Aplikacja do rezerwacji sprzętu: zapobiegaj konfliktom i śledź zwroty
Zaplanuj aplikację do rezerwacji sprzętu, która zapobiega podwójnym rezerwacjom, rejestruje zwroty i uszkodzenia oraz wstrzymuje wadliwe przedmioty do czasu serwisu.
Poznaj koncepcje architektur stanowych i bezstanowych, analizując ich definicje, różnice i praktyczne zastosowania.

Architektura stanowa to podejście do projektowania oprogramowania, w którym aplikacja przechowuje dane specyficzne dla klienta pomiędzy żądaniami. W tym modelu system śledzi zmiany stanu każdego klienta i zapamiętuje informacje o wcześniejszym stanie podczas kolejnych żądań. Pomaga to usprawnić interakcje między klientami i serwerami, zmniejszając potrzebę wymiany kompletnych danych przy każdym żądaniu, co prowadzi do bardziej płynnej obsługi użytkownika.
Wiele znanych aplikacji i usług, takich jak systemy bankowości internetowej, witryny handlu elektronicznego i platformy mediów społecznościowych, wykorzystuje architekturę stanową. Usługi te opierają się na mechanizmach uwierzytelniania użytkowników i wymagają ciągłego zarządzania sesjami użytkowników, aby zapewnić każdemu użytkownikowi spersonalizowane doświadczenia.
Zarządzanie sesjami jest krytycznym aspektem architektury stanowej. Zapewnia spójność i bezpieczeństwo danych poprzez prowadzenie rejestru sesji poszczególnych klientów przez cały okres interakcji. W zależności od aplikacji te dane specyficzne dla klienta mogą obejmować dane logowania, preferencje użytkownika i inne istotne informacje.
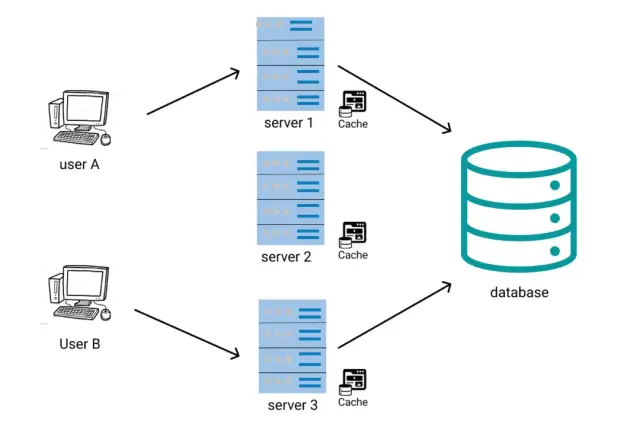
Źródło obrazu: średnie
Architektura bezstanowa to podejście do projektowania oprogramowania, w którym aplikacja działa niezależnie od jakiejkolwiek wcześniejszej interakcji. W tym modelu system nie przechowuje informacji specyficznych dla klienta pomiędzy żądaniami. Zamiast tego każde żądanie musi zawierać wszystkie istotne dane wymagane do przetwarzania. W rezultacie systemy bezstanowe rozpatrują każde żądanie indywidualnie, bez konieczności śledzenia lub utrzymywania danych klienta od jednego żądania do drugiego.
Architektury bezstanowe są powszechnie stosowane w interfejsach API RESTful , gdzie każde żądanie dostarcza wszystkich niezbędnych informacji, aby serwer mógł je spełnić. Ten typ architektury oferuje lepszą skalowalność ze względu na brak zależności od przechowywanych danych sesji. W rezultacie systemy bezstanowe mogą łatwiej obsługiwać rosnące obciążenia klientów bez uszczerbku dla wydajności i wydajności.
W architekturze bezstanowej za zarządzanie danymi i nawigację między stanami odpowiada klient. Często wymaga częstszej wymiany danych, w tym powtarzalnego uwierzytelniania użytkowników i przesyłania danych dotyczących preferencji, co może przyczyniać się do zwiększenia ładunku. Pomimo tego wzrostu ruchu sieciowego, systemy bezstanowe są często prostsze w utrzymaniu i skalowaniu niż ich stanowe odpowiedniki.
Zarówno architektury stanowe, jak i bezstanowe mają swoje unikalne cechy i zalety. Poniżej znajdują się kluczowe różnice między nimi:
Różnice te nie są absolutne, a ich wpływ może się różnić w zależności od wymagań aplikacji i sytuacji użycia. Decydując między architekturą stanową a bezstanową, programiści powinni wziąć pod uwagę unikalne potrzeby, wymagania i cele swoich konkretnych projektów.
Architektura stanowa to podejście do projektowania oprogramowania charakteryzujące się trwałością danych specyficznych dla klienta pomiędzy żądaniami. W ten sposób systemy stanowe mogą śledzić zmiany i utrzymywać stan sesji podczas interakcji użytkownika z aplikacją. Omówmy zalety i wady związane z tym podejściem.
W przeciwieństwie do architektury stanowej, architektura bezstanowa nie przechowuje informacji specyficznych dla klienta pomiędzy żądaniami. Każde żądanie musi zawierać wszystkie dane niezbędne do jego rozpatrzenia, umożliwiające jego samodzielne rozpatrzenie. Przyjrzyjmy się zaletom i wadom związanym z projektowaniem bezstanowym.
Wybór odpowiedniej architektury dla Twojej aplikacji – stanowej lub bezstanowej – zależy od różnych czynników, w tym od wymagań konkretnego projektu i przypadków użycia. Oto kilka ogólnych wskazówek, które pomogą Ci podjąć świadomą decyzję:
Należy również pamiętać, że korzystanie z narzędzi takich jak AppMaster może pomóc usprawnić proces programowania. Dzięki swojej wszechstronności AppMaster umożliwia programistom tworzenie aplikacji stanowych i bezstanowych, w zależności od specyficznych wymagań ich projektów i przypadków użycia. Wykorzystując moc tej platformy niewymagającej kodu , możesz skuteczniej poruszać się po skomplikowanych procesach tworzenia aplikacji, niezależnie od wybranej architektury.
Architektura stanowa to podejście do projektowania oprogramowania, w którym aplikacja przechowuje dane specyficzne dla klienta pomiędzy żądaniami, śledząc zmiany i utrzymując stan sesji.
Architektura bezstanowa to podejście do projektowania oprogramowania, w którym aplikacja nie przechowuje informacji specyficznych dla klienta z wcześniejszych żądań. Każde żądanie musi zawierać wszystkie istotne informacje, aby mogło być przetwarzane niezależnie.
Główne różnice obejmują:
Niektóre zalety architektury stanowej obejmują:
Wady architektury stanowej obejmują:
Niektóre zalety architektury bezstanowej obejmują:
Wady architektury bezstanowej obejmują:
Wybór pomiędzy architekturą stanową i bezstanową zależy od konkretnych wymagań i przypadków użycia aplikacji. Oceń zalety i wady każdego systemu, biorąc pod uwagę takie elementy, jak doświadczenie użytkownika, skalowalność, złożoność i bezpieczeństwo, aby podjąć świadomą decyzję.
Tak, AppMaster to wszechstronna platforma no-code, która pozwala użytkownikom tworzyć zarówno aplikacje stanowe, jak i bezstanowe, w zależności od konkretnych wymagań i przypadków użycia ich projektów. Ta elastyczność umożliwia programistom wybór architektury, która najlepiej odpowiada ich potrzebom.



Eksperymentuj z AppMaster z darmowym planem.
Kiedy będziesz gotowy, możesz wybrać odpowiednią subskrypcję.


