19 мая 2025 г.·7 мин
pgvector или управляемая векторная база данных для семантического поиска
Сравнение pgvector и управляемой векторной базы данных для семантического поиска: усилия по настройке, вопросы масштабирования, поддержка фильтрации и где это лучше вписывается в типичный стэк приложения.
Какую проблему решает семантический поиск в бизнес-приложении
Семантический поиск помогает пользователям найти правильный ответ, даже если они не используют «правильные» ключевые слова. Вместо точного совпадения слов он сопоставляет смысл. Кто-то, кто пишет «сбросить вход», всё равно должен увидеть статью с заголовком «Смените пароль и войдите снова», потому что намерение одно и то же.
Ключевой поиск ломается в бизнес-приложениях, потому что реальные пользователи непоследовательны. Они используют сокращения, делают опечатки, путают названия продуктов и описывают симптомы вместо официальных терминов. В FAQ, тикетах поддержки, политических документах и руководствах по онбордингу одна и та же проблема встречается в разных формулировках. Поисковый движок по ключевым словам часто возвращает ничего полезного или длинный список, который заставляет людей кликать в пустую.
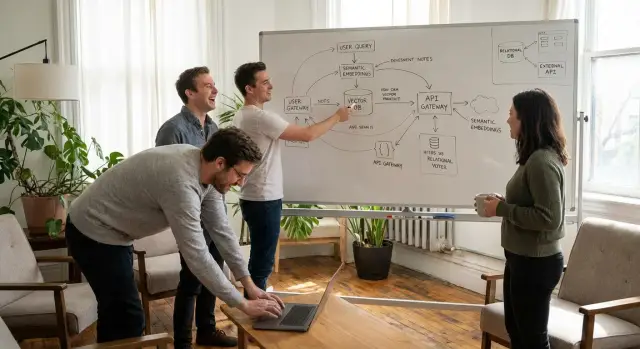
Эмбеддинги — обычный строительный блок. Ваше приложение превращает каждый документ (статью, тикет, заметку о продукте) в вектор — длинный список чисел, который представляет смысл. Когда пользователь задаёт вопрос, вы также эмбеддите запрос и ищете ближайшие векторы. «Векторная база данных» — это просто место, где вы храните эти векторы и способ их быстрого поиска.
В типичном бизнес-стеке семантический поиск затрагивает четыре области: хранилище контента (база знаний, документация, система тикетов), pipeline эмбеддингов (импорты и обновления при изменении контента), опыт запроса (поисковая строка, предлагаемые ответы, помощь агенту) и горнтейлы (права доступа и метаданные вроде команды, клиента, тарифа и региона).
Для большинства команд «достаточно хорошо» важнее «идеально». Практическая цель — релевантность с первого раза, ответы меньше чем за секунду и предсказуемые затраты по мере роста контента. Эта цель важнее, чем дискуссия о инструментах.
Два распространённых варианта: pgvector и управляемые векторные базы
Большинство команд в итоге выбирают между двумя паттернами для семантического поиска: держать всё внутри PostgreSQL с pgvector или добавить отдельную управляемую векторную базу рядом с основной БД. Правильный выбор зависит не столько от «что лучше», сколько от того, где вы хотите концентрировать сложность.
pgvector — это расширение PostgreSQL, которое добавляет тип данных вектор и индексы, чтобы вы могли хранить эмбеддинги в обычной таблице и выполнять поиск по похожести через SQL. На практике в вашей таблице документов может быть текст, метаданные (customer_id, status, visibility) и колонка с эмбеддингом. Поиск становится: «эмбеддить запрос, затем вернуть строки, чьи эмбеддинги ближе всего».
Управляемая векторная база — это хостинговый сервис, созданный в первую очередь для эмбеддингов. Обычно он даёт API для вставки векторов и поиска по похожести, а также операционные функции, которые вам пришлось бы реализовать самим.
Оба варианта выполняют ту же основную задачу: хранить эмбеддинги вместе с ID и метаданными, находить ближайших соседей для запроса и возвращать топ-по совпадению, чтобы приложение могло показать релевантные элементы.
Ключевое отличие — система записи. Даже если вы используете управляемую векторную базу, вы почти всегда оставляете PostgreSQL для бизнес-данных: аккаунтов, прав, биллинга, состояния рабочих процессов и аудита. Векторное хранилище становится слоем извлечения, а не местом, где запускается всё приложение.
Обычная архитектура выглядит так: сохранять авторитетные данные в Postgres, хранить эмбеддинги либо в Postgres (pgvector), либо в сервисе векторов, запускать поиск по похожести, чтобы получить совпадающие ID, а затем подтягивать полные строки из Postgres.
Если вы строите приложения на платформе вроде AppMaster, PostgreSQL уже естественно подходит для структурированных данных и прав доступа. Вопрос в том, должен ли поиск эмбеддингов жить там же или в специализированном сервисе, пока Postgres остаётся источником правды.
Настройка: что действительно нужно сделать
Команды часто выбирают по возможностям, а затем удивляются повседневной работе. Реальное решение — это выбор места концентрации сложности: в вашем текущем Postgres или в отдельной службе.
С pgvector вы добавляете векторный поиск в базу данных, которую вы уже эксплуатируете. Настройка обычно проста, но это всё равно работа с базой данных, а не только кодом приложения.
Типичная настройка pgvector включает: включение расширения, добавление колонки с эмбеддингом, создание индекса, соответствующего вашему шаблону запросов (и последующая его тонкая настройка), решение как обновлять эмбеддинги при изменении контента и написание запросов по похожести с учётом обычных фильтров.
С управляемой векторной базой вы создаёте новую систему рядом с основной БД. Это может означать меньше SQL, но больше интеграционной «склейки».
Типичная настройка управляемого сервиса включает: создание индекса (размерность и метрика расстояния), подключение API-ключей в секреты, построение задачи по загрузке эмбеддингов и метаданных, поддержание стабильного соответствия ID между записями приложения и векторными записями и настройку сетевого доступа, чтобы только бэкенд мог делать запросы.
CI/CD и миграции тоже отличаются. pgvector органично вписывается в существующие миграции и процесс ревью. Управляемые сервисы переносят изменения в код и админ-настройки, поэтому нужна понятная процедура для конфигурационных изменений и переиндексации.
Ответственность обычно следует за выбором. pgvector тяготеет к командам разработки приложения и тем, кто владеет Postgres (иногда DBA). Управляемый сервис чаще находится в ведении платформенной команды, а разработчики приложения занимаются инжестом и логикой запросов. Поэтому решение часто связано с организацией команды, а не только с технологией.
Фильтрация и права: ключевая деталь
Семантический поиск полезен только если он уважает, что пользователь может видеть. В реальном бизнес-приложении рядом с эмбеддингом лежит метадата: org_id, user_id, role, status (open, closed), visibility (public, internal, private). Если слой поиска не умеет чисто фильтровать по этим данным, вы получите запутанные результаты или, что хуже, утечки данных.
Самое существенное практическое отличие — фильтрация до или после векторного поиска. Фильтрация после кажется простой (поискать всё, потом отбросить запрещённые строки), но она проваливается по двум причинам. Во-первых, лучшие совпадения могут быть удалены, и останутся худшие результаты. Во-вторых, повышается риск безопасности, если какая-то часть пайплайна логирует, кэширует или показывает нефильтрованные результаты.
С pgvector векторы живут в PostgreSQL рядом с метаданными, поэтому вы можете применить права в том же SQL-запросе и позволить Postgres их принудительно соблюдать.
PostgreSQL: права и джоины — нативны
Если ваше приложение уже использует Postgres, pgvector часто выигрывает по простоте: поиск становится «ещё одним запросом». Вы можете делать джоины по тикетам, клиентам и членствам, и использовать Row Level Security, чтобы база данных сама блокировала неавторизованные строки.
Обычный паттерн — сначала сузить набор кандидатов фильтрами по org и status, затем запустить поиск по похожести на оставшемся наборе, при желании смешивая с точным поиском по ключевым словам для идентификаторов.
Управляемая векторная БД: фильтры разнятся, ответственность за права — обычно на вас
Большинство управляемых векторных баз поддерживают фильтры по метаданным, но язык фильтров может быть ограничен, и джоины там отсутствуют. Обычно вы денормализуете метаданные в каждую векторную запись и повторно реализуете проверки прав в приложении.
Для гибридного поиска в бизнес-приложениях обычно нужно, чтобы всё это работало вместе: жёсткие фильтры (org, role, status, visibility), точный поиск по ключевым словам (например номер счёта), векторная похожесть (по смыслу) и правила ранжирования (повысить недавние или открытые элементы).
Пример: портал поддержки, построенный в AppMaster, может хранить тикеты и права в PostgreSQL, что упрощает соблюдение условия «агент видит только свою организацию», при этом получая семантические совпадения по сводкам тикетов и ответам.
Качество поиска и основы производительности
Построить API поиска
Создайте безопасные бэкенд-эндпоинты и интерфейс поиска без старта с нуля.
Качество поиска — это смесь релевантности (полезны ли результаты?) и скорости (кажется ли поиск мгновенным?). И с pgvector, и с управляемой векторной БД вы обычно жертвуете немного релевантности в пользу меньшей задержки, используя приближённый поиск. Такой компромисс часто приемлем для бизнес-приложений, если вы измеряете его на реальных запросах.
В общих чертах вы настраиваете три вещи: модель эмбеддингов (как выглядит «смысл»), настройки индекса (насколько тщательно движок ищет) и слой ранжирования (как упорядочены результаты после применения фильтров, свежести или популярности).
В PostgreSQL с pgvector обычно выбирают индекс вроде IVFFlat или HNSW. IVFFlat быстрее и легче по время построения, но нужно настраивать количество «листов» и обычно полезно иметь достаточный объём данных, чтобы он проявил себя. HNSW часто даёт лучшую полноту (recall) при низкой задержке, но может требовать больше памяти и дольше строится. Управляемые системы предлагают похожие варианты, просто под другими именами и с другими дефолтами.
Несколько тактик важнее, чем думают: кешируйте популярные запросы, батчьте работу там, где можно (например заранее подгружайте следующую страницу) и подумайте о двухэтапном потоке: быстрый векторный поиск, затем повторная ранжировка топ-20–100 с бизнес-сигналами вроде свежести или уровня клиента. Также следите за сетевыми задержками: если поиск в отдельном сервисе, каждый запрос — это дополнительный раундтріп.
Чтобы измерять качество, начните с малого и конкретного. Соберите 20–50 реальных пользовательских вопросов, определите, что такое «хороший» ответ, и отслеживайте показатели: попадание в топ‑3 и топ‑10, медианную и p95 латентность, долю запросов без хорошего результата и насколько падает качество после применения прав и фильтров.
Здесь выбор перестаёт быть теоретическим. Лучший вариант — тот, который достигает вашей цели по релевантности при приемлемой задержке и с настройкой, которую вы можете поддерживать.
Вопросы масштабирования и эксплуатационные задачи
Многие команды начинают с pgvector, потому что это держит всё в одном месте: бизнес-данные и эмбеддинги. Для многих бизнес-приложений один узел PostgreSQL вполне достаточен, особенно если у вас десятки или сотни тысяч векторов и поиск не является главным источником трафика.
Ограничения обычно появляются, когда семантический поиск становится ключевым действием пользователя (на большинстве страниц, в каждом тикете, в чате) или когда вы храните миллионы векторов и требуете низких задержек в пиковые часы.
Признаки того, что один Postgres начинает напрягаться: p95 латентность поиска растёт во время обычной записи, приходится выбирать между быстрыми индексами и приемлемой скоростью записи, задачи обслуживания превращаются в «запланируйте на ночь» и требуется разное масштабирование для поиска и остальной БД.
С pgvector масштабирование обычно означает добавление read‑реплик для нагрузки запросов, партиционирование таблиц, тонкую настройку индексов и планирование работ по сборке индексов и росту хранения. Это выполнимо, но превращается в постоянную задачу. Также предстоит решить, хранить ли эмбеддинги в той же таблице, что и бизнес-данные, или вынести их, чтобы уменьшить «раздувание» таблиц и блокировки.
Управляемые векторные базы перекладывают это на вендора. Они часто предлагают независимое масштабирование compute и storage, встроенное шардингование и более простую доступность. Компромисс — эксплуатация двух систем (Postgres + векторное хранилище) и поддержание синхронизации метаданных и прав.
Затраты обычно удивляют команды больше, чем производительность. Главные драйверы расходов: хранение (векторы и индексы быстро растут), пиковый объём запросов (часто задаёт счёт), частота обновлений (пере-эмбеддинги и upsert’ы) и перенос данных (дополнительные вызовы, когда приложению нужна жёсткая фильтрация).
Если выбираете между pgvector и управляемым сервисом, решите, какую боль вы предпочитаете: глубокая настройка и планирование ёмкости Postgres или платёж за более простое масштабирование при дополнительной зависимости.
Вопросы безопасности, соответствия и надёжности
Выпустить веб и мобильные приложения
Соберите бэкенд, веб-интерфейс и нативные мобильные приложения вокруг функции поиска.
Детали безопасности часто решают быстрее, чем тесты производительности. Спросите заранее, где будут храниться данные, кто может их видеть и что происходит при сбое.
Начните с местоположения данных и доступа. Эмбеддинги всё ещё могут раскрывать смысл, и многие команды также хранят сырые фрагменты текста для подсветки. Чётко определите, какая система будет держать сырой текст (тикеты, заметки, документы), а где будут только эмбеддинги. Также решите, кто внутри компании может напрямую запрашивать хранилище и нужна ли строгая разделённость между продакшеном и аналитикой.
Контролы, которые стоит подтвердить до начала
Спросите эти вопросы для любого варианта:
- Как шифруются данные в покое и в пути, и можно ли управлять собственными ключами?
- Каков план резервного копирования, как часто тестируют восстановление и какие цели по времени восстановления вам нужны?
- Есть ли аудит-логи для чтения и записи, и можно ли настроить оповещения на необычный объём запросов?
- Как обеспечивается мультиарендность: отдельные базы данных, отдельные схемы или правила на уровне строк?
- Какова политика хранения удалённого контента, включая эмбеддинги и кэши?
Разделение мультиарендности — то, на чём спотыкаются многие. Если один клиент никогда не должен влиять на другого, нужна строгая скопированность арендатора в каждом запросе. В PostgreSQL это можно гарантировать с помощью Row Level Security и аккуратных паттернов запросов. В управляемой векторной базе обычно полагаются на неймспейсы или коллекции плюс логику приложения.
Надёжность и режимы отказа
Планируйте простои поиска. Если векторное хранилище упало, что увидят пользователи? Безопасный дефолт — падать обратно на поиск по ключевым словам или показывать только последние элементы, а не ломать страницу.
Пример: в портале поддержки, построенном с AppMaster, вы можете хранить тикеты в PostgreSQL и считать семантический поиск опциональной фичей. Если эмбеддинги не загружаются, портал всё ещё показывает списки тикетов и поддерживает точечный поиск по ключевым словам, пока вы восстанавливаете векторный сервис.
Пошагово: как выбрать с минимальным риском пилота
Держать векторы актуальными
Пере-эмбеддьте при публикации, редактировании или удалении с помощью drag-and-drop бизнес-логики.
Самый безопасный путь — запустить маленький пилот, который похож на ваше реальное приложение, а не на демонстрационную тетрадку.
Начните с чёткого описания того, что вы ищете и что обязательно должно фильтроваться. «Поиск по нашей документации» — слишком абстрактно. «Поиск по статьям помощи, ответам в тикетах и PDF-manual’ам, но показывать только то, что пользователь может увидеть» — реальное требование. Права доступа, ID арендатора, язык, область продукта и фильтр «только опубликованный контент» часто решают исход.
Затем выберите модель эмбеддингов и план обновления. Решите, что эмбеддить (весь документ, чанки или и то, и другое) и как часто обновлять (на каждое правку, раз в ночь или при публикации). Если контент часто меняется, измерьте, насколько болезненным будет пере-эмбеддинг, а не только насколько быстры запросы.
Далее постройте тонкий поисковый API в бэкенде. Держите его простым: один эндпоинт, принимающий запрос и поля фильтров, возвращающий топ‑результаты и логирующий происходящее. Если вы строите на AppMaster, вы можете реализовать инжест и поток обновлений как backend‑сервис и Business Process, который вызывает провайдера эмбеддингов, пишет векторы и метаданные и соблюдает правила доступа.
Проведите двухнедельный пилот с реальными пользователями и задачами. Используйте набор из нескольких типичных вопросов, отслеживайте «найдена ли нужная ответ» и время до первого полезного результата, еженедельно разбирайте плохие результаты, следите за объёмом пере-эмбеддинга и нагрузкой запросов, а также тестируйте сценарии отказа, такие как отсутствие метаданных или устаревшие векторы.
В конце примите решение на основе данных. Оставьте pgvector, если он обеспечивает качество и фильтрацию при приемлемой операционной нагрузке. Перейдите на управляемый сервис, если масштабирование и надёжность становятся главным фактором. Или используйте гибрид: PostgreSQL для метаданных и прав, векторное хранилище для извлечения, если это лучше подходит для вашего стека.
Распространённые ошибки команд
Большинство ошибок проявляются после успешного демо. Быстрый proof‑of‑concept может выглядеть отлично, а затем развалиться, когда вы добавите реальных пользователей, данные и правила.
Частые проблемы, которые приводят к переработке:
- Предположение, что векторы сами по себе решают контроль доступа. Поиск по похожести не знает, что пользователь может видеть. Если в вашем приложении есть роли, команды, арендаторы или приватные заметки, всё равно нужны строгие тесты и фильтры, чтобы поиск не просочил закрытый контент.
- Доверие демо «на глаз». Пара отобранных запросов — не оценка. Без небольшой размеченной выборки вопросов и ожидаемых ответов трудно отлавливать регрессии при изменении чанкинга, эмбеддингов или индексов.
- Эмбеддинг целого документа одним вектором. Большие страницы, тикеты и PDF обычно требуют чанкинга. Без чанков результаты получаются размытыми. Без версионности вы не поймёте, какой эмбеддинг соответствует какой ревизии.
- Игнорирование обновлений и удалений. В реальных приложениях контент редактируют и удаляют. Если вы не пере-эмбеддите при изменении и не убираете векторы при удалении, вы будете отдавать устаревшие совпадения, указывающие на отсутствующий или старый текст.
- Переточная тонкая настройка производительности до проработки UX. Команды тратят дни на настройки индексов, пропуская базовые вещи: фильтры по метаданным, хорошие сниппеты и fallback на точечный поиск, когда запрос очень точный.
Простой тест «после запуска» ловит эти проблемы рано: добавьте новое правило прав доступа, обновите 20 элементов, удалите 5, затем снова запустите те же 10 тестовых вопросов. Если вы строите на платформе вроде AppMaster, запланируйте эти проверки вместе с бизнес‑логикой и моделью данных, а не как «послефактум».
Пример: семантический поиск в портале поддержки
Быстрый прототип семантического поиска
Постройте реальный пилот семантического поиска с данными и правами доступа в PostgreSQL в AppMaster.
Средняя SaaS‑компания ведёт портал поддержки с двумя типами контента: тикеты клиентов и статьи центра помощи. Они хотят поисковую строку, которая понимает смысл, чтобы при вводе «не могу войти после смены телефона» показывались правильные статьи и похожие прошлые тикеты.
Незыблемые требования практичны: каждый клиент должен видеть только свои тикеты, агенты должны уметь фильтровать по статусу (open, pending, solved), и результаты должны казаться мгновенными, потому что подсказки появляются по мере ввода.
Вариант A: pgvector внутри того же PostgreSQL
Если портал уже хранит тикеты и статьи в PostgreSQL (обычно при использовании стека с Postgres, например AppMaster), добавление pgvector может быть чистым первым шагом. Вы держите эмбеддинги, метаданные и права в одном месте, поэтому «только тикеты customer_123» — это обычный WHERE.
Это хорошо работает, когда набор данных невелик (десятки или сотни тысяч записей), команда умеет настраивать индексы и планы запросов Postgres, и вы хотите меньше компонентов и более простую модель контроля доступа.
Компромисс в том, что векторный поиск может конкурировать с транзакционной нагрузкой. По мере роста, возможно, потребуется дополнительная мощность, аккуратная настройка индексов или даже отдельный экземпляр Postgres, чтобы защитить запись тикетов и SLA.
Вариант B: управляемая векторная БД для эмбеддингов, PostgreSQL для метаданных
С управляемой векторной базой вы обычно храните эмбеддинги и ID там, а «истину» (статус тикета, customer_id, права) — в PostgreSQL. На практике команды либо сначала фильтруют в Postgres и затем ищут среди допустимых ID, либо сначала ищут и затем повторно проверяют права перед показом результатов.
Этот вариант часто выигрывает, когда рост непредсказуем или команда не хочет тратить время на поддержание производительности. Но поток прав требует аккуратности, иначе есть риск утечек данных между клиентами.
Практический вывод: начните с pgvector, если вам сейчас нужны строгие фильтры и простая эксплуатация, и планируйте переход на управляемую векторную БД, если вы ожидаете быстрый рост, высокий объём запросов или не можете позволить поиску замедлять основную БД.
Быстрый чеклист и следующие шаги
Если вы в тупике, перестаньте спорить о функциях и выпишите, что ваше приложение должно делать в первый день. Реальные требования обычно проявляются в небольшом пилоте с реальными пользователями и данными.
Эти вопросы решают чаще, чем бенчмарки:
- Какие фильтры неприемлемы для компромисса (tenant, role, region, status, time range)?
- Какого размера будет индекс через 6–12 месяцев (элементы и эмбеддинги)?
- Какая задержка кажется мгновенной для ваших пользователей, включая пиковые нагрузки?
- Кто отвечает за бюджет и on‑call?
- Где должен храниться источник правды: в таблицах PostgreSQL или во внешнем индексе?
Также планируйте изменения. Эмбеддинги — не «поставил и забыл». Тексты меняются, модели меняются, релевантность дрейфует, пока кто‑то не пожалуется. Решите заранее, как вы будете обрабатывать обновления, как обнаруживать дрейф и что мониторить (латентность запросов, процент ошибок, полнота на небольшой тестовой выборке и количество поисков без результатов).
Если хотите быстро продвинуться с полным бизнес‑приложением вокруг поиска, AppMaster (appmaster.io) может подойти: платформа даёт моделирование данных в PostgreSQL, бэкенд‑логику и UI для веба и мобильных устройств в одном no-code рабочем процессе, и вы можете добавить семантический поиск как итерацию после того, как базовая логика и права готовы.
Вопросы и ответы
Семантический поиск возвращает полезные результаты даже когда слова пользователя не совпадают точно с текстом документа. Он особенно полезен, когда люди делают опечатки, используют сокращения или описывают симптомы вместо официальных терминов — как это часто бывает в порталах поддержки, внутренних инструментах и базах знаний.
Используйте pgvector, когда вы хотите меньше движущихся частей, удобную фильтрацию через SQL и у вас пока скромные объёмы данных и трафика. Это часто самый быстрый путь к безопасному, с учётом прав доступа, поиску, потому что эмбеддинги и метаданные живут в тех же PostgreSQL-запросах, которым вы уже доверяете.
Рассмотрите управляемую векторную базу, если вы ожидаете быстрый рост количества векторов или объёма запросов, или если хотите, чтобы масштабирование и доступность поиска обслуживались вне основной базы данных. Вы платите за более простую масштабируемость, но платите интеграционными усилиями и внимательным контролем прав доступа.
Эмбеддинг — это процесс превращения текста в числовой вектор, который представляет смысл. Векторная база данных (или pgvector в PostgreSQL) хранит эти векторы и быстро находит те, которые ближе всего к вектору запроса пользователя — так вы получаете «похожие по смыслу» результаты.
Фильтрация после векторного поиска часто удаляет лучшие совпадения и может оставить пользователя с худшими результатами или пустой страницей. Кроме того, это повышает риск утечек через логи, кэш или отладку, поэтому безопаснее применять фильтры по арендаторам и ролям как можно раньше.
С pgvector вы можете применять права доступа, делать соединения и использовать Row Level Security в том же SQL-запросе, который выполняет поиск по похожести. Это упрощает гарантию «никогда не показывать запрещённые строки», потому что PostgreSQL контролирует доступ там, где хранятся данные.
Большинство управляемых векторных баз поддерживают фильтры по метаданным, но обычно они не умеют делать джоины, а язык фильтров может быть ограничен. Часто приходится денормализовать метаданные, связанные с правами, в каждую векторную запись и делать финальную проверку авторизации в приложении.
Разбиение на чанки означает деление больших документов на более мелкие части перед эмбеддингом, что обычно повышает точность, потому что каждый вектор представляет более сфокусированную идею. Эмбеддинги целых документов подходят для коротких элементов, но длинные страницы, тикеты и PDF часто становятся размытыми без чанкинга и учёта версий.
Планируйте обновления с самого начала: пере-эмбедьте при публикации или редактировании для часто меняющегося контента и всегда удаляйте векторы, когда исходная запись удалена. Если этого не сделать, вы будете выдавать устаревшие результаты, указывающие на отсутствующие или неактуальные тексты.
Практический пилот использует реальные запросы и строгие фильтры, измеряет релевантность и латентность, и тестирует отказоустойчивость, например пропущенные метаданные или устаревшие векторы. Выберите вариант, который стабильно возвращает хорошие верхние результаты в рамках ваших правил прав доступа и с затратами и операционной нагрузкой, которые вы готовы поддерживать.