App per la prenotazione delle attrezzature: evita i conflitti e monitora le restituzioni
Progetta un'app per la prenotazione delle attrezzature che eviti le doppie prenotazioni, registri restituzioni e danni e metta in manutenzione i beni difettosi.
Imparate una guida completa ai database relazionali senza bisogno di codificare.

Comprendere il concetto di database e i suoi vari tipi, come i database relazionali e non relazionali, può essere difficile per chi non ha esperienza di codifica e sviluppo di applicazioni. Tuttavia, ciò non significa che sia un compito impossibile. Questo articolo vi aiuterà a ottenere una conoscenza completa dei database relazionali, dei loro pro e contro, degli esempi e di come creare un database relazionale anche senza esperienza di codifica. Iniziamo con i fondamenti dei database relazionali.
Un database relazionale è una raccolta di informazioni organizzate in modo appropriato e con relazioni chiaramente definite, in modo che sia possibile accedervi e recuperarle facilmente. Secondo il modello tradizionale di database relazionale, le strutture di dati che comprendono tabelle, viste e indici sono tenute separate dalle strutture fisiche di archiviazione. Di conseguenza, gli amministratori dei database possono modificare la memorizzazione fisica dei dati senza influenzare la struttura logica dei dati.
Diversi tipi di organizzazioni, soprattutto le grandi imprese, utilizzano i database relazionali per organizzare i dati e creare relazioni chiare tra i punti chiave dei dati. In questo modo, diventa facile cercare e trovare le informazioni necessarie per prendere decisioni aziendali fondamentali. I dati strutturati sono tipicamente la base di un database relazionale efficiente.
Un database relazionale utilizza tabelle di dati per memorizzare informazioni sugli oggetti correlati. Ogni riga ha un identificatore unico chiamato chiave, mentre ogni colonna ha gli attributi dei dati. È facile identificare le relazioni tra i punti di dati in un database relazionale perché ogni record assegna un valore a ogni caratteristica del database.
Il linguaggio SQL (Structured Query Language) è l'interfaccia standard per utenti e programmi applicativi (API) di un database relazionale. L'obiettivo delle dichiarazioni di codice SQL è quello di creare query interattive per le informazioni contenute in un database relazionale e raccogliere i dati per il processo decisionale e il reporting. È inoltre importante avere regole di integrità dei dati chiaramente definite per rendere il database relazionale accurato e accessibile.
È possibile comprendere meglio il funzionamento e la creazione di un database relazionale familiarizzando con la sua struttura. Le tabelle di un database relazionale hanno una colonna chiave che contiene un valore unico per ogni riga. Questa colonna è nota come chiave primaria.
Le colonne di una tabella che si riferiscono alle chiavi primarie di altre tabelle sono chiamate chiavi esterne. È fondamentale avere queste colonne perché i dati delle varie tabelle sono collegati tra loro attraverso i valori corrispondenti delle colonne chiave. Le colonne sono chiamate anche campi o attributi, mentre le righe sono chiamate anche record.
 In un database relazionale ideale, ogni tabella dovrebbe rappresentare un particolare tipo di entità, come un cliente, un prodotto o un reddito. Ogni riga si riferisce all'istanza specifica di quel tipo di entità, mentre la colonna si riferisce al valore particolare di quell'istanza, come il nome del cliente, il prezzo del prodotto o un importo esatto.
In un database relazionale ideale, ogni tabella dovrebbe rappresentare un particolare tipo di entità, come un cliente, un prodotto o un reddito. Ogni riga si riferisce all'istanza specifica di quel tipo di entità, mentre la colonna si riferisce al valore particolare di quell'istanza, come il nome del cliente, il prezzo del prodotto o un importo esatto.
Esempio
Il database delle vendite di un'organizzazione ha due tabelle chiamate entrate e servizi.
La tabella dei servizi avrà colonne per nome, durata e costo.
La tabella delle entrate avrà colonne per la data di vendita, il pagamento esatto, lo sconto e l'indirizzo.
Ogni voce delle entrate avrà una chiave esterna che fa riferimento alla chiave primaria della tabella dei servizi. Per ogni prodotto possono esserci più vendite, quindi questo tipo di relazione tra la tabella dei servizi e quella delle entrate si chiama relazione uno-a-molti. Analizzeremo in dettaglio i tipi di relazione nei database relazionali più avanti nell'articolo.
Ora che conoscete le basi dei database relazionali, potreste chiedervi perché sono importanti e quali sono i loro vantaggi. Analizziamo in dettaglio i pro e i contro dei database relazionali, in modo da poter padroneggiare l'arte di creare database relazionali per lo sviluppo di applicazioni.
I vantaggi principali dell'uso dei database relazionali sono i seguenti:
Il rischio di duplicazione dei dati è minimo, poiché i database relazionali sono costruiti utilizzando chiavi. Potrebbe essere difficile determinare quale fonte di informazioni sia affidabile se ci sono diversi record degli stessi dati. La rimozione di elementi duplicati nei database relazionali garantisce l'accuratezza dei dati.
Se si costruisce un database relazionale, non si avranno vincoli in futuro per l'aggiunta di altri dati. Il database offre la flessibilità necessaria per espandersi e modificarsi in base alle esigenze delle informazioni che verranno conservate.
È difficile cercare, filtrare e organizzare i dati come si desidera in altri tipi di database che dipendono dalla gerarchia delle informazioni o da percorsi predefiniti per accedere alle informazioni. Invece, estrarre i dati precisi che si desiderano da un database relazionale è molto più semplice.
L'uso dei database relazionali nello sviluppo di applicazioni presenta anche alcuni svantaggi.
Poiché le colonne devono essere create e i dati devono rientrare in categorie piuttosto rigide, i database relazionali necessitano di una struttura e di una pianificazione notevoli. Sebbene questa struttura presenti diversi vantaggi, presenta anche notevoli svantaggi, tra cui le difficoltà di manutenzione e la mancanza di adattabilità e scalabilità in assenza di competenze adeguate.
Per mantenere un database relazionale con la massima qualità è necessaria una notevole quantità di tempo, sforzi e competenze. Gli amministratori di database assumono in genere esperti di database e sviluppatori per gestire e ottimizzare il database.
Le grandi quantità di dati non strutturati non sono adatte per essere gestite dai database relazionali. I database relazionali non sono la scelta migliore per i dati che sono principalmente qualitativi, difficili da descrivere o dinamici, poiché lo schema deve cambiare nel tempo in base alla modifica o allo sviluppo dei dati, il che richiede tempo. Un database non relazionale è più adatto per gestire dati non strutturati.
I database relazionali non sono in grado di scalare orizzontalmente in modo efficace su numerosi server e architetture fisiche di storage. Quando un insieme di dati cresce e diventa più disperso, la struttura viene disturbata e l'utilizzo di numerosi server influisce sulle prestazioni (come i tempi di risposta delle applicazioni) e sulla disponibilità. È difficile gestire i database relazionali su più server.
Quando si codifica un database relazionale, gli utenti devono definire il dominio dei valori potenziali di una colonna di dati e i vincoli. Ad esempio, un dominio di potenziali clienti può consentire fino a 100 nomi di clienti, ma è possibile limitarlo a una tabella per consentire solo dieci nomi di clienti.
È anche importante considerare i vincoli durante la creazione di un database relazionale. L'integrità delle entità è utile per rendere unica la chiave primaria di una tabella e per garantire che il suo valore non sia impostato su null. L'integrità referenziale è necessaria per garantire che ogni valore di una colonna di chiave esterna si trovi nella chiave primaria della tabella originale.
Bisogna anche sapere che, a differenza dei database non relazionali, i database relazionali hanno un'indipendenza fisica dai dati. Il sistema può apportare modifiche allo schema interno senza influenzare gli schemi o le applicazioni esterne. Grazie a questi concetti, è possibile affidarsi a sistemi di gestione di database relazionali come Microsoft Access, Oracle e MySQL per creare database sofisticati con un'esperienza di codifica minima o nulla.
L'obiettivo dei database relazionali standard è quello di consentire agli utenti di gestire e organizzare relazioni di dati predefinite su più database. Al giorno d'oggi, i database relazionali basati su cloud stanno diventando molto popolari perché le organizzazioni sono in grado di esternalizzare processi integrali come la manutenzione del database e il supporto dell'infrastruttura.
Alcuni degli esempi più popolari di database relazionali sono:
MySQL è utilizzato per applicazioni web come Joomla e WordPress.
SQLite è una popolare libreria C utilizzata per incorporare funzionalità di database relazionali nei pacchetti software.
Microsoft Access è una parte molto diffusa della suite Microsoft Office e Microsoft 365. Ha un'interfaccia user-friendly che facilita i principianti nella gestione e nello sviluppo di database relazionali.
PostgreSQL è un sistema di gestione di database relazionali (RDBMS) open-source che si concentra sulla conformità agli standard ANSI SQL e fornisce molte caratteristiche utili come l'estensibilità.
Microsoft Azure SQL, Google Cloud SQL, Amazon Relational Database Service e IBM DB2 on Cloud sono alcuni dei moderni e popolari RDBMS basati su cloud.
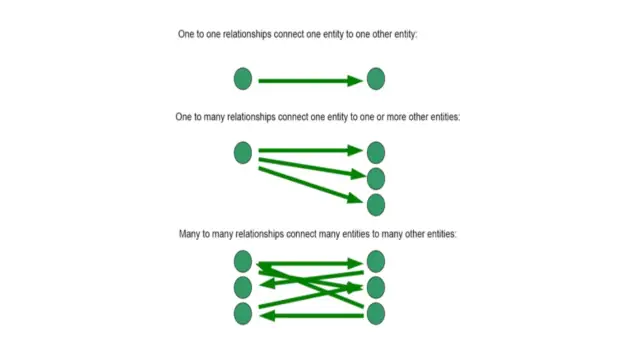
In un database relazionale esistono quattro diversi tipi di relazioni definite. È necessario conoscere queste relazioni per essere in grado di selezionare la relazione corretta e massimizzare l'accuratezza.
Uno a uno
Come suggerisce il nome, in una relazione uno-a-uno, una riga di una tabella è correlata a una sola riga di un'altra tabella.
Da uno a molti
In una relazione uno-a-molti, una riga di informazioni è correlata a molti record in una collezione diversa.
Da molti a uno
È l'opposto della relazione uno-a-molti. In parole più semplici, molte righe di informazioni sono collegate a un record in una relazione molti-a-uno.
Da molti a molti
In una relazione molti-a-molti, una riga di una tabella può essere associata a molte righe di una seconda tabella. Allo stesso modo, una riga della seconda tabella può essere correlata a molte righe della prima tabella.
Quando si crea una connessione, si sceglie un certo tipo di dati per indicare che si desidera che quell'attributo sia specificato da una collezione esistente. Non si tratta di una proprietà tipica in cui si può scegliere un tipo di dati come testo, intero, data o immagine, ad esempio. La possibilità di visualizzare, organizzare e filtrare i dati in modo sensato per l'applicazione dipende dalla corretta impostazione delle connessioni. Uno-a-uno, uno-a-molti e molti-a-molti sono le tre relazioni di base di un database relazionale.
I database relazionali sono utili per organizzare i dati strutturati in formati tabellari con relazioni stabilite. Tuttavia, la scelta della migliore architettura di database va ben oltre la semplice decisione tra modelli relazionali e non relazionali. Le considerazioni principali riguardano il tipo di dati e di applicazioni utilizzate o generate. Scoprite alcuni aspetti aggiuntivi da considerare quando si sceglie un modello di database per un'applicazione aziendale.
La creazione, l'implementazione, l'installazione e la manutenzione di un database relazionale possono essere un processo travolgente, soprattutto se non si ha familiarità con la codifica. La cosa positiva è che esistono piattaforme no-code come AppMaster che consentono di creare potenti backend e database per applicazioni mobili e web. È utile per creare database affidabili, efficienti e sicuri senza preoccuparsi delle proprie capacità di codifica e ottenendo comunque i migliori risultati.
Le piattaforme no-code consentono di creare applicazioni sofisticate senza spendere cifre eccessive per assumere sviluppatori e amministratori di database. Per questo motivo, dovreste dare un'occhiata a piattaforme come AppMaster per beneficiare dei moderni strumenti e tecnologie basati sull'intelligenza artificiale nello sviluppo di applicazioni mobili e nella creazione di database relazionali senza codifica.



Sperimenta con AppMaster con un piano gratuito.
Quando sarai pronto potrai scegliere l'abbonamento appropriato.


