć właściwości i metody z klasy nadrzędnej, promując ponowne wykorzystanie kodu i modułowość.
Obiektowy model danych obsługuje również enkapsulację , która ukrywa przed użytkownikami wewnętrzne szczegóły implementacji klasy. Ta funkcja jest kluczowa dla utrzymania integralności danych i zapewnienia kontrolowanego interfejsu do funkcjonalności klasy. Inną koncepcją OOP obsługiwaną przez obiektowy model danych jest polimorfizm . Polimorfizm umożliwia traktowanie obiektów z różnych klas jak obiektów ze wspólnej nadklasy, co ułatwia elastyczność i rozszerzalność systemu bazy danych. Chociaż obiektowy model danych oferuje wiele korzyści, wymaga głębszego zrozumienia koncepcji programowania obiektowego i może wymagać bardziej złożonych narzędzi programowych do projektowania i wdrażania.
Podczas pracy z dowolnym modelem danych ważne jest przestrzeganie pewnych zasad, aby utworzyć skuteczny, znaczący i łatwy w utrzymaniu model. Oto kilka kluczowych zasad modelowania danych:
Przestrzeganie tych zasad podczas procesu modelowania danych może znacznie poprawić jakość ostatecznego modelu, czyniąc go bardziej wydajnym, łatwiejszym w zarządzaniu i utrzymaniu. Oprócz przestrzegania tych zasad wykorzystanie potężnych narzędzi, takich jak platforma AppMaster , może znacznie uprościć i usprawnić proces modelowania danych.
Dzięki narzędziu do wizualnego modelowania danych i intuicyjnemu rozwiązaniu no-code użytkownicy mogą bez wysiłku projektować schemat bazy danych, tworzyć logikę biznesową i tworzyć aplikacje internetowe, mobilne i backendowe, które odpowiadają ich unikalnym potrzebom. Dzięki odpowiednim podstawom i narzędziom możesz tworzyć skuteczne, skalowalne i łatwe w utrzymaniu modele danych, które spełniają wymagania Twojej organizacji.
Projektowanie skutecznych i łatwych w utrzymaniu modeli danych ma kluczowe znaczenie dla tworzenia wydajnych, skalowalnych rozwiązań programowych. Platforma AppMaster oferuje potężne rozwiązanie niewymagające kodu do konstruowania modeli danych i projektowania aplikacji backendowych, internetowych i mobilnych.
Dzięki narzędziu do tworzenia wizualnego modelu danych oferowanemu przez AppMaster użytkownicy mogą z łatwością projektować schemat bazy danych, określać relacje i ograniczenia oraz tworzyć logikę biznesową umożliwiającą interakcję z danymi. Intuicyjny interfejs użytkownika pozwala na szybkie i wydajne tworzenie modelu danych, bez konieczności posiadania doświadczenia w programowaniu.
Wizualny projektant schematów bazy danych oferowany przez AppMaster umożliwia użytkownikom projektowanie schematu bazy danych poprzez definiowanie tabel, ustawianie relacji i określanie ograniczeń. Ten interfejs graficzny upraszcza proces modelowania danych, umożliwiając użytkownikom wizualne organizowanie jednostek i ich relacji, zamiast pisać złożone skrypty SQL. Użytkownicy mogą definiować klucze podstawowe, klucze obce i indeksy za pomocą przyjaznego dla użytkownika interfejsu i mogą łatwo łączyć tabele za pomocą operacji „przeciągnij i upuść” .
Oprócz projektanta schematów wizualnych, AppMaster udostępnia potężne narzędzie do projektowania procesów biznesowych (BP), które umożliwia użytkownikom tworzenie logiki biznesowej aplikacji i zarządzanie nią. BP Designer umożliwia użytkownikom konstruowanie logiki po stronie serwera dla aplikacji zaplecza, podczas gdy aplikacje internetowe i mobilne korzystają z projektantów Web BP i Mobile BP do tworzenia logiki biznesowej dla poszczególnych komponentów.
Korzystanie z BP Designer jest proste dzięki funkcjonalności platformy drag-and-drop. Użytkownicy mogą szybko budować złożone procesy biznesowe, łącząc różne komponenty, takie jak akcje, warunki i pętle. Platforma obsługuje także zarządzanie endpoints REST API i WSS, pomagając użytkownikom bezproblemowo udostępniać swoje modele danych innym systemom.
Po sfinalizowaniu modeli danych i procesów biznesowych użytkownicy mogą polegać na AppMaster w celu automatycznego generowania w pełni funkcjonalnych aplikacji. Upraszcza to proces tworzenia oprogramowania i eliminuje dług techniczny, odtwarzając aplikacje od zera za każdym razem, gdy wprowadzane są zmiany w planie. W rezultacie firmy mogą czerpać korzyści z szybszych cykli rozwoju, niższych kosztów i większej elastyczności.
AppMaster obsługuje wiele języków i frameworków, dzięki czemu wygenerowane aplikacje płynnie współpracują z różnymi technologiami. Aplikacje backendowe generowane są przy użyciu Go (Golang), aplikacje webowe wykorzystują framework Vue3 i JS/TS, natomiast aplikacje mobilne budowane są w oparciu o Kotlin i Jetpack Compose dla Androida oraz SwiftUI dla iOS. Co więcej, wygenerowane aplikacje są kompatybilne z bazami danych kompatybilnymi z Postgresql jako podstawową bazą danych.
Modele danych są niezbędne w opracowywaniu i zarządzaniu wydajnymi i łatwymi w utrzymaniu systemami zarządzania bazami danych. Zrozumienie różnych typów modeli danych, ich zastosowań i kluczowych zasad pomaga programistom i architektom podejmować świadome decyzje podczas projektowania i wdrażania systemów baz danych.
Dzięki potężnemu rozwiązaniu no-code platforma AppMaster umożliwia użytkownikom tworzenie kompleksowych modeli danych i aplikacji. Wizualny projektant schematów baz danych, projektant procesów biznesowych i funkcje automatycznego generowania aplikacji oferowane przez AppMaster sprawiają, że tworzenie niezawodnych i łatwych w utrzymaniu rozwiązań bazodanowych jest szybsze i bardziej dostępne.
W miarę ewolucji branży technologicznej narzędzia takie jak platforma AppMaster, która no-code stają się coraz bardziej cenne przy opracowywaniu skalowalnych i wydajnych modeli danych oraz bazujących na nich rozwiązań programowych.
Model danych to strukturalna reprezentacja elementów danych, ich relacji i ograniczeń w systemie zarządzania bazami danych (DBMS). Pomaga w organizowaniu, przechowywaniu i zarządzaniu dużymi ilościami danych.
Modele danych odgrywają kluczową rolę w systemie DBMS, ponieważ zapewniają ramy strukturalne do projektowania baz danych, ustalania spójności danych i umożliwiania wydajnego przechowywania danych, wyszukiwania i zarządzania.
Główne typy modeli danych to modele hierarchiczne, sieciowe, relacyjne, encja-relacja (ER) i modele obiektowe.
Hierarchiczny model danych reprezentuje dane w strukturze przypominającej drzewo, gdzie każdy węzeł ma jednego rodzica i wiele dzieci. Był to pierwszy model danych zastosowany w systemie DBMS i najlepiej nadaje się do relacji jeden do wielu.
Sieciowy model danych to elastyczny model danych, który umożliwia wiele relacji między jednostkami. Każdy węzeł w modelu sieci może mieć wiele węzłów nadrzędnych i podrzędnych, co czyni go idealnym rozwiązaniem dla relacji wiele do wielu.
Relacyjny model danych to model bazy danych oparty na koncepcji relacji reprezentowanych w postaci tabel. Umożliwia łatwą manipulację i wyszukiwanie danych przy użyciu języka SQL i jest najczęściej używanym modelem danych.
Model relacji między jednostkami (model ER) to koncepcyjny model danych reprezentujący jednostki i ich relacje. Jest powszechnie stosowany w projektowaniu baz danych i jest wizualnie przedstawiany za pomocą diagramu ER.
Obiektowy model danych integruje koncepcje bazy danych i programowania, reprezentując dane jako obiekty z atrybutami i metodami. Obsługuje dziedziczenie, enkapsulację i polimorfizm.
Zasady modelowania danych obejmują przejrzystość, prostotę, skalowalność, spójność i elastyczność. Zasady te pomagają tworzyć efektywne i łatwe w utrzymaniu modele danych.
Platforma AppMaster oferuje narzędzie do tworzenia wizualnych modeli danych w ramach rozwiązania no-code do tworzenia aplikacji backendowych, internetowych i mobilnych. Użytkownicy mogą łatwo projektować schemat bazy danych, logikę biznesową i nie tylko, korzystając z intuicyjnego interfejsu platformy.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


