Gerätereservierungs-App: Konflikte verhindern und Rückgaben verfolgen
Plane eine Gerätereservierungs-App, die Doppelbuchungen verhindert, Rückgaben und Schäden dokumentiert und fehlerhafte Geräte für die Wartung sperrt.
Beherrschen Sie den Prozess der Datenmodellierung in relationalen Datenbanken vom Konzept bis zur Implementierung. Verstehen Sie die Schritte, Techniken, Designmethoden und Tools, die für eine effiziente Entwicklung unerlässlich sind.

Die Datenmodellierung ist ein wichtiger Prozess in der Softwareentwicklung und dem Datenbankdesign. Dabei geht es darum, eine visuelle Darstellung der Daten einer Organisation und der Beziehungen zwischen verschiedenen Einheiten zu erstellen. Durch die effektive Abbildung der Struktur, Speicherung und Zugriffsmethoden für Datenelemente können Entwickler und Analysten eine effiziente Organisation und den Abruf von Daten innerhalb eines Systems sicherstellen.
Relationale Datenbankverwaltungssysteme (RDBMS) basieren stark auf Datenmodellierung, um gut strukturierte und effiziente Datenbanken aufzubauen. Datenmodelle in RDBMS helfen bei der Definition der Datenbankstruktur und geben die Entitäten, Attribute, Beziehungen und Einschränkungen an. Ein richtig gestaltetes Datenmodell kann die Datenkonsistenz verbessern, Redundanz reduzieren und die Leistung von Datenbankoperationen optimieren.
Dieser Artikel bietet einen Überblick über den Datenmodellierungsprozess in RDBMS, die verschiedenen Arten von Datenmodellen und die Techniken, die für eine effiziente und effektive Datenmodellierung erforderlich sind.
Der Prozess der Datenmodellierung umfasst mehrere Schritte, die sich grob in die folgenden Phasen einteilen lassen:

In RDBMS werden drei Haupttypen von Datenmodellen verwendet: konzeptionelle, logische und physische. Jeder Datenmodelltyp dient einem anderen Zweck und stellt eine andere Abstraktionsebene dar.
Ein konzeptionelles Datenmodell ist eine abstrakte Darstellung der Daten der Organisation auf hoher Ebene. Der Schwerpunkt liegt auf der Erfassung der Entitäten, ihrer Attribute und Beziehungen, ohne dass Implementierungsdetails angegeben werden. Das Hauptziel der konzeptionellen Datenmodellierung besteht darin, die Geschäftsanforderungen klar zu verstehen und die Kommunikation zwischen Stakeholdern wie Geschäftsanalysten, Entwicklern und Endbenutzern zu erleichtern.
Ein logisches Datenmodell ist eine Verfeinerung des konzeptionellen Datenmodells, bei dem Entitäten, Attribute und Beziehungen weiter detailliert und organisiert werden. In dieser Phase werden zusätzliche Einschränkungen und Regeln definiert und Datenelemente in Tabellen und Spalten organisiert. Das logische Datenmodell ist die Grundlage für das physische Datenmodell, das sich auf die tatsächlichen Implementierungsdetails in einem bestimmten RDBMS konzentriert.
Ein physisches Datenmodell ist der letzte Schritt im Datenmodellierungsprozess und stellt die tatsächlichen Implementierungsdetails in einem bestimmten RDBMS dar. Es enthält die technischen Spezifikationen, die zum Erstellen der Datenbankstruktur erforderlich sind, wie z. B. Tabellen- und Spaltennamen, Speicheranforderungen und Indextypen. Die physische Datenmodellierung konzentriert sich auf die Optimierung der Leistung von Datenbankoperationen basierend auf den spezifischen Merkmalen und Merkmalen des gewählten RDBMS.
Die konzeptionelle Datenmodellierung stellt den ersten Schritt im Datenmodellierungsprozess dar und konzentriert sich auf die allgemeine, abstrakte Sicht auf die Datenanforderungen einer Organisation. Dabei geht es darum, die wichtigsten Dateneinheiten, ihre Attribute und die Beziehungen zwischen ihnen zu identifizieren, ohne auf spezifische Details zu Datentypen oder Speicherung einzugehen. Das Hauptziel der konzeptionellen Datenmodellierung besteht darin, die Geschäftsanforderungen klar zu verstehen und eine solide Grundlage für die nächsten Phasen der Datenmodellierung (logische und physische Modellierung) zu schaffen.
Die Hauptkomponenten der konzeptionellen Datenmodellierung sind:
Die Erstellung eines konzeptionellen Datenmodells umfasst mehrere Schritte:
Am Ende des konzeptionellen Datenmodellierungsprozesses verfügen Sie über eine klare, übergeordnete Darstellung Ihres Datenmodells, die als Grundlage für die nächste Prozessstufe, die logische Datenmodellierung, dient.
Durch die logische Datenmodellierung wird das konzeptionelle Datenmodell verfeinert und erweitert, indem weitere Details zu Attributen, Datentypen und Beziehungen hinzugefügt werden. Es handelt sich um eine detailliertere Darstellung des Datenmodells, die unabhängig von einem bestimmten Datenbankverwaltungssystem (DBMS) oder einer bestimmten Technologie ist. Das Hauptziel der logischen Datenmodellierung besteht darin, die Struktur und Beziehungen zwischen Entitäten genau zu definieren und gleichzeitig einen gewissen Grad an Abstraktion von der tatsächlichen Implementierung aufrechtzuerhalten.
Die kritischen Komponenten der logischen Datenmodellierung sind:
Die Erstellung eines logischen Datenmodells umfasst mehrere Schritte:
Nach Abschluss des logischen Datenmodellierungsprozesses ist das resultierende Modell für die letzte Phase der physischen Datenmodellierung bereit.
Die physische Datenmodellierung ist der letzte Schritt im Datenmodellierungsprozess, bei dem das logische Datenmodell mithilfe eines bestimmten Datenbankverwaltungssystems (DBMS) und einer bestimmten Technologie in eine tatsächliche Implementierung übersetzt wird. Es ist die detaillierteste Darstellung des Datenmodells und enthält alle notwendigen Informationen zum Erstellen und Verwalten von Datenbankobjekten wie Tabellen, Indizes, Ansichten und Einschränkungen.
Zu den Schlüsselkomponenten der physischen Datenmodellierung gehören:
Die Erstellung eines physischen Datenmodells umfasst mehrere Schritte:
Das in dieser letzten Phase erstellte physische Datenmodell ist nicht nur ein wichtiges Dokument für die Entwicklung und Wartung der Datenbank, sondern dient auch als wichtige Referenz für andere Interessengruppen, darunter Geschäftsanalysten, Entwickler und Systemadministratoren.
AppMaster , eine leistungsstarke No-Code- Plattform, erleichtert den einfachen Übergang von der Datenmodellierung zur Implementierung. Durch die visuelle Erstellung von Datenmodellen für Backend-Anwendungen können Benutzer Datenbankschemata und Geschäftslogik mithilfe visuell gestalteter Geschäftsprozesse, REST-APIs und WSS-Endpunkte entwerfen. AppMaster generiert Quellcode für Anwendungen und ermöglicht so eine schnelle Implementierung, nahtlose Integration und einfache Wartung Ihrer Datenmodelle. Nutzen Sie die Leistungsfähigkeit von AppMaster, um die Datenmodellierung zu vereinfachen und Ihre Konzepte in voll funktionsfähige Anwendungen umzuwandeln.
Normalisierung ist ein systematischer Ansatz, der beim relationalen Datenbankdesign verwendet wird, um Daten zu organisieren, Redundanz zu reduzieren und die Datenkonsistenz sicherzustellen. Es vereinfacht die Struktur der Datenbank und ermöglicht eine effiziente Leistung. Der Prozess umfasst die Zerlegung einer Tabelle in kleinere, zusammengehörige Tabellen und die Herstellung geeigneter Beziehungen zwischen ihnen. Im Normalisierungsprozess werden mehrere Normalformen (1NF, 2NF, 3NF, BCNF, 4NF, 5NF) als Richtlinien verwendet, um unterschiedliche Normalisierungsgrade zu erreichen.
Der erste Schritt bei der Normalisierung ist das Erreichen der Ersten Normalform (1NF), die die folgenden Regeln durchsetzt:
Durch die Einhaltung von 1NF eliminiert die Datenbank sich wiederholende Gruppen und vereinfacht die Tabellenstruktur.
Die zweite Normalform (2NF) zielt darauf ab, teilweise Abhängigkeiten zu beseitigen. Eine Tabelle ist in 2NF, wenn:
Durch das Erreichen von 2NF stellt die Datenbank sicher, dass alle Nicht-Schlüsselattribute in einer Tabelle den gesamten Primärschlüssel beschreiben, wodurch teilweise Abhängigkeiten beseitigt und Redundanz reduziert werden.
Die dritte Normalform (3NF) eliminiert transitive Abhängigkeiten. Eine Tabelle ist in 3NF, wenn:
Durch die Einhaltung von 3NF eliminiert das Datenbankdesign transitive Abhängigkeiten und reduziert Redundanz und Inkonsistenzen weiter.
Die Boyce-Codd-Normalform (BCNF) ist eine stärkere Version von 3NF, die bestimmte Anomalien behandelt, die möglicherweise nicht von 3NF abgedeckt werden. Eine Tabelle ist in BCNF, wenn:
BCNF verfeinert das Datenmodell weiter, indem es sicherstellt, dass alle funktionalen Abhängigkeiten strikt durchgesetzt und Anomalien beseitigt werden.
Die vierte Normalform (4NF) befasst sich mit mehrwertigen Abhängigkeiten. Eine Tabelle ist in 4NF, wenn:
Durch die Einhaltung von 4NF eliminiert das Datenbankdesign redundante Informationen, die aus mehrwertigen Abhängigkeiten resultieren, und verbessert so die Effizienz der Datenbank.
Die fünfte Normalform (5NF) befasst sich mit Join-Abhängigkeiten. Eine Tabelle ist in 5NF, wenn:
Durch das Erreichen von 5NF eliminiert das Datenbankdesign zusätzliche Redundanz und stellt sicher, dass die Datenbank ohne Informationsverlust wiederhergestellt werden kann.
Beim Reverse Engineering wird die bestehende Struktur einer Datenbank analysiert und die entsprechenden Datenmodelle generiert, typischerweise für Dokumentations- oder Migrationszwecke. Reverse Engineering kann dabei helfen:
Verschiedene Datenmodellierungstools bieten Reverse-Engineering-Funktionen, mit denen Sie eine Verbindung zu einer Datenbank herstellen, das Schema extrahieren und entsprechende ER-Diagramme oder andere Datenmodelle generieren können. Manchmal müssen Sie die generierten Datenmodelle möglicherweise manuell verfeinern, um die zugrunde liegenden Geschäftsanforderungen genau darzustellen und die Datenbankstruktur zu vereinfachen.
Datenmodellierungstools bieten einen visuellen Ansatz zum Entwerfen von Datenbankschemata und helfen dabei, sicherzustellen, dass Daten effizient organisiert und abgerufen werden. Diese Tools verfügen über verschiedene Funktionen wie visuelle Modellierung, Codegenerierung, Versionskontrolle und Unterstützung für verschiedene Datenbankverwaltungssysteme. Zu den beliebten Datenmodellierungstools gehören:
ER/Studio ist ein Datenmodellierungs- und Architekturtool, das leistungsstarke Funktionen zum Entwerfen, Dokumentieren und Verwalten Ihrer Datenstrukturen bietet. Es unterstützt mehrere Datenbanken, darunter Oracle, SQL Server, MySQL und PostgreSQL. Zu den Hauptmerkmalen gehören:
PowerDesigner ist eine umfassende Datenmodellierungs- und Unternehmensarchitekturlösung, die verschiedene Funktionen zum Entwerfen und Verwalten von Datenstrukturen auf verschiedenen Plattformen bietet. Zu den Hauptmerkmalen gehören:
ERwin Data Modeler ist ein weiteres weit verbreitetes Datenmodellierungstool, das Funktionen zum Erstellen, Verwalten und Verwalten komplexer Datenstrukturen bietet. Zu den Hauptmerkmalen gehören:
Die Auswahl des richtigen Datenmodellierungstools hängt von den spezifischen Anforderungen Ihres Projekts ab, z. B. der Größe und Komplexität Ihrer Datenstrukturen, den von Ihnen verwendeten Datenbankverwaltungssystemen und dem Grad der erforderlichen Zusammenarbeit. Berücksichtigen Sie diese Faktoren unbedingt, wenn Sie verschiedene Tools bewerten, um die beste Entscheidung für Ihr Unternehmen zu treffen.
AppMaster, eine leistungsstarke no-code Plattform, vereinfacht den Prozess der Implementierung von Datenmodellen für Ihre Backend-, Web- und mobilen Anwendungen. Sie können damit Datenbankschemata entwerfen, Geschäftslogik mithilfe visuell gestalteter Geschäftsprozesse erstellen und intuitiv REST-API- und WSS-Endpunkte generieren. Indem Sie AppMaster für Ihre Datenmodellierungsanforderungen nutzen, können Sie Ihren Anwendungsentwicklungsprozess optimieren und den Zeit- und Arbeitsaufwand für die Umsetzung Ihrer Ideen minimieren.
Mit den visuellen Datenmodellierungstools von AppMaster können Sie Ihre Datenmodelle ganz einfach entwerfen, indem Sie Elemente per Drag & Drop auf die Leinwand ziehen. Definieren Sie Entitäten mit ihren jeweiligen Attributen, geben Sie Beziehungen und Einschränkungen zwischen ihnen an. AppMaster unterstützt eine Vielzahl von Datentypen, sodass Sie problemlos komplexe und anspruchsvolle Datenmodelle erstellen können.
Sobald Ihr Datenmodell eingerichtet ist, kann AppMaster Backend-Anwendungen mithilfe der leistungsstarken Programmiersprache Go (Golang) generieren. Diese Anwendungen sind hocheffizient und können unternehmensweite Anwendungsfälle mit hoher Auslastung bewältigen. Mit dem Business Process Designer von AppMaster können Sie die mit Ihrem Datenmodell verknüpfte Geschäftslogik visuell erstellen. Durch die Definition von Arbeitsabläufen, Regeln und Aktionen mithilfe der drag-and-drop Schnittstelle können Sie die Kernfunktionalität Ihrer Anwendung schnell entwickeln, ohne dass manuelle Codierung erforderlich ist.
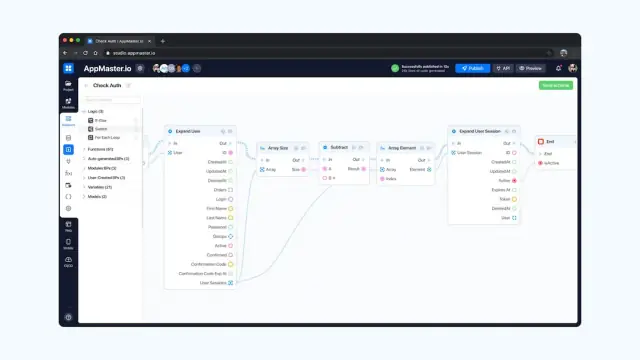
AppMaster generiert automatisch REST-API- und WSS-Endpunkte für Ihre Datenmodelle und ermöglicht so eine reibungslose Kommunikation zwischen Ihren Anwendungen und der Datenbank. Diese endpoints folgen der OpenAPI-Spezifikation und gewährleisten so die Kompatibilität mit verschiedenen Front-End-Frameworks und Anwendungen von Drittanbietern. Die Plattform generiert außerdem Swagger-Dokumentation, um Ihnen dabei zu helfen, die API effizient zu erkunden, zu testen und zu verwalten.
AppMaster generiert den Quellcode für Ihre Anwendungen und bietet Ihnen eine solide Grundlage, auf der Sie aufbauen können. Mit dem Enterprise-Abonnement können Sie auf den vollständigen Quellcode Ihrer Anwendungen zugreifen und diese vor Ort bereitstellen. Die generierten Anwendungen nutzen das Vue3- Framework für Webanwendungen und Kotlin mit Jetpack Compose für Android- und SwiftUI für iOS-Anwendungen und gewährleisten so eine hohe Leistung und Kompatibilität.
Einer der einzigartigen Vorteile der Verwendung AppMaster ist die Beseitigung technischer Schulden. AppMaster generiert Anwendungen jedes Mal von Grund auf neu, wenn Änderungen an den Blaupausen vorgenommen werden. Dieser Ansatz stellt sicher, dass Ihre Anwendungen immer auf dem neuesten Stand der Designprinzipien und Best Practices sind, wodurch sich die Komplexität und die Kosten für die Wartung Ihrer Anwendungen auf lange Sicht erheblich reduzieren.
Die Datenmodellierung in RDBMS ist ein entscheidender Bestandteil des Anwendungsentwicklungsprozesses. Das Verständnis der verschiedenen Arten von Datenmodellen sowie der bei ihrer Erstellung und Implementierung verwendeten Techniken und Methoden kann zu einem effizienteren und effektiveren Datenbankentwurfsprozess führen. Mit der intuitiven no-code Plattform von AppMaster können Sie Datenmodelle, Backend-, Web- und Mobilanwendungen visuell entwerfen und bereitstellen und so eine schnelle Anwendungsentwicklung, reduzierte Wartungskosten und die Beseitigung technischer Schulden ermöglichen. Durch die Nutzung der Leistungsfähigkeit von AppMaster können Entwickler und Unternehmen ihre Ideen schneller und effizienter umsetzen, was zu einem Wettbewerbsvorteil in der heutigen Technologiebranche führt.
Bei der Datenmodellierung handelt es sich um den Prozess der Erstellung einer visuellen Darstellung der Daten einer Organisation und der Art und Weise, wie diese strukturiert, gespeichert und abgerufen werden. Es hilft dabei, die Beziehungen zwischen verschiedenen Dateneinheiten und die Regeln für ihre Verwendung zu verstehen.
Es gibt drei Haupttypen von Datenmodellen: konzeptionelle, logische und physische. Das konzeptionelle Modell stellt die übergeordnete Sicht auf die Entitäten und Beziehungen dar, während das logische Modell das konzeptionelle Modell durch Hinzufügen von Attributen und Definieren von Beziehungen verfeinert und das physische Modell die tatsächlichen Implementierungsdetails in einem bestimmten Datenbankverwaltungssystem (DBMS) angibt.
Bei der konzeptionellen Datenmodellierung handelt es sich um den Prozess der Erstellung einer abstrakten Darstellung der Daten einer Organisation auf hoher Ebene. Dabei geht es darum, die wichtigsten Dateneinheiten, ihre Attribute und die Beziehungen zwischen ihnen zu identifizieren. Dieses Modell dient als Grundlage für die logische und physische Datenmodellierung, gewährleistet ein klares Verständnis der Geschäftsanforderungen und leitet den Datenbankdesignprozess.
Normalisierungstechniken werden beim Datenbankdesign verwendet, um Datenredundanz zu reduzieren und die Effizienz und Konsistenz der Datenspeicherung zu verbessern. Der Prozess umfasst das Organisieren von Daten in Tabellen, das Eliminieren doppelter Informationen und das Herstellen von Beziehungen zwischen den Tabellen. Mehrere Normalformen (1NF, 2NF, 3NF usw.) werden als Richtlinien verwendet, um unterschiedliche Normalisierungsgrade zu erreichen.
Zu den beliebten Datenmodellierungstools gehören ER/Studio, PowerDesigner und ERwin Data Modeler. Diese Tools bieten Funktionen wie visuelle Datenmodellierung, Codegenerierung und Unterstützung für eine Vielzahl von Datenbankverwaltungssystemen.
AppMaster, eine leistungsstarke no-code Plattform, ermöglicht Benutzern die visuelle Erstellung von Datenmodellen für Backend-Anwendungen. Benutzer können Datenbankschemata und Geschäftslogik mithilfe visuell gestalteter Geschäftsprozesse, REST-APIs und WSS-Endpunkte entwerfen. AppMaster generiert Quellcode für Anwendungen und ermöglicht so eine schnelle Implementierung und einfache Wartung von Datenmodellen.



Experimentieren Sie mit AppMaster mit kostenlosem Plan.
Wenn Sie fertig sind, können Sie das richtige Abonnement auswählen.


