تطبيق حجز المعدات: امنع التعارضات وتتبع الإرجاعات
خطط لتطبيق لحجز المعدات يمنع الحجوزات المزدوجة، ويسجل الإرجاعات والأضرار، ويضع العناصر المعطلة قيد الصيانة.
إعداد مراقبة مبسّط لخوادم تعتمد على CRUD: سجلات مهيكلة، مقاييس أساسية، وتنبيهات عملية لاكتشاف الاستعلامات البطيئة والأخطاء والانقطاعات مبكرًا.
تطبيقات الأعمال التي تعتمد على CRUD تفشل عادةً بطرق مملة ومكلفة. صفحة قائمة تصبح أبطأ كل أسبوع، زر الحفظ أحيانًا يتوقف عن العمل، والدعم يبلّغ عن "500s عشوائية" لا يمكنك إعادة إنتاجها. لا شيء يبدو معطلاً في التطوير، لكن الإنتاج يصبح غير موثوق.
التكلفة الحقيقية ليست الحادث نفسه فحسب. إنها الوقت الذي تُقضيه في التخمين. بدون إشارات واضحة، يتنقل الفريق بين "لابد أن المشكلة في قاعدة البيانات"، "لابد أنها الشبكة"، و"لابد أنها نقطة النهاية تلك" بينما ينتظر المستخدمون وتتبخر الثقة.
المراقبة الشاملة تحوّل تلك التخمينات إلى إجابات. ببساطة: يمكنك النظر إلى ما حدث وفهم السبب. تصل إلى ذلك بثلاثة أنواع من الإشارات:
بالنسبة لتطبيقات CRUD وخدمات API، الأمر أقل عن لوحات جميلة وأكثر عن التشخيص السريع. عندما يتباطأ نداء "إنشاء فاتورة"، يجب أن تكون قادرًا على معرفة ما إذا كان التأخير من استعلام قاعدة البيانات، أو API خارجي، أو عامل مثقل خلال دقائق، وليس ساعات.
إعداد مبسّط يبدأ من الأسئلة التي تحتاج فعلًا للإجابة عنها في يوم سيئ:
إذا بنت الخوادم الخلفية باستخدام ستاك مولد (مثلاً، AppMaster الذي يولّد خدمات Go)، ينطبق نفس القاعدة: ابدأ صغيرًا، حافظ على تناسق الإشارات، وأضف مقاييس أو تنبيهات جديدة فقط بعد أن يثبت حادث حقيقي أنها كانت ستختصر وقتًا.
إعداد المراقبة المبسّط يعتمد على ثلاثة أعمدة: السجلات، المقاييس، والتنبيهات. التتبعات مفيدة، لكنها زائد لغالبيّة تطبيقات CRUD.
الهدف واضح. يجب أن تعرف (1) متى يفشل المستخدمون، (2) لماذا يفشلون، و(3) أين في النظام يحدث ذلك. إذا لم تستطع الإجابة عن هذه بسرعة، ستضيع وقتًا في التخمين والجدال حول ما تغيّر.
أصغر مجموعة إشارات عادةً ما توصلك تكون كالتالي:
request_id، المستخدم، نقطة النهاية، والخطأ.يساعد أيضًا فصل الأعراض عن الأسباب. العرض هو ما يشعر به المستخدمون: 500s، مهلات، صفحات بطيئة. السبب هو ما أوجدها: تناحر أقفال، تجمع اتصالات مستنفد، أو استعلام بطيء بعد إضافة فلتر جديد. أنبه على الأعراض واستخدم إشارات "السبب" للتحقيق.
قاعدة عملية: اختر مكانًا واحدًا لعرض الإشارات المهمة. التبديل بين أداة سجلات، أداة مقاييس، وصندوق تنبيهات منفصل يبطئك عندما يهم الأمر أكثر.
عندما ينهار شيء، أسرع طريق للإجابة عادةً هو: "أي طلب بالضبط ضرب هذا المستخدم؟" ولهذا السبب تهم معرفات الارتباط أكثر من أي تعديل سجلات آخر تقريبًا.
اختر اسم حقل واحد (شائعًا request_id) واجعله مطلوبًا. ولّده عند الحافة (API gateway أو المعالج الأول)، مرّره عبر الاستدعاءات الداخلية، وادمجه في كل سطر سجل. بالنسبة للوظائف الخلفية، أنشئ request_id جديد لكل تشغيل وظيفة وخزّن parent_request_id عندما تُشغّل الوظيفة بواسطة نداء API.
سجّل بصيغة JSON، لا نصًا حرًا. هذا يحافظ على قابلية البحث واتساق السجلات عندما تكون متعبًا أو تحت ضغط.
مجموعة بسيطة من الحقول تكفي لمعظم خدمات CRUD-heavy:
timestamp, level, service, envrequest_id, route, method, statusduration_ms, db_query_counttenant_id أو account_id (معرّفات آمنة، ليست بيانات شخصية)يجب أن تساعد السجلات في تضييق نطاق "أي عميل وأي شاشة"، دون أن تتحول إلى تسريب بيانات. تجنّب الأسماء، الإيميلات، أرقام الهواتف، العناوين، الرموز، أو هيئات الطلب كاملة افتراضيًا. إذا احتجت تفاصيل أعمق، سجّلها فقط عند الطلب ومع التنقيح.
حقلان يدفعان ثمارهما بسرعة في أنظمة CRUD: duration_ms و db_query_count. يكتشفان المعالجات البطيئة وأنماط N+1 العرضية حتى قبل أن تضيف تتبعًا.
عرّف مستويات السجل بحيث يستخدمها الجميع بنفس الطريقة:
info: أحداث متوقعة (انتهى الطلب، بدأت وظيفة)warn: غير اعتيادي لكن قابل للاسترداد (طلب بطيء، إعادة المحاولة نجحت)error: طلب أو وظيفة فاشلة (استثناء، مهلة، تبعية سيئة)إذا بنيت خلفيات باستخدام منصة مثل AppMaster، حافظ على نفس أسماء الحقول عبر الخدمات المولّدة حتى يعمل "البحث حسب request_id" في كل مكان.
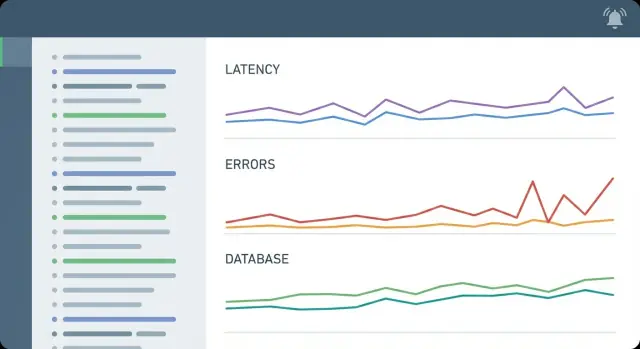
معظم الحوادث في تطبيقات CRUD لها شكل مألوف: بطيء في نقطة نهاية أو اثنتين، تَجهد قاعدة البيانات، والمستخدمون يرون مؤشرات انتظار أو مهلات. يجب أن تجعل مقاييسك تلك القصة واضحة خلال دقائق.
مجموعة مبسطة عادةً تغطي خمسة مجالات:
تفصيلان يجعلان المقاييس أكثر قابلية للعمل.
أولًا، فصل طلبات API التفاعلية عن العمل الخلفي. مرسل بريد بطيء أو حلقة إعادة المحاولة قد تجوع CPU، اتصالات DB، أو الشبكة الصادرة وتجعل API يبدو "بلا سبب". راقب القوائم، الإعادات، وزمن الوظائف كسلاسل زمنية منفصلة، حتى لو كانت تعمل في نفس الخلفية.
ثانيًا، أرفق بيانات الإصدار/البناء دائمًا بلوحات التحكم والتنبيهات. عند نشر خلفية مولّدة جديدة (مثلاً بعد تجديد الشيفرة من أداة no-code مثل AppMaster)، تريد الإجابة بسرعة: هل زاد معدل الخطأ أو زمن p95 مباشرة بعد هذا الإصدار؟
قاعدة بسيطة: إذا كان المقياس لا يمكنه أن يخبرك ماذا تفعل بعد ذلك (التراجع، التوسع، إصلاح استعلام، أو إيقاف وظيفة)، فإنه لا ينتمي إلى مجموعتك الحدّية.
في تطبيقات CRUD، غالبًا ما تكون قاعدة البيانات هي المكان الذي "يصبح فيه الشعور بالبطء" ألمًا حقيقيًا للمستخدم. يجب أن يجعل الإعداد المبسّط واضحًا عندما يكون عنق الزجاجة في PostgreSQL (ليس كود الـ API)، ونوع مشكلة DB هذه.
لا تحتاج لعشرات اللوحات. ابدأ بإشارات تشرح معظم الحوادث:
أضف توزيع أزمنة الاستعلام في طبقة الـ API ووسّمه بنقطة النهاية أو حالة الاستخدام (مثلاً: GET /customers، “search orders”، “update ticket status”). هذا يظهر ما إذا كانت نقطة النهاية بطيئة لأنها تشغّل العديد من الاستعلامات الصغيرة أو استعلامًا واحدًا كبيرًا.
شاشات CRUD كثيرًا ما تطلق N+1: استعلام قائمة واحد، ثم استعلام واحد لكل صف لجلب بيانات مرتبطة. راقب نقاط النهاية التي يظل فيها معدل الطلبات ثابتًا لكن عدد استعلامات DB لكل طلب يرتفع. إذا كنت تولّد خلفيات من النماذج والمنطق التجاري، فهنا غالبًا ما تضبط نمط الجلب.
إذا كان لديك ذاكرة مخبئة بالفعل، راقب معدل الضرب (hit rate). لا تضف ذاكرة فقط لتحسين الرسوم.
عامل تغيّرات المخطط والترحيلات كنافذة مخاطر. سجّل وقت بدايتها ونهايتها، ثم راقب لارتفاعات في الأقفال، زمن الاستعلام، وأخطاء الاتصال في تلك النافذة.
يجب أن تشير التنبيهات إلى مشكلة مستخدم حقيقية، لا إلى رسم بياني مزدحم. لتطبيقات CRUD، ابدأ بمراقبة ما يشعر به المستخدمون: الأخطاء والبطء.
إذا أضفت ثلاثة تنبيهات فقط في البداية، اجعلها:
بعد ذلك، أضف بعض تنبيهات "السبب المحتمل". غالبًا ما تفشل خلفيات CRUD بطرق متوقعة: قاعدة البيانات تنفد من الاتصالات، تراكم قوائم الوظائف، أو نقطة نهاية واحدة تبدأ بالمهلة وتسحب الأداء لباقي الـ API.
تحديد أرقام ثابتة مثل "p95 > 200ms" نادرًا ما ينجح عبر البيئات. قس أسبوعًا عاديًا، ثم ضع التنبيه فوق الطبيعي مع هامش أمان. مثلاً، إذا كان p95 عادةً 350-450ms خلال ساعات العمل، انبه عند 700ms لمدة 10 دقائق. إذا كان 5xx عادةً 0.1-0.3%، فاطلب الاتصال عند 2% لمدة 5 دقائق.
حافظ على ثبات العتبات. لا تضبطها كل يوم. اضبطها بعد حادث عندما يمكنك ربط التغييرات بنتائج حقيقية.
استخدم درجتي شدة حتى يثق الناس بالإشارة:
كتم التنبيهات خلال تغيّرات متوقعة مثل نوافذ النشر والصيانة المخطط لها.
اجعل التنبيهات قابلة للعمل. أضف "ما يجب فحصه أولًا" (أهم نقطة نهاية، اتصالات DB، نشر حديث) و"ما تغيّر" (إصدار جديد، تحديث مخطط). إذا بنيت في AppMaster، لاحظ أي خلفية أو وحدة جُدّدت ونُشرت مؤخرًا، لأن ذلك غالبًا ما يكون الخيط الأسرع.
تصبح الإعدادات المبسطة أسهل عندما تقرر ماذا يعني "كافٍ". هذا ما تفعله SLOs: أهداف واضحة تحول المراقبة الفضفاضة إلى تنبيهات محددة.
ابدأ بـ SLIs التي تتطابق مع ما يشعر به المستخدمون: التوفر (هل يمكن للمستخدمين إكمال الطلبات)، الزمن (كم تستغرق الإجراءات)، ومعدل الأخطاء (كم مرة تفشل الطلبات).
ضع SLOs لمجموعات نقاط نهاية، لا لكل مسار. لتطبيقات CRUD هذا يبقي الأمور مقروءة: قراءات (GET/list/search)، كتابات (create/update/delete)، والمصادقة (login/token refresh). هذا يتجنب مئات SLOs الصغيرة التي لا أحد يصونها.
أمثلة بسيطة تتناسب مع التوقعات النموذجية:
ميزانية الأخطاء هي الوقت المسموح به "السيئ" ضمن SLO. SLO توفر 99.9% شهريًا تعني أنك مسموح لك بنحو 43 دقيقة من التوقف شهريًا. إذا أنفقت الوقت مبكرًا، أوقف التغييرات الخطرة حتى تعود الاستقرارية.
استخدم SLOs لتقرير ما يستحق تنبيهًا مقابل ما هو اتجاه في لوحة. أنبه عندما تحرق ميزانية الخطأ بسرعة (المستخدمون يفشلون فعليًا)، لا عندما يبدو مقياس ما أسوأ قليلًا من الأمس.
إذا بنت الخلفيات بسرعة (مثلاً، مع AppMaster الذي يولد خدمة Go)، تحافظ SLOs على التركيز على تأثير المستخدم حتى مع تغير التنفيذ تحته.
ابدأ بالشريحة من النظام التي يلمسها المستخدمون أكثر. اختر نداءات API والوظائف التي، إذا كانت بطيئة أو معطلة، تجعل التطبيق كله يبدو معطلًا.
اكتب نقاط النهاية والوظائف الخلفية الأعلى أهمية. في تطبيق CRUD، عادةً ما تكون هذه تسجيل الدخول، القوائم/البحث، الإنشاء/التحديث، ووظيفة تصدير أو استيراد واحدة. إذا بنيت الخلفية بـ AppMaster، أدرج نقاط النهاية المولّدة وأي تدفقات أعمال تُشغّل بجدولة أو webhooks.
request_id, user_id (إن توفر), endpoint, status_code, latency_ms, db_time_ms, ورمز خطأ قصير error_code للفشل المعروف.حافظ على قلة وتركيز التنبيهات. تريد تنبيهات تشير إلى تأثير المستخدم، لا "شيء ما تغيّر".
مجموعة بداية جيدة: p95 زمن API مرتفع، معدل 5xx المستمر، ارتفاع مفاجئ في 4xx (غالبًا مصادقة أو تغيرات التحقق)، فشل وظائف خلفية، استعلامات DB بطيئة، اتصالات DB قرب الحد، ومساحة قرص منخفضة (إذا تستضيف بنفسك).
ثم اكتب دفتر تشغيل صغير لكل تنبيه. صفحة واحدة تكفي: ماذا تفحص أولًا (لوحات الحصص وحقول السجل الرئيسية)، الأسباب المحتملة (أقفال DB، فهرس مفقود، استعلام بطيء بعد إضافة فلتر)، والإجراء الآمن الأول (إعادة تشغيل عامل معلق، التراجع عن تغيير، إيقاف وظيفة ثقيلة).
أسرع طريقة لإهدار إعداد مراقبة صغير هي معاملته كخانة يجب وضع علامة عليها. تطبيقات CRUD تفشل عادة بطرق متوقعة قليلة (استدعاءات DB البطيئة، المهلات، الإصدارات السيئة)، لذا يجب أن تظل إشاراتك مركزة على ذلك.
الخطأ الأكثر شيوعًا هو إرهاق التنبيهات: تنبيهات كثيرة جدًا، وقليل من الإجراءات. إذا استدعيته على كل ارتفاع، سيتوقف الناس عن الثقة بالتنبيهات خلال أسبوعين. قاعدة جيدة: يجب أن تشير التنبيه إلى إصلاح محتمل، لا "شيء ما تغيّر".
خطأ كلاسيكي آخر هو فقدان معرفات الارتباط. إذا لم تتمكن من ربط سجل خطأ، طلب بطيء، واستعلام DB بطلب واحد، ستفقد ساعات. تأكد أن كل طلب يحصل على request_id (وأدرجه في السجلات، والتتبعات إن وُجدت، والاستجابات عندما يكون آمنًا).
الأنظمة المزعجة تشترك في نفس المشاكل:
تطبيقات CRUD عرضة بشكل خاص لـ "فخ المتوسط". استعلام واحد بطيء يمكن أن يجعل 5% من الطلبات مؤلمة بينما يبدو المتوسط جيدًا. زمن الذيل ومعدل الأخطاء يعطيان صورة أوضح.
أضف علامات نشر. سواء شحنت من CI أو جددت الشيفرة عبر منصة مثل AppMaster، سجّل النسخة ووقت النشر كحدث وفي سجلاتك.
إعدادك يعمل عندما تستطيع الإجابة على بعض الأسئلة بسرعة، دون التنقّب في اللوحات 20 دقيقة. إذا لم تستطع الوصول إلى "نعم/لا" بسرعة، فهناك إشارة مفقودة أو عروض مبعثرة.
يجب أن تكون قادرًا على فعل معظم هذا في أقل من دقيقة:
يجب أن تكون السجلات آمنة ومفيدة في نفس الوقت. تحتاج سياقًا كافيًا لتتبع طلب فاشل عبر الخدمات، لكن لا يجب أن تكشف بيانات شخصية.
اختر فشلًا حديثًا وافتح سجلاته. أكد أن لديك request_id, النقطة النهائية، رمز الحالة، المدة، ورسالة خطأ واضحة. وأكد أيضًا أنك لا تسجل رموز، كلمات مرور، تفاصيل دفع كاملة، أو حقول شخصية خام.
إذا كنت تبني خلفيات CRUD-heavy مع AppMaster، استهدف "عرض الحادث" واحدًا يجمع هذه الفحوصات: الأخطاء، p95 زمن الاستجابة بحسب نقطة النهاية، وصحة DB. هذا وحده يغطي أغلب الانقطاعات الحقيقية في تطبيقات الأعمال.
بوابة إدارية داخلية تعمل جيدًا طوال الصباح، ثم تصبح بطيئة خلال ساعة ذروة. يشكو المستخدمون من أن فتح قائمة “Orders” وحفظ التعديلات يستغرق 10 إلى 20 ثانية.
تبدأ بالإشارات العليا. لوحة الـ API تظهر أن p95 لعمليات القراءة ارتفع من ~300ms إلى 4-6s، بينما معدل الأخطاء بقي منخفضًا. في نفس الوقت، لوحة قاعدة البيانات تظهر اتصالات نشطة قرب حد التجمع وارتفاعًا في انتظار الأقفال. CPU على العقد الخلفية طبيعي، إذًا لا يبدو أنه مشكلة حسابية.
بعد ذلك تختار طلبًا بطيئًا وتتتبعه عبر السجلات. صفّ الحساب بحسب النقطة النهاية (مثلاً GET /orders) ورتّب بحسب المدة. التقط request_id من طلب 6 ثوانٍ وابحث عنه عبر الخدمات. ترى أن المعالج انتهى بسرعة، لكن سطر سجل استعلام DB ضمن نفس request_id يظهر استعلامًا استغرق 5.4 ثوانٍ مع rows=50 و lock_wait_ms كبير.
الآن يمكنك أن تقول السبب بثقة: البطء في مسار قاعدة البيانات (استعلام بطيء أو تناحر أقفال)، وليس الشبكة أو CPU. هذا ما يشتريه لك إعداد مبسّط: تضييق أسرع للبحث.
التصحيحات النموذجية، حسب ترتيب الأمان:
أغلق الحلقة بتنبيه مستهدف. أنبه فقط عندما يبقى p95 لنطاق نقاط النهاية فوق العتبة لمدة 10 دقائق وكان استخدام اتصالات DB فوق (مثلاً) 80%. هذا الجمع يتجنّب الضجيج ويلقِط المشكلة مبكرًا في المرة القادمة.
إعداد مراقبة مبسّط يجب أن يبدو مملًا في اليوم الأول. إذا بدأت بعدد كبير من اللوحات والتنبيهات، ستعدّلها إلى الأبد ومع ذلك تفوّت المشاكل الحقيقية.
عامل كل حادث كتعليق. بعد النشر، اسأل: ماذا كان سيجعل اكتشاف هذا أسرع وأسهل للتشخيص؟ أضف ذلك فقط.
وحد النمط مبكرًا، حتى لو عندك خدمة واحدة اليوم. استخدم نفس أسماء الحقول في السجلات ونفس أسماء المقاييس في كل مكان حتى تطابق الخدمات الجديدة النمط دون جدال. هذا يجعل اللوحات قابلة لإعادة الاستخدام.
انضباط إصدار صغير يربح بسرعة:
إذا بنت الخلفيات مع AppMaster، يساعد تخطيط حقول المراقبة والمقاييس قبل توليد الخدمات، حتى يأتي كل API جديد مع سجلات مهيكلة وإشارات صحية افتراضيًا. إذا أردت مكانًا واحدًا للبدء في بناء تلك الخلفيات، فـ AppMaster (appmaster.io) مصمم لتوليد backend وويب وموبايل جاهزين للإنتاج مع الحفاظ على تنفيذ متناسق مع تغيّر المتطلبات.
اختر تحسينًا واحدًا في كل مرة، بناءً على ما آلم فعليًا:
كرر الدورة بعد كل حادث حقيقي. خلال أسابيع قليلة، ستحصل على مراقبة تناسب تطبيق CRUD وحركة API لديك بدلًا من قالب عام.
ابدأ بالمراقبة عندما تستغرق مشاكل الإنتاج وقتًا للشرح أكثر مما تستغرقه للإصلاح. إذا كنت ترى “500s عشوائية”، صفحات قوائم بطيئة، أو مهلات لا تستطيع إعادة إنتاجها محليًا، فإن مجموعة صغيرة من السجلات المنسقة والمقاييس والتنبيهات ستختصر ساعات من التخمين.
المراقبة تخبرك بأن هناك خطأ، بينما تساعدك المراقبة الشاملة (observability) على فهم لماذا حدث عبر إشارات غنية بالسياق يمكن ربطها. بالنسبة لواجهات CRUD، الهدف العملي هو تشخيص سريع: أي نقطة نهاية، أي مستخدم/مستأجر، وهل الوقت ضائع في التطبيق أم في قاعدة البيانات.
ابدأ بسجلات طلبات مهيكلة، عدد قليل من المقاييس الأساسية، وبعض تنبيهات تؤثر على المستخدمين. قد تؤجل التتبع (tracing) لمعظم تطبيقات CRUD إذا كنت بالفعل تسجل duration_ms و db_time_ms و request_id قابلًا للبحث في كل مكان.
استخدم حقل ارتباط واحد مثل request_id وضمنه في كل سطر سجل للطلبات وكل تشغيل وظيفة خلفية. ولّده عند الحافة، مرّره داخل الاستدعاءات الداخلية، وتأكد أنه قابل للبحث لإعادة بناء طلب واحد فاشل أو بطيء بسرعة.
سجّل timestamp, level, service, env, route, method, status, duration_ms، ومعرّفات آمنة مثل tenant_id أو account_id. تجنّب تسجيل بيانات شخصية، رموز، أو هيئات الطلب كاملة افتراضيًا؛ إذا احتجت تفاصيل أعمق، أضفها فقط عند الطلب ومع تنقيح.
تابع معدل الطلبات، معدل 5xx، منتديات زمن الاستجابة (على الأقل p50 و p95)، وتشبع أساسي (CPU/الذاكرة بالإضافة إلى ضغط العمال أو قوائم الانتظار). أضف وقت قاعدة البيانات واستخدام تجمع الاتصال مبكرًا لأن العديد من أعطال CRUD هي في الواقع احتقان قاعدة بيانات أو نفاد تجمع الاتصال.
لأنها تخفي الذيل البطيء الذي يشعر به المستخدمون بالفعل. المتوسطات قد تبدو جيدة بينما p95 سيئة لشريحة مهمة من الطلبات — وهذا بالضبط كيف تبدو شاشات CRUD "بطيئة عشوائيًا" بدون أخطاء واضحة.
راقب معدل الاستعلامات البطيئة ونسب أوقات الاستعلام، انتظار الأقفال/الـ deadlocks، واستخدام الاتصالات مقابل حدود التجمع. هذه الإشارات تخبرك ما إذا كانت قاعدة البيانات عنق الزجاجة وما إذا كانت المشكلة أداء استعلام، تناحر، أو نفاد اتصالات تحت الحمل.
ابدأ بتنبيهات على أعراض المستخدم: معدل 5xx المستمر، p95 زمن استجابة مستمر، وانخفاض مفاجئ في الطلبات الناجحة. أضف تنبيهات مرتبطة بالأسباب لاحقًا (مثل اتصالات DB قرب الحد أو تراكم قوائم الوظائف) حتى يبقى إشارة الاستنفار موثوقة وقابلة للعمل.
أرفق بيانات الإصدار/البناء باللواح والتنبيهات والسجلات، وسجل علامات النشر حتى ترى متى تم شحن التغيير. مع الخلفيات المولّدة (مثل الخدمات المولدة بواسطة AppMaster)، هذا مهم لأن التجديد والنشر يمكن أن يحدثا كثيرًا، وتريد التأكد سريعًا مما إذا كانت مشكلة بدأت مباشرة بعد إصدار.



تجربة مع AppMaster مع خطة مجانية.
عندما تكون جاهزًا ، يمكنك اختيار الاشتراك المناسب.


