उपकरण आरक्षण ऐप: टकराव रोकें और वापसी ट्रैक करें
ऐसा उपकरण आरक्षण ऐप बनाएँ जो दोहरी बुकिंग रोके, वापसी और क्षति दर्ज करे और खराब उपकरणों को मेंटेनेंस होल्ड पर रखे।
अवधारणा से कार्यान्वयन तक संबंधपरक डेटाबेस में डेटा मॉडलिंग की प्रक्रिया में महारत हासिल करें। कुशल विकास के लिए आवश्यक चरणों, तकनीकों, डिज़ाइन पद्धतियों और उपकरणों को समझें।

सॉफ़्टवेयर विकास और डेटाबेस डिज़ाइन में डेटा मॉडलिंग एक महत्वपूर्ण प्रक्रिया है। इसमें किसी संगठन के डेटा और विभिन्न संस्थाओं के बीच संबंधों का एक दृश्य प्रतिनिधित्व बनाना शामिल है। डेटा तत्वों के लिए संरचना, भंडारण और पहुंच विधियों को प्रभावी ढंग से मैप करके, डेवलपर्स और विश्लेषक एक सिस्टम के भीतर डेटा के कुशल संगठन और पुनर्प्राप्ति को सुनिश्चित कर सकते हैं।
रिलेशनल डेटाबेस मैनेजमेंट सिस्टम (आरडीबीएमएस) अच्छी तरह से संरचित और कुशल डेटाबेस बनाने के लिए डेटा मॉडलिंग पर बहुत अधिक निर्भर करते हैं। आरडीबीएमएस में डेटा मॉडल डेटाबेस संरचना को परिभाषित करने, संस्थाओं, विशेषताओं, संबंधों और बाधाओं को निर्दिष्ट करने में मदद करते हैं। एक उचित रूप से डिज़ाइन किया गया डेटा मॉडल डेटा स्थिरता में सुधार कर सकता है, अतिरेक को कम कर सकता है और डेटाबेस संचालन के प्रदर्शन को अनुकूलित कर सकता है।
यह आलेख आरडीबीएमएस में डेटा मॉडलिंग प्रक्रिया, विभिन्न प्रकार के डेटा मॉडल और कुशल और प्रभावी डेटा मॉडलिंग के लिए आवश्यक तकनीकों का अवलोकन प्रदान करता है।
डेटा मॉडलिंग की प्रक्रिया में कई चरण शामिल होते हैं, जिन्हें मोटे तौर पर निम्नलिखित चरणों में समूहीकृत किया जा सकता है:

RDBMS में तीन मुख्य प्रकार के डेटा मॉडल का उपयोग किया जाता है: वैचारिक, तार्किक और भौतिक। प्रत्येक प्रकार का डेटा मॉडल एक अलग उद्देश्य पूरा करता है और एक अलग स्तर के अमूर्तता का प्रतिनिधित्व करता है।
एक वैचारिक डेटा मॉडल संगठन के डेटा का एक उच्च-स्तरीय, अमूर्त प्रतिनिधित्व है। यह किसी कार्यान्वयन विवरण को निर्दिष्ट किए बिना संस्थाओं, उनकी विशेषताओं और संबंधों को कैप्चर करने पर केंद्रित है। वैचारिक डेटा मॉडलिंग का मुख्य लक्ष्य व्यावसायिक आवश्यकताओं को स्पष्ट रूप से समझना और व्यापार विश्लेषकों, डेवलपर्स और अंतिम-उपयोगकर्ताओं जैसे हितधारकों के बीच संचार की सुविधा प्रदान करना है।
एक तार्किक डेटा मॉडल वैचारिक डेटा मॉडल का परिशोधन है, जहां संस्थाओं, विशेषताओं और संबंधों को और अधिक विस्तृत और व्यवस्थित किया जाता है। इस चरण में अतिरिक्त बाधाओं और नियमों को परिभाषित किया गया है, और डेटा तत्वों को तालिकाओं और स्तंभों में व्यवस्थित किया गया है। तार्किक डेटा मॉडल भौतिक डेटा मॉडल का आधार है, जो एक विशिष्ट आरडीबीएमएस में वास्तविक कार्यान्वयन विवरण पर केंद्रित है।
एक भौतिक डेटा मॉडल डेटा मॉडलिंग प्रक्रिया का अंतिम चरण है और एक विशिष्ट आरडीबीएमएस में वास्तविक कार्यान्वयन विवरण का प्रतिनिधित्व करता है। इसमें डेटाबेस संरचना बनाने के लिए आवश्यक तकनीकी विशिष्टताएँ शामिल हैं, जैसे तालिका और स्तंभ नाम, भंडारण आवश्यकताएँ और सूचकांक प्रकार। भौतिक डेटा मॉडलिंग चुने हुए आरडीबीएमएस की विशिष्ट विशेषताओं और विशेषताओं के आधार पर डेटाबेस संचालन के प्रदर्शन को अनुकूलित करने पर केंद्रित है।
वैचारिक डेटा मॉडलिंग डेटा मॉडलिंग प्रक्रिया में पहले चरण का प्रतिनिधित्व करता है, जो किसी संगठन की डेटा आवश्यकताओं के उच्च-स्तरीय, अमूर्त दृश्य पर ध्यान केंद्रित करता है। इसमें डेटा प्रकार या भंडारण के बारे में विशिष्ट विवरण दिए बिना प्रमुख डेटा इकाइयों, उनकी विशेषताओं और उनके बीच संबंधों की पहचान करना शामिल है। वैचारिक डेटा मॉडलिंग का मुख्य लक्ष्य व्यावसायिक आवश्यकताओं को स्पष्ट रूप से समझना और डेटा मॉडलिंग (तार्किक और भौतिक मॉडलिंग) के अगले चरणों के लिए एक ठोस आधार तैयार करना है।
वैचारिक डेटा मॉडलिंग के प्राथमिक घटक हैं:
एक वैचारिक डेटा मॉडल बनाने में कई चरण शामिल होते हैं:
वैचारिक डेटा मॉडलिंग प्रक्रिया के अंत में, आपके पास अपने डेटा मॉडल का एक स्पष्ट, उच्च-स्तरीय प्रतिनिधित्व होगा, जो अगले प्रक्रिया चरण, तार्किक डेटा मॉडलिंग के लिए आधार के रूप में कार्य करता है।
तार्किक डेटा मॉडलिंग विशेषताओं, डेटा प्रकारों और संबंधों के बारे में अधिक विवरण जोड़कर वैचारिक डेटा मॉडल को परिष्कृत और विस्तारित करता है। यह डेटा मॉडल का अधिक विस्तृत प्रतिनिधित्व है जो एक विशिष्ट डेटाबेस प्रबंधन प्रणाली (डीबीएमएस) या प्रौद्योगिकी से स्वतंत्र है। तार्किक डेटा मॉडलिंग का प्राथमिक लक्ष्य संस्थाओं के बीच संरचना और संबंधों को सटीक रूप से परिभाषित करना है, जबकि वास्तविक कार्यान्वयन से कुछ हद तक अमूर्तता बनाए रखना है।
तार्किक डेटा मॉडलिंग के महत्वपूर्ण घटक हैं:
तार्किक डेटा मॉडल बनाने में कई चरण शामिल होते हैं:
तार्किक डेटा मॉडलिंग प्रक्रिया को पूरा करने के बाद, परिणामी मॉडल भौतिक डेटा मॉडलिंग के अंतिम चरण के लिए तैयार है।
भौतिक डेटा मॉडलिंग डेटा मॉडलिंग प्रक्रिया का अंतिम चरण है, जहां तार्किक डेटा मॉडल को एक विशिष्ट डेटाबेस प्रबंधन प्रणाली (डीबीएमएस) और प्रौद्योगिकी का उपयोग करके वास्तविक कार्यान्वयन में अनुवादित किया जाता है। यह डेटा मॉडल का सबसे विस्तृत प्रतिनिधित्व है, जिसमें डेटाबेस ऑब्जेक्ट्स, जैसे टेबल, इंडेक्स, व्यू और बाधाओं को बनाने और प्रबंधित करने के लिए सभी आवश्यक जानकारी शामिल है।
भौतिक डेटा मॉडलिंग के प्रमुख घटकों में शामिल हैं:
भौतिक डेटा मॉडल बनाने में कई चरण शामिल होते हैं:
इस अंतिम चरण में उत्पादित भौतिक डेटा मॉडल न केवल डेटाबेस के विकास और रखरखाव के लिए एक महत्वपूर्ण दस्तावेज है, बल्कि व्यापार विश्लेषकों, डेवलपर्स और सिस्टम प्रशासकों सहित अन्य हितधारकों के लिए एक महत्वपूर्ण संदर्भ के रूप में भी कार्य करता है।
ऐपमास्टर , एक शक्तिशाली नो-कोड प्लेटफ़ॉर्म, डेटा मॉडलिंग से कार्यान्वयन तक आसान संक्रमण की सुविधा प्रदान करता है। बैकएंड अनुप्रयोगों के लिए विज़ुअली डेटा मॉडल बनाकर, उपयोगकर्ता विज़ुअली डिज़ाइन की गई व्यावसायिक प्रक्रियाओं, REST API और WSS एंडपॉइंट्स का उपयोग करके डेटाबेस स्कीमा, व्यावसायिक तर्क डिज़ाइन कर सकते हैं। AppMaster अनुप्रयोगों के लिए स्रोत कोड उत्पन्न करता है, जो त्वरित कार्यान्वयन, निर्बाध एकीकरण और आपके डेटा मॉडल के आसान रखरखाव की अनुमति देता है। डेटा मॉडलिंग को सरल बनाने और अपनी अवधारणाओं को पूरी तरह कार्यात्मक अनुप्रयोगों में बदलने के लिए AppMaster की शक्ति का उपयोग करें।
सामान्यीकरण एक व्यवस्थित दृष्टिकोण है जिसका उपयोग डेटा को व्यवस्थित करने, अतिरेक को कम करने और डेटा स्थिरता सुनिश्चित करने के लिए रिलेशनल डेटाबेस डिज़ाइन में किया जाता है। यह डेटाबेस की संरचना को सरल बनाता है और इसे कुशलतापूर्वक कार्य करने की अनुमति देता है। इस प्रक्रिया में एक तालिका को छोटी, संबंधित तालिकाओं में विघटित करना और उनके बीच उचित संबंध स्थापित करना शामिल है। सामान्यीकरण प्रक्रिया में, सामान्यीकरण के विभिन्न स्तरों को प्राप्त करने के लिए दिशानिर्देश के रूप में कई सामान्य रूपों (1NF, 2NF, 3NF, BCNF, 4NF, 5NF) का उपयोग किया जाता है।
सामान्यीकरण में पहला कदम पहला सामान्य फॉर्म (1NF) प्राप्त करना है, जो निम्नलिखित नियमों को लागू करता है:
1NF का पालन करके, डेटाबेस दोहराए जाने वाले समूहों को हटा देता है और तालिका की संरचना को सरल बनाता है।
दूसरा सामान्य फॉर्म (2NF) का उद्देश्य आंशिक निर्भरता को दूर करना है। एक तालिका 2NF में है यदि:
2NF प्राप्त करके, डेटाबेस यह सुनिश्चित करता है कि तालिका में सभी गैर-कुंजी विशेषताएँ संपूर्ण प्राथमिक कुंजी का वर्णन कर रही हैं, इस प्रकार आंशिक निर्भरताएँ दूर हो जाती हैं और अतिरेक कम हो जाता है।
तीसरा सामान्य फॉर्म (3NF) सकर्मक निर्भरता को समाप्त करता है। एक तालिका 3NF में है यदि:
3NF का पालन करके, डेटाबेस डिज़ाइन सकर्मक निर्भरता को समाप्त करता है और अतिरेक और विसंगतियों को कम करता है।
बॉयस-कॉड नॉर्मल फॉर्म (बीसीएनएफ) 3एनएफ का एक मजबूत संस्करण है जो कुछ विसंगतियों को संबोधित करता है जो 3एनएफ द्वारा कवर नहीं किए जा सकते हैं। एक तालिका बीसीएनएफ में है यदि:
बीसीएनएफ यह सुनिश्चित करके डेटा मॉडल को और परिष्कृत करता है कि सभी कार्यात्मक निर्भरताएं सख्ती से लागू की जाती हैं और विसंगतियां समाप्त हो जाती हैं।
चौथा सामान्य फॉर्म (4NF) बहु-मूल्यवान निर्भरता से संबंधित है। एक तालिका 4NF में है यदि:
4NF का पालन करके, डेटाबेस डिज़ाइन बहु-मूल्यवान निर्भरताओं के परिणामस्वरूप अनावश्यक जानकारी को समाप्त कर देता है, जिससे डेटाबेस की दक्षता में सुधार होता है।
पांचवां सामान्य फॉर्म (5NF) जुड़ाव निर्भरता से संबंधित है। एक तालिका 5NF में है यदि:
5NF प्राप्त करके, डेटाबेस डिज़ाइन अतिरिक्त अतिरेक को समाप्त करता है और यह सुनिश्चित करता है कि डेटाबेस को जानकारी के नुकसान के बिना पुनर्निर्माण किया जा सकता है।
रिवर्स इंजीनियरिंग डेटाबेस की मौजूदा संरचना का विश्लेषण करने और संबंधित डेटा मॉडल तैयार करने की प्रक्रिया है, आमतौर पर दस्तावेज़ीकरण या माइग्रेशन उद्देश्यों के लिए। रिवर्स इंजीनियरिंग इसमें मदद कर सकती है:
विभिन्न डेटा मॉडलिंग उपकरण रिवर्स इंजीनियरिंग क्षमताएं प्रदान करते हैं, जो आपको डेटाबेस से जुड़ने, स्कीमा निकालने और संबंधित ईआर आरेख या अन्य डेटा मॉडल उत्पन्न करने की अनुमति देते हैं। कभी-कभी, आपको अंतर्निहित व्यावसायिक आवश्यकताओं को सटीक रूप से प्रस्तुत करने और डेटाबेस संरचना को सरल बनाने के लिए जेनरेट किए गए डेटा मॉडल को मैन्युअल रूप से परिष्कृत करने की आवश्यकता हो सकती है।
डेटा मॉडलिंग उपकरण डेटाबेस स्कीमा को डिजाइन करने के लिए एक दृश्य दृष्टिकोण प्रदान करते हैं और यह सुनिश्चित करने में मदद करते हैं कि डेटा व्यवस्थित और कुशलतापूर्वक एक्सेस किया गया है। ये उपकरण विभिन्न सुविधाओं के साथ आते हैं, जैसे विज़ुअल मॉडलिंग, कोड जनरेशन, संस्करण नियंत्रण और विभिन्न डेटाबेस प्रबंधन प्रणालियों के लिए समर्थन। कुछ लोकप्रिय डेटा मॉडलिंग टूल में शामिल हैं:
ER/Studio एक डेटा मॉडलिंग और आर्किटेक्चर टूल है जो आपके डेटा संरचनाओं को डिजाइन करने, दस्तावेज़ीकरण और प्रबंधित करने के लिए शक्तिशाली सुविधाएँ प्रदान करता है। यह Oracle, SQL Server, MySQL और PostgreSQL सहित कई डेटाबेस का समर्थन करता है। प्रमुख विशेषताओं में शामिल हैं:
PowerDesigner एक व्यापक डेटा मॉडलिंग और एंटरप्राइज आर्किटेक्चर समाधान है, जो विभिन्न प्लेटफार्मों पर डेटा संरचनाओं को डिजाइन और प्रबंधित करने के लिए विभिन्न सुविधाएँ प्रदान करता है। प्रमुख विशेषताओं में शामिल हैं:
ERwin Data Modeler एक और व्यापक रूप से उपयोग किया जाने वाला डेटा मॉडलिंग टूल है, जो जटिल डेटा संरचनाओं को बनाने, बनाए रखने और प्रबंधित करने की सुविधाएँ प्रदान करता है। प्रमुख विशेषताओं में शामिल हैं:
सही डेटा मॉडलिंग टूल का चयन आपके प्रोजेक्ट की विशिष्ट आवश्यकताओं पर निर्भर करता है, जैसे आपके डेटा संरचनाओं का आकार और जटिलता, आपके द्वारा उपयोग की जाने वाली डेटाबेस प्रबंधन प्रणाली और आपके द्वारा आवश्यक सहयोग का स्तर। अपने संगठन के लिए सर्वोत्तम निर्णय लेने के लिए विभिन्न उपकरणों का मूल्यांकन करते समय इन कारकों पर विचार करना सुनिश्चित करें।
AppMaster, एक शक्तिशाली no-code प्लेटफ़ॉर्म, आपके बैकएंड, वेब और मोबाइल एप्लिकेशन के लिए डेटा मॉडल लागू करने की प्रक्रिया को सरल बनाता है। यह आपको डेटाबेस स्कीमा डिज़ाइन करने, विज़ुअली डिज़ाइन की गई व्यावसायिक प्रक्रियाओं का उपयोग करके व्यावसायिक तर्क बनाने और सहजता से REST API और WSS एंडपॉइंट उत्पन्न करने की अनुमति देता है। अपनी डेटा मॉडलिंग आवश्यकताओं के लिए AppMaster लाभ उठाकर, आप अपनी एप्लिकेशन विकास प्रक्रिया को सुव्यवस्थित कर सकते हैं और अपने विचारों को जीवन में लाने के लिए आवश्यक समय और प्रयास को कम कर सकते हैं।
AppMaster के विज़ुअल डेटा मॉडलिंग टूल के साथ, आप तत्वों को कैनवास पर खींचकर और छोड़ कर आसानी से अपने डेटा मॉडल डिज़ाइन कर सकते हैं। संस्थाओं को उनकी संबंधित विशेषताओं के साथ परिभाषित करें, उनके बीच संबंध और बाधाएं निर्दिष्ट करें। AppMaster डेटा प्रकारों की एक विस्तृत श्रृंखला का समर्थन करता है, जिससे आप आसानी से जटिल और परिष्कृत डेटा मॉडल बना सकते हैं।
एक बार जब आपका डेटा मॉडल स्थापित हो जाता है, AppMaster शक्तिशाली गो (गोलंग) प्रोग्रामिंग भाषा का उपयोग करके बैकएंड एप्लिकेशन उत्पन्न कर सकता है। ये एप्लिकेशन अत्यधिक कुशल हैं और एंटरप्राइज़-स्केल हाईलोड उपयोग-मामलों को संभाल सकते हैं। AppMaster का बिजनेस प्रोसेस डिज़ाइनर आपको अपने डेटा मॉडल से जुड़े बिजनेस लॉजिक को दृश्य रूप से बनाने की सुविधा देता है। drag-and-drop इंटरफ़ेस का उपयोग करके वर्कफ़्लो, नियमों और क्रियाओं को परिभाषित करके, आप मैन्युअल कोडिंग की आवश्यकता के बिना अपने एप्लिकेशन की मुख्य कार्यक्षमता को जल्दी से विकसित कर सकते हैं।
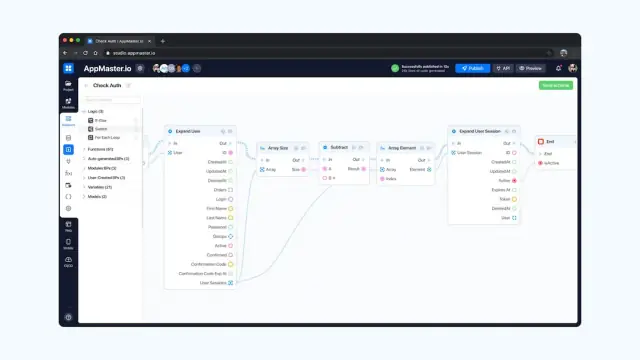
AppMaster स्वचालित रूप से आपके डेटा मॉडल के लिए REST API और WSS एंडपॉइंट उत्पन्न करता है, जिससे आपके एप्लिकेशन और डेटाबेस के बीच सहज संचार सक्षम होता है। ये endpoints ओपनएपीआई विनिर्देश का पालन करते हैं, जो विभिन्न फ्रंट-एंड फ्रेमवर्क और तृतीय-पक्ष अनुप्रयोगों के साथ संगतता सुनिश्चित करते हैं। प्लेटफ़ॉर्म आपको एपीआई को कुशलतापूर्वक खोजने, परीक्षण करने और प्रबंधित करने में मदद करने के लिए स्वैगर दस्तावेज़ भी तैयार करता है।
AppMaster आपके एप्लिकेशन के लिए स्रोत कोड तैयार करता है, जो आपको निर्माण के लिए एक ठोस आधार प्रदान करता है। एंटरप्राइज़ सदस्यता के साथ, आप अपने एप्लिकेशन के संपूर्ण स्रोत कोड तक पहुंच सकते हैं और उन्हें ऑन-प्रिमाइसेस तैनात कर सकते हैं। जेनरेट किए गए एप्लिकेशन वेब अनुप्रयोगों के लिए Vue3 फ्रेमवर्क और एंड्रॉइड के लिए Jetpack Compose के साथ कोटलिन और iOS अनुप्रयोगों के लिए SwiftUI का उपयोग करते हैं, जो उच्च प्रदर्शन और अनुकूलता सुनिश्चित करते हैं।
AppMaster का उपयोग करने का एक अनूठा लाभ तकनीकी ऋण का उन्मूलन है। हर बार ब्लूप्रिंट में बदलाव किए जाने पर AppMaster एप्लिकेशन को नए सिरे से तैयार करता है। यह दृष्टिकोण सुनिश्चित करता है कि आपके एप्लिकेशन नवीनतम डिज़ाइन सिद्धांतों और सर्वोत्तम प्रथाओं के साथ हमेशा अद्यतित रहें, जिससे लंबे समय तक आपके एप्लिकेशन को बनाए रखने की जटिलता और लागत काफी कम हो जाती है।
आरडीबीएमएस में डेटा मॉडलिंग अनुप्रयोग विकास प्रक्रिया का एक महत्वपूर्ण घटक है। विभिन्न प्रकार के डेटा मॉडल और उनके निर्माण और कार्यान्वयन में शामिल तकनीकों और कार्यप्रणाली को समझने से अधिक कुशल और प्रभावी डेटाबेस डिजाइन प्रक्रिया हो सकती है। AppMaster के सहज ज्ञान युक्त no-code प्लेटफ़ॉर्म के साथ, आप डेटा मॉडल, बैकएंड, वेब और मोबाइल एप्लिकेशन को डिज़ाइन और तैनात कर सकते हैं, जिससे तेज़ एप्लिकेशन विकास, कम रखरखाव लागत और तकनीकी ऋण का उन्मूलन सक्षम हो सकता है। AppMaster की शक्ति का लाभ उठाकर, डेवलपर्स और व्यवसाय अपने विचारों को अधिक तेज़ी से और कुशलता से जीवन में ला सकते हैं, जिसके परिणामस्वरूप आज के तकनीकी उद्योग में प्रतिस्पर्धात्मक लाभ हो सकता है।
डेटा मॉडलिंग किसी संगठन के डेटा का दृश्य प्रतिनिधित्व बनाने और इसे कैसे संरचित, संग्रहीत और एक्सेस किया जाता है, इसकी प्रक्रिया है। यह विभिन्न डेटा संस्थाओं और उनके उपयोग को नियंत्रित करने वाले नियमों के बीच संबंधों को समझने में मदद करता है।
डेटा मॉडल के तीन मुख्य प्रकार हैं: वैचारिक, तार्किक और भौतिक। वैचारिक मॉडल संस्थाओं और रिश्तों के उच्च-स्तरीय दृष्टिकोण का प्रतिनिधित्व करता है, जबकि तार्किक मॉडल विशेषताओं को जोड़कर और रिश्तों को परिभाषित करके वैचारिक मॉडल को परिष्कृत करता है, और भौतिक मॉडल एक विशिष्ट डेटाबेस प्रबंधन प्रणाली (डीबीएमएस) में वास्तविक कार्यान्वयन विवरण निर्दिष्ट करता है।
वैचारिक डेटा मॉडलिंग किसी संगठन के डेटा का उच्च-स्तरीय, अमूर्त प्रतिनिधित्व बनाने की प्रक्रिया है। इसमें प्रमुख डेटा इकाइयों, उनकी विशेषताओं और उनके बीच संबंधों की पहचान करना शामिल है। यह मॉडल तार्किक और भौतिक डेटा मॉडलिंग के लिए एक आधार के रूप में कार्य करता है, व्यावसायिक आवश्यकताओं की स्पष्ट समझ सुनिश्चित करता है और डेटाबेस डिजाइन प्रक्रिया का मार्गदर्शन करता है।
डेटा अतिरेक को कम करने और डेटा भंडारण की दक्षता और स्थिरता में सुधार करने के लिए डेटाबेस डिज़ाइन में सामान्यीकरण तकनीकों का उपयोग किया जाता है। इस प्रक्रिया में डेटा को तालिकाओं में व्यवस्थित करना, डुप्लिकेट जानकारी को समाप्त करना और तालिकाओं के बीच संबंध स्थापित करना शामिल है। सामान्यीकरण के विभिन्न स्तरों को प्राप्त करने के लिए दिशानिर्देश के रूप में कई सामान्य रूपों (1NF, 2NF, 3NF, आदि) का उपयोग किया जाता है।
कुछ लोकप्रिय डेटा मॉडलिंग टूल में ईआर/स्टूडियो, पावरडिज़ाइनर और ईआरविन डेटा मॉडलर शामिल हैं। ये उपकरण विज़ुअल डेटा मॉडलिंग, कोड जनरेशन और डेटाबेस प्रबंधन प्रणालियों की एक विस्तृत श्रृंखला के लिए समर्थन जैसी सुविधाएँ प्रदान करते हैं।
AppMaster, एक शक्तिशाली no-code प्लेटफ़ॉर्म, उपयोगकर्ताओं को बैकएंड अनुप्रयोगों के लिए दृश्य रूप से डेटा मॉडल बनाने की अनुमति देता है। उपयोगकर्ता विज़ुअल रूप से डिज़ाइन की गई व्यावसायिक प्रक्रियाओं, REST API और WSS एंडपॉइंट का उपयोग करके डेटाबेस स्कीमा, व्यावसायिक तर्क डिज़ाइन कर सकते हैं। AppMaster अनुप्रयोगों के लिए स्रोत कोड उत्पन्न करता है, जिससे त्वरित कार्यान्वयन और डेटा मॉडल का आसान रखरखाव सक्षम होता है।



फ्री प्लान के साथ ऐपमास्टर के साथ प्रयोग करें।
जब आप तैयार होंगे तब आप उचित सदस्यता चुन सकते हैं।


