Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
Zaawansowane techniki optymalizacji zapytań SQL w celu zwiększenia wydajności relacyjnych baz danych.

Optymalizacja zapytań SQL ma kluczowe znaczenie dla poprawy wydajności systemów zarządzania relacyjnymi bazami danych (RDBMS) . Celem optymalizacji zapytań jest znalezienie najbardziej efektywnego sposobu wykonania zapytania, co skróci czas odpowiedzi, minimalizuje zużycie zasobów i poprawia wydajność aplikacji bazodanowych.
Relacyjne bazy danych obsługują ogromne ilości danych, a efektywne ich przetwarzanie ma kluczowe znaczenie dla utrzymania wysokowydajnej aplikacji. Źle zaprojektowane i napisane zapytania SQL mogą znacząco wpłynąć na wygodę użytkownika, ponieważ mogą spowalniać aplikacje i zużywać nadmierne zasoby systemowe. Zrozumienie i zastosowanie technik optymalizacji zapytań SQL może znacznie poprawić zdolność systemu RDBMS do wydajnego i szybkiego zarządzania danymi oraz ich wyszukiwania.
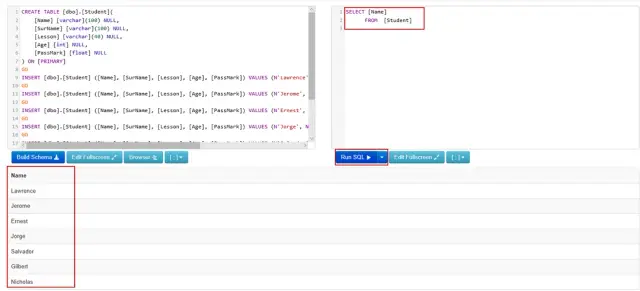
Źródło obrazu: SQLShack
Silnik bazy danych to rdzeń każdego RDBMS, odpowiedzialny za przetwarzanie i zarządzanie danymi przechowywanymi w relacyjnych bazach danych. Odgrywa kluczową rolę w optymalizacji zapytań poprzez interpretację instrukcji SQL, generowanie planów wykonania i najskuteczniejsze pobieranie danych z pamięci.
Po przesłaniu zapytania optymalizator zapytań silnika bazy danych przekształca instrukcję SQL w jeden lub więcej planów wykonania. Plany te reprezentują różne sposoby przetwarzania zapytania, a optymalizator wybiera najlepszy na podstawie szacunków kosztów, takich jak użycie operacji we/wy i procesora. Proces ten nazywany jest kompilacją zapytań i polega na analizowaniu, optymalizacji i generowaniu pożądanego planu wykonania.
Wybrany plan wykonania określa, w jaki sposób silnik bazy danych będzie uzyskiwał dostęp do danych żądanych przez instrukcję SQL, filtrował je i zwracał. Wydajny plan wykonania powinien minimalizować zużycie zasobów, skracać czas reakcji i zapewniać lepszą wydajność aplikacji.
Identyfikacja wąskich gardeł wydajnościowych w zapytaniach SQL ma kluczowe znaczenie dla optymalizacji ich wydajności. Poniższe techniki mogą pomóc w wykryciu obszarów, w których wydajność zapytań może być niższa:
Identyfikując i eliminując wąskie gardła wydajności w zapytaniach SQL, możesz skutecznie zoptymalizować ich wykonanie i znacznie poprawić wydajność swoich systemów baz danych.
Projektowanie wydajnych zapytań SQL to pierwszy krok w kierunku osiągnięcia optymalnej wydajności w relacyjnych bazach danych. Postępując zgodnie z poniższymi najlepszymi praktykami, można zwiększyć responsywność i skalowalność systemu baz danych:
DO:
SELECT column1, column2, column3 FROM table_name; NIE: SELECT * FROM table_name;
DO:
SELECT t1.column1, t2.column2 FROM table1 AS t1 JOIN table2 AS t2 ON t1.ID = t2.ID; NIE: SELECT column1, (SELECT column2 FROM table2 WHERE table1.ID = table2.ID) FROM table1;
SELECT column1, column2 FROM table_name WHERE column3 = 'some_value';
SELECT column1, column2 FROM table_name WHERE some_condition ORDER BY column3 LIMIT 10 OFFSET 20;
Indeksy i plany wykonania odgrywają kluczową rolę w optymalizacji zapytań SQL. Zrozumienie ich celu i zastosowania może pomóc w maksymalnym wykorzystaniu RDBMS:
Wskazówki dotyczące zapytań to dyrektywy lub instrukcje osadzone w zapytaniach SQL, które wskazują silnikowi bazy danych sposób wykonania określonego zapytania. Można ich używać do wpływania na plan wykonania, wybierania określonych indeksów lub zastępowania domyślnego zachowania optymalizatora bazy danych. Wskazówki dotyczące zapytań należy stosować oszczędnie i dopiero po dokładnym przetestowaniu, ponieważ mogą mieć niezamierzone konsekwencje. Oto kilka przykładów wskazówek dotyczących zapytań:
SELECT column1, column2 FROM table_name WITH (INDEX(index_name)) WHERE column3 = 'some_value';
SELECT column1, column2 FROM table1 INNER LOOP JOIN table2 ON table1.ID = table2.ID;
SELECT column1, column2 FROM table_name WHERE column3 = 'some_value' OPTION (MAXDOP 4);
Pamiętaj, że chociaż wskazówki dotyczące zapytań mogą pomóc w optymalizacji konkretnych zapytań, należy ich używać ostrożnie i po dokładnej analizie, ponieważ czasami mogą prowadzić do nieoptymalnego lub niestabilnego działania. Zawsze testuj swoje zapytania z podpowiedziami i bez nich, aby określić najlepsze podejście w danej sytuacji.
Odpowiednio zaprojektowany schemat bazy danych, wydajne zapytania SQL i odpowiednie wykorzystanie indeksów to kluczowe czynniki w osiągnięciu optymalnej wydajności w relacyjnych bazach danych. Aby jeszcze szybciej tworzyć aplikacje , rozważ użycie platformy AppMaster bez kodu , która umożliwia łatwe tworzenie skalowalnych aplikacji internetowych, mobilnych i backendowych.
Optymalizacja zapytań SQL wymaga głębokiego zrozumienia ich charakterystyki wydajnościowej, którą można analizować za pomocą różnych narzędzi do profilowania i diagnostyki. Narzędzia te pomagają uzyskać wgląd w wykonywanie zapytań, wykorzystanie zasobów i potencjalne problemy, umożliwiając skuteczne identyfikowanie i eliminowanie wąskich gardeł. W tym miejscu omówimy kilka podstawowych narzędzi i technik analizy wydajności zapytań SQL.
SQL Server Profiler to potężne narzędzie diagnostyczne dostępne w Microsoft SQL Server. Pozwala monitorować i śledzić zdarzenia zachodzące w instancji SQL Server, przechwytywać dane o poszczególnych instrukcjach SQL i analizować ich wydajność. Profiler pomaga znaleźć wolno działające zapytania, zidentyfikować wąskie gardła i odkryć potencjalne możliwości optymalizacji.
W bazach danych Oracle SQL Trace pomaga w zbieraniu danych związanych z wydajnością dla poszczególnych instrukcji SQL. Generuje pliki śledzenia, które można analizować za pomocą narzędzia TKPROF, które formatuje surowe dane śledzenia do bardziej czytelnego formatu. Raport wygenerowany przez TKPROF dostarcza szczegółowych informacji o planie wykonania, czasie, jaki upłynął i zużyciu zasobów dla każdej instrukcji SQL, co może być nieocenione w identyfikacji i optymalizacji problematycznych zapytań.
MySQL Performance Schema to silnik pamięci masowej zapewniający instrumenty do profilowania i diagnozowania problemów z wydajnością na serwerze MySQL. Przechwytuje informacje o różnych zdarzeniach związanych z wydajnością, w tym o wykonaniu zapytania i wykorzystaniu zasobów. Dane schematu wydajności można następnie przeglądać i analizować w celu zidentyfikowania wąskich gardeł wydajności. Co więcej, MySQL Query Analyzer, będący częścią MySQL Enterprise Monitor, to narzędzie graficzne, które zapewnia wgląd w wydajność zapytań i pomaga identyfikować zapytania problematyczne. Monitoruje w czasie rzeczywistym aktywność zapytań, analizuje plany wykonania i dostarcza rekomendacji dotyczących optymalizacji.
Większość RDBMS udostępnia polecenie EXPLAIN w celu analizy planu wykonania zapytania. Polecenie EXPLAIN zapewnia wgląd w sposób, w jaki silnik bazy danych przetwarza dane zapytanie SQL, pokazując operacje, kolejność wykonywania, metody dostępu do tabeli, typy złączy i nie tylko. W PostgreSQL użycie EXPLAIN ANALYZE dostarcza dodatkowych informacji na temat rzeczywistych czasów wykonania, liczby wierszy i innych statystyk czasu wykonywania. Zrozumienie wyników działania polecenia EXPLAIN może pomóc w rozpoznaniu problematycznych obszarów, takich jak nieefektywne łączenia lub skanowanie pełnych tabel, i pomóc w wysiłkach optymalizacyjnych.
Do zapytań SQL można zastosować liczne wzorce optymalizacji, aby uzyskać lepszą wydajność. Niektóre typowe wzorce obejmują:
Skorelowane podzapytania mogą być znaczącym źródłem słabej wydajności, ponieważ są wykonywane raz dla każdego wiersza zapytania zewnętrznego. Przepisanie skorelowanych podzapytań na łączenie regularne lub boczne może często prowadzić do znacznej poprawy czasu wykonywania.
Użycie klauzuli IN może czasami skutkować nieoptymalną wydajnością, szczególnie w przypadku dużych zbiorów danych. Zastąpienie klauzuli IN podzapytaniem EXISTS lub operacją JOIN może pomóc w optymalizacji zapytania SQL, umożliwiając silnikowi bazy danych lepsze wykorzystanie indeksów i innych technik optymalizacji.
Indeksy mogą radykalnie poprawić wydajność zapytań, ale są skuteczne tylko wtedy, gdy zapytanie SQL jest zaprojektowane tak, aby prawidłowo z nich korzystać. Upewnij się, że klauzule WHERE używają predykatów przyjaznych indeksom — warunków, które można skutecznie ocenić przy użyciu dostępnych indeksów. Może to obejmować wykorzystanie kolumn indeksowanych, użycie odpowiednich operatorów porównania i unikanie funkcji lub wyrażeń, które uniemożliwiają użycie indeksów.
Zmaterializowane widoki przechowują wynik zapytania i mogą być używane do buforowania wyników złożonych obliczeń lub agregacji, do których często uzyskuje się dostęp, ale rzadko je aktualizować. Korzystanie z widoków zmaterializowanych może prowadzić do znacznej poprawy wydajności w przypadku obciążeń wymagających dużej liczby odczytów.
Chociaż optymalizacja zapytań SQL ma kluczowe znaczenie dla osiągnięcia dobrej wydajności bazy danych, istotne jest zrównoważenie optymalizacji i łatwości konserwacji. Nadmierna optymalizacja może prowadzić do powstania złożonego i trudnego do zrozumienia kodu, co utrudnia jego utrzymanie, debugowanie i modyfikowanie. Aby zrównoważyć optymalizację i łatwość konserwacji, rozważ następujące kwestie:
Znalezienie właściwej równowagi między optymalizacją a łatwością konserwacji gwarantuje, że relacyjne bazy danych i aplikacje będą mogły zapewnić pożądaną wydajność, zachowując jednocześnie elastyczność, łatwość konserwacji i dostosowywania się do przyszłych zmian.
Optymalizacja zapytań SQL odnosi się do procesu znajdowania najbardziej efektywnego sposobu wykonania zapytania w systemie zarządzania relacyjnymi bazami danych (RDBMS). Obejmuje identyfikację wąskich gardeł wydajności, stosowanie najlepszych praktyk w projektowaniu zapytań i wykorzystanie funkcji silnika bazy danych w celu skrócenia czasu odpowiedzi na zapytania.
Optymalizacja zapytań SQL ma kluczowe znaczenie dla poprawy wydajności baz danych i aplikacji, ponieważ wolne i źle zoptymalizowane zapytania mogą prowadzić do nieefektywności, marnowania zasobów i zmniejszenia zadowolenia użytkowników.
Wąskie gardła w wydajności zapytań SQL można zidentyfikować, analizując plany wykonania zapytań, korzystając z profilerów i narzędzi diagnostycznych, oceniając czasy odpowiedzi i sprawdzając metryki, takie jak użycie procesora, pamięci i dysku.
Do najlepszych praktyk projektowania wydajnych zapytań SQL zalicza się używanie instrukcji SELECT z określonymi kolumnami, minimalizowanie użycia symboli wieloznacznych, używanie odpowiednich złączeń i indeksów, wykorzystywanie możliwości klauzuli WHERE oraz implementowanie paginacji.
Indeksy w RDBMS mogą znacznie poprawić wydajność zapytań, zapewniając szybki i wydajny dostęp do określonych kolumn i wierszy w tabeli. Zmniejszają potrzebę pełnego skanowania tabeli i mogą pomóc w sortowaniu, grupowaniu i filtrowaniu danych.
Plany wykonania to wizualna reprezentacja kroków i operacji wykonywanych przez silnik bazy danych w celu wykonania zapytania SQL. Mogą pomóc w zidentyfikowaniu wąskich gardeł i zrozumieniu, w jaki sposób silnik bazy danych przetwarza zapytanie.
Wskazówki dotyczące zapytań to dyrektywy lub instrukcje osadzone w zapytaniach SQL, które dostarczają silnikowi bazy danych wskazówek dotyczących sposobu wykonania określonego zapytania. Mogą pomóc w wpływie na plan wykonania, wyborze konkretnych indeksów, czy nadpisaniu domyślnego zachowania optymalizatora bazy danych.
Profilery i narzędzia diagnostyczne mogą pomóc w optymalizacji zapytań SQL, dostarczając cennych informacji na temat wykonywania zapytań, wykorzystania zasobów, wskaźników wydajności i potencjalnych problemów. Narzędzia te pomagają identyfikować wąskie gardła, sugerować optymalizacje i monitorować poprawę wydajności.
Typowe wzorce optymalizacji zapytań SQL obejmują przepisywanie skorelowanych podzapytań w formie złączeń, zastępowanie klauzul IN operacjami EXISTS lub JOIN, używanie predykatów przyjaznych indeksom w klauzulach WHERE oraz tworzenie zmaterializowanych widoków do złożonych obliczeń.
Równoważenie optymalizacji i łatwości konserwacji w optymalizacji zapytań SQL polega na znalezieniu równowagi pomiędzy poprawą wydajności i czytelnością kodu. Zbyt duża optymalizacja może skutkować złożonymi i trudnymi w utrzymaniu zapytaniami, natomiast niewystarczająca optymalizacja może prowadzić do niskiej wydajności bazy danych. Celem jest osiągnięcie odpowiedniego połączenia wydajności i łatwości konserwacji.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


