
设备预订应用:避免冲突并跟踪归还
规划一个设备预订应用,防止重复预订,记录归还和损坏,并将故障设备置于维护停用状态。
面向 CRUD 密集型后端的最小可观测性:结构化日志、核心指标与实用告警,帮助尽早发现慢查询、错误与故障。
CRUD 密集型的业务应用通常会以枯燥但代价高昂的方式失败:列表页每周变慢,保存按钮偶尔超时,支持反馈“随机 500 错误”却无法复现。开发环境看不出异常,但生产环境却不可靠。
真正的成本不仅是事件本身,更是猜测的时间。没有明确的信号,团队会在“肯定是数据库”“肯定是网络”“肯定是某个端点”之间来回跳,而用户只能等待、信任下降。
可观测性把这些猜测变成答案。简单来说:你能看到发生了什么并理解为什么。要做到这一点,需要三类信号:
对于 CRUD 应用和 API 服务,这不是关于花哨的仪表盘,而是关于快速定位问题。当一次“创建发票”的调用变慢时,你应该能在几分钟内判断出延迟是来自数据库查询、下游 API,还是被过载的 worker,而不是花几个小时排查。
最小设置应从你在糟糕日子里真正需要回答的问题出发:
如果你用生成栈构建后端(例如 AppMaster 生成的 Go 服务),同样的规则适用:从小做起,保持信号一致,只有在真实事件证明有用后再增加新的指标或告警。
最小可观测性由三大支柱构成:日志、指标和告警。追踪有用,但对多数 CRUD 密集型业务应用而言是锦上添花。
目标很直接:你应当知道(1)用户什么时候失败,(2)为什么失败,以及(3)问题出在哪个系统部分。如果你不能迅速回答这些问题,就会浪费时间猜测并争论改了什么。
通常最小的一组信号包括:
request_id、用户、端点和错误进行搜索。把症状和原因分开也很有帮助。症状是用户感受到的:500 错误、超时、页面变慢。原因是导致症状的元凶:锁争用、连接池饱和或新增筛选导致的慢查询。对症状做告警,用“原因”信号来调查。
一个实用规则:选一个查看重要信号的单一位置。当你在日志工具、指标工具和独立的告警收件箱之间切换时,在最关键时刻你会被拖慢。
当出现故障时,最快的定位路径通常是:“用户命中了哪次精确请求?”这就是为什么稳定的关联 ID 比几乎任何其他日志改进都重要。
选择一个字段名(常见为 request_id)并视为必填。在边缘(API 网关或第一个处理器)生成它,内部调用传递,并把它包含在每一行日志里。对于后台任务,每次任务运行创建新的 request_id,并在任务由 API 调用触发时保存 parent_request_id。
用 JSON 格式记录日志,而不是自由文本。这样在疲劳、紧张和快速浏览时日志仍可搜索且一致。
对于大多数 CRUD 密集型 API 服务,一组简单的字段就足够:
timestamp、level、service、envrequest_id、route、method、statusduration_ms、db_query_counttenant_id 或 account_id(安全的标识符,非个人数据)日志应帮助你缩小“是哪个客户和哪个界面”,同时避免导致数据泄露。默认避免记录姓名、邮箱、电话号码、地址、令牌或完整请求体。如果需要更深的细节,仅在按需场景并进行脱敏后记录。
两项字段在 CRUD 系统里回报很快:duration_ms 和 db_query_count。它们能在你加入追踪前就发现慢处理器和意外的 N+1 模式。
定义日志级别并统一使用:
info:预期事件(请求完成、任务启动)warn:不寻常但可恢复(请求变慢、重试成功)error:失败的请求或任务(异常、超时、依赖出错)如果你用类似 AppMaster 的平台构建后端,确保生成的服务使用相同的字段名,这样“按 request_id 搜索”在所有服务中都可工作。
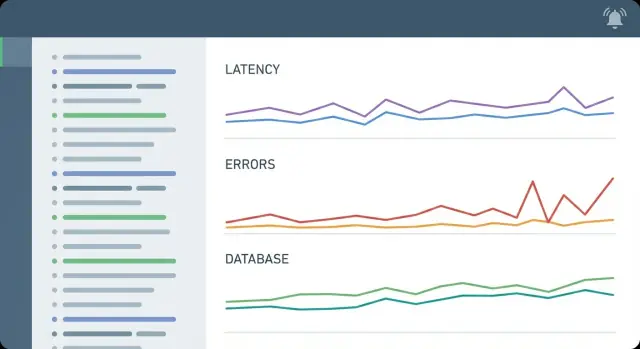
CRUD 密集型应用的大多数事件都有熟悉的形态:一两个端点变慢,数据库受压,用户看到加载转圈或超时。你的指标应能在几分钟内把这个故事讲清楚。
最小集合通常覆盖五个领域:
两点能让指标更具可操作性。
首先,将交互式 API 请求与后台工作分开。慢速的邮件发送或 webhook 重试循环可能会占满 CPU、数据库连接或外网,导致 API 看起来“随机变慢”。把队列、重试和任务时长单独作为时间序列跟踪,即便它们运行在同一后端。
其次,始终在仪表盘和告警里附加版本/构建元数据。当你部署一个新的生成后端(例如从无代码工具 AppMaster 重新生成 Go 服务)时,你需要快速判断:错误率或 p95 延迟是否在此发布后跃升?
一个简单规则:如果某个指标不能告诉你下一步该做什么(回滚、扩容、修查询或停止任务),它就不属于最小集合。
在 CRUD 密集型应用中,数据库常常是“感觉慢”变成真实用户痛点的地方。最小设置应让人一目了然地看出瓶颈是否来自 PostgreSQL,以及是哪类数据库问题。
你不需要几十个仪表盘。先从能解释大多数事件的信号开始:
在 API 层增加查询计时直方图,并用端点或用例打标签(例如:GET /customers、“搜索订单”、“更新工单状态”)。这样可以看出端点慢是因为执行了很多小查询,还是某一条大查询。
CRUD 界面经常触发 N+1:一个列表查询,然后对每行再发一次关联查询。关注那些请求数保持平稳但每次请求的 DB 查询数上升的端点。如果你是通过模型和业务逻辑生成后端,这通常是调优抓取模式的地方。
如果已有缓存,跟踪命中率。不要为了更好看图而盲目增加缓存。
把模式变更与迁移视为风险窗口:记录开始与结束时间,然后观察该窗口期间锁、查询时间和连接错误的激增。
告警应指向真实的用户问题,而不是一个繁忙的图表。对于 CRUD 密集型应用,先监控用户感受:错误和变慢。
如果一开始只加三条告警,建议为:
之后再添加几条“可能原因”型告警。CRUD 后端常见失败模式:数据库连接用尽、后台队列堆积、或某个单端点开始超时并拖垮整个 API。
把“p95 > 200ms”这样硬编码的数字硬套在各环境里通常不可行。先测量一周的正常值,然后在正常值上加安全裕度设置告警。例如,如果业务时间内 p95 通常是 350–450ms,则设置在 700ms、持续 10 分钟触发。如果 5xx 通常在 0.1–0.3%,那就把告警设置为 2%、持续 5 分钟。
保持阈值稳定。不要每天都调。发生事件后在能把更改与真实结果联系起来时再调优。
使用两种严重级别让人信任信号:
在预期变动期间(如发布窗口、计划维护)静默告警。
让告警可操作:包含“先检查什么”(顶端端点、DB 连接、最近部署)和“有什么变化”(新发布、模式更新)。如果你用 AppMaster 构建,写明最近是哪个后端或模块被重新生成并部署,因为那常常是最快的线索。
当你明确什么叫“足够好”时,最小设置会更容易。这就是 SLO 的作用:把模糊的监控目标变成具体的告警触发条件。
从映射到用户感受的 SLIs 开始:可用性(用户能否完成请求)、延迟(动作完成速度)和错误率(请求失败的频次)。
按端点分组而不是逐条路由设置 SLO。对 CRUD 密集型应用,分组能保持可读性:读取(GET/列表/搜索)、写入(create/update/delete)和认证(登录/刷新 token)。这样避免出现无人维护的上百条小 SLO。
典型可接受的 SLO 示例:
错误预算是 SLO 允许的“坏时间”。99.9% 的月度可用性意味着每月大约允许 43 分钟的不可用时间。如果你在月初就花光了预算,应暂停高风险变更,直到稳定性恢复。
用 SLO 来区分什么需要告警,什么只需仪表盘趋势。只有在错误预算快速消耗(用户正在真实失败)时才告警,而不是因为某个指标比昨天稍差一点。
如果你快速生成后端(例如 AppMaster 生成的 Go 服务),SLO 能在实现底层频繁变化时把注意力保持在用户影响上。
从用户最常触达的系统切片开始。挑选那些变慢或故障就会让整个应用看起来崩坏的 API 调用和任务。
把你的顶级端点和后台工作写下来。对于 CRUD 业务应用,通常是登录、列表/搜索、创建/更新以及一个导入或导出任务。如果你用 AppMaster 构建后端,把生成的端点和以计划或 webhook 触发的业务流程都列进去。
request_id、user_id(若可用)、endpoint、status_code、latency_ms、db_time_ms,以及已知失败的简短 error_code。保持告警少而集中。你要的是能指向用户影响的告警,而不是“某些东西变了”。
入门集合可以包括:API p95 延迟过高、持续 5xx 比率、4xx 突增(常为认证或校验变更)、后台任务失败、慢查询、数据库连接接近限制,以及磁盘空间不足(自托管时)。
然后为每条告警写一个小型跑本(runbook)。一页纸就够:先检查什么(仪表盘面板与关键日志字段)、可能原因(DB 锁、缺索引、下游故障),以及首要安全动作(重启卡住的 worker、回滚变更、暂停重负载任务)。
把监控当成打勾事项是浪费最迅速的方式。CRUD 密集型应用通常以几种可预见的方式失败(慢数据库调用、超时、糟糕的发布),所以信号应专注于这些问题。
最常见的问题是告警疲劳:太多告警、太少可执行动作。如果你对每个峰值都发页面,团队在两周内就会不再信任告警。一个好规则是:告警应指向可能的修复,而不仅仅是“某些东西变了”。
另一个常见错误是缺失关联 ID。如果你不能把某条错误日志、一次慢请求和一条数据库查询关联到同一个请求,你就会损失数小时。确保每个请求都有 request_id(并在日志、追踪(若有)及响应(安全时)中包含它)。
噪声系统通常出现相同的问题:
CRUD 应用特别容易掉进“平均陷阱”。一条慢查询可能让 5% 的请求体验很差,而平均值看起来还好。尾部延迟加上错误率能给出更清晰的画面。
添加部署标记。无论你是通过 CI 发布还是用 AppMaster 重新生成代码,都要记录版本和部署时间,这样你能快速判断问题是否随发布而来。
当你能快速回答几个问题而不需要在仪表盘里翻找 20 分钟时,说明你的设置起作用了。如果无法快速得到“是/否”的答案,你缺少关键信号或视图过于分散。
在一次事件中,大部分检查你应能在 1 分钟内完成:
日志需要在保证安全的同时有用:要有足够的上下文以便跨服务追踪同一次失败请求,但不能泄露个人数据。
挑一个近期失败并打开其日志。确认你有 request_id、端点、状态码、耗时和清晰的错误信息。同时确认没有记录原始令牌、密码、完整支付信息或敏感字段。
如果你用 AppMaster 构建 CRUD 密集型后端,争取做一个统一的“事件视图”来组合这些检查:错误、按端点的 p95 延迟和数据库健康。这就覆盖了业务应用中大多数真实宕机场景。
一个内部管理后台上午都工作正常,到了繁忙时段变得明显缓慢。用户抱怨“订单”列表打开和保存编辑需要 10–20 秒。
你先看顶层信号。API 仪表盘显示读端点的 p95 从约 300 ms 跳升到 4–6 s,同时错误率保持低位。数据库面板显示活跃连接接近连接池上限并且锁等待增加。后端节点的 CPU 看起来正常,因此这不像是计算资源的问题。
接着,你挑一条慢请求并通过日志跟踪。按端点过滤(例如 GET /orders)并按耗时排序。从一条 6 秒的请求中取出 request_id 并在各服务中搜索它。你看到处理器很快完成,但该 request_id 对应的数据库查询日志行显示一条耗时 5.4 秒的查询,rows=50,并有较大的 lock_wait_ms。
现在你可以自信地说明原因:慢点在数据库路径(慢查询或锁争用),而不是网络或后端 CPU。这正是最小设置带来的价值:更快地缩小排查范围。
典型的修复按安全顺序:
用有针对性的告警把环路闭合。仅当端点分组的 p95 延迟在 10 分钟内持续高于阈值,且数据库连接使用高于(例如)80% 时才触发页面告警。这样的组合能减少噪声并在下一次更早发现类似问题。
一个最小可观测性设置在第一天应该感觉平淡无奇。如果一开始就堆积太多仪表盘和告警,你会永远调不完它们,仍然错过真正的问题。
把每次事件当作反馈。修复发布后问自己:什么能让定位更快、更容易?仅添加能实现该目标的信号。
即便目前只有一个服务,也尽早标准化。日志里使用相同字段名、指标也用一致命名,这样新增服务时就能无争议地套用同样模式,也便于复用仪表盘。
小范围的发布纪律会很快带来回报:
如果你用 AppMaster 构建后端,建议在生成服务前规划好可观测字段和关键指标,这样每个新 API 都能默认带上统一的结构化日志和健康信号。如果你想从一个地方开始构建这些后端,AppMaster(appmaster.io)旨在生成可用于生产的后端、Web 和移动应用,同时在需求变化时保持实现一致性。
每次只挑一个改进项,基于真实痛点来做:
在每个真实事件后重复这个循环。几周之内,你会得到一套适合你的 CRUD 应用和 API 流量的监控,而不是一套千篇一律的模板。
开始采用可观测性,当你在生产中花的时间解释问题比修复问题还多时。如果你看到“随机 500 错误”、列表页面变慢或无法复现的超时,一组一致的日志、指标和告警会节省大量的猜测时间。
监控告诉你“发生了什么”(什么坏了),而可观测性帮你理解“为什么”发生,通过可关联的上下文丰富信号来定位原因。对于 CRUD API,实用目标是快速定位:哪个端点、哪个用户/租户,以及时间到底花在了应用层还是数据库上。
最小可行的方案包括结构化的请求日志、少量核心指标和几条以用户影响为导向的告警。对于许多 CRUD 应用,如果你已经记录了 duration_ms、db_time_ms(或类似字段)和一个稳定的 request_id 可以全局搜索,分布式追踪可以后置。
使用单一的关联字段,比如 request_id,并在每条请求日志和每次后台任务运行中包含它。在边缘(API 网关或第一个处理器)生成它,内部调用传递它,这样就能通过日志快速重建一个失败或变慢的请求链路。
记录 timestamp、level、service、env、route、method、status、duration_ms,以及像 tenant_id 或 account_id 这样的安全标识符。默认不要记录个人数据、令牌或完整请求体;如需更深细节,仅在特定错误下按需记录并进行脱敏处理。
跟踪请求量、5xx 比率、延迟百分位(至少 p50 和 p95),以及基本的饱和度信息(CPU/内存和任何工作进程或队列压力)。尽早加入数据库时间和连接池使用率,因为很多 CRUD 故障实质上是数据库争用或连接耗尽。
因为用户感受到的是尾部延迟而非平均值,p95/p99 能揭示那些用户实际遇到的慢请求。平均值可能看起来正常,但一部分请求的 p95 很糟糕,正是“随机变慢”的根源。
监控慢查询率与 p95/p99 查询时间、锁等待/死锁、以及连接使用(活跃连接 vs 池限制)。这些信号能告诉你数据库是否是瓶颈,以及问题更像是查询性能、争用还是连接不足。
先从用户感受出发:持续的 5xx 比率、持续的 p95 延迟、以及成功请求数量的突然下降。这样可以避免告警疲劳:先告警用户可感知的问题,再根据需要补充“可能原因”类的告警(如数据库连接接近上限或任务积压)。
把版本/构建元数据附到日志、仪表盘和告警里,并记录部署标记,这样你能快速判断回归是否发生在某次发布之后。对于由生成工具(如 AppMaster)生成并频繁再生成的后端,这点尤其重要。




