31 авг. 2025 г.·7 мин
Таймеры SLA и эскалации: поддерживаемое моделирование рабочих процессов
Научитесь моделировать таймеры SLA и эскалации с явными состояниями, поддерживаемыми правилами и простыми путями эскалации, чтобы workflow‑приложения было легко изменять.
Почему правила на основе времени быстро становятся трудны в сопровождении
Правила по времени обычно начинают просто: «Если на тикет нет ответа 2 часа, уведомить кого‑то». Затем рабочий процесс растёт, команды добавляют исключения, и внезапно никто не уверен, что же происходит. Так таймеры SLA и эскалации превращаются в лабиринт.
Полезно чётко назвать движущие части.
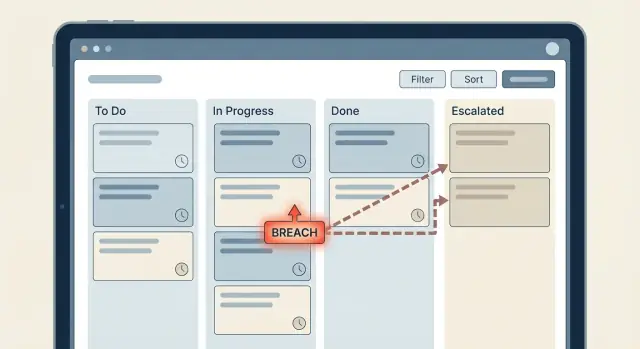
Таймер — это часы, которые вы запускаете (или планируете) после события, например «тикет переведён в Waiting for Agent». Эскалация — это действие, которое вы выполняете, когда часы достигают порога: уведомить лидера, сменить приоритет или переназначить задачу. Нарушение (breach) — это записанный факт «мы пропустили SLA», который используют для отчётов, алертов и последующих действий.
Проблемы появляются, когда логика времени разнесена по приложению: несколько проверок в потоке «обновить тикет», ещё несколько в ночной задаче и разовые правила, добавленные позже для специального клиента. Каждая часть по‑отдельности логична, но вместе они порождают сюрпризы.
Типичные симптомы:
- Одинаковое вычисление времени копируется в разные места, и исправления не доходят до всех копий.
- Пропускаются пограничные случаи (пауза, возобновление, переназначение, переключения статуса, выходные vs рабочие часы).
- Правило срабатывает дважды, потому что два пути планируют похожие таймеры.
- Аудит превращается в гадание: нельзя ответить «почему это эскалировало?» без прочтения всего приложения.
- Маленькие изменения кажутся рискованными, поэтому команды добавляют исключения вместо того, чтобы исправить модель.
Цель — предсказуемое поведение, которое легко изменить позже: один ясный источник правды для тайминга SLA, явные состояния нарушения для отчётов и простые шаги эскалации, которые можно поменять без поиска по визуальной логике.
Начните с определения SLA, которое вам действительно нужно
Прежде чем строить таймеры, выпишите точное обещание, которое вы измеряете. Много ошибок возникает от попытки покрыть все возможные правила времени сразу.
Распространённые типы SLA звучат похоже, но измеряют разное:
- First response: время до первого содержательного ответа человека.
- Resolution: время до окончательного закрытия проблемы.
- Waiting on customer: время, которое не должно учитываться, пока вы заблокированы клиентом.
- Internal handoff: время, которое тикет может находиться в конкретной очереди.
- Reopen SLA: что происходит, когда «закрытый» элемент возвращается.
Далее решите, что значит «время». Календарное время считает 24/7. Рабочее время учитывает только заданные часы работы (например, Пн‑Пт, 9–18). Если вам не нужно рабочее время, избегайте его на раннем этапе — оно добавляет пограничные случаи: праздники, часовые пояса и частичные дни.
Потом пропишите правила паузы. Пауза — это не просто «изменён статус». Это правило с владельцем. Кто может поставить паузу (только агент, только система, действие клиента)? Какие статусы её ставят (Waiting on Customer, On Hold, Pending Approval)? Что возобновляет? При возобновлении продолжаем ли со оставшимся временем или перезапускаем таймер?
И наконец, определите, что значит breach в продуктовых терминах. Нарушение должно быть конкретной сущностью, которую можно хранить и запрашивать, например:
- флаг нарушения (true/false)
- метка времени нарушения (
breached_at) (когда дедлайн был пропущен)
- состояние нарушения (Approaching, Breached, Resolved after breach)
Пример: «First response SLA breached» может означать, что тикет получает состояние Breached, поле breached_at и уровень эскалации, равный 1.
Модельте SLA как явные состояния, а не как разбросанные проверки
Если вы хотите, чтобы таймеры SLA и эскалации оставались читаемыми, относитесь к SLA как к маленькой машине состояний. Когда «истина» разбросана по мелким проверкам (if now > due, если приоритет высокий, если последний ответ пуст), визуальная логика быстро запутывается и небольшие изменения ломают систему.
Начните с короткого, согласованного набора состояний SLA, которые поймёт любой шаг рабочего процесса. Для многих команд этого достаточно:
- On track
- Warning
- Breached
- Paused
- Completed
Один флаг breached = true/false редко бывает достаточен. Нужен контекст: какой SLA нарушен (first response или resolution), находится ли он сейчас на паузе и была ли уже эскалация. Без этого люди начинают вычитывать смысл из комментариев, меток времени и имён статусов — и логика становится хрупкой.
Сделайте состояние явным и сохраняйте метки времени, которые это объясняют. Тогда решения просты: оценщик читает запись, решает следующее состояние, и всё остальное реагирует на это состояние.
Полезные поля рядом с состоянием:
started_at и due_at (какие часы мы запускаем и когда дедлайн)breached_at (когда фактически пересекли линию)paused_at и paused_reason (почему часы остановились)breach_reason (какое правило вызвало нарушение, простыми словами)last_escalation_level (чтобы не уведомлять один и тот же уровень дважды)
Пример: тикет переходит в «Waiting on customer». Установите состояние SLA в Paused, запишите paused_reason = "waiting_on_customer" и остановите таймер. Когда клиент ответит — возобновите, установив новый started_at (или сняв паузу и пересчитав due_at). Никаких охот за условиями по всему коду.
Спроектируйте лестницу эскалаций под вашу организацию
Лестница эскалаций — это ясный план действий, когда таймер SLA близок к нарушению или уже нарушён. Ошибка — просто копировать оргструктуру в workflow. Нужен минимальный набор шагов, который поможет сдвинуть зависшую задачу.
Простая лестница, которую многие используют: назначенный агент (Level 0) получает первое напоминание, затем подключается тимлид (Level 1), и только после этого менеджер (Level 2). Это работает, потому что начинается у того, кто может реально сделать работу, а полномочия растут только при необходимости.
Чтобы правила эскалации было легко поддерживать, храните пороги эскалации как данные, а не как захардкоженные условия. Поместите их в таблицу или объект настроек: «первое напоминание через 30 минут», «эскалация к лидам через 2 часа». Когда политика меняется, вы обновляете одно место, а не правите несколько рабочих потоков.
Делайте эскалации полезными, а не шумными
Эскалации превращаются в спам, если срабатывают слишком часто. Добавьте защитные механизмы, чтобы каждый шаг имел свою цель:
- Правило повторной отправки (например, повторно напомнить Level 0 один раз, если не было действий).
- Окно охлаждения (например, не присылать уведомления в течение 60 минут после предыдущего).
- Условие остановки (отменять будущие эскалации, как только предмет переходит в совместимый статус).
- Максимальный уровень (не подниматься выше Level 2 без ручного триггера).
Решите, кто отвечает за тикет после эскалации
Одни только уведомления не решают проблему, если ответственность остаётся размытой. Заранее определите правила владения: остаётся ли тикет у агента, переназначается ли лиду или переходит в общую очередь?
Пример: после эскалации Level 1 переназначьте тикет тимлиду и сделайте оригинального агента наблюдателем. Так будет понятно, кто должен действовать дальше, и тикет не будет отскакивать между людьми.
Поддерживаемый паттерн: события, оценщик, действия
Чисто моделируйте два SLA
Отдельно отслеживайте SLA на ответ и на разрешение в поддержке.
Проще всего держать таймеры SLA и эскалации в порядке, рассматривая их как маленькую систему из трёх частей: события, оценщик и действия. Это не даёт логике времени расползаться по десяткам проверок вида «if time > X».
1) События: только фиксируйте, что случилось
События — простые факты, которые не содержат математике по таймерам. Они отвечают на вопрос «что изменилось?», а не «что теперь делать?». Типичные события: тикет создан, агент ответил, клиент ответил, статус изменился, ручная пауза/возобновление.
Храните их как метки времени и поля статусов (например: created_at, last_agent_reply_at, last_customer_reply_at, status, paused_at).
2) Оценщик: одно место, которое считает время и выставляет состояние
Сделайте единый шаг «SLA evaluator», который запускается после любого события и по расписанию. Этот оценщик — единственное место, где вычисляются due_at и оставшееся время. Он читает факты, пересчитывает дедлайны и записывает явные поля состояния SLA, например sla_response_state и sla_resolution_state.
Здесь модель нарушений остаётся аккуратной: оценщик ставит состояния вроде OK, AtRisk, Breached, вместо того чтобы прятать логику внутри уведомлений.
3) Действия: реагируйте на смены состояния, а не на математику времени
Уведомления, назначение и эскалации должны срабатывать только при изменении состояния (например: OK → AtRisk). Держите отправку сообщений отдельно от обновления состояния. Тогда вы сможете менять, кто получает уведомления, не трогая расчёты.
Шаг за шагом: как строить таймеры и эскалации во визуальной логике
Поддерживаемая конфигурация обычно выглядит так: несколько полей на записи, маленькая таблица политик и один оценщик, который решает, что делать дальше.
1) Настройте данные, чтобы логика времени имела одно место
Начните с сущности, которая владеет SLA (тикет, заказ, запрос). Добавьте явные метки времени и одно поле «текущее состояние SLA». Держите всё простым и предсказуемым.
Затем добавьте таблицу политик, которая описывает правила вместо их захардкоживания во многих потоках. Простой вариант — одна строка на приоритет (P1, P2, P3) с колонками для целевых минут и порогов эскалации (например: предупреждать на 80%, нарушать на 100%). Это отличается от правки пяти workflow‑ов — вы меняете одну запись.
2) Запускайте плановый оценщик, а не десятки таймеров
Вместо создания таймеров везде используйте один плановый процесс, который проверяет элементы периодически (каждую минуту для строгих SLA, каждые 5 минут для большинства команд). Расписание вызывает один оценщик, который:
- выбирает активные записи (не закрытые)
- вычисляет «now vs due» и выводит следующее состояние
- рассчитывает следующий момент проверки (чтобы не проверять лишний раз)
- пишет
sla_state и next_check_at
Так с таймерами SLA и эскалациями легче работать: вы отлаживаете один оценщик, а не множество таймеров.
3) Делайте действия реагирующими на изменения (edge‑triggered)
Оценщик должен выводить и новое состояние, и флаг, что состояние изменилось. Только тогда запускайте сообщения или задачи (например ok → warning, warning → breached). Если запись остаётся в breached час, не нужно слать 12 одинаковых уведомлений.
Практический паттерн: храните sla_state и last_escalation_level, сравнивайте их с новыми вычисленными значениями и только при изменении вызывайте отправку сообщений (email/SMS/Telegram) или создание внутренней задачи.
Обработка пауз, возобновлений и смены статусов
Централизуйте логику тайминга SLA
Постройте оценщик SLA, который задаёт понятные состояния: OK, Warning и Breached.
Паузы — место, где правила времени обычно ломаются. Если их не смоделировать явно, SLA либо будет продолжать идти, когда не должен, либо сбрасываться, когда кто‑то случайно нажал статус.
Простое правило: только один статус (или маленький набор) ставит паузу. Частый выбор — Waiting for customer. Когда тикет уходит в этот статус, сохраните pause_started_at. Когда клиент ответит и тикет выйдет из статуса, закройте паузу, записав pause_ended_at и добавив длительность в paused_total_seconds.
Не ограничивайтесь одним счётчиком. Фиксируйте каждое окно паузы (start, end, кто или что его инициировал), чтобы остался аудит‑трейл. Тогда при разборе, почему кейс нарушил SLA, вы сможете показать, что он провёл 19 часов в ожидании клиента.
Переназначение и обычные смены статусов не должны перезапускать часы. Держите метки SLA отдельно от полей владения. Например, sla_started_at и sla_due_at задаются один раз (при создании или при изменении политики), а переназначение просто обновляет assignee_id. Оценщик вычислит прошедшее время как: now − sla_started_at − paused_total_seconds.
Правила, которые сохраняют предсказуемость таймеров SLA и эскалаций:
- Ставьте паузу только для явных статусов (например, Waiting for customer), а не для «мягких» флагов.
- Возобновляйте только при выходе из этого статуса, а не при любом входящем сообщении.
- Никогда не сбрасывайте SLA при переназначении; рассматривайте это как маршрутизацию, а не новый кейс.
- Разрешайте ручные переводы, но требуйте причину и ограничьте, кто может так делать.
- Логируйте каждое изменение статуса и каждое окно паузы.
Пример сценария: тикет поддержки с SLA на ответ и на разрешение
Примите паттерн Events → Evaluator → Actions
Разделите события, оценщик и действия, чтобы каждая часть была простой для изменений.
Простой способ проверить дизайн — тикет с двумя SLA: первый ответ за 30 минут и полное разрешение за 8 часов. Здесь логика часто ломается, если она разбросана по экранам и кнопкам.
Предположим, что тикет хранит: state (New, InProgress, WaitingOnCustomer, Resolved), response_status (Pending, Warning, Breached, Met), resolution_status (Pending, Warning, Breached, Met), а также метки времени created_at, first_agent_reply_at и resolved_at.
Реалистичная временная шкала:
- 09:00 Тикет создан (New). Запускаются таймеры ответа и разрешения.
- 09:10 Назначен агент A (оба SLA остаются Pending).
- 09:25 Ответа от агента нет. Ответ достигает 25 минут и переходит в Warning.
- 09:40 Всё ещё нет ответа. Ответ достигает 30 минут и становится Breached.
- 09:45 Агент отвечает. Response помечается как Met (даже если ранее был Breached, сохраняется запись о нарушении для отчётов).
- 10:30 Клиент отвечает с уточнениями. Тикет идёт в InProgress, разрешение продолжается.
- 11:00 Агент задаёт вопрос. Тикет уходит в WaitingOnCustomer и таймер разрешения ставится на паузу.
- 14:00 Клиент отвечает. Тикет возвращается в InProgress и таймер возобновляется.
- 16:30 Тикет решён. Resolution становится Met, если суммарное активное время меньше 8 часов, иначе Breached.
Для эскалаций держите одну ясную цепочку, которая срабатывает на переходы состояний. Например: при переходе response → Warning уведомьте назначенного агента; при переходе в Breached — уведомьте тимлида и обновите приоритет.
На каждом шаге обновляйте небольшой набор полей, чтобы было легко понимать логику:
- Устанавливайте
response_status или resolution_status в Pending, Warning, Breached или Met.
- Записывайте
*_warning_at и *_breach_at один раз и больше не перезаписывайте.
- Инкрементируйте
escalation_level (0, 1, 2) и сохраняйте escalated_to (Agent, Lead, Manager).
- Добавляйте строку в лог
sla_events с типом события и кем уведомили.
- При необходимости обновляйте
priority и due_at, чтобы UI и отчёты отражали эскалацию.
Ключ в том, что Warning и Breached — явные состояния. Их видно в данных, их можно аудитить, и лестницу можно менять позже без поиска скрытых проверок таймеров.
Распространённые ловушки и как их избежать
Логика SLA портится, когда она расползается. Быстрая проверка времени в кнопке здесь, условный алерт там — и вскоре никто не может объяснить, почему тикет эскалировал. Держите таймеры SLA и эскалации как маленькую, центральную часть логики, на которую опираются все экраны и действия.
Одна из ловушек — встраивание проверок времени во множество мест (UI, API‑хендлеры, ручные действия). Исправление — вычислять статус SLA в одном оценщике и сохранять результат на записи. Экраны должны читать состояние, а не его придумывать.
Другая ловушка — разный источник времени. Если браузер считает «минуты с создания», а бэкенд использует серверное время, вы получите пограничные случаи вокруг сна, часовых поясов и перехода на летнее/зимнее время. Для всего, что триггерит эскалацию, предпочитайте серверное время.
Уведомления тоже могут быстро стать шумными. Если вы «проверяете каждую минуту и шлёте, если просрочено», люди будут получать спам каждую минуту. Привязывайте сообщения к переходам: «warning sent», «escalated», «breached». Тогда вы шлёте по одному разу на шаг и можете отследить, что именно произошло.
Логика по рабочим часам — ещё один источник случайной сложности. Если у каждого правила своя ветка «если выходной, то…», обновления становятся мучительными. Поместите математику рабочих часов в одну функцию (или общий блок), который возвращает «сколько SLA‑минут потреблено», и переиспользуйте её.
И наконец: не полагайтесь на пересчёт нарушения заново. Сохраняйте момент, когда оно произошло:
- Запишите
breached_at в первый раз, когда обнаружили нарушение, и не перезаписывайте.
- Сохраняйте
escalation_level и last_escalated_at, чтобы действия были идемпотентны.
- Сохраняйте
notified_warning_at (или похожее), чтобы не повторять оповещения.
Пример: тикет попал в «Response SLA breached» в 10:07. Если вы только пересчитываете, позже смена статуса или баг с паузой может показать нарушение в 10:42. С breached_at = 10:07 отчёты и постмортемы остаются консистентными.
Быстрый чеклист для поддерживаемой логики SLA
Остановите спам от эскалаций
Триггерьте уведомления только при смене состояния, чтобы избежать повторных оповещений.
Прежде чем добавлять таймеры и алерты, пройдитесь по правилам с целью сделать их читаемыми через месяц.
- Каждый SLA имеет чёткие границы. Опишите точное событие старта, событие остановки, правила паузы и что считается нарушением. Если нельзя указать одно событие старта, логика расползётся в случайные условия.
- Эскалации — это лестница, а не куча алертов. Для каждого уровня эскалации определите порог (например, 30m, 2h, 1d), кого уведомлять, окно охлаждения и максимальный уровень.
- Смена состояний логируется с контекстом. Когда состояние SLA меняется (Running, Paused, Breached, Resolved), сохраняйте кто и когда это сделал, и почему.
- Плановые проверки безопасно запускать дважды. Оценщик должен быть идемпотентным: при повторном запуске не должен создавать дубликаты эскалаций или заново слать те же сообщения.
- Уведомления идут при переходах, а не от чистой математики времени. Шлите оповещения при смене состояния, а не при простом условии «now − created_at > X».
Практическая проверка: возьмите один тикет, который близок к нарушению, и проиграйте его временную линию. Если вы не можете объяснить, что произойдёт при каждой смене статуса, не читая весь workflow, модель слишком разбросана.
Следующие шаги: реализуйте, наблюдайте, затем улучшайте
Постройте минимально полезный кусок сначала. Выберите один SLA (например, первый ответ) и один уровень эскалации (например, уведомление тимлида). Вы узнаете больше за неделю реального использования, чем за идеальный дизайн на бумаге.
Держите пороги и получателей как данные, а не как логику. Поместите минуты и часы, правила по рабочим часам, кто уведомляется и какая очередь владеет кейсом в таблицы или записи конфигурации. Тогда рабочий процесс останется стабильным, а бизнес сможет менять числа и маршрутизацию.
Запланируйте простую панель мониторинга сразу. Большая аналитика не нужна — просто общий взгляд на текущее состояние: on track, warning, breached, escalated.
Если вы строите это в no‑code workflow‑приложении, выбирайте платформу, которая позволяет моделировать данные, логику и плановые оценщики в одном месте. Например, AppMaster (appmaster.io) поддерживает моделирование БД, визуальные бизнес‑процессы и генерацию production‑ready приложений — это хорошо подходит под паттерн «events, evaluator, actions».
Улучшайте безопасно, итерациями в порядке:
- Добавляйте следующий уровень эскалации только после того, как Level 1 стабилен
- Расширяйтесь с одного SLA до двух (response и resolution)
- Добавляйте правила паузы/возобновления (waiting on customer, on hold)
- Уточняйте уведомления (дедупликация, тихие часы, корректные получатели)
- Пересматривайте еженедельно: меняйте пороги в данных, а не перекраивайте потоки
Когда будете готовы, соберите небольшой рабочий вариант и растите его на основе реальных отзывов и реальных тикетов.
Вопросы и ответы
Начните с чёткой формулировки обещания, которое вы измеряете (например, первый ответ или разрешение), пропишите точные правила старта, остановки и паузы. Затем централизуйте вычисления времени в одном оценщике, который выставляет явные состояния SLA, вместо того чтобы рассыпать проверки вида «if now > X» по разным рабочим потокам.
Таймер — это часы, которые вы запускаете или планируете после события (например, тикет перешёл в новый статус). Эскалация — это действие при достижении порога (уведомление лида, изменение приоритета). Бреач (нарушение) — это сохранённый факт, что SLA не выполнено, который потом используют для отчётов и разборов.
Да. First response измеряет время до первого содержательного ответа человека, а resolution — до окончательного закрытия. Они по‑разному ведут себя при паузах и повторных открытиях, поэтому проще моделировать и отчёты получать отдельно.
По умолчанию используйте календарное время — оно проще и легче отлаживается. Рабочее время добавляет сложности: праздники, часовые пояса, частичные дни. Включайте рабочее время только если это действительно необходимо.
Моделируйте паузы как явные состояния, привязанные к конкретным статусам (например, Waiting on Customer). Фиксируйте момент начала и конца паузы. При возобновлении либо продолжайте с оставшимся временем, либо пересчитывайте дедлайн в одном месте — но не позволяйте случайным переключениям статуса сбрасывать таймер.
Один флаг «breached = true/false» сглаживает контекст: какой SLA нарушен, на паузе ли он и была ли уже эскалация. Лучше использовать явные состояния: On track, Warning, Breached, Paused, Completed — чтобы система была предсказуемой и удобной для аудита.
Храните метки времени, которые объясняют состояние: started_at, due_at, breached_at и поля паузы вроде paused_at и paused_reason. Также сохраняйте данные по эскалациям, например last_escalation_level, чтобы не посылать одно и то же уведомление повторно.
Небольшая лестница эскалации: сначала человек, который может сделать работу, потом тимлид, и только при необходимости менеджер. Храните пороги и получателей как данные (таблица политик), чтобы менять время эскалации без правки множества процессов.
Привязывайте уведомления к переходам состояний (OK → Warning, Warning → Breached), а не к проверкам «всё ещё просрочено». Добавьте простые защитные правила: окна ожидания (cooldown), правило повторной отправки и условие остановки, чтобы не спамить.
В no‑code инструменте применяйте паттерн events → evaluator → actions: события лишь фиксируют факты, оценщик вычисляет дедлайны и выставляет состояния SLA, а действия реагируют только на смены состояния. В AppMaster вы можете смоделировать данные, собрать визуальный бизнес‑процесс для оценщика и запускать уведомления и переназначения из реакций на обновления состояния, сохраняя математику времени в одном месте.