


Equipment reservation app: prevent conflicts and track returns
Plan an equipment reservation app that prevents double bookings, records returns and damage, and places faulty items on maintenance hold.
Discover High Availability and its importance for mission-critical systems. Learn about strategies and technologies for achieving HA and their advantages.

As organizations increasingly rely on technology to drive their operations, the importance of having reliable, always-on systems has never been greater. High Availability (HA) is a set of strategies and technologies designed to ensure that mission-critical systems are operational and available to users as much as possible. In this article, we will explore the concept of High Availability, examine the different methods used to achieve it, and discuss the advantages and limitations of each approach. Whether you are a system administrator, a business owner, or a technologist, this article will provide you with the knowledge you need to ensure the availability of your critical systems.
High Availability (HA) is a system design principle and a set of techniques that aims to ensure that a certain system, service, or infrastructure is continuously operational and available for use with minimal interruption or downtime. The goal of HA is to provide a high level of reliability and availability for systems and services that are critical to the operation of an organization. This can be achieved through various methods such as redundancy, failover, and replication. By implementing HA, organizations can minimize the risk of system failures and ensure that their systems and services are always available to users, even in unexpected outages or hardware failures.
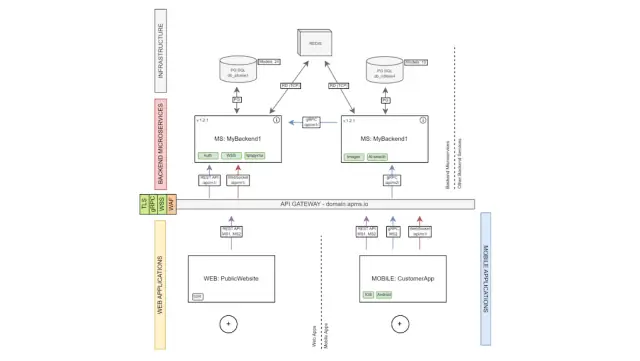
Applications built on the AppMaster platform support high availability for this; the backend application must be created, taking into account that they are Stateless. They do not have any internal state. Our users who need to provide high availability for their backend applications should download their project binaries and host them in Kubernetes or Docker Swarm in load-balancing mode. That is, each next request from the client will go to a new instance of the backend, so you can increase the load almost indefinitely and have a failover cluster.
High availability works by implementing strategies and technologies to keep a system or service continuously operational and available to users. There are several common methods used to achieve high availability, such as:
By implementing these methods, high availability can ensure that a system or service is always available, even during failures or outages. However, it's important to note that high availability is not a guarantee of 100% uptime, and some downtime is expected even with HA systems.
High availability clusters (HACs) are a specific type of high availability solution that involves grouping multiple servers together to work as a single system. The servers in a high-availability cluster work together to provide a single point of access for users and to ensure that if one server fails, the others can take over and continue providing services.
There are several types of high-availability clusters, such as:
HACs can provide several benefits, such as high availability, improved scalability, and increased performance. They are used in many applications, such as databases, web servers, email servers, and more. It's important to note that setting up and maintaining a HAC can be complex and requires specialized software and hardware. It's also essential to have a proper testing and disaster recovery plan in place to ensure that the cluster can fail over correctly in case of a failure.
High availability is crucial for organizations that rely heavily on technology to drive their operations. It ensures critical systems and services are always operational and available, minimizing downtime and disruption. Business continuity is one of the most important benefits of high availability. It helps ensure that business operations can continue even during unexpected outages or failures, minimizing the risk of lost revenue, productivity, and customer dissatisfaction. Compliance with regulations is another important aspect, as many industries have strict requirements for system availability. High availability can help organizations meet these requirements and avoid costly fines and penalties.
Additionally, high availability can provide organizations with a competitive edge by ensuring that their systems and services are always available to customers, which can help improve customer satisfaction and loyalty. Furthermore, High availability can minimize costs by minimizing downtime and the associated costs of lost revenue, damage to reputation, and additional costs to restore the service. Overall, high availability plays a vital role in maintaining the reliability and availability of critical systems and services. It helps organizations minimize the risks of system failures and ensure that their operations can continue smoothly.
High availability architecture refers to the design and implementation of systems and infrastructure that can provide high availability and reliability. It involves using multiple strategies and technologies to ensure that a system or service is always available, even during failures or outages.
Here are a few key components of a high-availability architecture:
A high availability architecture is typically implemented in a distributed fashion, using multiple servers, network devices, and other components working together to provide a high level of availability. It also requires a robust testing, maintenance, and disaster recovery plan to ensure that the systems can failover correctly in case of a failure.
Several products can help organizations achieve high availability, and the specific products needed will depend on the organization's specific requirements and the type of systems and services that need to be made highly available. Here are a few examples of products that can be used to achieve high availability:
It's important to note that setting up and maintaining a high-availability solution can be complex and requires specialized knowledge and skills. Working with experienced professionals is essential to ensure that the answer is implemented correctly and can meet the organization's needs.
High availability (HA) and redundancy are related concepts, but they refer to different aspects of ensuring that systems and services are always available. High availability refers to ensuring that a system or service is always available, with minimal interruption or downtime. It involves using multiple strategies and technologies to ensure that a system or service is always available, even during failures or outages.
Redundancy, on the other hand, refers to having multiple copies of a system or component so that if one fails, the others can take over. This can be achieved through various methods, such as hardware redundancy, software redundancy, and network redundancy. Redundancy is one of the key strategies to achieve high availability, but it is not the only one.
So, in short, high availability is a goal, a design principle, and refers to the overall availability of a system. At the same time, redundancy is a strategy, a technique, and refers to the practice of having multiple copies of a system or component.
High availability and fault tolerance are related concepts that ensure that systems and services are always available. High availability (HA) ensures that a system or service is always available with minimal interruption or downtime. It involves using multiple strategies and technologies to ensure that a system or service is always available, even during failures or outages.
Fault tolerance, on the other hand, refers to the ability of a system to continue operating even when one or more of its components fail. It measures how well a system can withstand failures and continue to function. Fault tolerance can be achieved through various methods such as redundancy, replication, and load balancing.
Both high availability and fault tolerance are essential for ensuring that systems and services are always available. High availability focuses on minimizing downtime and ensuring that systems are always available, while fault tolerance focuses on ensuring that systems can continue operating even when failures occur.
In summary, high availability is a goal, a design principle, and refers to the overall availability of a system. At the same time, fault tolerance is a property that measures a system's ability to operate despite failures.
Implementing high availability (HA) can be complex and requires specialized knowledge and skills. Here are a few best practices that organizations can follow to achieve high availability:
By following these best practices, organizations can increase the reliability and availability of their systems and services and minimize the risk of system failures and outages.
High availability refers to the ability of a system or service to remain operational and accessible to users during planned or unplanned outages or disruptions. This can include hardware failures, network outages, or other types of disruptions.
High availability is important because it helps ensure that systems and services remain available and accessible to users, even in the event of an outage or disruption. This can help prevent downtime and minimize the impact of outages on business operations.
High availability can be achieved through a variety of methods, including:
Yes, there are different levels of high availability, depending on the desired level of uptime and the cost of achieving it. Some common levels of high availability include:
99.9% availability: also known as "three nines" availability, this level of availability translates to about 8.76 hours of downtime per year
99.99% availability: also known as "four nines" availability, this level of availability translates to about 52.56 minutes of downtime per year
99.999% availability: also known as "five nines" availability, this level of availability translates to about 5.26 minutes of downtime per year
High availability and disaster recovery are related, but they are not the same thing. High availability is focused on preventing outages and ensuring that systems and services remain available, while disaster recovery is focused on restoring systems and services in the event of a major disruption or disaster. Together, high availability and disaster recovery can help ensure that a business can continue to operate in the face of disruptions and outages.
High availability can be implemented both on-premises and in the cloud. On-premises implementations typically involve setting up redundant systems and components within a single physical location, while cloud-based implementations can make use of features like load balancing and auto-scaling to provide high availability across multiple geographic locations.
Some benefits of using high availability solutions include:
Experiment with AppMaster with free plan.
When you will be ready you can choose the proper subscription.


