
उपकरण आरक्षण ऐप: टकराव रोकें और वापसी ट्रैक करें
ऐसा उपकरण आरक्षण ऐप बनाएँ जो दोहरी बुकिंग रोके, वापसी और क्षति दर्ज करे और खराब उपकरणों को मेंटेनेंस होल्ड पर रखे।
डीबीएमएस में डेटा मॉडल का यह गहन विश्लेषण आपको डेटाबेस प्रबंधन प्रणालियों में इन संरचनाओं के महत्व, उनके प्रकार, उपयोग और प्रमुख सिद्धांतों को समझने में मदद करेगा।

एक डेटा मॉडल एक डेटाबेस प्रबंधन प्रणाली (डीबीएमएस) के भीतर डेटा तत्वों, उनके संबंधों और बाधाओं का एक संरचनात्मक प्रतिनिधित्व है। यह डेटाबेस सिस्टम को डिजाइन और कार्यान्वित करने के लिए एक ब्लूप्रिंट के रूप में कार्य करता है, जिससे सॉफ्टवेयर डेवलपर्स और डेटाबेस प्रशासकों को डेटा को कुशलतापूर्वक व्यवस्थित, संग्रहीत और प्रबंधित करने की अनुमति मिलती है।
डेटा मॉडल टीम के सदस्यों के बीच निर्णय लेने और संचार को सुव्यवस्थित करते हैं, जो विकास के दौरान एक दृश्य और वैचारिक उपकरण के रूप में कार्य करते हैं। इसके मूल में, एक डेटा मॉडल अपने संगठन और संबंधों सहित डेटा संरचना को परिभाषित करना चाहता है। इसके अलावा, यह संग्रहीत डेटा की आवश्यकताओं को वर्गीकृत करने और प्रस्तुत करने और डेटा अखंडता को बनाए रखने का एक साधन प्रदान करता है, जिससे अधिक प्रभावी और सुसंगत डेटा हेरफेर और पुनर्प्राप्ति का मार्ग प्रशस्त होता है।
डेटा मॉडल डेटाबेस प्रबंधन प्रणालियों में महत्वपूर्ण भूमिका निभाते हैं, क्योंकि वे:
पिछले कुछ वर्षों में कई प्रकार के डेटा मॉडल विकसित किए गए हैं। प्रत्येक प्रकार के अपने फायदे और नुकसान हैं, और उनकी उपयुक्तता विशिष्ट उपयोग के मामले पर निर्भर करती है। डेटा मॉडल के मुख्य प्रकार हैं:
किसी विशेष डेटाबेस सिस्टम के लिए सबसे उपयुक्त मॉडल का चयन करने के लिए प्रत्येक डेटा मॉडल की विशेषताओं और सीमाओं को समझना आवश्यक है। आइए इनमें से प्रत्येक प्रकार पर करीब से नज़र डालें।
पदानुक्रम डेटा मॉडल सबसे शुरुआती डेटाबेस मॉडल में से एक है, जिसे 1960 के दशक में विकसित किया गया था। यह पेड़ जैसी संरचनाओं का उपयोग करके डेटा का प्रतिनिधित्व करता है, जिसमें प्रत्येक नोड में एक पैरेंट और कई चाइल्ड नोड होते हैं। यह मॉडल एक-से-अनेक संबंधों (1:N) के लिए उपयुक्त है, जहां एक मूल इकाई एकाधिक चाइल्ड संस्थाओं से संबंधित होती है।
इसकी सरलता और कार्यान्वयन में आसानी पदानुक्रमित मॉडल की विशेषता है। फिर भी, जटिल रिश्तों और डेटा अतिरेक से निपटने में यह कुछ सीमाएँ प्रस्तुत करता है। आइए पदानुक्रमित मॉडल की प्रमुख विशेषताओं, फायदे और नुकसान पर करीब से नज़र डालें।
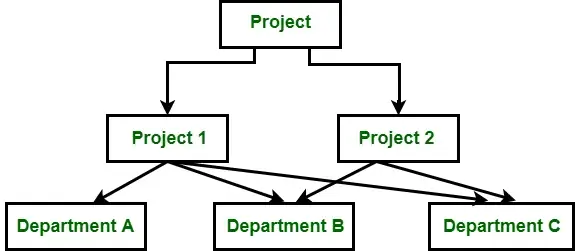
नेटवर्क डेटा मॉडल को 1960 के दशक के अंत में पदानुक्रमित मॉडल के विकास के रूप में विकसित किया गया था। यह एक नोड को एकाधिक पैरेंट और चाइल्ड नोड्स की अनुमति देकर पदानुक्रमित मॉडल का विस्तार करता है। यह लचीलापन नेटवर्क डेटा मॉडल को अनेक-से-अनेक संबंधों (एम:एन) का प्रतिनिधित्व करने में सक्षम बनाता है, जिससे यह अधिक जटिल डेटा संरचनाओं के लिए उपयुक्त हो जाता है।
छवि स्रोत: गीक्सफॉरगीक्स
बढ़ी हुई मॉडलिंग क्षमता और लचीलेपन की जटिलता और प्रदर्शन में कुछ लागत आती है। फिर भी, नेटवर्क मॉडल की अपनी खूबियाँ हैं और अभी भी विशिष्ट अनुप्रयोगों में इसका उपयोग किया जाता है। आइए नेटवर्क मॉडल की विशेषताओं, फायदे और नुकसान पर करीब से नज़र डालें।
रिलेशनल डेटा मॉडल को डेटा संबंधों के प्रतिनिधित्व को सरल बनाने के तरीके के रूप में 1970 में डॉ. एडगर एफ. कॉड द्वारा पेश किया गया था। रिलेशनल मॉडल डेटा को संबंधों के रूप में दर्शाता है, जो अनिवार्य रूप से पंक्तियों और स्तंभों वाली तालिकाएँ हैं। प्रत्येक पंक्ति, जिसे टुपल के रूप में भी जाना जाता है, एक एकल डेटा रिकॉर्ड का प्रतिनिधित्व करती है, जबकि प्रत्येक कॉलम डेटा प्रकार की एक विशेषता से मेल खाता है।
रिलेशनल मॉडल आसान डेटा हेरफेर की अनुमति देता है और इसकी सहज प्रकृति, लचीलेपन और संरचित क्वेरी भाषा (एसक्यूएल) के लिए समर्थन के लिए व्यापक रूप से उपयोग किया जाता है। इसके कई फायदों के बीच, रिलेशनल मॉडल डेटा अखंडता और SQL का उपयोग करके डेटा को क्वेरी करने और संशोधित करने में आसानी पर जोर देता है। आइए रिलेशनल मॉडल की विशेषताओं, फायदे और नुकसान के बारे में अधिक विस्तार से जानें।
पदानुक्रमित, नेटवर्क और संबंधपरक डेटा मॉडल में प्रत्येक में अद्वितीय विशेषताएं, फायदे और सीमाएं हैं। डेटा मॉडल का चुनाव प्रबंधित डेटा की विशिष्ट आवश्यकताओं, जटिलता और संबंधों पर निर्भर करता है।
इकाई-संबंध मॉडल (ईआर मॉडल) एक वैचारिक डेटा मॉडल है जो डेटा को संस्थाओं और उनके संबंधों के रूप में दर्शाता है। ईआर मॉडल का प्राथमिक लक्ष्य संगठन के घटकों, जैसे संस्थाओं, विशेषताओं और संबंधों की पहचान करके संगठन की डेटा आवश्यकताओं का स्पष्ट, सीधा और चित्रमय प्रतिनिधित्व प्रदान करना है।
ईआर मॉडल में, एक इकाई एक वास्तविक दुनिया की वस्तु या अवधारणा है जिसे आप डेटाबेस में प्रस्तुत करना चाहते हैं, जैसे कोई व्यक्ति, कोई वस्तु या कोई घटना। प्रत्येक इकाई में विशेषताओं का एक समूह होता है जो उसकी विशेषताओं या गुणों का वर्णन करता है। उदाहरण के लिए, किसी ग्राहक इकाई में, विशेषताओं में नाम, पता, फोन नंबर आदि शामिल हो सकते हैं। ईआर मॉडल में संबंध दो या दो से अधिक संस्थाओं के बीच संबंध है। ईआर मॉडल में तीन प्रकार के रिश्ते हैं: एक-से-एक, एक-से-अनेक, और अनेक-से-अनेक। डेटा अखंडता और कुशल डेटाबेस उपयोग सुनिश्चित करने के लिए रिश्तों को सही ढंग से मॉडल करना आवश्यक है।
एक इकाई-संबंध आरेख (ईआरडी) ईआर मॉडल में घटकों और उनके संबंधों को देखने का एक लोकप्रिय तरीका है। ईआरडी एक ग्राफिकल प्रतिनिधित्व है जो संस्थाओं, विशेषताओं और संबंधों को दर्शाने के लिए प्रतीकों का उपयोग करता है। यह आरेख डेटाबेस डिज़ाइनरों को संगठन की डेटा आवश्यकताओं को शीघ्रता से समझने और उन्हें उपयुक्त भौतिक डेटाबेस डिज़ाइन में अनुवाद करने में मदद करता है।
ऑब्जेक्ट-ओरिएंटेड डेटा मॉडल एक हालिया डेटा मॉडलिंग उन्नति है जो डेटाबेस और प्रोग्रामिंग अवधारणाओं को जोड़ती है। इस मॉडल में, डेटा को ऑब्जेक्ट के रूप में दर्शाया जाता है, और संबंध ऑब्जेक्ट-ओरिएंटेड प्रोग्रामिंग (ओओपी) तकनीकों जैसे इनहेरिटेंस, इनकैप्सुलेशन और पॉलीमोर्फिज्म के माध्यम से स्थापित किए जाते हैं।
ऑब्जेक्ट-ओरिएंटेड डेटा मॉडल में, एक ऑब्जेक्ट एक क्लास का एक उदाहरण है, और एक क्लास एक ब्लूप्रिंट है जो ऑब्जेक्ट की संरचना और व्यवहार को परिभाषित करता है। प्रत्येक वस्तु अपनी स्थिति को विशेषताओं के माध्यम से और अपने व्यवहार को विधियों के माध्यम से समाहित करती है। ऑब्जेक्ट-ओरिएंटेड डेटा मॉडल का सबसे महत्वपूर्ण लाभ विरासत के लिए इसका समर्थन है। इनहेरिटेंस एक वर्ग को मूल वर्ग से गुणों और विधियों को प्राप्त करने की अनुमति देता है, जिससे कोड के पुन: उपयोग और मॉड्यूलरिटी को बढ़ावा मिलता है।
ऑब्जेक्ट-ओरिएंटेड डेटा मॉडल एनकैप्सुलेशन का भी समर्थन करता है, जो किसी वर्ग के आंतरिक कार्यान्वयन विवरण को उसके उपयोगकर्ताओं से छुपाता है। यह सुविधा डेटा अखंडता बनाए रखने और कक्षा की कार्यक्षमता के लिए एक नियंत्रित इंटरफ़ेस प्रदान करने के लिए महत्वपूर्ण है। ऑब्जेक्ट-ओरिएंटेड डेटा मॉडल द्वारा समर्थित एक अन्य OOP अवधारणा बहुरूपता है। बहुरूपता विभिन्न वर्गों की वस्तुओं को एक सामान्य सुपरक्लास की वस्तुओं के रूप में मानने की अनुमति देती है, जिससे डेटाबेस सिस्टम में लचीलापन और विस्तारशीलता की सुविधा मिलती है। जबकि ऑब्जेक्ट-ओरिएंटेड डेटा मॉडल कई फायदे प्रदान करता है, इसके लिए ऑब्जेक्ट-ओरिएंटेड प्रोग्रामिंग अवधारणाओं की गहरी समझ की आवश्यकता होती है और डिजाइन और कार्यान्वयन के लिए अधिक जटिल सॉफ़्टवेयर टूल की आवश्यकता हो सकती है।
किसी भी डेटा मॉडल के साथ काम करते समय, एक प्रभावी, सार्थक और रखरखाव योग्य मॉडल बनाने के लिए कुछ सिद्धांतों का पालन करना महत्वपूर्ण है। यहां डेटा मॉडलिंग के कुछ महत्वपूर्ण सिद्धांत दिए गए हैं:
डेटा मॉडलिंग प्रक्रिया के दौरान इन सिद्धांतों का पालन करने से अंतिम मॉडल की गुणवत्ता में काफी सुधार हो सकता है, जिससे यह अधिक कुशल, प्रबंधनीय और रखरखाव योग्य बन जाएगा। इन सिद्धांतों का पालन करने के अलावा, ऐपमास्टर प्लेटफ़ॉर्म जैसे शक्तिशाली टूल का लाभ उठाकर डेटा मॉडलिंग प्रक्रिया को काफी सरल और सुव्यवस्थित किया जा सकता है।
इसके विज़ुअल डेटा मॉडलिंग टूल और सहज no-code समाधान के साथ, उपयोगकर्ता आसानी से डेटाबेस स्कीमा डिज़ाइन कर सकते हैं, व्यावसायिक तर्क बना सकते हैं, और वेब, मोबाइल और बैकएंड एप्लिकेशन बना सकते हैं जो उनकी विशिष्ट आवश्यकताओं के अनुरूप हैं। सही नींव और उपकरणों के साथ, आप प्रभावी, स्केलेबल और रखरखाव योग्य डेटा मॉडल बना सकते हैं जो आपकी संगठनात्मक आवश्यकताओं को पूरा करते हैं।
शक्तिशाली, स्केलेबल सॉफ़्टवेयर समाधान बनाने के लिए प्रभावी और रखरखाव योग्य डेटा मॉडल डिज़ाइन करना महत्वपूर्ण है। AppMaster प्लेटफ़ॉर्म डेटा मॉडल के निर्माण और बैकएंड, वेब और मोबाइल एप्लिकेशन को डिज़ाइन करने के लिए एक शक्तिशाली नो-कोड समाधान प्रदान करता है।
AppMaster द्वारा प्रदान किए गए विज़ुअल डेटा मॉडल निर्माण टूल के साथ, उपयोगकर्ता आसानी से डेटाबेस स्कीमा डिज़ाइन कर सकते हैं, रिश्तों और बाधाओं को निर्दिष्ट कर सकते हैं, और अपने डेटा के साथ बातचीत करने के लिए व्यावसायिक तर्क बना सकते हैं। सहज उपयोगकर्ता इंटरफ़ेस तेज़ और कुशल डेटा मॉडल विकास की अनुमति देता है, जिसमें किसी प्रोग्रामिंग अनुभव की आवश्यकता नहीं होती है।
AppMaster द्वारा प्रस्तुत विज़ुअल डेटाबेस स्कीमा डिज़ाइनर उपयोगकर्ताओं को तालिकाओं को परिभाषित करने, संबंध स्थापित करने और बाधाओं को निर्दिष्ट करके अपने डेटाबेस स्कीमा को डिज़ाइन करने में सक्षम बनाता है। यह ग्राफ़िकल इंटरफ़ेस जटिल SQL स्क्रिप्ट लिखने के बजाय उपयोगकर्ताओं को संस्थाओं और उनके संबंधों को दृश्य रूप से व्यवस्थित करने की अनुमति देकर डेटा मॉडलिंग प्रक्रिया को सरल बनाता है। उपयोगकर्ता उपयोगकर्ता के अनुकूल इंटरफेस का उपयोग करके प्राथमिक कुंजी, विदेशी कुंजी और इंडेक्स को परिभाषित कर सकते हैं और ड्रैग-एंड-ड्रॉप ऑपरेशंस का उपयोग करके तालिकाओं को आसानी से कनेक्ट कर सकते हैं।
विज़ुअल स्कीमा डिज़ाइनर के साथ-साथ, AppMaster एक शक्तिशाली बिजनेस प्रोसेस (बीपी) डिज़ाइनर प्रदान करता है जो उपयोगकर्ताओं को अपने एप्लिकेशन के व्यावसायिक तर्क बनाने और प्रबंधित करने की अनुमति देता है। बीपी डिज़ाइनर उपयोगकर्ताओं को बैकएंड अनुप्रयोगों के लिए सर्वर-साइड लॉजिक बनाने में सक्षम बनाता है, जबकि वेब और मोबाइल एप्लिकेशन प्रति-घटक के आधार पर व्यावसायिक तर्क बनाने के लिए वेब बीपी और मोबाइल बीपी डिजाइनरों का उपयोग करते हैं।
प्लेटफ़ॉर्म की drag-and-drop कार्यक्षमता के कारण, BP डिज़ाइनर का उपयोग करना सरल है। उपयोगकर्ता विभिन्न घटकों जैसे क्रियाओं, स्थितियों और लूपों को जोड़कर तेजी से जटिल व्यावसायिक प्रक्रियाओं का निर्माण कर सकते हैं। प्लेटफ़ॉर्म REST API और WSS endpoints प्रबंधित करने का भी समर्थन करता है, जिससे उपयोगकर्ताओं को अपने डेटा मॉडल को अन्य प्रणालियों में सहजता से प्रदर्शित करने में मदद मिलती है।
अपने डेटा मॉडल और व्यावसायिक प्रक्रियाओं को अंतिम रूप देने पर, उपयोगकर्ता स्वचालित रूप से पूरी तरह कार्यात्मक एप्लिकेशन उत्पन्न करने के लिए AppMaster पर भरोसा कर सकते हैं। यह सॉफ्टवेयर विकास प्रक्रिया को सरल बनाता है और जब भी ब्लूप्रिंट में बदलाव किया जाता है तो एप्लिकेशन को स्क्रैच से पुनर्जीवित करके तकनीकी ऋण को समाप्त करता है। परिणामस्वरूप, कंपनियां तेज़ विकास चक्र, कम लागत और बढ़े हुए लचीलेपन से लाभान्वित हो सकती हैं।
AppMaster कई भाषाओं और फ्रेमवर्क का समर्थन करता है, जिससे जेनरेट किए गए एप्लिकेशन विभिन्न तकनीकों के साथ निर्बाध रूप से काम कर सकते हैं। बैकएंड एप्लिकेशन गो (गोलंग) का उपयोग करके तैयार किए जाते हैं, वेब एप्लिकेशन Vue3 फ्रेमवर्क और JS/TS का उपयोग करते हैं, जबकि मोबाइल एप्लिकेशन एंड्रॉइड के लिए कोटलिन और Jetpack Compose और iOS के लिए SwiftUI पर बनाए जाते हैं। इसके अलावा, जेनरेट किए गए एप्लिकेशन अपने प्राथमिक डेटाबेस के रूप में Postgresql -संगत डेटाबेस के साथ संगत हैं।
कुशल और रखरखाव योग्य डेटाबेस प्रबंधन प्रणालियों के विकास और प्रबंधन में डेटा मॉडल महत्वपूर्ण हैं। विभिन्न प्रकार के डेटा मॉडल, उनके अनुप्रयोगों और प्रमुख सिद्धांतों को समझने से सॉफ्टवेयर डेवलपर्स और आर्किटेक्ट्स को डेटाबेस सिस्टम को डिजाइन और कार्यान्वित करते समय सूचित निर्णय लेने में मदद मिलती है।
अपने शक्तिशाली no-code समाधान के साथ, AppMaster प्लेटफ़ॉर्म उपयोगकर्ताओं को व्यापक डेटा मॉडल और एप्लिकेशन बनाने में सक्षम बनाता है। AppMaster द्वारा प्रदान की जाने वाली विज़ुअल डेटाबेस स्कीमा डिज़ाइनर, बिजनेस प्रोसेस डिज़ाइनर और स्वचालित एप्लिकेशन जेनरेशन सुविधाएँ विश्वसनीय और रखरखाव योग्य डेटाबेस समाधानों को त्वरित और अधिक सुलभ बनाती हैं।
जैसे-जैसे तकनीकी उद्योग विकसित होता है, AppMaster के no-code प्लेटफ़ॉर्म जैसे उपकरण स्केलेबल और कुशल डेटा मॉडल और उन पर निर्भर सॉफ़्टवेयर समाधान विकसित करने के लिए तेजी से मूल्यवान हो जाते हैं।
एक डेटा मॉडल एक डेटाबेस प्रबंधन प्रणाली (डीबीएमएस) के भीतर डेटा तत्वों, उनके संबंधों और बाधाओं का एक संरचनात्मक प्रतिनिधित्व है। यह बड़ी मात्रा में डेटा को व्यवस्थित, संग्रहीत और प्रबंधित करने में सहायता करता है।
डेटा मॉडल डीबीएमएस में एक महत्वपूर्ण भूमिका निभाते हैं, क्योंकि वे डेटाबेस को डिजाइन करने, डेटा स्थिरता स्थापित करने और कुशल डेटा भंडारण, पुनर्प्राप्ति और प्रबंधन को सक्षम करने के लिए एक संरचनात्मक ढांचा प्रदान करते हैं।
डेटा मॉडल के मुख्य प्रकार पदानुक्रमित, नेटवर्क, रिलेशनल, इकाई-संबंध (ईआर), और ऑब्जेक्ट-ओरिएंटेड मॉडल हैं।
पदानुक्रमित डेटा मॉडल एक पेड़ जैसी संरचना में डेटा का प्रतिनिधित्व करता है, जिसमें प्रत्येक नोड में एक माता-पिता और कई बच्चे होते हैं। यह DBMS में उपयोग किया जाने वाला पहला डेटा मॉडल था और एक-से-अनेक रिश्तों के लिए सबसे उपयुक्त है।
नेटवर्क डेटा मॉडल एक लचीला डेटा मॉडल है जो संस्थाओं के बीच कई संबंधों की अनुमति देता है। नेटवर्क मॉडल में प्रत्येक नोड में एकाधिक पैरेंट और चाइल्ड नोड हो सकते हैं, जो इसे अनेक-से-अनेक संबंधों के लिए आदर्श बनाता है।
रिलेशनल डेटा मॉडल संबंधों की अवधारणा पर आधारित एक डेटाबेस मॉडल है, जिसे तालिकाओं के रूप में दर्शाया जाता है। यह SQL का उपयोग करके आसान डेटा हेरफेर और पुनर्प्राप्ति को सक्षम बनाता है और यह सबसे व्यापक रूप से उपयोग किया जाने वाला डेटा मॉडल है।
इकाई-संबंध मॉडल (ईआर मॉडल) एक वैचारिक डेटा मॉडल है जो संस्थाओं और उनके संबंधों का प्रतिनिधित्व करता है। यह आमतौर पर डेटाबेस डिज़ाइन में उपयोग किया जाता है और इसे ईआर आरेख का उपयोग करके दृश्य रूप से दर्शाया जाता है।
ऑब्जेक्ट-ओरिएंटेड डेटा मॉडल डेटाबेस और प्रोग्रामिंग अवधारणाओं को एकीकृत करता है, जो डेटा को विशेषताओं और विधियों के साथ ऑब्जेक्ट के रूप में प्रस्तुत करता है। यह वंशानुक्रम, एनकैप्सुलेशन और बहुरूपता का समर्थन करता है।
डेटा मॉडलिंग के सिद्धांतों में स्पष्टता, सरलता, मापनीयता, स्थिरता और लचीलापन शामिल हैं। ये सिद्धांत प्रभावी और रखरखाव योग्य डेटा मॉडल बनाने में मदद करते हैं।
AppMaster प्लेटफ़ॉर्म बैकएंड, वेब और मोबाइल एप्लिकेशन बनाने के लिए अपने no-code समाधान के हिस्से के रूप में एक विज़ुअल डेटा मॉडल निर्माण टूल प्रदान करता है। उपयोगकर्ता प्लेटफ़ॉर्म के सहज इंटरफ़ेस का उपयोग करके आसानी से डेटाबेस स्कीमा, व्यावसायिक तर्क और बहुत कुछ डिज़ाइन कर सकते हैं।



फ्री प्लान के साथ ऐपमास्टर के साथ प्रयोग करें।
जब आप तैयार होंगे तब आप उचित सदस्यता चुन सकते हैं।


