Ekipman rezervasyon uygulaması: çakışmaları önleyin ve iadeleri takip edin
Çifte rezervasyonları önleyen, iadeleri ve hasarları kaydeden, arızalı ekipmanları bakım bekletmesine alan bir ekipman rezervasyon uygulaması planlayın.
Uzun süreli iş akışları karmaşık şekilde başarısız olabilir. Açık durum desenleri, adım bazlı yeniden denemeler, dead-letter işlemleri ve operatörün güvenebileceği panolar öğrenin.
Uzun süreli iş akışları kısa isteklerden farklı şekillerde başarısız olur. Kısa bir API çağrısı ya hemen başarılı olur ya da hemen hata döner. Saatlerce veya günlerce süren bir iş akışı 10 adımdan 9'unu geçse bile işin içinde dağınıklık bırakabilir: yarım kalan kayıtlar, kafa karıştırıcı durumlar ve net bir sonraki eylem olmaması.
Bu yüzden “dün çalışıyordu” cümlesini sık duyarsınız. İş akışı değişmemiştir ama çevresi değişmiştir. Uzun süreli iş akışları diğer servislerin sağlıklı kalmasına, kimlik bilgileri geçerliliğine ve verinin beklenen biçimde kalmasına bağlıdır.
En yaygın hata modları şunlardır: zaman aşımı ve yavaş bağımlılıklar (bir partner API bugün 40 saniye sürebilir), kısmi güncellemeler (A kaydı oluşturuldu, B oluşturulmadı ve güvenle yeniden çalıştırılamıyor), bağımlılık kesintileri (e-posta/SMS sağlayıcıları, ödeme ağ geçitleri, bakım pencereleri), kaybolan geri çağırmalar ve kaçırılan zamanlamalar (webhook gelmedi, zamanlayıcı tetiklenmedi) ve insan adımlarının durması (onay günlerce bekleyip sonra güncellenmiş varsayımlarla devam eder).
Zor olan nokta durumdur. “Hızlı istek” durumu bellekte tutup bitince temizler. Bir iş akışı bunu yapamaz. Adımlar arasında durumu kalıcı hale getirmeli ve yeniden başlatmalar, deploylar veya çökme sonrası kaldığı yerden devam edebilmeli. Ayrıca aynı adımın iki kere tetiklenmesine (yeniden denemeler, yinelenen webhooklar, operatör tekrarları) karşı da dayanıklı olmalıdır.
Pratikte “güvenilir” asla başarısız olmamak değil; tahmin edilebilir, açıklanabilir, kurtarılabilir ve açık sahiplikli olmaktır.
Tahmin edilebilir, bir bağımlılık her başarısız olduğunda iş akışının hep aynı tepkiyi vermesi demektir. Açıklanabilir, bir operatörün bir dakika içinde “Nerede takıldı ve neden?” sorusuna cevap verebilmesidir. Kurtarılabilir, güvenle yeniden denenebilmeyi veya devam edebilmeyi sağlar. Açık sahiplik ise her takılmış öğenin bekle, yeniden dene, veriyi düzelt veya bir kişiye devret gibi belirgin bir sonraki eylemi olmasını sağlar.
Basit bir örnek: bir onboarding otomasyonu müşteri kaydı oluşturur, erişim sağlar ve hoşgeldin mesajı gönderir. Sağlama (provisioning) başarılı ama mesaj gönderme e-posta sağlayıcısı nedeniyle başarısız olursa, güvenilir bir iş akışı “Provisioned, message pending” kaydeder ve yeniden deneme planlar. Sağlamayı körü körüne tekrar çalıştırmaz.
Araçlar bu işi kolaylaştırabilir: iş akışı mantığı ile kalıcı veriyi yakın tutarlar. Örneğin AppMaster ile Data Designer içinde iş akışı durumunu modelleyebilir ve Business Processes üzerinden güncelleyebilirsiniz. Ancak güvenilirlik araçtan çok desendedir: uzun süreli otomasyonu zaman, hatalar ve insan müdahalesine dayanan dayanıklı durumlar serisi olarak ele alın.
Uzun süreli iş akışları tekrarlanabilir şekillerde başarısız olur: üçüncü taraf API yavaşlar, bir insan onaylamamıştır veya bir iş kuyruğun arkasında bekliyordur. Açık durumlar bu durumları bariz kılar, böylece “süre alıyor” ile “bozuldu”yu karıştırmazsınız.
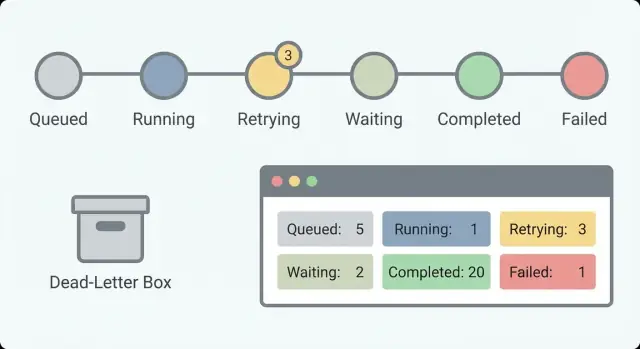
Şu an ne olduğunu cevaplayan küçük bir durum setiyle başlayın. 30 durum varsa kimse hatırlamaz. 5–8 civarı bir set, nöbetçi bir kişinin bir bakışta anlamasını sağlar.
Birçok iş akışı için işe yarayan pratik durum seti:
Waiting ile Running'i ayırmak önemlidir. “Müşteri yanıtını bekliyor” sağlıklıdır. “6 saattir çalışıyor” takılma olabilir. Bu ayrım olmadan yanlış alarmlarla uğraşırsınız ve gerçek sorunları kaçırırsınız.
Sadece bir durum adı yeterli değildir. Durumu eyleme dönüştüren birkaç alan ekleyin:
Örnek: bir onboarding akışı “Waiting” gösterip neden olarak “Pending manager approval” ve son değişiklik “2 gün önce” diyorsa, bunun takılmadığını ama hatırlatma gerekebileceğini gösterir.
Durum adlarını bir API gibi davranarak koruyun. Her ay yeniden adlandırırsanız panolar, alarmlar ve destek oyun kitapları hızla yanıltıcı olur. Yeni bir anlam gerekiyorsa yeni bir durum eklemeyi düşünün ve mevcut kayıtlar için eski durumu bırakın.
AppMaster içinde bu durumları Data Designer ile modelleyip Business Process mantığıyla güncelleyebilirsiniz. Bu, durumun uygulamanızda görünür ve tutarlı kalmasını sağlar; logların içinde kaybolmaz.
Yeniden denemeler gerçek problemi gizlemeye başlayana kadar yardımcıdır. Amaç “hiç başarısız olmamak” değil; “insanların anlayıp düzeltebileceği bir şekilde başarısız olmak”tır. Bu, neyin yeniden denenebilir neyin denenmemesi gerektiği konusunda açık bir kuralla başlar.
Çoğu ekip için kabul edilebilir bir kural: geçici olduğu muhtemel hataları yeniden deneyin (ağ zaman aşımı, rate limit, kısa üçüncü taraf kesintileri). Net olarak kalıcı olan hataları yeniden denemeyin (geçersiz girdi, eksik yetki, “hesap kapalı”, “kart reddedildi”). Hangi grupta olduğundan emin değilseniz, öğrenene kadar yeniden denemez olarak ele alın.
Yeniden deneme sayaçlarını adım başına takip edin, sadece iş akışı için tek bir sayaç tutmayın. Bir iş akışının on adımı olabilir ve sadece biri sorunlu olabilir. Adım düzeyindeki sayaçlar, ilerideki bir adımın önceki bir adımın deneme haklarını “çalmasını” engeller.
Örneğin “Belge yükleme” çağrısı birkaç kez yeniden denenirken, “Hoşgeldin e-postası gönder” işlemi yükleme önceki denemeleri tükettiği için sonsuza kadar denememelidir.
Riske uygun bir backoff deseni seçin. Basit, düşük maliyetli yeniden denemeler için sabit gecikmeler yeterli olabilir. Rate limit ile karşılaşılabilecek durumlar için üstel backoff faydalıdır. Beklemelerin kontrolsüz büyümesini önlemek için bir üst sınır ve retry stormları önlemek için biraz jitter ekleyin.
Sonra ne zaman duracağınızı belirleyin. İyi durdurma koşulları açıktır: maksimum deneme sayısı, maksimum toplam süre veya belirli hata kodları için derhal vazgeçme. Ödeme ağ geçidi “geçersiz kart” döndürürse, normalde 5 deneme izin veriyor olsanız bile hemen durulmalıdır.
Operatörlerin ne olacağını bilmesi gerekir. Bir sonraki yeniden deneme zamanını ve nedeni kaydedin (ör. “Deneme 3/5 saat 14:32, neden: zaman aşımı”). AppMaster’da bunu iş akışı kaydına saklayarak bir pano “ne zamana kadar bekleniyor” bilgisini tahmin etmeye gerek kalmadan gösterebilir.
İyi bir yeniden deneme politikası iz bırakır: ne başarısız oldu, kaç kez denendi, ne zaman yeniden denenecek ve ne zaman durup dead-letter işlemine devredilecek.
Saatler veya günler süren iş akışlarında yeniden denemeler normaldir. Risk, zaten başarılı olmuş bir adımı tekrar etmektir. İdempotentlik, bir adımın iki kere çalıştırılmasının bir kere çalıştırmakla aynı etkiye sahip olması kuralıdır.
Klasik bir hata: kartı tahsil edersiniz ama iş akışı “ödeme başarılı” bilgisini kaydetmeden çökebilir. Yeniden denemede tekrar tahsil edilir. Bu, dış dünyanın değişip iş akışı durumunun değişmemesiyle oluşan çift yazma problemidir.
En güvenli desen, her yan etki yaratan adım için sabit bir idempotentlik anahtarı oluşturmaktır, bunu dış çağrı ile gönderin ve sonucu geri alır almaz adım sonucunu kaydedin. Birçok ödeme sağlayıcı ve webhook alıcısı idempotency anahtarlarını destekler (örneğin bir OrderID ile siparişi tahsil etmek). Adım tekrarlandığında sağlayıcı orijinal sonucu döndürür ve eylemi tekrar yapmaz.
İş akışı motorunuz içinde her adımın yeniden oynatılabileceğini varsayın. AppMaster’da bu genellikle adım çıktılarının veri tabanında saklanması ve Business Process içinde entegrasyon çağrısı yapmadan önce bunların kontrol edilmesi anlamına gelir. Eğer “Hoşgeldin e-postası gönderildi” alanında zaten bir MessageID kayıtlıysa, yeniden deneme bu kaydı kullanıp devam etmelidir.
Pratik, tekrar güvenli yaklaşım:
Giriş webhookları veya kullanıcıların aynı düğmeye iki kere basması gibi durumlarda yinelemeler hâlâ olur. Olay türüne göre politika belirleyin: tam kopyaları yok sayın (aynı idempotency anahtarı), uyumlu güncellemeleri birleştirin (ör. profil alanı için son yazma kazanır) veya para ya da uyumluluk riski varsa inceleme için işaretleyin.
Dead-letter, başarısız olup normal yoldan çıkarılan ve her şeyi bloklamaması için kasıtlı olarak saklanan iş akışı öğesidir. Amaç, ne olduğu kolayca anlaşılacak, onarılıp güvenle yeniden işlenebilecek şekilde saklamaktır.
En büyük hata sadece bir hata mesajı saklamaktır. Dead-letter sonrasında bakan kişi problemi yeniden üretmek için tahmin yapmak zorunda kalmamalı.
Kullanışlı bir dead-letter girdisi şunları içerir:
Sınıflandırma dead-letterları eyleme geçilebilir kılar. Kısa bir kategori operatörün doğru sonraki adımı seçmesini sağlar. Yaygın gruplar: kalıcı hata (iş mantığı, geçersiz durum), veri sorunu (eksik alan, kötü format), bağımlılık kesintisi (zaman aşımı, rate limit, outage) ve auth/izin (süresi dolmuş token, reddedilmiş kimlik).
Yeniden işleme kontrollü olmalıdır. Amaç iki kere tahsil etmek veya spam göndermek gibi tekrar eden zararlardan kaçınmaktır. Kim yeniden deneyebilir, ne zaman yeniden denenir, ne değiştirilebilir (belirli alanlar düzenlenebilir, eksik belge eklenebilir, token yenilenebilir) ve ne sabit kalmalıdır (istek ID ve aşağı taraf idempotency anahtarları) gibi kurallar tanımlayın.
Dead-letter öğelerini sabit tanımlayıcılarla aranabilir yapın. Bir operatör “sipariş 18422” yazdığında tam adımı, girdileri ve deneme geçmişini görebiliyorsa onarım hızlı ve tutarlı olur.
AppMaster içinde bunu kuruyorsanız, dead-letter'ı birinci sınıf bir veri modeli olarak ele alın ve durum, denemeler ve tanımlayıcıları alanlar olarak saklayın. Böylece dahili panonuz sorgulayabilir, filtreleyebilir ve kontrollü yeniden işleme tetikleyebilir.
Uzun süreli iş akışları yavaş, kafa karıştırıcı şekilde başarısız olabilir: bir adım e-posta cevabını bekliyor, bir ödeme sağlayıcısı zaman aşımı veriyor veya bir webhook iki kez geliyor. İş akışının şu an ne yaptığını göremezseniz tahmin yürütürsünüz. İyi görünürlük “bozuldu”yu net cevaba çevirir: hangi iş akışı, hangi adım, hangi durum ve ne yapmak gerekiyor.
Her adımın aynı küçük alan setini yaymasını sağlayarak başlayın, böylece operatörler hızlıca tarayabilir:
Bu alanlar genel durumun hızlı sayımlarını sağlar. Uzun süreli iş akışlarında tekil hatalardan çok sayılar önemlidir çünkü eğilimlere bakarsınız: iş birikmesi, yeniden deneme patlaması veya hiç bitmeyen beklemeler.
Başlatılan, tamamlanan, başarısız olan, yeniden deneniyor olan ve bekleyenleri zaman içinde takip edin. Küçük bir bekleme sayısı normal olabilir (insan onayları). Artan bekleme sayısı genellikle bir şeyin bloklandığını gösterir. Artan yeniden deneme sayısı ise genelde bir sağlayıcı sorunu veya aynı hatayı üreten bir bug işaretidir.
Alarmlar operatörün deneyimiyle eşleşmelidir. “Hata oluştu” yerine semptomlara alarm verin: artan birikim (başlatılan eksi tamamlanan sürekli artıyorsa), beklenenden uzun süredir beklemede olan çok sayıda iş, belirli bir adım için yüksek yeniden deneme oranı veya bir sürüm/config değişikliği sonrası hata sıçraması.
Her iş akışı için olay izini saklayın ki “ne oldu?” bir görünümde yanıtlanabilsin. Yararlı bir iz; zaman damgaları, durum geçişleri, girdiler ve çıktılardan özetler (tam hassas payloadlar değil) ve yeniden deneme veya hata nedenlerinin kısa açıklamasını içerir. Örnek: “Kart tahsil: deneme 3/5, sağlayıcıdan zaman aşımı, sonraki deneme 10dk sonra.”
Korelasyon ID'leri yapıştırıcı gibidir. Bir müşteri “ödeme iki kez çekildi” dediğinde, iş akışı olaylarını ödeme sağlayıcısının charge ID'si ve dahili sipariş ID'niz ile bağlamanız gerekir. AppMaster'da Business Process mantığında korelasyon ID'leri üreterek ve API çağrılarında ileterek pano ve logların hizalanmasını sağlayabilirsiniz.
Bir iş akışı saatlerce veya günlerce çalıştığında hatalar normaldir. Normal hatayı kesintiye dönüştüren şey, sadece “Failed” diyen ve başka şey söylemeyen bir panodur. Amaç, bir operatörün hızlıca üç soruyu cevaplayabilmesidir: ne oluyor, neden oluyor ve güvenle ne yapabilir?
İş akışı listesini önemli öğeleri bulmayı kolaylaştıracak şekilde başlatın. Filtreler panik ve gereksiz iletiyi azaltır çünkü herkes görünümü kolayca daraltabilir.
Faydalı filtreler: durum, yaş (başlama zamanı ve mevcut durumda geçen süre), sahip (takım/müşteri/sorumlu operatör), tür (iş akışı adı/versiyonu) ve müşteri odaklı adımlarınız varsa öncelik.
Sonra durumu yanında “neden”i gösterin, logların içinde saklamak yerine. Bir durum göstergesi ancak son hata mesajı, kısa hata kategorisi ve sistemin bir sonraki planı ile eşleştirildiğinde işe yarar. İki alan çoğu işi görür: son hata ve sonraki deneme zamanı. Eğer sonraki deneme boşsa, işin insan beklediğini, duraklatıldığını veya kalıcı olarak başarısız olduğunu açıkça gösterin.
Operatör eylemleri varsayılan olarak güvenli olmalı. İnsanları düşük riskli eylemlere yönlendirin ve riskli eylemleri açıkça belirtin:
“Zorla devam et” en çok zararın olduğu yerdir. Eğer sunuyorsanız, riski sade dille yazın: “Bu ödeme doğrulamasını atlar ve ödenmemiş bir sipariş oluşturabilir.” Ayrıca ilerlerse hangi verilerin yazılacağını gösterin.
Operatörlerin yaptığı her şeyi denetleyin. Kim, ne zaman, önce/sonra durum ve gerekçe notunu kaydedin. AppMaster’da dahili araçlar oluşturuyorsanız bu denetim izini birinci sınıf tablo olarak saklayın ve iş akışı detay sayfasında gösterin ki devir teslimler temiz olsun.
Bu desen iş akışlarını tahmin edilebilir kılar: her öğe her zaman net bir durumda, her hata için bir hedef yer vardır ve operatörler tahminde bulunmadan hareket edebilir.
Adım 1: Durumları ve izin verilen geçişleri tanımlayın. İnsanların anlayacağı küçük bir durum seti yazın (ör. Queued, Running, Waiting on external, Succeeded, Failed, Dead-letter). Ardından hangi geçişlerin yasal olduğunu kararlaştırın ki iş limboya kaymasın.
Adım 2: İşleri temiz girdiler ve çıktılarla küçük adımlara bölün. Her adım bir iyi tanımlanmış girdi almalı ve bir çıktı (veya açık bir hata) üretmelidir. İnsan kararı veya dış API çağrısı gerekiyorsa, bunu ayrı bir adım yapın ki duraklayıp temiz devam edebilsin.
Adım 3: Her adım için bir yeniden deneme politikası ekleyin. Deneme limiti, denemeler arası gecikme ve asla yeniden denememesi gereken sebep(ler)i belirleyin (geçersiz veri, izin reddi, eksik alan). Operatörlerin tam olarak neyin takılı olduğunu görmesi için her adımda bir yeniden deneme sayacı saklayın.
Adım 4: Her adımdan sonra ilerlemeyi kalıcı hale getirin. Bir adım bittiğinde yeni durumu ve ana çıktıları kaydedin. Süreç yeniden başlarsa son tamamlanan adımdan devam etmeli, yeniden baştan başlamamalıdır.
Adım 5: Yeniden denemeler tükendiğinde dead-letter kaydına yönlendirin ve yeniden işlemeyi destekleyin. Dead-letter’a taşındığında tam bağlamı saklayın: girdiler, son hata, adım adı, deneme sayısı ve zaman damgaları. Yeniden işleme kasıtlı olmalı: önce veriyi veya konfigürasyonu düzeltin, sonra belirli bir adımdan yeniden kuyruklayın.
Adım 6: Pano alanlarını ve operatör eylemlerini tanımlayın. İyi bir pano “ne başarısız oldu, nerede ve ne yapabilirim?” sorusunu cevaplar. AppMaster’da bunu iş akışı tablolarıyla desteklenen basit bir admin web uygulaması olarak oluşturabilirsiniz.
Dahil edilmesi gereken temel alanlar ve eylemler:
Çalışan işe alımı iyi bir stres testi olur. Onaylar, dış sistemler ve çevrimdışı insanlar karışır. Basit bir akış: IK yeni çalışan formu gönderir, yönetici onaylar, IT hesaplar oluşturur ve yeni çalışana hoşgeldin mesajı gider.
Durumları okunabilir yapın. Birisi kaydı açtığında “Yönetici onayı bekleniyor” ile “Hesap kurulumu yeniden deneniyor” arasındaki farkı hemen görmelidir. Bir satırlık açıklık saatlerce süren tahmin yürütmeyi kurtarabilir.
UI’de gösterilecek net durum seti örneği:
Ağlara veya üçüncü taraf APIlarına bağlı adımlar yeniden denemeye uygun olmalıdır. Hesap sağlama (e-posta, SSO, Slack), e-posta/SMS gönderimi ve dahili API çağrıları iyi yeniden deneme adaylarıdır. Yeniden deneme sayacını görünür tutun ve bunu bir üst sınırla sınırlayın (ör. en fazla 5 deneme, artan gecikmelerle, sonra dur).
Dead-letter işlemleri kendi başına düzelmeyecek sorunlar içindir: yönetici eksik, geçersiz e-posta veya politika ile çakışan erişim isteği. Bir çalıştırmayı dead-letter’a gönderirken; hangi alanın doğrulamada başarısız olduğu, son API yanıtı ve bir geçersiz kısıtlamayı aşabilecek kişinin kim olduğu gibi bağlamı saklayın.
Operatörlerin küçük ve net eylem seti olmalı: veriyi düzelt (yönetici ekle, e-postayı düzelt), başarısız tek adımı yeniden çalıştır (tüm iş akışını değil) veya temiz iptal et (ve gerekiyorsa kısmi kurulumları geri al).
AppMaster ile bunu Business Process Editor'de modelleyebilir, yeniden deneme sayaçlarını veri içinde tutabilir ve operatör ekranını web UI builder ile oluşturup durum, son hata ve başarısız adımı yeniden dene butonunu gösterebilirsiniz.
Çoğu güvenilirlik problemi öngörülebilir: bir adım iki kez çalışır, yeniden denemeler gece 2'de dolanır veya “takılmış” bir öğenin son ne yaptığına dair hiçbir ipucu yoktur. Bir kontrol listesi bunu tahmin olmaktan çıkarır.
Erken yakalayan kısa kontroller:
Eğer sadece bir şeyi iyileştirebiliyorsanız, görünürlüğü iyileştirin. Birçok “iş akışı hatası” aslında “ne yaptığını göremiyoruz” problemidir. Panonuz son ne olduğunu, bir sonraki adımda ne olacağını ve ne zaman olacağını göstermeli.
Pratik bir operatör görünümü; mevcut durum, son hata mesajı, deneme sayısı, sonraki deneme zamanı ve bir net eylem (şimdi yeniden dene, çözüldü olarak işaretle veya elle incelemeye gönder) içermelidir. Eylemler varsayılan olarak güvenli olsun: tek adımı yeniden çalıştırın, tüm iş akışını değil.
Sonraki adımlar:
Bunu yaşayan bir kontrol listesi olarak ele alın. Yeni bir adım eklediğinizde üretime geçmeden önce bu kontrolleri çalıştırın.
Uzun süren iş akışları saatlerce başarılı çalışıp sonunda başarısız olabilir ve kısmi değişiklikler bırakabilir. Ayrıca çalışırken üçüncü tarafların erişilebilirliği, kimlik bilgileri, veri biçimi ve insan yanıt süreleri gibi dış etkenlere bağımlıdırlar.
Operatörün kolayca anlayabileceği küçük ve okunabilir bir durum seti tutun. İyi bir varsayılan: queued, running, waiting, succeeded ve failed. “Waiting” ile “running”i ayırmak, sağlıklı beklemeler ile takılmaları ayırt etmenizi sağlar.
Durumu eyleme dönüştüren bilgileri saklayın: o anki durum, son değişiklik zamanı, önceki durum ve bekleme/başarısızlık için kısa bir neden. Yeniden deneme varsa, görünmez tahminlere yol açmamak için deneme sayısını ve planlanan sonraki deneme zamanını da saklayın.
Yanlış alarmları ve kaçırılan olayları önler. “Yönetici onayı bekleniyor” sağlıklı olabilir; “altı saattir çalışıyor” ise takılma göstergesidir. Bunları ayrı tutmak uyarıları ve operasyonel kararları iyileştirir.
Geçici olduğu muhtemel hataları (zaman aşımı, rate limit, kısa üçüncü taraf kesintileri) yeniden deneyin. Geçerli olmayan girdi, yetki eksikliği veya reddedilen kart gibi kalıcı hataları yeniden denemeyin—tekrarlamak sadece zarar verir.
Adım düzeyinde izlenen denemeler, tek bir aksi iyi olmayan entegrasyonun tüm iş akışının deneme kotasını tüketmesini engeller. Bu ayrıca hangi adımın başarısız olduğunu ve ne kadar denendiğini daha net gösterir.
Risk seviyesine uygun basit bir backoff seçin ve beklemelerin sınırsız büyümesini önlemek için bir üst sınır koyun. Durdurma kurallarını açıkça belirleyin (maksimum deneme sayısı, toplam maksimum süre vb.) ve başarısızlık nedenini ile planlanan sonraki denemeyi kaydedin.
Her adımın tekrar çalıştırılabileceğini varsayın. Yan etki yaratan bir adım iki kez çalışırsa zarar görmemesi için idempotentlik anahtarı kullanın, “adım başlatıldı” kaydı yazın ve başarı sonrası dış sağlayıcı yanıtını hemen saklayın. Yeniden denemede saklanan sonucu tekrar kullanın.
Dead-letter, normal akıştan kasıtlı olarak çıkartılmış ve diğer öğeleri engellememesi için saklanan başarısız bir öğedir. Tekrar işleme öncesi problemi yeniden üretmek için yeterli bağlam olmalıdır: kimlikler, orijinal girdiler veya güvenli bir anlık görüntü, başarısız olan adım, deneme geçmişi ve bağımlı servis yanıtı gibi bilgiler.
En çabuk kullanılabilen panolar; nerede olduğunu, neden orada olduğunu ve bir sonraki adımın ne olacağını gösterir. Tutarlı alanlar: workflow ID, mevcut adım, durum, o durumdaki süre, son hata ve korelasyon kimlikleri. Operatörlere varsayılan olarak güvenli eylemler verin (tek adımı yeniden dene, duraklat/devam et) ve riskli eylemleri açıkça etiketleyin.



Ücretsiz planla AppMaster ile denemeler yapın.
Hazır olduğunuzda uygun aboneliği seçebilirsiniz.


