08 февр. 2025 г.·5 мин
Приложение для управления инцидентами для IT‑команд: рабочие процессы и постмортемы
Спланируйте и создайте приложение для управления инцидентами в IT: уровни критичности, чёткая ответственность, таймлайны и постмортемы в одном внутреннем инструменте.
Какая проблему на самом деле решает внутреннее приложение для инцидентов
Когда случается авария, большинство команд хватают то, что под рукой: тред в чате, цепочку писем, может быть, таблицу, которую кто-то обновляет, когда есть минутка. Под давлением такая схема ломается всегда одинаково: ответственность размывается, метки времени теряются, а решения исчезают в потоке сообщений.
Простое приложение для управления инцидентами исправляет базовые вещи. Оно даёт одно место, где живёт инцидент — с понятным владельцем, уровнем критичности, который всем ясен, и хронологией того, что и когда происходило. Эта единая запись важна, потому что одни и те же вопросы всплывают при каждом инциденте: кто ведёт? когда всё началось? каково текущее состояние? что уже пробовали?
Без общей записи передачи теряют время. Поддержка говорит клиентам одно, а инженерия делает другое. Руководители просят апдейты и отвлекают тех, кто чинит. Потом никто не может с уверенностью восстановить таймлайн, и постмортем превращается в догадки.
Цель не в том, чтобы заменить мониторинг, чат или тикеты. Оповещения по-прежнему могут приходить из других систем. Задача — зафиксировать след решений и сохранить синхронность людей.
Операторы IT и инженеры на дежурстве используют такое приложение для координации реакции. Поддержка — чтобы быстро давать точные обновления. Руководители — чтобы видеть прогресс без прерывания тех, кто работает над устранением.
Пример сценария: P1-авария от оповещения до закрытия
В 9:12 мониторинг отмечает всплеск 500 ошибок на портале клиентов. Агент поддержки также сообщает: «У большинства пользователей не работает вход.» Руководитель на дежурстве открывает P1-инцидент в приложении и прикладывает первое оповещение плюс скриншот от поддержки.
При P1 поведение меняется быстро. Владелец инцидента подтягивает владельца бэкенда, владельца базы данных и связного из поддержки. Нефундаментальная работа приостанавливается. Плановые деплои останавливаются. Команда договаривается о частоте обновлений (например, каждые 15 минут). Запускается общий созвон, но запись инцидента остаётся источником правды.
К 9:18 кто-то спрашивает: «Что изменилось?» В таймлайне видно деплой в 8:57, но не указано, что именно деплоилось. Владелец бэкенда всё равно откатывает. Ошибки падают, затем возвращаются. Теперь команда подозревает базу данных.
Большинство задержек проявляются в нескольких предсказуемых местах: неясные передачи («я думал, что ты это проверял»), потерянный контекст (недавние изменения, известные риски, текущий владелец) и рассыпанные обновления в чате, тикетах и почте.
В 9:41 владелец базы данных находит убегающий запрос, запущенный по расписанию. Он отключает задачу, перезапускает пострадавший сервис и подтверждает восстановление. Критичность понижают до P2 для наблюдения.
Хорошее закрытие — это не просто «оно снова работает». Это чистая запись: поминутный таймлайн, окончательная корневая причина, кто какое решение принял, что было приостановлено и какие follow-up назначены с владельцами и сроками. Так стрессовый P1 превращается в урок, а не в повторную боль.
Модель данных: самая простая структура, которая всё ещё работает
Хороший инструмент для инцидентов — это в основном хорошая модель данных. Если записи расплывчаты, люди будут спорить о том, что такое инцидент, когда он начался и что ещё открыто.
Держите базовые сущности близко к тому, как команды IT уже говорят:
- Incident: контейнер для того, что произошло
- Service: что поддерживает бизнес (API, база данных, VPN, биллинг)
- User: участники реакции и заинтересованные лица
- Update: краткие статусные заметки во времени
- Task: конкретная работа во время инцидента (и после)
- Postmortem: единый отчёт, привязанный к инциденту, с пунктами действий
Чтобы избежать путаницы позже, дайте Incident несколько структурированных полей, которые всегда заполняются. Свободный текст полезен, но не должен быть единственным источником правды. Практический минимум: понятный заголовок, влияние (что видят пользователи), затронутые сервисы, время начала, текущий статус и критичность.
Важнее отношений, чем лишних полей. Один инцидент должен иметь много обновлений и много задач, а также связь «многие ко многим» с сервисами (потому что сбои часто затрагивают несколько систем). Postmortem должен быть один на инцидент, чтобы была единая финальная история.
Пример: инцидент «Ошибки при оформлении заказа» связан с сервисами «Payments API» и «PostgreSQL», имеет обновления каждые 15 минут и задачи вроде «Откат деплоя» и «Добавить защиту с повторной попыткой». Позже постмортем фиксирует корневую причину и создаёт долгосрочные задачи.
Уровни критичности и целевые показатели реакции
Когда люди в стрессе, им нужны простые ярлыки, которые означают одно и то же для всех. Определите P1–P4 простыми словами и показывайте определение рядом с полем критичности.
- P1 (Критично): ядро сервиса недоступно или вероятна потеря данных. Много пользователей заблокировано.
- P2 (Высоко): ключевая функция не работает, но есть обход или ограниченная зона поражения.
- P3 (Средне): не срочная проблема, небольшой круг пользователей, минимальное влияние на бизнес.
- P4 (Низко): косметический или незначительный баг, планируется на более поздний срок.
Целевые показатели реакции должны выглядеть как обязательства. Простой базовый набор (подстраивайте под реальность):
| Severity | First response (ack) | First update | Update frequency |
|---|
| P1 | 5 min | 15 min | every 30 min |
| P2 | 15 min | 30 min | every 60 min |
| P3 | 4 hours | 1 business day | daily |
| P4 | 2 business days | 1 week | weekly |
Держите правила эскалации механическими. Если P2 пропускает свою частоту обновлений или влияние растёт, система должна предложить пересмотреть критичность. Чтобы избежать лишних переключений, ограничьте, кто может менять критичность (часто владелец инцидента или командир инцидента), но разрешите любому запросить пересмотр в комментарии.
Короткая матрица воздействия также помогает быстро подобрать критичность. Зафиксируйте её в нескольких обязательных полях: число затронутых пользователей, риск для дохода, безопасность, соответствие требованиям и наличие обходного решения.
Состояния рабочего процесса, которые ведут людей в стресс
Предотвратите наполовину заполнённые инциденты
Требуйте владельца, следующее действие и корневую причину, прежде чем инцидент может продвинуться.
Во время инцидента людям не нужны дополнительные опции. Им нужен небольшой набор состояний, который делает следующий шаг очевидным.
Начните со шагов, которые вы уже выполняете в спокойный день, затем держите список коротким. Если больше 6–7 состояний, команды будут спорить о формулировках вместо того, чтобы чинить проблему.
Практический набор:
- New: оповещение получено, ещё не подтверждено
- Acknowledged: кто-то взял на себя, начат первый ответ
- Investigating: подтверждаем влияние, сужаем вероятную причину
- Mitigating: выполняются действия по снижению влияния
- Monitoring: сервис кажется стабильным, наблюдаем на предмет отката
- Resolved: сервис восстановлен, готово к разбору
Каждому статусу нужны чёткие правила входа и выхода. Например:
- Нельзя перейти в Acknowledged, пока не назначен владелец и не написано следующее действие одним предложением.
- Нельзя перейти в Mitigating, пока не существует как минимум одной конкретной задачи по смягчению (откат, выключение флага, добавление ёмкости).
Используйте переходы, чтобы требовать поля, которые люди забывают. Распространённое правило: нельзя закрыть инцидент без краткого резюме корневой причины и как минимум одного follow-up. Если разрешать «RCA: TBD», оно обычно так и остаётся.
Страница инцидента должна отвечать на три вопроса с первого взгляда: кто владеет этим, какое следующее действие и когда было последнее обновление.
Правила назначения и эскалации
Когда инцидент шумный, самый быстрый способ потерять время — размытая ответственность. Ваше приложение должно делать одного человека явно ответственным, при этом позволяя другим легко помогать.
Простой паттерн, который работает:
- Primary owner: ведёт реакцию, публикует обновления, решает следующие шаги
- Helpers: берут задачи (диагностика, откат, коммуникации) и отчитываются
- Approver: лидер, который может одобрить рискованные действия
Назначение должно быть явным и аудируемым. Отслеживайте, кто назначил владельца, кто принял назначение и каждое последующее изменение. «Принял» важно, потому что назначить того, кто спит или офлайн, не означает реальную ответственность.
Назначение по дежурству или командное назначение обычно зависит от критичности. Для P1/P2 по умолчанию используйте ротацию on-call, чтобы всегда был именованный владелец. Для меньших критичностей подойдёт командное назначение, но всё равно требуйте одного первичного владельца в короткий срок.
Планируйте отпуска и простои в ваших человеческих процессах, а не только в системах. Если назначенный человек помечен как недоступный, маршрутизируйте к второму on-call или лидеру команды. Делайте это автоматически, но видно, чтобы можно было быстро скорректировать.
Эскалация должна срабатывать и по критичности, и по тишине. Полезная отправная точка:
- P1: эскалировать, если нет принятия владения в 5 минут
- P1/P2: эскалировать, если нет обновления в 15–30 минут
- Любая критичность: эскалировать, если состояние «Investigating» длится дольше целевого времени реакции
Таймлайны, обновления и уведомления
Один источник правды для IT
Перенесите координацию инцидентов из прокрутки чата в единый системный источник правды.
Хороший таймлайн — это общая память. Во время инцидента контекст быстро теряется. Если вы фиксируете нужные моменты в одном месте, передачи проще, а постмортем в большинстве случаев уже наполовину готов.
Что должен фиксировать таймлайн
Держите таймлайн однозначным. Не превращайте его в лог чата. Большинство команд опираются на небольшой набор записей: обнаружение, подтверждение, ключевые шаги смягчения, восстановление и закрытие.
Каждая запись должна иметь отметку времени, автора и короткое простое описание. Тот, кто подключился поздно, должен прочитать пять записей и понять, что происходит.
Типы обновлений, которые сохраняют ясность
Разные обновления служат разной аудитории. Полезно, когда записи имеют тип: внутренняя заметка (сырые детали), апдейт для клиента (безопасная формулировка), решение (почему выбран вариант A) и передача (что должен знать следующий участник).
Напоминания должны следовать критичности, а не личным предпочтениям. Если таймер сработал, сначала напомните текущему владельцу, затем эскалируйте при повторном пропуске.
Уведомления должны быть таргетированными и предсказуемыми. Небольшой набор правил обычно достаточен: уведомлять при создании, смене критичности, восстановлении и просроченных обновлениях. Не рассылайте всю компанию при каждом изменении.
Постмортемы, которые приводят к реальным следующим шагам
Поддержка реакции в пути
Позвольте владельцам на дежурстве публиковать обновления и менять статус прямо с телефона.
Постмортем должен выполнять две задачи: простым языком объяснить, что случилось, и сделать так, чтобы такая же ошибка была менее вероятна в будущем.
Держите отчёт коротким и принуждайте к действиям. Практическая структура: резюме, влияние на клиентов, корневая причина, исправления в ходе смягчения и follow-up.
Follow-up — ключевое. Не оставляйте их в абзаце в конце. Превращайте каждый follow-up в задачу с владельцем и сроком выполнения, даже если срок — «в следующем спринте». Так «надо улучшить мониторинг» превращается в «Алекс добавляет алерт по насыщению DB до пятницы».
Теги делают постмортемы полезными позднее. Добавляйте 1–3 темы к каждому инциденту (пробел в мониторинге, релиз, ёмкость, процесс). Спустя месяц вы сможете ответить на базовые вопросы, например, от релизов ли чаще всего происходят P1.
Доказательства должно быть легко прикреплять, но не делать их обязательными. Поддерживайте опциональные поля для скриншотов, фрагментов логов и ссылок на внешние системы (ID тикетов, треды чата, номера дел у вендоров). Держите это лёгким, чтобы люди действительно заполняли.
Пошагово: собрать мини-систему в виде одного внутреннего приложения
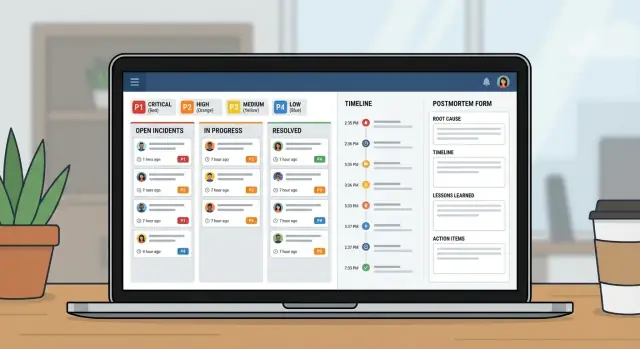
Относитесь к этому как к небольшому продукту, а не к таблице с дополнительными колонками. Хорошее приложение для инцидентов — на самом деле три вида экранов: что происходит сейчас, что делать дальше и чему учиться потом.
Начните с набросков экранов, которые люди будут открывать под давлением:
- Очередь: открытые инциденты с несколькими фильтрами (Open, Needs update, Waiting on vendor, Closed)
- Страница инцидента: критичность, владелец, текущий статус, таймлайн, задачи и последнее обновление
- Страница постмортема: влияние, корневая причина, пункты действий, владельцы
Соберите модель данных и права вместе. Если каждый может редактировать всё, история станет грязной. Частый подход: широкий доступ на чтение для IT, контролируемые изменения состояния/критичности, участники могут добавлять обновления, а постмортем утверждается конкретным владельцем.
Затем добавьте правила рабочего процесса, которые предотвращают наполовину заполнённые инциденты. Обязательные поля должны зависеть от состояния. Можно позволить «New» с только заголовком и сообщившим, но требовать для «Mitigating» краткого описания влияния, а для «Resolved» — резюме корневой причины и как минимум одного follow-up.
Наконец, протестируйте, проиграв 2–3 прошлых инцидента. Один человек — командир инцидента, другой — резолвер. Вы быстро увидите, какие статусы неясны, какие поля пропускают и где нужны лучшие значения по умолчанию.
Распространённые ошибки и как их избежать
Сделайте рабочие процессы управляемыми
Преобразуйте ваши уровни критичности, статусы и обязательные поля в реальные правила рабочего процесса.
Большинство систем для инцидентов терпят неудачу по простым причинам: люди не помнят правила в стрессе, и приложение не захватывает факты, которые нужны позже.
Ошибка 1: Слишком много уровней критичности или статусов
Если у вас шесть уровней критичности и десять статусов, люди будут гадать. Держите 3–4 уровня и статусы, ориентированные на следующее действие.
Ошибка 2: Нет единого владельца
Когда все «наблюдают», никто не ведёт. Требуйте одного именованного владельца перед тем, как инцидент сможет продвинуться, и делайте передачи явными.
Ошибка 3: Таймлайны, которым нельзя доверять
Если «когда что произошло» полагается на историю чата, постмортемы превратятся в споры. Автозаписывайте отметки времени для открытия, подтверждения, смягчения и восстановления, и держите записи короткими.
Также избегайте закрытия с расплывчатыми пометками типа «сетевая проблема». Требуйте одно ясное утверждение корневой причины и как минимум одно конкретное следующее действие.
Чеклист запуска и дальнейшие шаги
Перед развёртыванием по всему IT оргу стресс-тестируйте базовые вещи. Если люди не найдут нужную кнопку за первые две минуты, они вернутся к чатам и таблицам.
Сфокусируйтесь на кратком наборе проверок перед запуском: роли и права, чёткие определения критичности, принудительное наличие владельца, правила напоминаний и путь эскалации, если цели реакции пропускаются.
Пилотируйте с одной командой и несколькими сервисами, которые генерируют частые оповещения. Работайте две недели, затем корректируйте по реальным инцидентам.
Если вы хотите собрать это как единый внутренний инструмент без склеивания таблиц и отдельных приложений, AppMaster (appmaster.io) — один из вариантов. Он позволяет создать модель данных, правила рабочего процесса и интерфейсы веб/мобильных приложений в одном месте, что хорошо подходит для очереди инцидентов, страницы инцидента и трекинга постмортемов.
Вопросы и ответы
Он заменяет разбросанные обновления одним общим источником правды, который быстро отвечает на базовые вопросы: кто владеет инцидентом, что видят пользователи, что уже пробовали и что будет дальше. Это уменьшает потери времени на передачи, противоречивые сообщения и постоянные просьбы «можете кратко рассказать?».
Открывайте инцидент сразу, как только кажется, что есть реальное влияние на клиентов или бизнес, даже если корневая причина пока не ясна. Можно начать с чернового заголовка и пометки «влияние неизвестно», затем уточнять по мере подтверждения тяжести и охвата.
Сделайте минимум структурных полей: понятный заголовок, краткое описание воздействия, затронутые сервисы, время начала, текущий статус, уровень критичности и один владелец. Добавляйте обновления и задачи по ходу, но не полагайтесь только на свободный текст для ключевых фактов.
Используйте 3–4 уровня с простыми определениями, чтобы не было места для споров. Хорошая отправная точка: P1 для отказа ядра или риска потери данных, P2 для серьёзного сбоя с обходными путями или ограниченным фрагментом, P3 для менее критичных проблем и P4 для косметики или мелких багов.
Отмечайте обязательные сроки, которые воспринимаются как обязательства: время до подтверждения (ack), время до первого обновления и частота обновлений. Запускайте напоминания и эскалации, когда частота нарушена — молчание часто оказывается самой большой проблемой в инцидентах.
Ориентируйтесь на примерно шесть статусов: New, Acknowledged, Investigating, Mitigating, Monitoring и Resolved. Каждый статус должен подсказывать следующее действие, а переходы — обеспечивать заполнение полей, которые люди обычно забывают в стрессе (например, владелец перед переходом в Acknowledged).
Требуйте одного первичного владельца, который отвечает за ведение реакции и публикацию обновлений. Отслеживайте явно, кто принял владение, чтобы не перекидывать инцидент «кому-то, кто спит». Делайте передачу ответственности зафиксированным событием, чтобы следующий человек не начинал расследование с нуля.
Фиксируйте только важные моменты: обнаружение, подтверждение, ключевые решения, шаги по смягчению, восстановление и закрытие — с отметкой времени и автором. Не превращайте таймлайн в лог чата; кто подключился поздно должен понять ситуацию, прочитав 5 записей.
Держите постмортем коротким и ориентированным на действия: краткое резюме, влияние на клиентов, корневая причина, что было изменено во время смягчения и назначенные follow-up с владельцами и сроками. Письменная часть важна, но именно назначенные задачи мешают повторению той же ошибки.
Да — если моделировать инциденты, обновления, задачи, сервисы и постмортемы как реальные сущности и внедрять правила рабочего процесса в приложении. AppMaster (appmaster.io) — один из вариантов, который позволяет создать модель данных, экраны веб/мобильных интерфейсов и проверки состояний в одном месте, чтобы процесс не сворачивался обратно в таблицы под давлением.