25 sept 2023·8 min de lectura
Modelado de datos en RDBMS: del diseño conceptual a la implementación
Dominar el proceso de modelado de datos en bases de datos relacionales desde el concepto hasta la implementación. Comprender los pasos, técnicas, metodologías de diseño y herramientas esenciales para un desarrollo eficiente.
El modelado de datos es un proceso vital en el desarrollo de software y diseño de bases de datos. Implica crear una representación visual de los datos de una organización y las relaciones entre diferentes entidades. Al mapear de manera efectiva la estructura, el almacenamiento y los métodos de acceso a los elementos de datos, los desarrolladores y analistas pueden garantizar una organización y recuperación eficiente de los datos dentro de un sistema.
Los sistemas de gestión de bases de datos relacionales (RDBMS) dependen en gran medida del modelado de datos para crear bases de datos eficientes y bien estructuradas. Los modelos de datos en RDBMS ayudan a definir la estructura de la base de datos, especificando las entidades, atributos, relaciones y restricciones. Un modelo de datos diseñado correctamente puede mejorar la coherencia de los datos, reducir la redundancia y optimizar el rendimiento de las operaciones de la base de datos.
Este artículo proporciona una descripción general del proceso de modelado de datos en RDBMS, los diferentes tipos de modelos de datos y las técnicas necesarias para un modelado de datos eficiente y eficaz.
El proceso de modelado de datos
El proceso de modelado de datos implica varios pasos, que a grandes rasgos se pueden agrupar en las siguientes etapas:
- Análisis de requisitos: el primer paso en el modelado de datos es recopilar y analizar los requisitos comerciales. Esto implica comprender el propósito y los objetivos de la base de datos, los elementos de datos que se almacenarán y las relaciones entre ellos. También incluye la identificación de restricciones, suposiciones y reglas comerciales que rigen el uso de datos dentro del sistema.
- Diseño: A partir del análisis de requisitos, se diseña el modelo de datos para satisfacer las necesidades específicas de la organización. Esto implica elegir estructuras de datos apropiadas, definir las entidades, atributos y relaciones, y especificar restricciones y otras reglas. Dependiendo del nivel de abstracción requerido, un modelo de datos se puede diseñar a nivel conceptual, lógico o físico.
- Validación: una vez diseñado el modelo de datos, es necesario validarlo para garantizar que represente con precisión los requisitos comerciales y cumpla con los estándares de usabilidad y rendimiento deseados. La validación implica verificar el modelo en busca de errores, inconsistencias y redundancias y confirmar que cumple con las mejores prácticas de modelado de datos.
- Implementación: una vez validado el modelo de datos, se utiliza para guiar la implementación real de la base de datos en un RDBMS específico. Esto incluye la creación de tablas, el establecimiento de relaciones, la definición de claves primarias y externas y la implementación de restricciones, activadores y otros objetos de la base de datos. Dependiendo de la elección del RDBMS, es posible que se requieran ciertos ajustes y optimizaciones para ajustar el modelo y lograr un rendimiento óptimo.
- Mantenimiento: una vez implementada la base de datos, el modelo de datos y la documentación asociada deben actualizarse y mantenerse a medida que evoluciona el sistema. Esto incluye modificar el modelo para reflejar cambios en los requisitos, corregir errores y aplicar optimizaciones para mejorar el rendimiento.

Tipos de modelos de datos
En RDBMS se utilizan tres tipos principales de modelos de datos: conceptuales, lógicos y físicos. Cada tipo de modelo de datos tiene un propósito diferente y representa un nivel diferente de abstracción.
Modelos de datos conceptuales
Un modelo de datos conceptual es una representación abstracta de alto nivel de los datos de la organización. Se centra en capturar las entidades, sus atributos y relaciones sin especificar ningún detalle de implementación. El objetivo principal del modelado de datos conceptuales es comprender claramente los requisitos comerciales y facilitar la comunicación entre las partes interesadas, como analistas comerciales, desarrolladores y usuarios finales.
Modelos de datos lógicos
Un modelo de datos lógico es un refinamiento del modelo de datos conceptual, donde las entidades, atributos y relaciones se detallan y organizan más. En esta etapa se definen restricciones y reglas adicionales y los elementos de datos se organizan en tablas y columnas. El modelo de datos lógicos es la base del modelo de datos físicos, que se centra en los detalles de implementación reales en un RDBMS específico.
Modelos de datos físicos
Un modelo de datos físicos es el paso final en el proceso de modelado de datos y representa los detalles de implementación reales en un RDBMS específico. Incluye las especificaciones técnicas necesarias para crear la estructura de la base de datos, como nombres de tablas y columnas, requisitos de almacenamiento y tipos de índice. El modelado de datos físicos se centra en optimizar el rendimiento de las operaciones de la base de datos en función de las características y características específicas del RDBMS elegido.
Modelado de datos conceptuales
El modelado de datos conceptuales representa el primer paso en el proceso de modelado de datos, centrándose en la visión abstracta de alto nivel de los requisitos de datos de una organización. Implica identificar las entidades de datos clave, sus atributos y las relaciones entre ellas sin entrar en detalles específicos sobre los tipos de datos o el almacenamiento. El objetivo principal del modelado de datos conceptual es comprender claramente los requisitos comerciales y formar una base sólida para las siguientes etapas del modelado de datos (modelado lógico y físico).
Componentes del modelado de datos conceptuales
Los componentes principales del modelado de datos conceptuales son:
- Entidades: representan los objetos o conceptos clave en el dominio, como clientes, productos, pedidos o empleados.
- Atributos: defina las propiedades de las entidades, como el nombre del cliente, el precio del producto, la fecha del pedido o la identificación del empleado.
- Relaciones: representan las asociaciones entre entidades, como un cliente que realiza varios pedidos, un producto que pertenece a una categoría o un empleado que trabaja en un departamento específico.
Crear un modelo de datos conceptual
La creación de un modelo de datos conceptual implica varios pasos:
- Identificar entidades: enumere las entidades clave de su dominio que se incluirán en la base de datos. Piense en qué objetos son de primordial importancia y requieren almacenamiento y recuperación.
- Definir atributos: determine los atributos de cada entidad relevantes para el alcance de su modelo de datos. Concéntrese en las propiedades principales de cada entidad sin profundizar en detalles como tipos de datos o restricciones.
- Establecer Relaciones: Analizar las conexiones entre entidades y definir las relaciones existentes, asegurando que las relaciones propuestas tengan sentido desde una perspectiva empresarial.
- Revisar y refinar: revisar el modelo conceptual inicial, buscando inconsistencias, redundancias e información faltante. Actualice el modelo según sea necesario para mejorar su precisión e integridad.
Al final del proceso de modelado de datos conceptuales, tendrá una representación clara y de alto nivel de su modelo de datos, que sirve como base para la siguiente etapa del proceso, el modelado de datos lógicos.
Modelado de datos lógicos
El modelado de datos lógicos refina y amplía el modelo de datos conceptual agregando más detalles sobre atributos, tipos de datos y relaciones. Es una representación más detallada del modelo de datos que es independiente de una tecnología o sistema de gestión de bases de datos (DBMS) específico. El objetivo principal del modelado lógico de datos es definir con precisión la estructura y las relaciones entre entidades, manteniendo al mismo tiempo un grado de abstracción de la implementación real.
Componentes del modelado lógico de datos
Los componentes críticos del modelado lógico de datos son:
- Entidades, atributos y relaciones: estos componentes conservan su significado y propósito originales del modelo de datos conceptual.
- Tipos de datos: asigne tipos de datos específicos a cada atributo, definiendo el tipo de información que puede almacenar, como números enteros, cadenas o fechas.
- Restricciones: Defina reglas o restricciones que deben cumplir los datos almacenados en los atributos, como unicidad, integridad referencial o restricciones de dominio.
Crear un modelo de datos lógico
La creación de un modelo de datos lógico implica varios pasos:
- Refinar entidades, atributos y relaciones: revise y actualice los componentes transferidos del modelo de datos conceptual, asegurándose de que representen con precisión los requisitos comerciales previstos. Busque oportunidades para hacer que el modelo sea más eficiente, como identificar entidades o atributos reutilizables.
- Defina tipos de datos y restricciones: asigne tipos de datos apropiados a cada atributo y especifique las restricciones que deben aplicarse para garantizar la coherencia e integridad de los datos.
- Normalice el modelo de datos lógico: aplique técnicas de normalización para eliminar la redundancia y aumentar la eficiencia dentro del modelo de datos. Asegurar que cada entidad y sus atributos cumplan con los requisitos de las distintas formas normales (1NF, 2NF, 3NF, etc.).
Después de completar el proceso de modelado lógico de datos, el modelo resultante está listo para la etapa final del modelado de datos físicos.
Modelado de datos físicos
Comienza con un modelo limpio
Empieza con un conjunto sencillo de entidades y evoluciona tu modelo de forma segura mientras aprendes.
El modelado de datos físicos es el paso final en el proceso de modelado de datos, donde el modelo de datos lógicos se traduce en una implementación real utilizando un sistema de gestión de bases de datos (DBMS) y una tecnología específicos. Es la representación más detallada del modelo de datos y contiene toda la información necesaria para crear y administrar objetos de base de datos, como tablas, índices, vistas y restricciones.
Componentes del modelado de datos físicos
Los componentes clave del modelado de datos físicos incluyen:
- Tablas: representan las estructuras de almacenamiento reales de las entidades en el modelo de datos, y cada fila de la tabla corresponde a una instancia de entidad.
- Columnas: Corresponden a los atributos del modelo de datos lógicos, especificando el tipo de datos, las restricciones y otras propiedades específicas de la base de datos para cada atributo.
- Índices: Defina estructuras adicionales que mejoren la velocidad y eficiencia de las operaciones de recuperación de datos en tablas.
- Claves externas y restricciones: representan las relaciones entre tablas, asegurando que se mantenga la integridad referencial a nivel de la base de datos.
Crear un modelo de datos físicos
La creación de un modelo de datos físicos implica varios pasos:
- Elija un DBMS: seleccione un sistema de administración de bases de datos específico (como PostgreSQL , MySQL o SQL Server) en el que se implementará el modelo de datos físicos. Esta elección determinará las características, los tipos de datos y las restricciones disponibles del modelo.
- Asigne entidades lógicas a tablas: cree tablas en el DBMS elegido para representar cada entidad en el modelo de datos lógicos y sus atributos como columnas en la tabla.
- Defina índices y restricciones: cree los índices necesarios para optimizar el rendimiento de las consultas y defina restricciones de clave externa para imponer la integridad referencial entre tablas relacionadas.
- Genere objetos de base de datos: utilice una herramienta de modelado de datos o escriba manualmente scripts SQL para crear los objetos de la base de datos reales, como tablas, índices y restricciones, según el modelo de datos físicos.
El modelo de datos físicos producido en esta etapa final no sólo es un documento crucial para el desarrollo y mantenimiento de la base de datos, sino que también sirve como una referencia importante para otras partes interesadas, incluidos analistas de negocios, desarrolladores y administradores de sistemas.
AppMaster , una potente plataforma sin código , facilita la transición sencilla del modelado de datos a la implementación. Al crear visualmente modelos de datos para aplicaciones backend, los usuarios pueden diseñar esquemas de bases de datos y lógica empresarial utilizando procesos empresariales, API REST y puntos finales WSS diseñados visualmente. AppMaster genera código fuente para aplicaciones, lo que permite una implementación rápida, una integración perfecta y un mantenimiento sencillo de sus modelos de datos. Aproveche el poder de AppMaster para simplificar el modelado de datos y convertir sus conceptos en aplicaciones completamente funcionales.
Técnicas de normalización
Añade lógica a tus datos
Añade reglas de negocio con Business Processes de arrastrar y soltar vinculados a tus datos.
La normalización es un enfoque sistemático utilizado en el diseño de bases de datos relacionales para organizar datos, reducir la redundancia y garantizar la coherencia de los datos. Simplifica la estructura de la base de datos y le permite funcionar de manera eficiente. El proceso implica descomponer una tabla en tablas más pequeñas relacionadas y al mismo tiempo establecer relaciones adecuadas entre ellas. En el proceso de normalización, se utilizan varias formas normales (1NF, 2NF, 3NF, BCNF, 4NF, 5NF) como pautas para lograr diferentes niveles de normalización.
El primer paso en la normalización es lograr la Primera Forma Normal (1NF), que impone las siguientes reglas:
- Cada celda de la tabla debe contener un valor único.
- Todas las entradas de una columna deben ser del mismo tipo de datos.
- Las columnas deben tener nombres únicos.
- No importa el orden en que se almacenen los datos.
Al adherirse a 1NF, la base de datos elimina los grupos repetidos y simplifica la estructura de la tabla.
La Segunda Forma Normal (2NF) tiene como objetivo eliminar las dependencias parciales. Una mesa está en 2NF si:
- Está en 1NF.
- Todos los atributos que no son clave dependen completamente de la clave principal.
Al lograr 2NF, la base de datos garantiza que todos los atributos que no son clave en una tabla describan la clave principal completa, eliminando así dependencias parciales y reduciendo la redundancia.
La Tercera Forma Normal (3NF) elimina las dependencias transitivas. Una mesa está en 3NF si:
- Está en 2NF.
- No existen dependencias transitivas entre atributos que no son clave.
Al adherirse a 3NF, el diseño de la base de datos elimina las dependencias transitivas y reduce aún más la redundancia y las inconsistencias.
La forma normal de Boyce-Codd (BCNF) es una versión más sólida de 3NF que aborda ciertas anomalías que pueden no estar cubiertas por 3NF. Una tabla está en BCNF si:
- Está en 3NF.
- Para cada dependencia funcional no trivial, el determinante es una superclave.
BCNF refina aún más el modelo de datos al garantizar que todas las dependencias funcionales se apliquen estrictamente y se eliminen las anomalías.
La Cuarta Forma Normal (4NF) se ocupa de las dependencias multivaluadas. Una mesa está en 4NF si:
- Está en BCNF.
- No hay dependencias de múltiples valores.
Al adherirse a 4NF, el diseño de la base de datos elimina la información redundante resultante de dependencias de múltiples valores, mejorando así la eficiencia de la base de datos.
La Quinta Forma Normal (5NF) se ocupa de las dependencias de unión. Una mesa está en 5NF si:
- Está en 4NF.
- Las superclaves de la tabla implican todas las dependencias de unión en la tabla.
Al lograr 5NF, el diseño de la base de datos elimina la redundancia adicional y garantiza que la base de datos pueda reconstruirse sin pérdida de información.
Ingeniería inversa de modelos de datos
La ingeniería inversa es el proceso de analizar la estructura existente de una base de datos y generar los modelos de datos correspondientes, generalmente con fines de documentación o migración. La ingeniería inversa puede ayudar a:
- Genere automáticamente modelos de datos para sistemas heredados, donde la documentación original puede faltar o estar desactualizada.
- Descubra las relaciones y dependencias ocultas entre varios elementos de datos en una base de datos.
- Facilitar la migración o integración de bases de datos.
- Documentación de soporte y comprensión de sistemas complejos.
Varias herramientas de modelado de datos ofrecen capacidades de ingeniería inversa, lo que le permite conectarse a una base de datos, extraer el esquema y generar los diagramas ER correspondientes u otros modelos de datos. A veces, es posible que necesite refinar manualmente los modelos de datos generados para representar con precisión los requisitos comerciales subyacentes y simplificar la estructura de la base de datos.
Herramientas de modelado de datos
Haz los datos útiles para los equipos
Crea paneles de administración y portales de clientes que se ajusten a tu estructura de datos normalizada.
Las herramientas de modelado de datos ofrecen un enfoque visual para diseñar esquemas de bases de datos y ayudan a garantizar que los datos se organicen y se acceda a ellos de manera eficiente. Estas herramientas vienen con varias características, como modelado visual, generación de código, control de versiones y soporte para varios sistemas de administración de bases de datos. Algunas herramientas populares de modelado de datos incluyen:
Emergencias/estudio
ER/Studio es una herramienta de arquitectura y modelado de datos que proporciona potentes funciones para diseñar, documentar y gestionar sus estructuras de datos. Admite varias bases de datos, incluidas Oracle, SQL Server, MySQL y PostgreSQL. Las características clave incluyen:
- Modelado de datos visuales para modelos conceptuales, lógicos y físicos.
- Soporte para colaboración en equipo y control de versiones.
- Capacidades de ingeniería directa e inversa.
- Generación automatizada de código para varios lenguajes de programación.
Diseñador de energía
PowerDesigner es una solución integral de arquitectura empresarial y modelado de datos que ofrece varias funciones para diseñar y administrar estructuras de datos en varias plataformas. Las características clave incluyen:
- Soporte para múltiples bases de datos y técnicas de modelado, incluidas entidad-relación, UML, XML y BPMN.
- Capacidades de ingeniería directa e inversa.
- Modelado de movimiento de datos para rastrear y optimizar flujos de datos.
- Análisis de impacto y gestión de cambios para gestionar cambios en múltiples capas de la arquitectura de TI.
Modelador de datos ERwin
ERwin Data Modeler es otra herramienta de modelado de datos ampliamente utilizada, que proporciona funciones para crear, mantener y gestionar estructuras de datos complejas. Las características clave incluyen:
- Soporte para diferentes tipos de bases de datos, como SQL Server, Oracle, MySQL y más.
- Modelado de datos visuales para modelos de datos conceptuales, lógicos y físicos.
- Generación automatizada de código para SQL, DDL y otros lenguajes de programación.
- Capacidades de ingeniería directa e inversa.
- Gestión centralizada de modelos para colaboración, control de versiones y seguridad.
La elección de la herramienta de modelado de datos adecuada depende de las necesidades específicas de su proyecto, como el tamaño y la complejidad de sus estructuras de datos, los sistemas de gestión de bases de datos que utiliza y el nivel de colaboración que requiere. Asegúrese de considerar estos factores al evaluar diferentes herramientas para tomar la mejor decisión para su organización.
Implementación de modelos de datos con AppMaster
Obtén backends listos para producción
Crea backends escalables en Go generados a partir de tu modelo visual y procesos.
AppMaster, una potente plataforma no-code, simplifica el proceso de implementación de modelos de datos para sus aplicaciones backend, web y móviles. Le permite diseñar esquemas de bases de datos, crear lógica de negocios utilizando procesos de negocios diseñados visualmente y generar API REST y puntos finales WSS de manera intuitiva. Al aprovechar AppMaster para sus necesidades de modelado de datos, puede optimizar el proceso de desarrollo de aplicaciones y minimizar el tiempo y el esfuerzo necesarios para hacer realidad sus ideas.
Modelado de datos visuales
Con las herramientas de modelado de datos visuales de AppMaster, puede diseñar fácilmente sus modelos de datos arrastrando y soltando elementos en el lienzo. Defina entidades con sus respectivos atributos, especifique relaciones y restricciones entre ellas. AppMaster admite una amplia gama de tipos de datos, lo que le permite crear fácilmente modelos de datos complejos y sofisticados.
Aplicaciones backend y procesos comerciales
Una vez que su modelo de datos esté implementado, AppMaster puede generar aplicaciones backend utilizando el poderoso lenguaje de programación Go (golang) . Estas aplicaciones son muy eficientes y pueden manejar casos de uso de gran carga a escala empresarial. Business Process Designer de AppMaster le permite crear visualmente la lógica empresarial asociada con su modelo de datos. Al definir flujos de trabajo, reglas y acciones mediante la interfaz drag-and-drop, puede desarrollar rápidamente la funcionalidad principal de su aplicación sin necesidad de codificación manual.
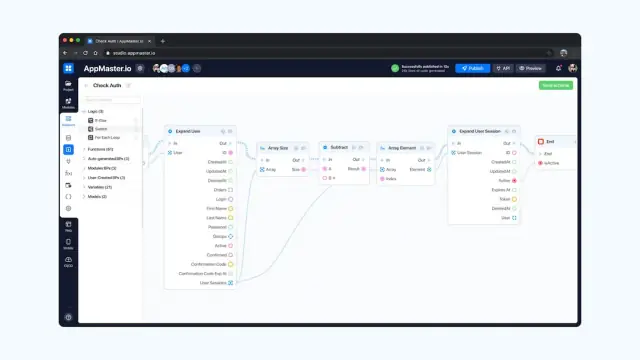
API REST y puntos finales WSS
AppMaster genera automáticamente API REST y puntos finales WSS para sus modelos de datos, lo que permite una comunicación fluida entre sus aplicaciones y la base de datos. Estos endpoints siguen la especificación OpenAPI, lo que garantiza la compatibilidad con varios marcos de front-end y aplicaciones de terceros. La plataforma también genera documentación Swagger para ayudarlo a explorar, probar y administrar la API de manera eficiente.
Generación e implementación de código fuente
AppMaster genera el código fuente para sus aplicaciones, proporcionándole una base sólida sobre la que construir. Con la suscripción Enterprise, puede acceder al código fuente completo de sus aplicaciones e implementarlas localmente. Las aplicaciones generadas utilizan el marco Vue3 para aplicaciones web y Kotlin con Jetpack Compose para Android y SwiftUI para aplicaciones iOS, lo que garantiza un alto rendimiento y compatibilidad.
Eliminando la deuda técnica
Una de las ventajas únicas de utilizar AppMaster es la eliminación de la deuda técnica. AppMaster regenera aplicaciones desde cero cada vez que se realizan cambios en los planos. Este enfoque garantiza que sus aplicaciones estén siempre actualizadas con los últimos principios de diseño y mejores prácticas, lo que reduce significativamente la complejidad y el costo de mantener sus aplicaciones a largo plazo.
Conclusión
El modelado de datos en RDBMS es un componente crucial del proceso de desarrollo de aplicaciones. Comprender los diferentes tipos de modelos de datos y las técnicas y metodologías involucradas en su creación e implementación puede conducir a un proceso de diseño de bases de datos más eficiente y efectivo. Con la plataforma intuitiva no-code de AppMaster, puede diseñar e implementar visualmente modelos de datos, aplicaciones backend, web y móviles, lo que permite un desarrollo rápido de aplicaciones, costos de mantenimiento reducidos y la eliminación de la deuda técnica. Al aprovechar el poder de AppMaster, los desarrolladores y las empresas pueden hacer realidad sus ideas de manera más rápida y eficiente, lo que genera una ventaja competitiva en la industria tecnológica actual.
FAQ
El modelado de datos es el proceso de crear una representación visual de los datos de una organización y cómo se estructuran, almacenan y acceden a ellos. Ayuda a comprender las relaciones entre diferentes entidades de datos y las reglas que rigen su uso.
Hay tres tipos principales de modelos de datos: conceptuales, lógicos y físicos. El modelo conceptual representa la vista de alto nivel de las entidades y relaciones, mientras que el modelo lógico refina el modelo conceptual agregando atributos y definiendo relaciones, y el modelo físico especifica los detalles de implementación reales en un sistema de gestión de bases de datos (DBMS) específico.
El modelado de datos conceptuales es el proceso de crear una representación abstracta de alto nivel de los datos de una organización. Implica identificar las entidades de datos clave, sus atributos y las relaciones entre ellas. Este modelo sirve como base para el modelado de datos lógicos y físicos, garantiza una comprensión clara de los requisitos comerciales y guía el proceso de diseño de la base de datos.
Las técnicas de normalización se utilizan en el diseño de bases de datos para reducir la redundancia de datos y mejorar la eficiencia y coherencia del almacenamiento de datos. El proceso implica organizar datos en tablas, eliminar información duplicada y establecer relaciones entre las tablas. Se utilizan varias formas normales (1NF, 2NF, 3NF, etc.) como pautas para lograr diferentes niveles de normalización.
Algunas herramientas populares de modelado de datos incluyen ER/Studio, PowerDesigner y ERwin Data Modeler. Estas herramientas ofrecen funciones como modelado visual de datos, generación de código y soporte para una amplia gama de sistemas de gestión de bases de datos.
AppMaster, una poderosa plataforma no-code, permite a los usuarios crear visualmente modelos de datos para aplicaciones backend. Los usuarios pueden diseñar esquemas de bases de datos y lógica empresarial utilizando procesos empresariales visualmente diseñados, API REST y puntos finales WSS. AppMaster genera código fuente para aplicaciones, lo que permite una implementación rápida y un mantenimiento sencillo de los modelos de datos.






