22 авг. 2025 г.·5 мин
Отладка интеграций вебхуков: подписи, повторы, воспроизведение, журналы событий
Научитесь отлаживать интеграции вебхуков: стандартизируйте подписи, безопасно обрабатывайте повторы, включайте воспроизведение и храните легко ищущиеся журналы событий.
Почему интеграции вебхуков превращаются в чёрный ящик
Вебхук — это просто одно приложение, которое вызывает ваше приложение при каком‑то событии. Платёжный провайдер сообщает «платёж успешен», форма говорит «новая отправка», CRM сообщает «сделка обновлена». Всё выглядит просто, пока что‑то не ломается и вы не понимаете, куда смотреть: нет экрана, нет очевидной истории и нет безопасного способа воспроизвести произошедшее.
Именно поэтому проблемы с вебхуками так раздражают. Запрос приходит (или нет). Ваша система его обрабатывает (или падает). Первый сигнал часто — расплывчатый тикет вроде «клиенты не могут оформить заказ» или «статус не обновился». Если провайдер делает повторы, вы можете получить дубликаты. Если он меняет поле в полезной нагрузке, ваш парсер может сломаться только для некоторых аккаунтов.
Типичные симптомы:
- «Отсутствующие» события, когда непонятно — не прислали или не обработали
- Дубликаты доставок, которые создают побочные эффекты по дважды (два счёта, два письма, два изменения статуса)
- Изменения полезной нагрузки (новые поля, отсутствующие поля, неверные типы), приводящие к ошибкам иногда
- Проверки подписи, которые проходят в одной среде и падают в другой
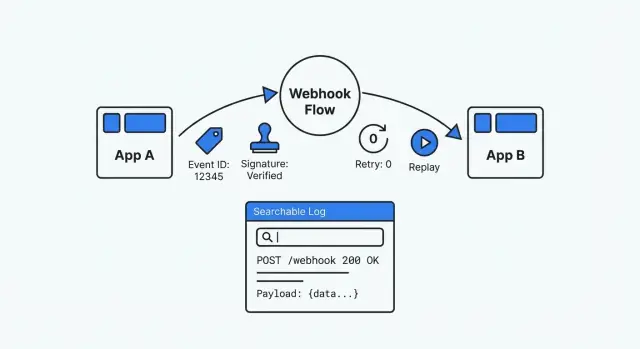
Отлаживаемая настройка вебхуков — противоположность догадкам. Она отслеживаема (можно найти каждую доставку и то, что с ней сделали), воспроизводима (можно безопасно проиграть прошлое событие) и проверяема (можно доказать подлинность и результат обработки). Когда кто‑то спрашивает «что случилось с этим событием?», вы должны ответить с доказательствами за несколько минут.
Если вы строите приложения на платформе вроде AppMaster, такой подход особенно важен. Визуальная логика быстро меняется, но вам всё равно нужна ясная история событий и безопасное воспроизведение, чтобы внешние системы не превращались в чёрный ящик.
Минимальные данные, необходимые для наблюдаемости вебхуков
Под давлением вы всегда должны иметь одни и те же базовые вещи: запись, которой можно доверять, искать и воспроизводить. Без этого каждый вебхук — отдельная загадка.
Определите, что означает одно «событие» вебхука в вашей системе. Относитесь к нему как к чеку: один входящий запрос = одно сохранённое событие, даже если обработка произойдёт позже.
Минимум, что следует сохранять:
- Event ID: используйте ID провайдера, если он есть; иначе генерируйте свой.
- Доверенные данные приёма: когда вы получили запрос и кто его послал (имя провайдера, endpoint, IP если храните). Храните
received_at отдельно от временных меток внутри полезной нагрузки.
- Статус обработки и причина: используйте небольшой набор состояний (received, verified, handled, failed) и храните короткую причину ошибки.
- Необработанный запрос и распарсенное представление: сохраняйте raw body и заголовки точно как пришли (для аудитов и проверок подписи), плюс распарсенное JSON‑представление для поиска и поддержки.
- Ключи корреляции: одно‑два поля, по которым можно искать (order_id, invoice_id, user_id, ticket_id).
Например: провайдер платежей отправляет payment_succeeded, но у вашего клиента всё ещё отображается неоплачено. Если журнал событий содержит raw request, вы сможете подтвердить подпись и увидеть точную сумму и валюту. Если там также есть invoice_id, поддержка найдёт событие по счёту, увидит, что оно в «failed», и даст инжинирингу ясную причину ошибки.
В AppMaster один практичный подход — таблица «WebhookEvent» в Data Designer и Business Process, обновляющий статус по мере завершения шагов. Инструмент — не суть; последовательная запись — суть.
Стандартизируйте структуру события, чтобы логи были читаемыми
Если каждый провайдер шлёт разные формы полезной нагрузки, ваши логи всегда будут выглядеть беспорядочно. Стабильный «конверт» события ускоряет отладку: вы можете смотреть одни и те же поля, даже когда данные меняются.
Полезный конверт обычно включает:
id (уникальный id события)type (понятное название события, например invoice.paid)created_at (когда событие произошло, не когда вы его получили)data (бизнес‑полезная нагрузка)version (например v1)
Вот простой пример, который можно логировать и сохранять как есть:
{
"id": "evt_01H...",
"type": "payment.failed",
"created_at": "2026-01-25T10:12:30Z",
"version": "v1",
"correlation": {"order_id": "A-10492", "customer_id": "C-883"},
"data": {"amount": 4990, "currency": "USD", "reason": "insufficient_funds"}
}
Выберите один стиль именования (snake_case или camelCase) и придерживайтесь его. Строго соблюдайте типы: не делайте amount строкой иногда и числом иногда.
Версионирование — ваша страховка. Когда нужно изменить поля, опубликуйте v2, оставив v1 рабочим на время. Это предотвращает инциденты поддержки и облегчает отладку при обновлениях.
Проверка подписи: последовательная и тестируемая
Подписи защищают ваш endpoint от несанкционированного доступа. Без проверки любой, кто узнал URL, может прислать фейковые события, а злоумышленники — попытаться подделать запросы.
Наиболее распространённый паттерн — HMAC‑подпись с общим секретом. Отправитель подписывает raw body запроса (лучше всего) или канонический строковый вид. Вы пересчитываете HMAC и сравниваете. Многие провайдеры включают временную метку в то, что подписывается, чтобы предотвратить позднее воспроизведение захваченных запросов.
Рутина проверки должна быть скучной и предсказуемой:
- Читайте raw body точно как пришёл (до парсинга JSON).
- Пересчитайте подпись по алгоритму провайдера и вашему секрету.
- Сравнивайте с использованием функции постоянного времени.
- Отклоняйте старые метки времени (короткое окно, например несколько минут).
- Отрабатывайте по принципу «fail closed»: если чего‑то не хватает или что‑то некорректно, считайте запрос недействительным.
Сделайте проверку тестируемой. Вынесите её в небольшую функцию и напишите тесты с известными корректными и некорректными примерами. Частая ошибка — подписывать уже распарсенный JSON вместо raw байтов.
Планируйте ротацию секретов с первого дня. Поддерживайте два активных секрета во время перехода: пробуйте новый сначала, затем откат к предыдущему.
Когда проверка не проходит, логируйте достаточно данных для отладки, но не раскрывайте секреты: имя провайдера, временную метку (и была ли она слишком старая), версию подписи, request/correlation ID и короткий хеш raw body (не саму body).
Повторы и идемпотентность без дублирующих побочных эффектов
Обрабатывайте повторы без дубликатов
Дедупликация по event ID — не давайте повторным попыткам создавать двойные счета, письма или обновления.
Повторы — нормальная часть работы. Провайдеры повторяют при тайм‑аутах, сетевых сбоях или 5xx ответах. Даже если ваша система выполнила работу, провайдер мог не получить ваш ответ вовремя, поэтому одно и то же событие может прийти повторно.
Решите заранее, какие ответы означают «повторять», а какие — «останавливать». Многие команды используют такие правила:
- 2xx: принято, прекращать повторы
- 4xx: проблема конфигурации или запроса, обычно прекращать повторы
- 408/429/5xx: временная ошибка или ограничение по скорости, повторять
Идемпотентность означает, что вы можете безопасно обработать то же событие несколько раз без повторения побочных эффектов (двойная оплата, дубли заказов, отправка двух писем). Рассматривайте вебхуки как доставку «по крайней мере один раз».
Практичный паттерн — сохранять уникальный ID входящего события с результатом обработки. При повторной доставке:
- Если ранее было успешно, верните 2xx и не делайте ничего.
- Если ранее упало, повторите внутреннюю обработку (или верните статус, допускающий повтор).
- Если оно в процессе, избегайте параллельной работы и верните короткий ответ «accepted».
Для внутренних повтов используйте экспоненциальную паузу с ограничением по числу попыток. После достижения лимита переводите событие в состояние «needs review» с последней ошибкой. В AppMaster это чисто ложится на небольшую таблицу для event ID и статусов, плюс Business Process, который планирует повторы и маршрутизирует повторяющиеся ошибки.
Инструменты воспроизведения, которые помогают поддержке быстро исправлять проблемы
Повторы — автоматические. Воспроизведение — намеренное.
Инструмент воспроизведения превращает «мы думаем, что отправили» в повторный тест с точно той же полезной нагрузкой. Он безопасен только когда выполняются два условия: идемпотентность и аудит‑трек. Идемпотентность предотвращает двойное списание, двойную отгрузку или двойную рассылку. Аудит‑трек показывает, что воспроизведено, кем и что произошло.
Воспроизведение одного события vs воспроизведение по диапазону времени
Воспроизведение одного события — стандартный кейс поддержки: один клиент, одно упавшее событие, повторная доставка после исправления. Воспроизведение по диапазону времени нужно при инцидентах: у провайдера был сбой в окне времени, и нужно повторно отправить всё, что упало.
Держите отбор простым: фильтруйте по типу события, диапазону времени и статусу (failed, timed out или delivered but unacknowledged), затем воспроизводите одно событие или пакет.
Ограничения, которые предотвращают инциденты
Воспроизведение должно быть мощным, но не опасным. Несколько защит помогают:
- Ролевой доступ
- Лимиты скорости на назначение
- Обязательная заметка с причиной, сохраняемая в аудите
- Опциональное одобрение для больших пакетных воспроизведений
- Режим dry‑run, который проверяет без отправки
После воспроизведения показывайте результат рядом с оригинальным событием: успешно, всё ещё падает (с последней ошибкой) или проигнорировано (обнаружен дубликат через идемпотентность).
Журналы событий, полезные при инцидентах
Развернуть или экспортировать исходный код
Разверните в своём облаке или экспортируйте настоящий исходный код, когда нужно полное управление.
Когда вебхук ломается во время инцидента, ответы нужны за минуты. Хороший лог рассказывает понятную историю: что пришло, что вы с этим сделали и где это остановилось.
Сохраняйте raw request точно как пришёл: временная метка, путь, метод, заголовки и raw body. Эта необработанная полезная нагрузка — ваша исходная правда, когда вендоры меняют поля или парсер неверно читает данные. Маскируйте чувствительные значения перед сохранением (authorization headers, токены и любые персональные или платёжные данные, которые вам не нужны).
Один raw‑блок недостаточен. Также храните распарсенное, searchable представление: тип события, внешний event ID, идентификаторы клиента/аккаунта, связанные object ID (invoice_id, order_id) и ваш внутренний correlation ID. Это позволяет поддержке найти «все события для клиента 8142», не открывая каждый payload.
Во время обработки ведите короткую временную шкалу шагов с единообразными формулировками, например: «validated signature», «mapped fields», «checked idempotency», «updated records», «queued follow-ups».
Удержание данных важно. Храните историю, достаточную для реальных задержек и споров, но не собирайте всё подряд навсегда. Рассмотрите вариант сначала удалять или анонимизировать raw payload, а затем сохранять лёгкие метаданные дольше.
Пошагово: как построить отлаживаемый конвейер вебхуков
Настройте оповещения о всплесках ошибок вебхуков
Отправляйте оповещения в Telegram или по email, когда сбои вебхуков растут или события застряли в failed.
Постройте приемник как небольшой конвейер с понятными контрольными точками. Каждый запрос становится сохранённым событием, каждый запуск обработки — попыткой, а каждая ошибка — объектом поиска.
Конвейер приёма
Относитесь к HTTP‑endpoint как к приёмнику только. Делайте минимум работы сразу, затем передавайте обработку воркеру, чтобы тайм‑ау��ты не превращались в загадку.
- Снимите заголовки, raw body, временную метку приёма и провайдера.
- Проверьте подпись (или сохраните явный статус «failed verification»).
- Ста��вьте задачу на обработку, используя устойчивый event ID как ключ.
- Обрабатывайте в воркере с проверками идемпотентности и бизнес‑действиями.
- Запишите итоговый результат (success/failure) и полезное сообщение об ошибке.
На практике вам понадобятся две основные записи: одна строка на событие вебхука и одна строка на попытку обработки.
Хорошая модель события включает: event_id, provider, received_at, signature_status, payload_hash, payload_json (или raw payload), current_status, last_error, next_retry_at. Записи попыток могут хранить: attempt_number, started_at, finished_at, http_status (если применимо), error_code, error_text.
Как только данные есть, добавьте небольшую админ‑страницу, чтобы поддержка могла искать по event ID, customer ID или диапазону времени и фильтровать по статусу. Сделайте её скучной и быстрой.
Настройте алерты по шаблонам, а не по единичным ошибкам. Например: «провайдер упал 10 раз за 5 минут» или «событие застряло в failed».
Ожидания от отправителя
Если вы контролируете сторону отправки, стандартизируйте три вещи: всегда включайте event ID, всегда подписывайте payload одинаково и публикуйте политику повторов понятным языком. Это предотвращает бесконечные переписки, когда партнёр говорит «мы отправили», а ваша система ничего не показывает.
Пример: платежный вебхук от «failed» до «fixed» с воспроизведением
Частый сценарий — webhook от Stripe, который делает два действия: создаёт запись Order, затем отправляет квитанцию по email/SMS. Звучит просто, пока одно событие не упадёт и никто не знает, списали ли деньги, есть ли заказ и ушла ли квитанция.
Реалистичная ошибка: вы ротируете секрет Stripe. Несколько минут ваш endpoint всё ещё проверяет старый секрет, поэтому Stripe доставляет события, а ваш сервер отклоняет их с 401/400. Дашборд показывает «webhook failed», а логи приложения — только «invalid signature».
Хорошие логи делают причину очевидной. Для неудачного события запись должна показывать устойчивый event ID и достаточно деталей по верификации, чтобы точно локализовать несовпадение: версия подписи, timestamp подписи, результат проверки и понятная причина отклонения (неверный секрет vs дрейф времени). Во время ротации полезно логировать, какой секрет использовался для попытки проверки (например «current» vs «previous»), а не сам секрет.
Когда secret исправили и оба («current» и «previous») принимаются в короткое окно, всё равно остаётся задача обработать застрявшие события. Инструмент воспроизведения превращает это в простую задачу:
- Найти событие по event_id.
- Подтвердить, что причина ошибки решена.
- Воспроизвести событие.
- Проверить идемпотентность: Order создан один раз, квитанция отправлена один раз.
- Добавить результат воспроизведения и временные метки в тикет.
Типичные ошибки и как их избегать
Проверяйте подписи вебхуков последовательно
Добавьте шаг HMAC-проверки в поток до парсинга JSON или записи данных.
Большинство проблем с вебхуками кажутся загадочными, потому что системы записывают только финальную ошибку. Относитесь к каждой доставке как к короткому отчёту инцидента: что пришло, какое решение принято и что произошло дальше.
Частые ошибки:
- Логирование только исключений вместо полного жизненного цикла (received, verified, queued, processed, failed, retried)
- Сохранение полных payload и заголовков без маскировки, что приводит к попаданию секретов или персональных данных в логи
- Обработка повторов как новых событий, что даёт двойные списания или дубли сообщений
- Возврат 200 OK до того, как событие надёжно сохранено, из‑за чего дашборды выглядят зелёными, а работа позднее умирает
Практичные исправления:
- Храните минимальную, searchable запись запроса плюс историю изменений статуса.
- Маскируйте чувствительные поля по умолчанию и ограничивайте доступ к raw payload.
- Принуждайте идемпотентность на уровне БД, а не только в коде.
- Подтверждайте приём только после надёжного сохранения события.
- Делайте воспроизведение поддерживаемым рабочим процессом, а не скриптом «на коленке».
Если вы используете AppMaster, эти части естественно укладываются в платформу: таблица событий в Data Designer, статус‑ориентированный Business Process для верификации и обработки, и админ‑UI для поиска и воспроизведения.
Быстрый чеклист и дальнейшие шаги
Стремитесь к одним и тем же базовым вещам каждый раз:
- У каждого события есть уникальный event_id, и вы сохраняете raw payload как пришёл.
- Проверка подписи выполняется для каждого запроса, а неудачи содержат понятную причину.
- Повторы предсказуемы, а обработчики идемпотентны.
- Воспроизведение доступно только авторизованным ролям и оставляет след аудита.
- Логи доступны для поиска по event_id, provider id, статусу и времени, с кратким «что произошло».
Отсутствие хотя бы одной из этих вещей всё ещё может превратить интеграцию в чёрный ящик. Если вы не сохраняете raw payload, вы не сможете доказать, что прислал провайдер. Если ошибки подписи не конкретны, вы потратите часы на разбирательства о том, чья это проблема.
Если хотите быстро собрать это без ручной реализации каждой детали, AppMaster (appmaster.io) поможет собрать модель данных, потоки обработки и админ‑UI в одном месте, при этом генерируя реальный исходный код для итогового приложения.