
Gerätereservierungs-App: Konflikte verhindern und Rückgaben verfolgen
Plane eine Gerätereservierungs-App, die Doppelbuchungen verhindert, Rückgaben und Schäden dokumentiert und fehlerhafte Geräte für die Wartung sperrt.
Diese eingehende Analyse von Datenmodellen in DBMS wird Ihnen helfen, die Bedeutung dieser Strukturen in Datenbankverwaltungssystemen, ihre Typen, Verwendungszwecke und Schlüsselprinzipien zu verstehen.

Ein Datenmodell ist eine strukturelle Darstellung der Datenelemente, ihrer Beziehungen und Einschränkungen innerhalb eines Datenbankverwaltungssystems (DBMS) . Es dient als Blaupause für den Entwurf und die Implementierung von Datenbanksystemen und ermöglicht Softwareentwicklern und Datenbankadministratoren die effiziente Organisation, Speicherung und Verwaltung von Daten.
Datenmodelle optimieren die Entscheidungsfindung und Kommunikation zwischen Teammitgliedern und dienen als visuelles und konzeptionelles Werkzeug während der Entwicklung. Im Kern versucht ein Datenmodell, die Datenstruktur einschließlich ihrer Organisation und Beziehungen zu definieren. Darüber hinaus bietet es die Möglichkeit, die Anforderungen der gespeicherten Daten zu kategorisieren und darzustellen und die Datenintegrität aufrechtzuerhalten, was eine effektivere und konsistentere Datenbearbeitung und -abfrage ermöglicht.
Datenmodelle spielen in Datenbankverwaltungssystemen eine entscheidende Rolle, da sie:
Im Laufe der Jahre wurden verschiedene Arten von Datenmodellen entwickelt. Jeder Typ hat seine eigenen Vor- und Nachteile und ihre Eignung hängt vom jeweiligen Anwendungsfall ab. Die wichtigsten Arten von Datenmodellen sind:
Um das am besten geeignete Modell für ein bestimmtes Datenbanksystem auszuwählen, ist es wichtig, die Funktionen und Einschränkungen jedes Datenmodells zu verstehen. Schauen wir uns jeden dieser Typen genauer an.
Das Hierarchiedatenmodell ist eines der frühesten Datenbankmodelle und wurde in den 1960er Jahren entwickelt. Es stellt Daten mithilfe baumartiger Strukturen dar, wobei jeder Knoten einen übergeordneten und mehrere untergeordnete Knoten enthält. Dieses Modell eignet sich gut für Eins-zu-viele-Beziehungen (1:N), bei denen eine übergeordnete Entität mit mehreren untergeordneten Entitäten verknüpft ist.
Seine Einfachheit und einfache Implementierung zeichnen das hierarchische Modell aus. Dennoch weist es einige Einschränkungen beim Umgang mit komplexen Beziehungen und Datenredundanzen auf. Schauen wir uns die wichtigsten Merkmale, Vor- und Nachteile des hierarchischen Modells genauer an.
Das Netzwerkdatenmodell wurde Ende der 1960er Jahre als Weiterentwicklung des hierarchischen Modells entwickelt. Es erweitert das hierarchische Modell, indem es einem Knoten ermöglicht, mehrere übergeordnete und untergeordnete Knoten zu haben. Diese Flexibilität ermöglicht es dem Netzwerkdatenmodell, Viele-zu-Viele-Beziehungen (M:N) darzustellen, wodurch es für komplexere Datenstrukturen geeignet ist.
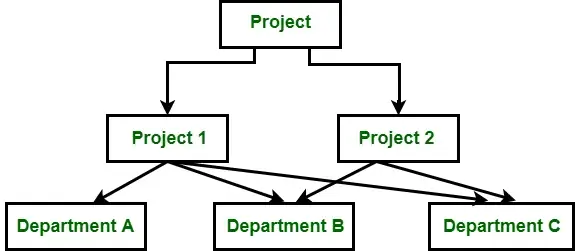
Bildquelle: GeeksforGeeks
Die erhöhte Modellierungsfähigkeit und Flexibilität gehen mit einem gewissen Aufwand an Komplexität und Leistung einher. Dennoch hat das Netzwerkmodell seine Vorzüge und wird immer noch in bestimmten Anwendungen eingesetzt. Schauen wir uns die Merkmale, Vor- und Nachteile des Netzwerkmodells genauer an.
Das relationale Datenmodell wurde 1970 von Dr. Edgar F. Codd eingeführt, um die Darstellung von Datenbeziehungen zu vereinfachen. Das relationale Modell stellt Daten als Beziehungen dar, bei denen es sich im Wesentlichen um Tabellen mit Zeilen und Spalten handelt. Jede Zeile, auch Tupel genannt, stellt einen einzelnen Datensatz dar, während jede Spalte einem Attribut des Datentyps entspricht.
Das relationale Modell ermöglicht eine einfache Datenbearbeitung und wird aufgrund seiner intuitiven Natur, Flexibilität und Unterstützung für strukturierte Abfragesprache (SQL) häufig verwendet. Zu den zahlreichen Vorteilen des relationalen Modells zählen die Datenintegrität und die einfache Abfrage und Änderung von Daten mithilfe von SQL. Lassen Sie uns die Merkmale, Vor- und Nachteile des relationalen Modells genauer untersuchen.
Die hierarchischen, Netzwerk- und relationalen Datenmodelle weisen jeweils einzigartige Merkmale, Vorteile und Einschränkungen auf. Die Wahl des Datenmodells hängt von den spezifischen Anforderungen, der Komplexität und den Beziehungen der verwalteten Daten ab.
Das Entity-Relationship-Modell (ER-Modell) ist ein konzeptionelles Datenmodell, das Daten als Entitäten und ihre Beziehungen darstellt. Das Hauptziel des ER-Modells besteht darin, eine klare, unkomplizierte und grafische Darstellung der Datenanforderungen der Organisation bereitzustellen, indem ihre Komponenten wie Entitäten, Attribute und Beziehungen identifiziert werden.
Im ER-Modell ist eine Entität ein reales Objekt oder Konzept, das Sie in der Datenbank darstellen möchten, z. B. eine Person, ein Element oder ein Ereignis. Jede Entität verfügt über eine Reihe von Attributen , die ihre Merkmale oder Eigenschaften beschreiben. In einer Kundenentität können die Attribute beispielsweise Name, Adresse, Telefonnummer usw. umfassen. Die Beziehung im ER-Modell ist die Verbindung zwischen zwei oder mehr Entitäten. Im ER-Modell gibt es drei Arten von Beziehungen: Eins-zu-Eins, Eins-zu-Viele und Viele-zu-Viele. Es ist wichtig, Beziehungen richtig zu modellieren, um Datenintegrität und effiziente Datenbanknutzung sicherzustellen.
Ein Entity-Relationship-Diagramm (ERD) ist eine beliebte Methode zur Visualisierung der Komponenten und ihrer Beziehungen im ER-Modell. Ein ERD ist eine grafische Darstellung, die Symbole zur Bezeichnung von Entitäten, Attributen und Beziehungen verwendet. Dieses Diagramm hilft Datenbankdesignern, die Datenanforderungen der Organisation schnell zu verstehen und sie in ein geeignetes physisches Datenbankdesign umzusetzen.
Das objektorientierte Datenmodell ist eine neuere Weiterentwicklung der Datenmodellierung, die Datenbank- und Programmierkonzepte kombiniert. In diesem Modell werden Daten als Objekte dargestellt und Beziehungen werden durch Techniken der objektorientierten Programmierung (OOP) wie Vererbung, Kapselung und Polymorphismus hergestellt.
Im objektorientierten Datenmodell ist ein Objekt eine Instanz einer Klasse , und eine Klasse ist ein Bauplan, der die Struktur und das Verhalten von Objekten definiert. Jedes Objekt kapselt seinen Zustand durch Attribute und sein Verhalten durch Methoden . Einer der bedeutendsten Vorteile des objektorientierten Datenmodells ist seine Unterstützung der Vererbung . Durch Vererbung kann eine Klasse Eigenschaften und Methoden von einer übergeordneten Klasse erben und so die Wiederverwendung und Modularität von Code fördern.
Das objektorientierte Datenmodell unterstützt auch die Kapselung , die die internen Implementierungsdetails einer Klasse vor ihren Benutzern verbirgt. Diese Funktion ist entscheidend für die Aufrechterhaltung der Datenintegrität und die Bereitstellung einer kontrollierten Schnittstelle zur Funktionalität der Klasse. Ein weiteres vom objektorientierten Datenmodell unterstütztes OOP-Konzept ist Polymorphismus . Polymorphismus ermöglicht die Behandlung von Objekten verschiedener Klassen als Objekte einer gemeinsamen Oberklasse, was die Flexibilität und Erweiterbarkeit des Datenbanksystems erleichtert. Das objektorientierte Datenmodell bietet zwar zahlreiche Vorteile, erfordert jedoch ein tieferes Verständnis objektorientierter Programmierkonzepte und erfordert möglicherweise komplexere Softwaretools für Design und Implementierung.
Bei der Arbeit mit Datenmodellen ist es wichtig, bestimmte Prinzipien zu befolgen, um ein effektives, aussagekräftiges und wartbares Modell zu erstellen. Hier sind einige wichtige Prinzipien der Datenmodellierung:
Die Einhaltung dieser Grundsätze während des Datenmodellierungsprozesses kann die Qualität des endgültigen Modells erheblich verbessern und es effizienter, verwaltbarer und wartbarer machen. Zusätzlich zur Einhaltung dieser Grundsätze kann der Einsatz leistungsstarker Tools wie der AppMaster- Plattform den Datenmodellierungsprozess erheblich vereinfachen und rationalisieren.
Mit dem visuellen Datenmodellierungstool und der intuitiven no-code Lösung können Benutzer mühelos Datenbankschemata entwerfen, Geschäftslogik erstellen und Web-, Mobil- und Backend-Anwendungen erstellen, die ihren individuellen Anforderungen entsprechen. Mit der richtigen Grundlage und den richtigen Tools können Sie effektive, skalierbare und wartbare Datenmodelle erstellen, die den Anforderungen Ihres Unternehmens gerecht werden.
Der Entwurf effektiver und wartbarer Datenmodelle ist für die Erstellung leistungsstarker, skalierbarer Softwarelösungen von entscheidender Bedeutung. Die AppMaster Plattform bietet eine leistungsstarke No-Code- Lösung zum Erstellen von Datenmodellen und zum Entwerfen von Backend-, Web- und Mobilanwendungen.
Mit dem von AppMaster bereitgestellten Tool zur Erstellung visueller Datenmodelle können Benutzer ganz einfach Datenbankschemata entwerfen, Beziehungen und Einschränkungen angeben und Geschäftslogik für die Interaktion mit ihren Daten erstellen. Die intuitive Benutzeroberfläche ermöglicht eine schnelle und effiziente Entwicklung von Datenmodellen, ohne dass Programmierkenntnisse erforderlich sind.
Mit dem von AppMaster angebotenen visuellen Datenbankschema-Designer können Benutzer ihr Datenbankschema entwerfen, indem sie Tabellen definieren, Beziehungen festlegen und Einschränkungen festlegen. Diese grafische Benutzeroberfläche vereinfacht den Datenmodellierungsprozess, indem sie es Benutzern ermöglicht, Entitäten und ihre Beziehungen visuell anzuordnen, anstatt komplexe SQL-Skripte schreiben zu müssen. Benutzer können über eine benutzerfreundliche Oberfläche Primärschlüssel, Fremdschlüssel und Indizes definieren und Tabellen einfach per Drag-and-Drop verbinden.
Neben dem visuellen Schema-Designer bietet AppMaster einen leistungsstarken Business Process (BP) Designer, mit dem Benutzer die Geschäftslogik ihrer Anwendungen erstellen und verwalten können. Mit dem BP Designer können Benutzer serverseitige Logik für Backend-Anwendungen erstellen, während Web- und mobile Anwendungen die Web BP- und Mobile BP-Designer zum Erstellen von Geschäftslogik auf Komponentenbasis verwenden.
Dank der drag-and-drop Funktionalität der Plattform ist die Verwendung des BP Designers einfach. Benutzer können komplexe Geschäftsprozesse schnell aufbauen, indem sie verschiedene Komponenten wie Aktionen, Bedingungen und Schleifen verbinden. Die Plattform unterstützt auch die Verwaltung von REST-API- und WSS- endpoints und hilft Benutzern, ihre Datenmodelle nahtlos anderen Systemen zur Verfügung zu stellen.
Nach der Fertigstellung ihrer Datenmodelle und Geschäftsprozesse können sich Benutzer darauf verlassen, dass AppMaster automatisch voll funktionsfähige Anwendungen generiert. Dies vereinfacht den Softwareentwicklungsprozess und eliminiert technische Schulden, indem Anwendungen bei jeder Änderung des Blueprints von Grund auf neu generiert werden. Dadurch können Unternehmen von schnelleren Entwicklungszyklen, geringeren Kosten und erhöhter Flexibilität profitieren.
AppMaster unterstützt mehrere Sprachen und Frameworks, sodass generierte Anwendungen nahtlos mit verschiedenen Technologien zusammenarbeiten können. Backend-Anwendungen werden mit Go (Golang) generiert, Webanwendungen verwenden das Vue3- Framework und JS/TS, während mobile Anwendungen auf Kotlin und Jetpack Compose für Android und SwiftUI für iOS basieren. Darüber hinaus sind generierte Anwendungen mit Postgresql -kompatiblen Datenbanken als Primärdatenbank kompatibel.
Datenmodelle sind für die Entwicklung und Verwaltung effizienter und wartbarer Datenbankverwaltungssysteme von entscheidender Bedeutung. Das Verständnis der verschiedenen Arten von Datenmodellen, ihrer Anwendungen und Schlüsselprinzipien hilft Softwareentwicklern und -architekten, fundierte Entscheidungen beim Entwurf und der Implementierung von Datenbanksystemen zu treffen.
Mit ihrer leistungsstarken no-code Lösung ermöglicht die AppMaster Plattform Benutzern die Erstellung umfassender Datenmodelle und Anwendungen. Der visuelle Datenbankschema-Designer, der Geschäftsprozess-Designer und die Funktionen zur automatisierten Anwendungsgenerierung von AppMaster machen die Erstellung zuverlässiger und wartbarer Datenbanklösungen schneller und zugänglicher.
Mit der Weiterentwicklung der Technologiebranche werden Tools wie die no-code Plattform von AppMaster immer wertvoller für die Entwicklung skalierbarer und effizienter Datenmodelle und der darauf basierenden Softwarelösungen.
Ein Datenmodell ist eine strukturelle Darstellung der Datenelemente, ihrer Beziehungen und Einschränkungen innerhalb eines Datenbankverwaltungssystems (DBMS). Es hilft bei der Organisation, Speicherung und Verwaltung großer Datenmengen.
Datenmodelle spielen in DBMS eine entscheidende Rolle, da sie einen strukturellen Rahmen für den Entwurf von Datenbanken, die Herstellung von Datenkonsistenz und die Ermöglichung einer effizienten Datenspeicherung, -abfrage und -verwaltung bieten.
Die Haupttypen von Datenmodellen sind hierarchische, Netzwerk-, relationale, Entity-Relationship- (ER) und objektorientierte Modelle.
Das hierarchische Datenmodell stellt Daten in einer baumartigen Struktur dar, wobei jeder Knoten einen übergeordneten Knoten und mehrere untergeordnete Knoten hat. Es war das erste in DBMS verwendete Datenmodell und eignet sich am besten für Eins-zu-Viele-Beziehungen.
Das Netzwerkdatenmodell ist ein flexibles Datenmodell, das mehrere Beziehungen zwischen Entitäten ermöglicht. Jeder Knoten im Netzwerkmodell kann mehrere übergeordnete und untergeordnete Knoten haben, was ihn ideal für Viele-zu-Viele-Beziehungen macht.
Das relationale Datenmodell ist ein Datenbankmodell, das auf dem Konzept von Beziehungen basiert und als Tabellen dargestellt wird. Es ermöglicht eine einfache Datenbearbeitung und -abfrage mithilfe von SQL und ist das am weitesten verbreitete Datenmodell.
Das Entity-Relationship-Modell (ER-Modell) ist ein konzeptionelles Datenmodell, das Entitäten und ihre Beziehungen darstellt. Es wird häufig beim Datenbankdesign verwendet und anhand eines ER-Diagramms visuell dargestellt.
Das objektorientierte Datenmodell integriert Datenbank- und Programmierkonzepte und stellt Daten als Objekte mit Attributen und Methoden dar. Es unterstützt Vererbung, Kapselung und Polymorphismus.
Zu den Prinzipien der Datenmodellierung gehören Klarheit, Einfachheit, Skalierbarkeit, Konsistenz und Flexibilität. Diese Prinzipien helfen dabei, effektive und wartbare Datenmodelle zu erstellen.
AppMaster Plattform bietet als Teil ihrer no-code Lösung ein Tool zur Erstellung visueller Datenmodelle für die Erstellung von Backend-, Web- und mobilen Anwendungen. Benutzer können mithilfe der intuitiven Benutzeroberfläche der Plattform problemlos Datenbankschemata, Geschäftslogik und mehr entwerfen.



Experimentieren Sie mit AppMaster mit kostenlosem Plan.
Wenn Sie fertig sind, können Sie das richtige Abonnement auswählen.


