Ekipman rezervasyon uygulaması: çakışmaları önleyin ve iadeleri takip edin
Çifte rezervasyonları önleyen, iadeleri ve hasarları kaydeden, arızalı ekipmanları bakım bekletmesine alan bir ekipman rezervasyon uygulaması planlayın.
SLA zamanlayıcılarını ve eskalasyonlarını, açık durumlar, bakımı kolay kurallar ve basit eskalasyon yolları ile nasıl modelleyeceğinizi öğrenin; böylece iş akışı uygulamaları kolayca değiştirilebilir kalır.
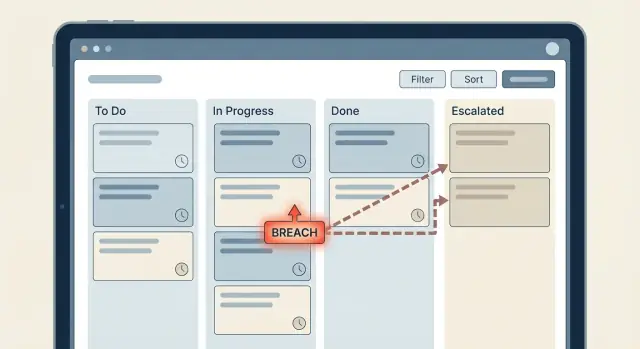
Zaman tabanlı kurallar genellikle basit başlar: “Eğer bir bilete 2 saat içinde cevap verilmezse birini bilgilendir.” Sonra iş akışı büyür, ekipler istisnalar ekler ve birdenbire kimse ne olduğundan emin olmaz. SLA zamanlayıcıları ve eskalasyonlar böylece bir labirente dönüşür.
Hareketli parçaları net isimlendirmek yardımcı olur.
Bir zamanlayıcı bir olaydan sonra başlattığınız (veya planladığınız) saattir, örneğin “bilet Bekliyor - Temsilci durumuna taşındı.” Bir eskalasyon o saatin bir eşiği vurduğunda yaptığınızdır: bir lideri bildirmek, önceliği değiştirmek veya işi yeniden atamak gibi. Bir ihlal ise “SLA kaçırıldı” diyen kaydedilmiş bir gerçektir; raporlama, uyarılar ve takibi için kullanırsınız.
Zaman mantığı uygulama boyunca dağılırsa sorunlar ortaya çıkar: birkaç kontrol “bileti güncelle” akışında, daha fazlası gece çalışan bir işte ve daha sonra özel bir müşteri için eklenen tek seferlik kurallar. Her parça tek başına mantıklı görünür, ama birlikte sürprizler yaratırlar.
Tipik belirtiler:
Amaç, sonradan değiştirmesi kolay kalan öngörülebilir davranıştır: SLA zamanlaması için tek bir açık gerçek kaynağı, raporlayabileceğiniz açık ihlal durumları ve görsel mantıkta avlanma yapmadan ayarlayabileceğiniz eskalasyon adımları.
Herhangi bir zamanlayıcı inşa etmeden önce ölçtüğünüz tam taahhüdü yazın. Karışık mantığın çoğu, baştan her olası zaman kuralını karşılamaya çalışmaktan gelir.
Yaygın SLA türleri benzer ses çıkarsa da farklı şeyleri ölçer:
Sonra “zaman”ın ne anlama geldiğine karar verin. Takvim zamanı 7/24 sayar. Çalışma zamanı yalnızca tanımlı mesai saatlerini sayar (örneğin Pzt-Cuma, 9-18). Gerçekten çalışma zamanına ihtiyacınız yoksa başta ondan kaçının. Tatiller, saat dilimleri ve kısmi günler gibi kenar durumlar ekler.
Ardından duraklamalar hakkında ayrıntı verin. Bir duraklama sadece “durum değişti” değildir. Sahibi olan bir kuraldır. Kim duraklatabilir (sadece temsilci, sadece sistem, müşteri eylemi)? Hangi durumlar duraklatır (Waiting on Customer, On Hold, Pending Approval)? Ne tekrar başlatır? Yeniden başlatıldığında kalan süreden mi devam edilir yoksa zamanlayıcı mı yeniden başlar?
Son olarak, bir ihlal ürün terimleriyle ne anlama geliyor tanımlayın. Bir ihlal saklanıp sorgulanabilecek somut bir şey olmalıdır, örneğin:
Örnek: “İlk yanıt SLA'sı ihlal edildi” demek biletin Breached durumuna geçmesi, breached_at zaman damgasının yazılması ve eskalasyon seviyesinin 1 olarak ayarlanması anlamına gelebilir.
SLA zamanlayıcılarının ve eskalasyonlarının okunabilir kalmasını istiyorsanız, SLA'yı küçük bir durum makinası gibi ele alın. “Gerçek” küçük kontrollerle (şimdi > due, priority yüksekse, son cevap boşsa gibi) dağıtıldığında, görsel mantık hızla karışır ve küçük değişiklikler işleri bozar.
Herkesin anlayacağı kısa, üzerinde anlaşılmış bir SLA durum kümesiyle başlayın. Birçok ekip için bunlar çoğu durumu kapsar:
Tek bir breached = true/false bayrağı nadiren yeterlidir. Hangi SLA'nın ihlal olduğunu (ilk yanıt mı çözüm mü), şu an durakta olup olmadığını ve zaten eskale edilip edilmediğini bilmeniz gerekir. Bu bağlam olmadan insanlar anlamı yorumlamak için yorumlara, zaman damgalarına ve durum adlarına bakmaya başlar; mantık kırılganlaşır.
Durumu açıkça yapın ve onu açıklayan zaman damgalarını saklayın. Kararlar basit kalır: değerlendiriciniz kaydı okur, bir sonraki durumu belirler ve her şey o duruma göre tepki verir.
Saklanması yararlı alanlar:
started_at ve due_at (hangi saat çalışıyor ve ne zaman vadesi var?)breached_at (gerçekte ne zaman aşıldı?)paused_at ve paused_reason (saat neden durdu?)breach_reason (hangi kural ihlali tetikledi, düz metinle)last_escalation_level (aynı seviyeye tekrar bildirim göndermemek için)Örnek: bir bilet “Waiting on customer” durumuna geçerse. SLA durumunu Paused olarak ayarlayın, paused_reason = "waiting_on_customer" kaydedin ve sayacı durdurun. Müşteri yanıt verdiğinde devam etmek için yeni bir started_at ayarlayın (veya pause'u kaldırıp due_at'ı yeniden hesaplayın). Birçok koşulda avlanmaya gerek kalmaz.
Eskalasyon merdiveni, bir SLA sayacı yakınsak veya ihlal olduğunda ne olacağına dair net bir plandır. Hata, organizasyon şemasını olduğu gibi iş akışına kopyalamaktır. Amacınız, tıkanmış bir öğeyi yeniden hareket ettirecek en küçük adım kümesidir.
Birçok ekip için basit bir merdiven: atanmış temsilci (Seviye 0) ilk bildirim alır, sonra takım lideri (Seviye 1) müdahil olur ve sadece bundan sonra yöneticiye (Seviye 2) gider. Bu işe yapılabilecek kişinin yanından başlayıp yalnızca gerektiğinde yetkiyi yükselttiği için işe yarar.
İş akışı eskalasyon kurallarının korunabilir kalması için, eskalasyon eşiklerini kod içinde donmuş koşullar olarak değil veri olarak saklayın. Onları bir tabloya veya ayarlar nesnesine koyun: “ilk hatırlatma 30 dakika sonra” veya “2 saat sonra lead'e eskale et”. Politika değiştiğinde tek bir yeri güncellersiniz, birden fazla akışı düzenlemezsiniz.
Eskalasyonlar çok sık tetiklendiğinde spam olur. Her adımın amacı olmasını sağlayacak korunmalar ekleyin:
Sadece bildirimler tıkalı işi çözmezse sorumluluk belirsiz kalır. Önden kimin sahibi olacağına karar verin: bilet temsilciye mi kalır, lider’e mi atanır yoksa paylaşılan bir kuyruğa mı gider?
Örnek: Seviye 1 eskalasyondan sonra, bileti takım liderine atayın ve orijinal temsilciyi izleyici (watcher) yapın. Bu bir sonraki kimin işlem yapması gerektiğini açıkça gösterir ve aynı öğenin insanlara gidip gelmesini engeller.
SLA zamanlayıcılarını ve eskalasyonlarını bakımı kolay tutmanın en kolay yolu bunları üç parçalı küçük bir sistem gibi ele almaktır: olaylar, bir değerlendirici ve eylemler. Bu, zaman mantığının onlarca “eğer zaman > X” kontrolüne yayılmasını engeller.
Olaylar zaman hesabı içermemeli. Bunlar “ne değişti?” sorusunu cevaplar, “bu konuda ne yapmalıyız?” değil. Tipik olaylar: bilet oluşturuldu, temsilci cevap verdi, müşteri cevap verdi, durum değişti veya manuel duraklatma/devam.
Bunları zaman damgaları ve durum alanları olarak saklayın (örneğin: created_at, last_agent_reply_at, last_customer_reply_at, status, paused_at).
Her olaydan sonra ve periyodik olarak çalışan tek bir “SLA değerlendirici” adımı yapın. Bu değerlendirici due_at ve kalan zamanı hesaplayan tek yerdir. Mevcut gerçekleri okur, son tarihleri yeniden hesaplar ve sla_response_state ve sla_resolution_state gibi açık SLA durum alanlarını yazar.
İşte ihlal durumu modellemesi temiz kalır: değerlendirici OK, AtRisk, Breached gibi durumları ayarlar, mantığı bildirimlerin içine saklamaz.
Bildirimler, atamalar ve eskalasyonlar yalnızca bir durum değiştiğinde tetiklenmelidir (örneğin: OK -> AtRisk). Mesaj göndermeyi SLA durumunu güncellemeden ayrı tutun. Böylece kim bildirilecekse onu değiştirmek için hesaplamalara dokunmanız gerekmez.
Bakımı kolay bir kurulum genelde şöyle görünür: kaydın üzerinde birkaç alan, küçük bir politika tablosu ve ne olacağına karar veren bir değerlendirici.
SLA'ya sahip olan varlıkla başlayın (bilet, sipariş, talep). Açık zaman damgaları ve tek bir “mevcut SLA durumu” alanı ekleyin. Sıkıcı ve tahmin edilebilir tutun.
Sonra kuralları sabit akışlara gömmek yerine tanımlayan küçük bir politika tablosu ekleyin. Basit versiyon: her öncelik için bir satır (P1, P2, P3) ve hedef dakikalar ile eskalasyon eşikleri sütunları (örneğin: %80'de uyarı, %100'de ihlal). Bu, bir kaydı değiştirmek ile beş akışı düzenlemek arasındaki farktır.
Her yerde ayrı zamanlayıcılar oluşturmak yerine, kayıtları periyodik olarak kontrol eden tek bir planlı işlem kullanın (katı SLA'lar için her dakika, birçok ekip için her 5 dakika). Planlayıcı şunu yapar:
sla_state ve next_check_at alanlarını yazarBu, SLA zamanlayıcılarını ve eskalasyonları akıl yürütmeyi kolaylaştırır çünkü bir değerlendiriciyi debug edersiniz, onlarca zamanlayıcıyı değil.
Değerlendirici hem yeni durumu hem de değişip değişmediğini çıktılar. Yalnızca durum hareket ettiğinde mesaj veya görev yaratılsın (örneğin ok -> warning, warning -> breached). Kayıt bir saat boyunca breached halinde kalsa, 12 tekrar bildirim almak istemezsiniz.
Pratik desen: sla_state ve last_escalation_level saklayın, bunları yeni hesaplanan değerlerle karşılaştırın ve yalnızca sonra mesajlaşma (email/SMS/Telegram) veya dahili görev oluşturma çağrısı yapın.
Duraklamalar zaman kurallarının genellikle karıştığı yerdir. Bunları net modellemezseniz, SLA ya çalışmaya devam eder ya da biri yanlışlıkla durumu tıklayınca sıfırlanır.
Basit bir kural: saati durduran tek bir durum (veya küçük bir set) olsun. Yaygın seçim Waiting for customer'dır. Bir bilet o duruma girince pause_started_at zaman damgası kaydedin. Müşteri yanıtlayıp durumdan çıkınca pause_ended_at yazıp sürenin paused_total_seconds'ına ekleyin.
Tek bir sayaç tutmayın. Her duraklama penceresini (başlangıç, bitiş, tetikleyen kim/neyse) yakalayın ki denetim izi olsun. Sonradan “neden bir vaka ihlal oldu” diye sorulduğunda, 19 saat müşteri beklemesinde olduğunu gösterebilirsiniz.
Yeniden atama ve normal durum değişiklikleri saati yeniden başlatmamalıdır. SLA zaman damgalarını sahiplik alanlarından ayrı tutun. Örneğin sla_started_at ve sla_due_at oluşturulurken (veya SLA politikası değiştiğinde) bir kez ayarlansın; yeniden atama yalnızca assignee_id güncellesin. Değerlendiriciniz sonra geçen süreyi şöyle hesaplayabilir: now - sla_started_at - paused_total_seconds.
SLA zamanlayıcılarını ve eskalasyonlarını öngörülebilir tutacak kurallar:
Tasarımınızı test etmenin basit yolu: ilk yanıtta 30 dakika ve tam çözümde 8 saat olan iki SLA'lı bir destek bileti. Mantık ekranlar ve butonlar arasında dağılırsa burada bozulur.
Varsayalım her bilet şunları saklıyor: state (New, InProgress, WaitingOnCustomer, Resolved), response_status (Pending, Warning, Breached, Met), resolution_status (Pending, Warning, Breached, Met) ve created_at, first_agent_reply_at, resolved_at gibi zaman damgaları.
Gerçekçi bir zaman çizelgesi:
Eskalasyonlar için durum geçişlerinde tetiklenen tek bir zincir tutun. Örneğin, response Warning olduğunda atanmış temsilciyi bilgilendirin. Breached olduğunda takım liderini bilgilendirin ve önceliği güncelleyin.
Her adımda aynı küçük alan setini güncelleyin ki üzerinde düşünmesi kolay olsun:
response_status veya resolution_status'u Pending, Warning, Breached veya Met olarak ayarlayın.*_warning_at ve *_breach_at zaman damgalarını bir kez yazın, sonra üzerine yazmayın.escalation_level (0, 1, 2) arttırın ve escalated_to (Agent, Lead, Manager) ayarlayın.sla_events log satırı ekleyin.priority ve due_at ayarlayın.Önemli nokta Warning ve Breached'in açık durumlar olmasıdır. Veride görünürler, denetlenebilir ve eskalasyon merdivenini daha sonra saklı zaman hesaplarını aramadan değiştirebilirsiniz.
SLA mantığı yayıldığında işler karışır. Bir butona eklenen hızlı bir zaman kontrolü burada, bir API işlemcisinde bir koşul orada ve kısa sürede kimse bir biletin neden eskale edildiğini açıklayamaz. SLA zamanlayıcılarını ve eskalasyonlarını küçük, merkezi bir mantık parçası olarak tutun; her ekran ve aksiyon buna dayansın.
Yaygın bir tuzak, zaman kontrollerini birçok yere gömmektir (UI ekranları, API handler'lar, manuel eylemler). Onarımı: SLA durumunu bir değerlendiricide hesaplayın ve sonucu kaydedin. Ekranlar durumu okumalı, tekrar icat etmemeli.
Başka bir tuzak, farklı saatleri kullanıp zamanlayıcıların uyuşmamasıdır. Tarayıcı “oluşturulandan beri dakika” hesaplarken backend sunucu zamanını kullanıyorsa uyku, saat dilimleri ve yaz-kış saati değişiklikleri etrafında kenar vakalar görürsünüz. Eskalasyon tetikleyen her şey için sunucu zamanını tercih edin.
Bildirimler de hızla gürültülü olabilir. “Her dakika kontrol et ve gecikmişse gönder” derseniz insanlar her dakika spam alabilir. Mesajları geçişlere bağlayın: “uyarı gönderildi”, “eskale edildi”, “ihlal oldu”. Böylece her adım için bir kez gönderir ve neler olduğunu denetleyebilirsiniz.
İş saatleri mantığı da kazara karmaşıklık kaynağıdır. Her kuralın kendi "eğer hafta sonu ise…" dalı olursa güncellemeler acı verici olur. İş-saatleri hesabını tek bir fonksiyona (veya paylaşılan bloğa) koyun: “şimdiye kadar tüketilen SLA dakika sayısını döndüren” ve bunu yeniden kullanın.
Son olarak, ihlali sıfırdan yeniden hesaplamaya güvenmeyin. İhlalin gerçekleştiği anı saklayın:
breached_at'ı kaydedin ve üzerine yazmayın.escalation_level ve last_escalated_at'ı saklayın ki eylemler idempotent olsun.notified_warning_at gibi alanlar saklayın.Örnek: bir bilet “Response SLA breached” oldu ve zamanı 10:07 idi. Sadece yeniden hesaplamaya dayanan bir yaklaşım daha sonra bir durum değişikliği veya duraklama/yeniden başlatma hatası yüzünden ihlali 10:42 olarak gösterebilir. breached_at = 10:07 ile raporlama ve sonrasındaki incelemeler tutarlı kalır.
Zamanlayıcılar ve uyarılar eklemeden önce, kuralları bir ay sonra okunabilir yapma hedefiyle bir kez gözden geçirin.
now - created_at > X doğru olduğunda değil.Pratik bir test: breşinge yakın bir bilet seçin ve zaman çizelgesini tekrar oynatın. Her durum değişikliğinde ne olacağını iş akışını tamamen okumadan açıklayamıyorsanız, modeliniz çok dağınıktır.
En küçük işe yarar parçayı önce inşa edin. Bir SLA seçin (örneğin ilk yanıt) ve bir eskalasyon seviyesi (örneğin takım liderini bildir) ile başlayın. Bir haftalık gerçek kullanım, kusursuz bir tasarımdan daha fazla şey öğretecektir.
Eşikleri ve alıcıları mantık yerine veri tutun. Dakikalar ve saatler, iş-saatleri kuralları, kim bildirilir ve hangi kuyuğun vakayı sahiplenmesi gerektiği tablo veya konfig kayıtlarında olsun. Böylece iş akışı sabit kalırken iş gerekleri sayıları ve yönlendirmeyi değiştirebilir.
Erken bir gösterge panosu görünümü planlayın. Büyük bir analiz sistemine ihtiyacınız yok; şu an ne olduğunu gösteren paylaşılan bir tablo yeter: on track, warning, breached, escalated.
Eğer bunu bir kodsuz iş akışı uygulamasında kuruyorsanız, veri modelleme, mantık ve planlı değerlendiricileri tek yerde modellemenizi sağlayan bir platform seçmek yardımcı olur. Örneğin, AppMaster (appmaster.io) veri tabanı modelleme, görsel iş süreçleri ve üretime hazır uygulama üretimini destekler; bu "olaylar, değerlendirici, eylemler" desenine iyi uyar.
Güvenli şekilde yineleyerek iyileştirme sırası:
Hazır olduğunuzda önce küçük bir versiyon inşa edin, sonra gerçek geri bildirim ve gerçek biletlerle büyütün.
Ölçtüğünüz taahhüdü (ilk yanıt mı yoksa çözüm mü gibi) netleştirin ve tam olarak hangi olayın sayacı başlatıp durdurduğunu, hangi durumların duraklattığını yazın. Ardından zaman hesabını merkezileştirip tüm küçük "şimdi > X" kontrollerini tek bir değerlendiricide toplayın; bu, dağılan mantığı önler.
Bir sayaç, örneğin bir bilet yeni bir duruma geçtiğinde başlattığınız saattir. Bir eskalasyon, eşik aşıldığında yapılan eylemdir (lead'i bildirmek, önceliği değiştirmek vb.). Bir ihlal ise SLA'nın kaçırıldığını gösteren ve sonradan raporlanabilen saklı bilgidir.
İlk yanıt, insanın yaptığı ilk anlamlı yanıta kadar geçen süredir; çözüm ise sorunun tamamen kapatılmasına kadar geçen süredir. Duraklamalar ve yeniden açılmalar bu iki ölçümü farklı şekilde etkiler; onları ayrı modellemek kuralları ve raporlamayı basitleştirir.
Varsayılan olarak takvim zamanını (7/24) kullanın; bu daha basittir ve hata ayıklaması daha kolaydır. İş saatleri gerekiyorsa ekleyin, çünkü tatiller, saat dilimleri ve kısmi gün hesapları ekstra karmaşıklık getirir.
Duraklamaları Waiting on Customer gibi belirgin durumlara bağlayın ve pause_started_at ile pause_ended_at gibi zaman damgalarını kaydedin. Yeniden başlatırken kalan süreyle devam edin veya tek bir yerde yeniden hesaplayın; rastgele durum değişikliklerinin saati sıfırlamasına izin vermeyin.
Tek bir breached = true/false bayrağı genellikle yeterli değildir; hangi SLA'nın ihlal olduğunu, şu an durakta mı olduğunu veya zaten eskale edilip edilmediğini gizler. On track, Warning, Breached, Paused, Completed gibi açık durumlar sistemi öngörülebilir ve denetlenebilir kılar.
Durumu açıklayan zaman damgalarını saklayın: started_at, due_at, breached_at ve duraklama alanları paused_at, paused_reason. Ayrıca last_escalation_level gibi alanlarla aynı seviyeye tekrar bildirim gönderilmesini engelleyebilirsiniz.
İşi yapabilecek kişiden başlayıp gerektiğinde kademeli olarak bir lead'e, sonra yöneticiye yükselen küçük bir merdiven en iyi sonuç verir. Eşikleri ve alıcıları veri olarak (örneğin politika tablosu) saklayın; böylece zamanlamayı değiştirmek için birden fazla akışı düzenlemeniz gerekmez.
Bildirimleri durum geçişlerine bağlayın (ör. OK -> Warning, Warning -> Breached) ve her adım için soğuma pencereleri, yeniden deneme kuralları ve bir maksimum seviye belirleyin. Bu, tekrar eden spam'ı önler.
Olayları kaydedin, tek bir değerlendirici ile son tarihleri hesaplayın ve eylemleri yalnızca durum değişikliklerine yanıt olarak tetikleyin. AppMaster içinde veri modelleyip görsel iş süreçleriyle değerlendirici kurarak bu desen uygulanabilir: olaylar gerçekleri yazar, değerlendirici son tarihleri hesaplar, eylemler ise yalnızca durum değiştiğinde çalışır.



Ücretsiz planla AppMaster ile denemeler yapın.
Hazır olduğunuzda uygun aboneliği seçebilirsiniz.


