
设备预订应用:避免冲突并跟踪归还
规划一个设备预订应用,防止重复预订,记录归还和损坏,并将故障设备置于维护停用状态。
用一个内部工具规划并构建 IT 团队的事件管理应用:包含严重性工作流、明确负责人、时间线和事后分析。
当故障发生时,大多数团队会抓住手边能用的东西:一个聊天室线程、一串邮件,或许还有某人在有空时更新的电子表格。在压力下,这种做法每次都会出问题:责任不清、时间戳丢失、决策被滚动淹没。
一个简单的事件管理应用能修补这些基础问题。它提供一个事件的单一记录位置,明确负责人、所有人认可的严重性等级,以及发生了什么和何时发生的时间线。这个单一记录很重要,因为每次事件都会出现相同的问题:谁在主导?什么时候开始的?当前状态是什么?已经尝试了什么?
没有共享记录时,交接会浪费时间。支持对客户说一套,工程在做另一套。管理者要求更新把响应者从修复中拉走。事后没人能自信地重建时间线,事后分析就变成猜测。
目标不是替代监控、聊天或工单。告警可以继续从别处触发。重点是捕捉决策链并保持人们步调一致。
IT 运维和值班工程师用它来协调响应。支持用它快速给出准确更新。管理者用它在不打断响应者的情况下查看进展。
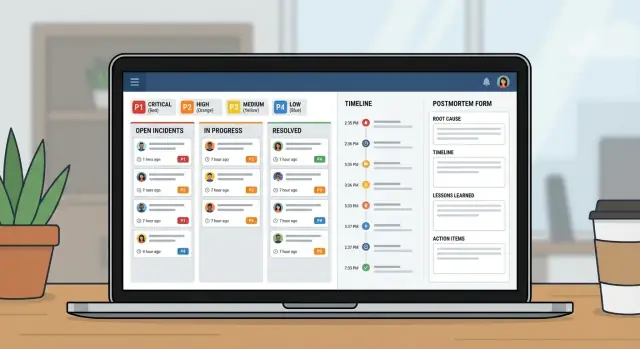
上午 9:12,监控发现客户门户出现大量 500 错误。支持也报告“多数用户无法登录”。值班 IT 负责人在事件应用中创建了一个 P1 事件,并附上了首次告警和支持的截图。
遇到 P1 时,行为会迅速改变。事件负责人拉入后端负责人、数据库负责人和一名支持联络人。非必要工作暂停,计划内部署停止。团队约定更新节奏(例如每 15 分钟一次)。开始共享通话,但事件记录仍是事实来源。
到 9:18,有人问:“发生了什么变更?”时间线显示 8:57 有一次部署,但未说明部署内容。后端负责人先回滚。错误下降后又回升,团队转而怀疑数据库。
大多数延迟出现在几个可预测的环节:交接不清(“我以为你在看那个”)、上下文缺失(近期变更、已知风险、当前负责人)以及更新分散在聊天、工单和邮件中。
9:41,数据库负责人发现调度任务启动了一个失控查询。他们禁用该任务,重启受影响服务,并确认恢复。严重性降为 P2 继续观察。
好的关闭不是“又能用了”。它是一份干净的记录:逐分钟的时间线、最终根因、谁做了哪些决策、哪些工作被暂停,以及带负责人和截止日的后续事项。这样一次高压的 P1 会变成学习素材,而不是重复的痛苦。
一个好的事件工具本质上是一个良好的数据模型。如果记录含糊,人们会争论事件是什么、何时开始以及还有哪些未关闭项。
把核心实体贴近 IT 团队已有的说法:
为防止后续混淆,给事件设置一些必须填写的结构化字段。自由文本有用,但不应是唯一的事实来源。实用最小集包括:清晰标题、影响(用户体验)、受影响服务、开始时间、当前状态和严重性。
关系比额外字段更重要。一个事件应有多条更新和多条任务,并与服务保持多对多关系(因为故障常常影响多个系统)。事后分析应与事件一对一关联,这样才有唯一的最终叙述。
示例:一个“结账错误”事件关联到“Payments API”和“PostgreSQL”两个服务,每 15 分钟有一次更新,任务包括“回滚部署”和“增加重试保护”。事后分析随后记录根因并创建长期任务。
人在紧张时需要简单且统一的标签。用平实语言定义 P1 至 P4,并把定义显示在严重性字段旁。
响应目标应像承诺一样写出。一个简单基线(按你实际情况调整):
| 严重性 | 首次响应(确认) | 首次更新 | 更新频率 |
|---|---|---|---|
| P1 | 5 分钟 | 15 分钟 | 每 30 分钟 |
| P2 | 15 分钟 | 30 分钟 | 每 60 分钟 |
| P3 | 4 小时 | 1 个工作日 | 每日 |
| P4 | 2 个工作日 | 1 周 | 每周 |
把升级规则做成机械化的判断。如果 P2 未按更新节奏进行,系统应提示复审严重性。为避免频繁抖动,限制谁可以更改严重性(通常是事件负责人或指挥),但允许任何人在评论中请求复审。
一个简单的影响矩阵也有助于团队快速选择严重性。在事件表单中捕捉几个必填字段:受影响用户、营收风险、安全合规、以及是否存在变通方案。
事件期间,人们不需要更多选项,而需要一小组能让下一步明显的状态。
从平时表现良好的步骤开始,然后保持列表简短。若状态超过 6 或 7 个,团队会为措辞争论而不是修复问题。
一个实用集合:
每个状态都需要明确的进入与退出规则。例如:
使用状态转换来强制填写那些人们常忘的字段。一个常见规则是:关闭事件前必须有简短的根因总结和至少一项后续工作。如果允许“RCA: 待定”,它往往会一直保持待定。
事件页面应一目了然回答三件事:谁负责、下一步行动是什么、以及上一次更新是什么时候发布的。
在事件嘈杂时,最容易浪费时间的就是模糊的责任归属。你的应用应让一个人明确负责,同时又方便他人协助。
一个简单且经得住考验的模式:
指派应明确且可审计。记录是谁设置了负责人、谁接受了指派,以及之后的每次变更。“接受”很重要,因为把任务指派给正在睡觉或离线的人并不是真正的责任承担。
值班与基于团队的指派通常取决于严重性。对于 P1/P2,默认使用值班轮换以确保总有一个命名负责人。对于较低严重性的事件,基于团队的指派也可行,但仍需在短时间内确定一名主要负责人。
在流程中为休假和不可用情况做计划,不只是依赖系统。如果被指派人标记为不可用,应自动路由到备用值班或团队负责人。保持自动化,但要可见,以便快速修正。
升级应同时基于严重性和沉默触发。一个有用的起点:
好的时间线是共享记忆。事件期间,上下文会迅速消失。如果你在一个地方捕捉到正确的时刻,交接会更容易,事后分析在许多情况下在打开文档前就已基本成型。
保持时间线有感知。不要把它变成聊天日志。大多数团队依赖一小类条目:检测、确认、关键缓解步骤、恢复和关闭。
每条条目需要时间戳、作者和简短的明文描述。后来加入的人应该能读五条条目就明白当前情况。
不同的更新面向不同受众。有助于当条目带有类型,例如内部笔记(原始细节)、对客户的更新(安全措辞)、决策(为何选 A 方案)和交接(下一位需要知道的事项)。
提醒应基于严重性而不是个人偏好。计时器触发时先提醒当前负责人,重复错过则升级。
通知应有针对性和可预测性。一个小规则集通常足够:在创建、严重性变更、恢复和逾期更新时通知。避免为每次小变更通知全公司。
事后分析应完成两件事:用平实语言解释发生了什么,并让同样的故障下次更难发生。
把写作保持简短,并把输出强制成行动。一种实用结构包括:摘要、客户影响、根因、已采取的修复以及后续项。
后续项是关键。不要把它们留在结尾的段落中。把每个后续项转成有负责人和截止日的可跟踪任务,即使截止日是“下个冲刺”。这就是“我们应该改进监控”和“Alex 在周五前添加 DB 连接饱和告警”之间的区别。
标签让事后分析在以后有用。每个事件添加 1 到 3 个主题(监控缺口、发布、容量、流程)。一个月后,你就能回答大部分 P1 是否来自发布或缺失告警之类的问题。
证据应该容易附加,但非强制。支持截图、日志片段和外部系统引用(工单 ID、聊天线程、厂商案例号)的可选字段。保持轻量,人们才会真正填写它。
把它当作一个小产品来做,而不是带着额外列的电子表格。一个好的事件应用其实是三个视图:现在发生了什么、下一步该做什么、以及事后学到了什么。
先画出在压力下人们会打开的屏幕:
同时构建数据模型与权限。如果人人都能编辑一切,历史会变得混乱。一种常见做法是:IT 有广泛查看权限,状态/严重性的更改受控,响应者可以添加更新,事后分析有明确审批人。
然后添加防止半成品事件的工作流规则。必填字段应依状态而定。你或许允许“新建”只有标题和报告者,但要求“缓解中”包含影响摘要,要求“已解决”包含根因摘要和至少一项后续任务。
最后通过回放 2 到 3 起过去的事件进行测试。让一人扮演事件指挥、一人扮演响应者。你会很快看到哪些状态不清、哪些字段被跳过以及哪里需要更好的默认值。
大多数事件系统因为简单的原因失败:人在压力下记不得规则,应用没有捕捉到事后需要的事实。
若有六个严重性等级和十个状态,人们会靠猜测。把严重性控制在 3 到 4 个,状态要聚焦于下一步该做什么。
当每个人都在“看着它”时,就没有人真正驱动。要求在事件继续前有一名命名负责人,并把交接做成显式记录。
如果“什么时候发生了什么”依赖聊天记录,事后分析就会变成争论。自动捕捉打开、确认、缓解和解决的时间戳,并保持时间线条目简短。
还要避免以模糊的根因笔记关闭事件,比如“网络问题”。要求一条清晰的根因陈述和至少一项具体的后续步骤。
在向整个 IT 组织推广前,对基础功能进行压力测试。如果人们在前两分钟找不到正确的按钮,他们会回到聊天线程和电子表格。
专注于一套简短的上线检查项:角色与权限、清晰的严重性定义、强制的责任分配、提醒规则以及在响应目标被错过时的升级路径。
先在一个团队和一些频繁触发告警的服务上试点。运行两周,根据真实事件调整。
如果你想把它做成一个单一的内部工具,而不是拼接电子表格和多个应用,AppMaster(appmaster.io)是一个选项。它能让你在同一平台上创建数据模型、工作流规则和 Web/移动界面,非常适合实现事件队列、事件页面和事后分析跟踪。
它把分散在聊天和邮件里的更新汇总到一条共享记录中,能快速回答关键问题:谁负责?用户看到了什么?已经尝试了什么?下一步是什么?这样可以减少交接浪费、信息冲突和“能不能总结下?”式的打断。
一旦你认为事件对客户或业务有真实影响,就应打开事件,即便根本原因尚不清楚。可以先以草稿标题和“影响未知”打开,然后随着确认严重性和范围再逐步完善细节。
保持精简且有结构:清晰的标题、影响摘要、受影响的服务、开始时间、当前状态、严重性和一个单一负责人。随着情况发展再添加更新和任务,但核心事实不要只依赖自由文本。
使用 3 到 4 个级别,且定义要平实易懂以免产生争论。一个常见默认是:P1 表示核心服务中断或存在数据丢失风险,P2 表示主要功能受影响但有变通方案或影响范围有限,P3 表示较小影响,P4 为次要或视觉类问题。
把目标设为承诺式,而不是随意估计:确认时间、首次更新时间和更新频率。然后在未按节奏更新时触发提醒和升级,因为“沉默”往往是事故期间真正的问题。
建议维持约六个状态:New、Acknowledged、Investigating、Mitigating、Monitoring 和 Resolved。每个状态都应让下一步一目了然,且状态转换要强制那些人在压力下常忘记的字段,比如在 Acknowledged 前必须有负责人,关闭前必须有根本原因摘要。
要求一名主要负责人对响应负责并发布更新。明确记录“接受”动作,避免把任务分配给离线或休息的人。把交接记录为可审计的事件,这样下一个负责人不会从头再来调查。
时间线只记录关键时刻:检测、确认、关键决策、缓解步骤、恢复与关闭,每条记录包含时间戳和作者。把它当作共享记忆,而不是聊天记录,这样后续加入的人能在几分钟内了解全貌。
写得简短且以行动为导向:发生了什么、客户影响、根本原因、缓解时采取了什么、以及带负责人和截止日期的后续项。文档有用,但能阻止同样事件重演的是那些被分配并跟踪的任务。
可以把事件、更新、任务、服务和事后分析建模为真实数据,并在应用中强制工作流规则。AppMaster(appmaster.io)是一个选项,它能让团队在同一平台上构建数据模型、Web/移动界面和基于状态的校验,从而避免在压力下退回到电子表格和分散系统。




