
设备预订应用:避免冲突并跟踪归还
规划一个设备预订应用,防止重复预订,记录归还和损坏,并将故障设备置于维护停用状态。
管理面板的索引:根据真实查询模式,优先优化用户最常点击的筛选器:状态、负责人、日期范围和文本搜索。
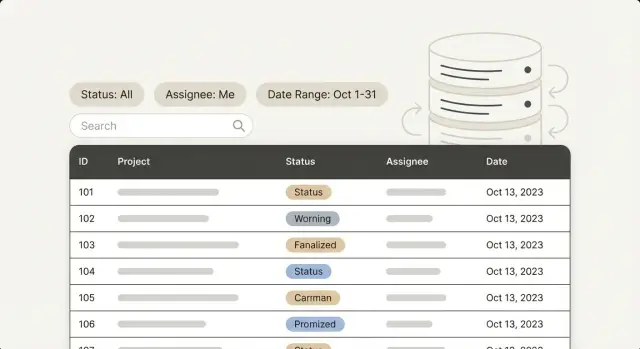
管理面板通常起初感觉很快:打开列表、滚动、点击一条记录,然后继续。慢感会在用户以真实工作方式过滤时出现:"只有未关闭的工单"、"分配给 Maya"、"上周创建"、"订单号包含 1047"。每次点击都会带来等待,列表开始变得卡顿。
同一张表对一个筛选可能很快,对另一个筛选却异常缓慢。状态筛选可能只触及一小部分行并快速返回;而“在两个日期之间创建”的筛选可能迫使数据库读取很大的范围。负责人筛选单独看可能没问题,但一旦与状态和排序组合就会变慢。
索引是数据库在不读取整表的前提下查找匹配行的捷径。但索引不是免费的:它们占用空间,并会让插入和更新变慢一些。添加过多索引会让写操作变慢,却未必修复真正的瓶颈。
与其把每样都索引,不如优先处理那些:
本文有意聚焦。管理列表中最先收到的性能抱怨几乎总是来自四类筛选:状态、负责人、日期范围和文本字段。理解它们为什么表现不同后,下一步就很清晰:查看真实查询模式,添加与之匹配的最小索引,并验证你是否改善了慢路径而未产生新问题。
管理面板很少因为一个巨大的报表而变慢。它们变慢是因为几个常用页面被整天频繁访问,而这些页面反复运行大量小查询。
运维团队通常活跃在少数工作队列:工单、订单、用户、审批、内部请求。在这些页面上,筛选反复出现:
数据库的工作量取决于意图:
管理面板还会以可预见的方式组合筛选:"Open + Unassigned"、"Pending + Assigned to me" 或 "Completed in the last 30 days"。索引在匹配这些真实查询形态时效果最好,而不是单纯匹配一组列名。
如果你在 AppMaster 中构建管理工具,这些模式通常可以通过查看最常用的列表屏幕及其默认筛选直接看到。这让你更容易为真正驱动日常工作的路径建立索引,而不是为纸面上看起来合理的字段建一堆索引。
把索引当做分诊。不要从给下拉筛选中出现的每个列都建起。先处理那些持续运行并让人恼火的少数查询。
优化没人点的筛选是浪费精力。要找到真实的热点路径,结合多种信号:
在很多团队中,默认视图像是 “Open tickets” 或 “New orders”。每次有人刷新、切换标签或回复后返回时,它都会运行。
在添加索引前,按查询的行为把常见查询分组。大多数管理列表查询落入几个桶:
status = 'open'、assignee_id = 42created_atORDER BY created_at DESC 并取第 N 页把每个顶级屏幕的形态记录下来,包括 WHERE、ORDER BY 和分页。看似在 UI 上类似的两个查询在数据库中可能行为截然不同。
从一个优先目标开始:管理员打开时的默认列表查询。然后再选 2 或 3 个高频查询。通常这就足以消除最大延迟,而不会把数据库变成索引陈列馆。
示例:支持团队打开一个 Tickets 列表,筛选为 status = 'open',按最新排序,可选负责人和日期范围。先优化这个确切组合。变快后,再按使用情况移动到下一个屏幕。
状态是人们首先添加的筛选之一,也是最容易以无效方式建立索引的字段。
大多数状态字段低基数:只有少数值(open、pending、closed)。当某一状态占多数行时,单独在 status 上建索引往往改变不大。数据库仍需读取大量行,而且索引本身还带来额外开销。
你通常能感受到收益的情形包括:
常见模式是“显示未关闭的项,按最新排序”。在这种情况下,把筛选和排序一起索引通常比单独索引 status 更有效。
下列组合通常优先带来收益:
status + updated_at(按状态过滤,按最近变更排序)status + assignee_id(工作队列视图)status + updated_at + assignee_id(仅当该确切视图被大量使用时)当某个状态占主导时,部分索引是折衷的好选择。如果“open”是主要视图,就只索引 open 行。索引更小,写入开销也更低。
-- PostgreSQL example: index only open rows, optimized for newest-first lists
CREATE INDEX CONCURRENTLY tickets_open_updated_idx
ON tickets (updated_at DESC)
WHERE status = 'open';
一个实用的测试是:以有无状态筛选运行慢查询。如果无论是否加状态筛选都慢,单独的状态索引拯救不了它。把注意力放在排序和第二个真正能缩小列表的筛选上。
在大多数管理面板中,负责人是记录上的用户 ID:像 assignee_id 这样的外键。这是经典的等值筛选,通常用一个简单索引就能带来明显提升。
负责人也常与其他筛选一起出现,因为它符合人们的工作方式。负责人 + 状态经常被用来查看“我的待办”。如果该视图很慢,通常需要的不仅是单列索引。
一个好的起点是与常用筛选组合匹配的复合索引:
(assignee_id, status) 用于“我的未完成事项”(assignee_id, status, updated_at) 如果列表还按最近活动排序复合索引中列的顺序很重要。把等值筛选放在前面(通常是 assignee_id,然后是 status),把排序或范围列放在最后(updated_at)。这符合数据库能高效利用索引的方式。
未分配项是常见的陷阱。许多系统用 NULL 表示“未分配”,管理者常筛选它们。根据数据库与查询形态,NULL 值可能改变查询计划,使得一个对已分配项很有效的索引对未分配项毫无用处。
如果未分配是第一等级的工作流,选定一个明确的方法并测试它:
assignee_id 可空,但确保专门测试 WHERE assignee_id IS NULL 并在需要时为其建立索引。如果你在 AppMaster 中构建管理面板,记录团队经常使用的确切筛选与排序,然后用一小组精心挑选的索引去镜像这些模式,而不是为每个可用字段都建索引。
日期筛选通常以“最近 7 天”或“最近 30 天”的预设出现,另外还有开始与结束日期的自定义选择。看似简单,但在大表上会触发截然不同的数据库工作量。
首先,明确用户到底指的是哪个时间戳列。使用:
created_at 表示“新项”视图updated_at 表示“最近变更”视图在该列上建普通 btree 索引。没有索引时,每次点击“最近 30 天”可能会变成全表扫描。
预设范围常表现为 created_at \u003e= now() - interval '30 days'。这是范围条件,而对 created_at 的索引可以被有效使用。如果 UI 也按最新排序,匹配排序方向(例如 PostgreSQL 中的 created_at DESC)在高频列表上会有帮助。
当日期范围与其他筛选(状态、负责人)结合时,要有选择性。复合索引在组合常见时很棒,否则它们会增加写入成本而难以回本。
实用规则:
(status, created_at) 可能有用。created_at 索引并避免大量复合索引。时区与边界会带来大量“丢失记录”的 bug。如果用户选择的是日期(非时间),决定如何解释结束日期。一个安全模式是:起始包含、结束不包含:created_at \u003e= start 且 created_at \u003c end_next_day。在查询前将用户输入转换为 UTC 并用 UTC 存储时间戳。
示例:运维管理员选择 1 月 10 日到 1 月 12 日并期望看到 1 月 12 日整天的记录。如果你的查询用了 \u003c= '2026-01-12 00:00',你会丢掉 1 月 12 日的大部分记录。索引可能没问题,但边界逻辑错了。
文本搜索是许多管理面板变慢的地方,因为用户期望一个输入框能找到所有东西。第一步修复是把两类需求分开:精确匹配(快速且可预测)与包含搜索(灵活但更昂贵)。
精确匹配字段包括订单 ID、工单号、邮箱、电话或外部引用。管理员常粘贴 ID 或邮箱时,这些字段非常适合普通数据库索引。一个简单的索引加上等值查询可以让体验几乎瞬间响应。
包含搜索是当用户输入片段如“refund”或“john”,期望在姓名、备注和描述中匹配。这通常实现为 LIKE %term%。前导通配符会使普通 B-tree 索引失效,数据库不得不扫描大量行。
一个实用的方式是,在不压垮数据库的前提下构建搜索:
term%),普通索引通常能帮助,且对姓名类搜索感觉足够好。LIKE %term%。输入规则比大多数团队预料的更重要:它们能减少负载并使结果一致:
一个小例子:支持经理搜索 “ann” 找客户。如果系统在备注、姓名和地址上对 LIKE %ann% 进行扫描,它可能会扫描成千上万条记录。如果你先检查精确字段(邮箱或客户 ID),再在必要时回退到更智能的文本索引,搜索就能在不把每次查询都变成数据库锻炼的情况下保持快速。
索引很容易添加,也很容易后悔。一个安全的工作流让你聚焦于管理员依赖的筛选,并避免那些“可能有用”的索引在以后拖慢写入速度。
以真实使用为起点。拉取两类顶级查询:
对管理面板来说,这些通常是带筛选与排序的列表页。
接着,精确捕捉数据库看到的查询形态。把精确的 WHERE 与 ORDER BY 记录下来,包含排序方向与常见组合(例如:status = 'open' AND assignee_id = 42 ORDER BY created_at DESC)。微小差别会改变哪个索引有用。
使用一个简单的循环:
分页值得单独检查。基于偏移量的分页(OFFSET 20000)即使有索引也会随页数加深而变慢。如果用户经常跳到非常深的页面,考虑使用游标式分页(例如“显示时间戳/ID 之前的项”),这样索引能在大表上做一致的工作。
最后,保留一份小记录以便数月后仍能理解你的索引列表:索引名、表、列(及顺序)和它支持的查询。
最迅速让管理面板变慢的做法就是在不了解人们如何过滤、排序与分页的情况下乱加索引。索引会占空间并增加每次插入和更新的开销。
这些模式会造成大多数问题:
LIKE '%term%' 的包含搜索。一个常见场景:支持团队按 Status = Open 过滤工单,按 updated time 排序并翻页。如果你只在 status 上建索引,数据库可能仍需收集所有 open 工单并对它们排序。一个匹配筛选与排序的索引能快速返回第 1 页结果。
在管理 UI 改动前后做简短复查:
WHERE + ORDER BY 模式的索引。LIKE '%term%')并决定是否真的需要包含搜索。如果在 PostgreSQL 上用 AppMaster 构建管理面板,把这项复查作为发布新屏幕的一部分。正确的索引通常直接由 UI 实际使用的筛选与排序决定。
在添加更多索引前,先确认现有索引是否在帮助用户每天实际使用的筛选。一个好的管理面板在常用路径上感觉是瞬时的,而不是在罕见的单次搜索上。
一些检查能抓住大多数问题:
WHERE 与 ORDER BY 的索引,而不仅仅是其中一部分。一个切实可行的下一步是把你的黄金路径写成普通句子,比如:"Support agents 筛选 open tickets、分配给我、最近 7 天,按最新排序。" 用这些句子来设计一小组明确支持它们的索引。
如果你仍处在早期构建阶段,先在创建过多屏幕前建模数据与默认筛选会有帮助。在 AppMaster (appmaster.io) 中,你可以快速迭代管理视图,然后在真实使用揭示热点路径后,为它们添加少量匹配的索引。
从管理员最常打开的默认列表视图开始:这是管理员第一次打开面板时看到的内容,再加上那 2–3 个他们整天点击的筛选器。统计使用频率和痛点(最慢且使用最多),然后只为那些确实能减少等待时间的查询形态添加索引。
因为不同筛选器会触发不同量级的工作。有些筛选能把结果缩小到很小的一部分行,能很好地使用索引;而另一些筛选会触及很大的数据范围或需要对大量结果排序,所以即便在同一张表上,一个查询能用好索引而另一个仍要进行大量扫描和排序。
不一定。如果大多数行共享同一个状态,单独在 status 上建索引通常不会带来太大好处。索引更有价值的情况是该状态较少见,或者你把 status 与能真正缩小结果集的排序或另一个筛选条件组合起来索引。
使用与实际操作相匹配的复合索引,例如按状态筛选并按最近活动排序。对于 PostgreSQL,当某一状态主导视图时,部分索引(partial index)通常很有效,因为它保持索引小且专注于常用工作流。
对 assignee_id 建单列索引常常是快速的提升,因为这是一个等值筛选。如果“我的未完成事项”是核心工作流,优先使用以 assignee_id 开头并接着 status(可选再接排序列)的复合索引,通常比分散的单列索引表现更好。
未分配常以 NULL 表示,而 WHERE assignee_id IS NULL 与 WHERE assignee_id = 123 的查询计划可能不同。如果未分配队列很重要,应单独测试该查询,并采用支持它的索引策略(例如数据库支持时可用的部分索引)。
在用户实际过滤的那个时间戳列上建立 btree 索引。一般用 created_at 表示“新项”,用 updated_at 表示“最近变更”。如果 UI 还按最新排序,匹配排序方向的索引(例如 PostgreSQL 中的 created_at DESC)在高频列表上会更有效,但仍要限制复合索引到真正常用的组合。
绝大部分“缺失记录”问题来自日期边界处理,而不是索引。一个可靠的模式是起始包含、结束不包含:将用户选择的日期转换为 UTC,查询 \u003e= start 且 \u003c end_next_day,这样不会意外地丢掉结束日的记录。
因为像 LIKE %term% 的“包含”查询无法利用普通 btree 索引来直接跳转到匹配项,所以会扫描大量行。把精确查找(ID、邮箱、订单号)作为首选快速路径;只有在确有需要时,才用专门的搜索工具(PostgreSQL 全文搜索或三元组索引等)来实现包含搜索。
太多索引会增加存储并让插入、更新变慢,而且如果索引并不匹配 WHERE + ORDER BY 的实际查询模式,也可能无法解决真实瓶颈。一个安全的循环是:每次只改一个索引,重新测量目标慢查询,并且仅保留那些能明显改善常用路径的改动。\n\n如果你在 AppMaster 中构建管理界面,记录团队最常用的筛选和排序,然后用一小组镜像这些真实视图的索引来替代对每个字段一股脑地建索引。




