
设备预订应用:避免冲突并跟踪归还
规划一个设备预订应用,防止重复预订,记录归还和损坏,并将故障设备置于维护停用状态。
了解如何通过清晰的状态、可维护的规则和简单的升级路径来建模 SLA 计时器与升级,使工作流应用便于更改。
基于时间的规则通常起初很简单:“如果工单在 2 小时内没人回复,就通知某人。”然后工作流增长、团队加入例外规则,很快就没人确定到底会发生什么。这就是 SLA 计时器和升级如何变成迷宫的原因。
把活动部分命名清楚会很有帮助。
一个 计时器(timer) 是你在事件后启动(或安排)的时钟,比如“工单移动到 Waiting for Agent”。一个 升级(escalation) 是当时钟到达阈值时你所采取的动作,比如通知负责人、更改优先级或重分配工作。一个 违约(breach) 是记录下来的事实,表示“我们错过了 SLA”,用于报告、告警和后续处理。
当时间逻辑散落在应用各处时问题就出现了:在“更新工单”流程里有几处检查,在夜间作业里有更多检查,为特殊客户后来又加了临时规则。每一部分单独看都合理,但放在一起就会产生意外。
典型症状:
目标是获得可预测的行为并便于以后修改:为 SLA 计时提供一个清晰的单一可信来源、显式的违约状态供报告使用,以及可在不四处查找可视化逻辑的情况下调整的升级步骤。
在构建任何计时器之前,写下你要衡量的确切承诺。很多混乱源于试图在一开始就覆盖所有可能的时间规则。
常见的 SLA 类型听起来相似但测量的对象不同:
接着,决定“时间”是什么意思。日历时间(Calendar time) 按 24/7 计;工作时间(Working time) 只计算定义好的营业时间(例如周一到周五,9 点到 18 点)。如果你并不真正需要工作时间,尽量在早期避免它。它会增加像节假日、时区和部分工作日这样的边缘情况。
然后明确暂停规则。暂停不仅仅是“状态改变”。它应该是一条有负责人(owner)的规则。谁可以暂停(仅代理、仅系统、客户操作)?哪些状态会导致暂停(Waiting on Customer、On Hold、Pending Approval)?什么会恢复它?恢复时是继续剩余时间还是重置计时器?
最后,以产品术语定义违约是什么意思。违约应该是可以存储和查询的具体记录,例如:
示例:“首次响应 SLA 违约”可能意味着工单进入一个 Breached 状态,写入 breached_at 时间戳,并把升级级别设置为 1。
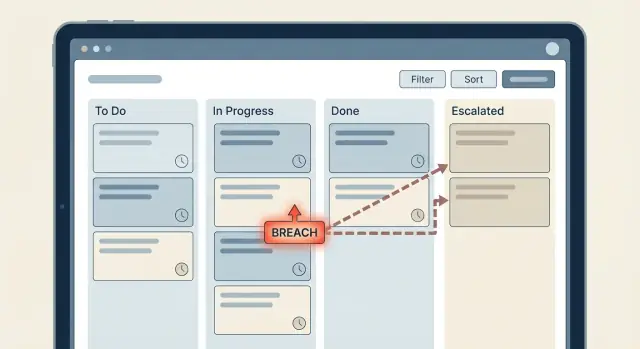
如果你希望 SLA 计时器和升级保持可读,把 SLA 当作一个小型状态机来处理。当“真相”被分散到许多小检查(如果现在 > 到期、如果优先级高、如果最后回复为空),可视化逻辑会很快变得混乱,小改动就会破坏行为。
从一组简短且达成一致的 SLA 状态开始,让每个工作流步骤都能理解它们。对很多团队来说,这些状态足以覆盖大多数情况:
单一的 breached = true/false 标记通常不够用。你仍然需要知道哪个 SLA 违约(首次响应或解决)、它当前是否被暂停、以及你是否已经做过升级。没有这些上下文,人们会开始从注释、时间戳和状态名中重新推导含义,那样逻辑就会变脆弱。
把状态显式化并存储能解释它的时间戳。这样决策就简单了:评估器读取记录,决定下一个状态,其他部分都根据该状态做出反应。
有用的字段(与状态一起存储):
started_at 和 due_at(我们在跑哪个时钟,什么时候到期?)breached_at(何时实际越线?)paused_at 和 paused_reason(为什么时钟停止?)breach_reason(哪个规则触发了违约,用明文说明)last_escalation_level(以避免重复通知同一等级)示例:工单移到 “Waiting on customer”。把 SLA 状态设为 Paused,记录 paused_reason = "waiting_on_customer",并停止计时器。当客户回复时恢复:设置新的 started_at(或取消暂停并重新计算 due_at)。不需要到处查条件。
升级梯队是当 SLA 计时器接近违约或已经违约时的明确计划。常见错误是把组织结构直接复制到工作流里。你想要的是最小化的步骤集以让停滞项重新流动。
许多团队使用的简单梯队:被分配的代理(Level 0)先收到提醒,然后拉入团队负责人(Level 1),只有在此之后才交给经理(Level 2)。它之所以有效,是因为从能实际完成工作的地方开始,仅在需要时才提升权限。
为了保持工作流升级规则的可维护性,把升级阈值作为数据存储,而不是硬编码条件。把它们放到表或设置对象里:例如“30 分钟后第一次提醒”或“2 小时后升级到负责人”。当策略变化时,只需更新一个地方,而不是编辑多个工作流。
当升级频繁触发时,容易变成垃圾信息。为每一步添加保护措施,使其有明确目的:
仅靠通知无法解决停滞工作,如果责任不明确。预先定义好所有权规则:工单是仍旧分配给代理,还是重新分配给负责人,或者移动到共享队列?
示例:在 Level 1 升级后,把工单重新分配给团队负责人,并把原始代理设为观察者(watcher)。这能明确下一步该谁执行,避免同一项在人员之间来回弹跳。
保持 SLA 计时器和升级可维护的最简单方法是把它们当作一个由三部分组成的小系统处理:事件、评估器和动作。这样时间逻辑不会散落在几十个“如果时间 > X”的检查中。
事件是简单的事实,不应包含计时器计算。它们回答的是“发生了什么改变?”,而不是“我们应该怎么做?”。典型事件包括工单创建、代理回复、客户回复、状态改变或手动暂停/恢复。
把这些以时间戳和状态字段存储(例如:created_at、last_agent_reply_at、last_customer_reply_at、status、paused_at)。
创建一个单一的“SLA 评估器”步骤,在任何事件之后以及按计划定期运行。这个评估器是唯一计算 due_at 和剩余时间的地方。它读取当前事实、重新计算截止时间,并写回显式的 SLA 状态字段,例如 sla_response_state 和 sla_resolution_state。
这就是违约状态建模保持清晰的地方:评估器设置状态比如 OK、AtRisk、Breached,而不是把逻辑藏在通知里。
通知、分配和升级应该仅在状态变化时触发(例如:OK -> AtRisk)。把发送消息与更新 SLA 状态分开。这样你可以在不碰计算逻辑的情况下更改谁会收到通知。
一个可维护的设置通常包含:记录上的少量字段、一个小的策略表,以及一个决定接下来发生什么的评估器。
以拥有 SLA 的实体为起点(工单、订单、请求)。添加显式时间戳和一个“当前 SLA 状态”字段。保持字段平凡且可预测。
然后加入一个小的策略表来描述规则,而不是把它们硬编码到多个流程中。一个简单版本是按优先级(P1、P2、P3)一行一条,包含目标分钟数和升级阈值(例如:在 80% 时警告,在 100% 时违约)。这就是修改一条记录与编辑五个工作流之间的区别。
不要在每处创建单独计时器,而是使用一个定期检查的进程(严格 SLA 每分钟一次,许多团队可每 5 分钟一次)。计划任务调用一个评估器,该评估器将:
sla_state 和 next_check_at这会让 SLA 计时器和升级更易于推理,因为你只需调试一个评估器,而不是许多计时器。
评估器应该同时输出新状态和是否发生变化。只有在状态移动时才触发消息或任务(例如 ok -> warning、warning -> breached)。如果记录在 breached 状态保持一小时,你不希望收到 12 次重复通知。
一个实用模式是:保存 sla_state 和 last_escalation_level,将其与新计算值比较,只有发生变化时才调用消息发送(email/SMS/Telegram)或创建内部任务。
暂停通常是时间规则变得混乱的地方。如果不清晰建模,SLA 要么在不该跑的时候继续,要么在有人误点状态时重置。
一个简单规则:仅有一个状态(或一小组状态)暂停时钟。常见选择是 Waiting for customer。当工单进入该状态时,记录一个 pause_started_at 时间戳。当客户回复并且工单离开该状态时,记录 pause_ended_at 并把持续时间加到 paused_total_seconds。
不要只保留一个计数器。捕获每个暂停窗口(开始、结束、触发者)以便审计。之后当有人问为什么案件违约时,你可以展示它在等待客户上花了 19 小时。
重分配和正常状态变化不应重置时钟。把 SLA 时间戳与所有权字段分开。例如,sla_started_at 和 sla_due_at 应在创建时(或 SLA 策略变更时)设置一次,而重分配仅更新 assignee_id。然后评估器可以这样计算已用时间:now - sla_started_at - paused_total_seconds。
保持 SLA 计时器和升级可预测的规则:
测试设计的一个简单方式是:一个支持工单有两个 SLA:首次响应 30 分钟,完整解决 8 小时。如果逻辑分散在多个界面和按钮上,这就是常见崩溃点。
假设每个工单存储:state(New、InProgress、WaitingOnCustomer、Resolved)、response_status(Pending、Warning、Breached、Met)、resolution_status(Pending、Warning、Breached、Met),以及像 created_at、first_agent_reply_at、resolved_at 这样的时间戳。
一个现实时间线:
对于升级,保持在状态转换上触发一个清晰链条。例如,当响应变为 Warning 时,通知被分配的代理;当变为 Breached 时,通知团队负责人并更新优先级。
在每一步,更新相同一小组字段以便于推理:
response_status 或 resolution_status 设为 Pending、Warning、Breached 或 Met。*_warning_at 和 *_breach_at 时间戳写一次,之后不再覆盖它们。escalation_level(0、1、2)并写入 escalated_to(Agent、Lead、Manager)。sla_events 日志,记录事件类型和谁被通知。priority 和 due_at,让 UI 和报表反映升级状态。关键在于 Warning 和 Breached 是显式状态。你可以在数据中看到它们、对其审计,并在不去寻找隐藏计时检查的情况下改变升级梯队。
当 SLA 逻辑四处扩散时会变得混乱:这里一个按钮上的时间检查、那里一个条件告警,加上后来加入的临时规则,很快就没人能解释为什么工单被升级了。把 SLA 计时器和升级作为一小块中心化的逻辑,让每个界面和动作都依赖它。
一个常见陷阱是把时间检查嵌入多个地方(UI 界面、API 处理器、手动动作)。修复办法是让一个评估器计算 SLA 状态并把结果存回记录。界面只读状态,而不是重新生成它。
另一个陷阱是让不同计时器使用不同时钟。如果浏览器计算“自创建以来的分钟数”而后端使用服务器时间,你会在睡眠、时区和夏令时切换时看到边缘情况。任何触发升级的逻辑都应优先使用服务器时间。
通知也很容易变得喧扰。如果你“每分钟检查一次并在逾期时发送”,人们可能每分钟就收到一封邮件。把消息与转变绑定:“已发送警告”、“已升级”、“已违约”。这样每一步只发送一次,并且能审计发生了什么。
工作时间逻辑也是意外复杂性的来源。如果每条规则都有自己的“如果周末则……”分支,后期更新会很痛苦。把工作时间的计算放在一个函数(或共享模块)中,返回“已消耗的 SLA 分钟数”,并复用它。
最后,不要仅依赖从头重算违约时间。存储违约发生的时刻:
breached_at,并永远不覆盖它。escalation_level 和 last_escalated_at,以保证操作幂等。notified_warning_at(或类似字段)以防止重复告警。示例:工单在 10:07 达到“响应 SLA 违约”。如果你只在后面重算,后来的状态变化或暂停/恢复错误可能会让看起来像违约发生在 10:42。有了 breached_at = 10:07,报告和事后分析就更一致。
在你添加计时器和告警之前,做一遍以确保规则在一个月后仍可读:
一个实用测试:选一个即将违约的工单并重放其时间线。如果你无法在不阅读整个工作流的情况下解释在每个状态变化时会发生什么,那么你的模型就过于分散。
先构建最小可用切片。先选一个 SLA(例如首次响应)和一个升级等级(例如通知团队负责人)。一周的真实使用会比纸面上的完美设计教会你更多。
把阈值和接收人作为数据而不是逻辑放置:把分钟数、工作时间规则、谁会被通知以及哪个队列拥有案件放到表或配置记录中。这样当业务调整数字与路由时,工作流能保持稳定。
及早规划一个简单的仪表盘视图。不需要大型分析系统,只要一个共享的当前状态概览:按进度、警告、已违约、已升级。
如果你在无代码工作流应用中构建,选择一个能在同一处建模数据、逻辑和计划评估器的平台会更有帮助。例如,AppMaster (appmaster.io) 支持数据库建模、可视化业务流程,并生成可用于生产的应用,这很契合“事件、评估器、动作”的模式。
按下面顺序安全迭代:
准备好后,先构建一个小版本,然后在真实反馈和真实工单中逐步扩展。
先弄清你要衡量的承诺是什么,比如首次响应或问题解决,并写下确切的开始、停止和暂停规则。然后把时间计算集中到一个评估器里,该评估器设置显式的 SLA 状态,而不是把“如果现在 > X”这种检查零散地散布在多个工作流里。
计时器是你在事件后启动或安排的时钟,比如工单被移到新状态。升级是在阈值达到时执行的动作,例如通知负责人或更改优先级。违约(breach)是记录下来的事实,表明 SLA 被错过了,便于事后报告和审计。
首次响应衡量的是人工发送首个有意义回复所需的时间,而解决时限衡量的是问题真正关闭所需的时间。它们在暂停和重新打开时的行为不同,所以把它们分开建模可以让规则更简单、报告更准确。
默认使用日历时间(24/7)——因为它更简单、更易调试。只有在确实需要按工作时间计算时才增加工作时间逻辑,因为这会引入节假日、时区和部分工作日等额外复杂性。
把暂停建模为与特定状态绑定的显式状态,例如 Waiting on Customer,并记录暂停何时开始和结束。恢复时要么继续剩余时间,要么在一个地方重新计算到期时间,但不要让随意的状态切换重置计时器。
单一的 breached = true/false 标记往往不足够,它会隐藏很多上下文,比如哪个 SLA 违约、是否处于暂停,以及是否已经升级。使用像“On track(按进度)”、“Warning(警告)”、“Breached(已违约)”、“Paused(已暂停)”、“Completed(已完成)”这样的显式状态能让系统更可预测、易审计且便于修改。
存储能解释状态的时间戳,例如 started_at、due_at、breached_at,以及像 paused_at 和 paused_reason 这样的暂停字段。同时保存升级跟踪字段如 last_escalation_level,以避免重复通知,这样更便于审计 SLA 行为。
一个不会制造混乱的实用升级梯队是:先提醒能实际处理工作的负责人(Agent),然后是团队负责人(Lead),只有必要时才升级到经理(Manager)。把阈值和接收人作为数据(比如策略表)保存,这样调整时只需改一处配置,而不是修改多个工作流。
把通知绑定到状态转变,例如 OK -> Warning 或 Warning -> Breached,而不是“仍然逾期就发”。加入简单的保护措施,比如重试规则、冷却窗口和停止条件,这样每一步只发一次消息而不是重复打扰。
模式是事件、单一评估器和动作:事件记录事实,评估器计算截止时间并设置 SLA 状态,动作仅对状态变化做出反应。在 AppMaster (appmaster.io) 里,你可以在一个平台上建模数据、用可视化业务流程实现评估器,并从状态更新触发通知或分配,从而把时间计算集中起来。




