Почему drag-and-drop-воркфлоу ломаются
Визуальные редакторы процессов кажутся безопасными, потому что видно всю диаграмму. Но картинка может врать. Воркфлоу может выглядеть аккуратно и при этом падать в продакшене, когда появляются реальные пользователи, реальные данные и реальные проблемы с таймингом.
Многие проблемы возникают от того, что диаграмму воспринимают как чеклист, а не как то, чем она является на самом деле: программой. Блоки всё ещё содержат логику. Они создают состояние, ветвятся, повторяются и вызывают побочные эффекты. Когда эти части не выделены явно, «маленькие» правки тихо меняют поведение.
Антипаттерн воркфлоу — это повторяющаяся плохая форма, которая постоянно приносит проблемы. Это не одиночный баг, а привычка: прятать важное состояние в переменных, установленных в одном углу диаграммы и используемых в другом, или позволять потоку расти до тех пор, что его никто не может осмысленно прочитать.
Симптомы знакомы:
- Одинаковый ввод даёт разные результаты в разных запусках
- Отладка превращается в угадывание, потому что непонятно, где изменилось значение
- Маленькие правки ломают нерелевантные ветки
- Исправления добавляют ветвления вместо их уменьшения
- Ошибки оставляют частичные изменения (некоторые шаги прошли, другие — нет)
Начните с того, что дешевле и видно сразу: более понятные имена, плотная группировка, удаление мёртвых путей и явные входы и выходы у каждого шага. На платформах типа AppMaster это часто означает держать Business Process сфокусированным: каждый блок делает одну задачу и передаёт данные открыто.
Дальше планируйте более глубокий рефактор для структурных проблем: распутывание «спагетти»-потоков, централизация решений и добавление компенсаций для частичных успехов. Цель не в красивой диаграмме, а в том, чтобы воркфлоу вел себя одинаково каждый раз и его было безопасно менять при изменении требований.
Скрытое состояние: тихий источник сюрпризов
Многие визуальные ошибки начинаются с одной невидимой проблемы: состояние, на которое вы опираетесь, но которое не названо явно.
Состояние — это всё, что нужно воркфлоу, чтобы работать правильно. Это переменные (например, customer_id), флаги (например, is_verified), таймеры и повторные попытки, а также состояние вне диаграммы: строка в базе данных, запись в CRM, статус платежа или уже отправленное сообщение.
Скрытое состояние появляется, когда эта «память» живёт там, где вы её не ждёте. Типичные примеры: настройки узлов, которые тайно ведут себя как переменные, неявные значения по умолчанию, которые вы никогда не устанавливали сознательно, или побочные эффекты, изменяющие данные без явного указания. Шаг, который «проверяет» что-то и одновременно обновляет поле статуса — классическая ловушка.
Обычно всё работает, пока вы не внесёте маленькую правку. Вы перемещаете узел, повторно используете субфлоу, меняете значение по умолчанию или добавляете новую ветку. Вдруг воркфлоу начинает вести себя «случайно»: переменная перезаписывается, флаг не сброшен или внешняя система вернула чуть другой ответ.
Где прячется состояние (даже в чисто выглядящих диаграммах)
Состояние обычно прячется в:
- Настройках узлов, которые действуют как переменные (захардкоженные ID, статусы по умолчанию)
- Неявных выходах от предыдущих шагов («использовать последний результат»)
- Шагах «чтения», которые также пишут (обновления БД, изменения статусов)
- Внешних системах (платежи, email/SMS-провайдеры, CRM), которые помнят прошлые действия
- Таймерах и повторных попытках, которые продолжают работать после изменения ветки
Правило, которое предотвращает большинство сюрпризов
Делайте состояние явным и именованным. Если значение важно позже, сохраните его в явно именованной переменной, установите в одном месте и сбрасывайте, когда оно больше не нужно.
Например, в AppMaster’s Business Process Editor относитесь к каждому важному выходу как к полноценной переменной, а не как к тому, что «знаете», потому что узел сработал раньше. Небольшая правка вроде переименования status в payment_status и установки этого значения только после подтверждения платежа может сэкономить часы отладки при следующих изменениях.
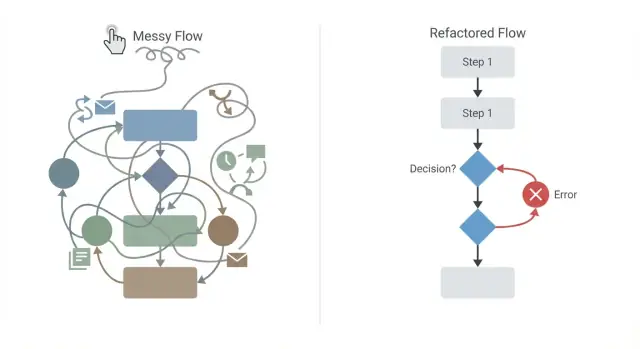
«Спагетти»-потоки: когда диаграмма становится нечитаемой
«Спагетти»-поток — это визуальный процесс, где соединители пересекаются повсюду, шаги возвращаются назад в неожиданных местах, а условия вложены так глубоко, что никто не может объяснить основную ветку без зума и скролла. Если ваша диаграмма напоминает карту метро, нарисованную на салфетке, вы уже платите цену.
Это делает ревью ненадёжным. Люди пропускают пограничные случаи, согласования занимают больше времени, а изменение в одном углу может сломать что-то далеко. Во время инцидента трудно ответить на простые вопросы вроде «Какой шаг выполнился последним?» или «Почему мы попали в эту ветку?»
«Спагетти» обычно растёт из благих намерений: копирование рабочей ветки «ещё раз», добавление быстрых фиксов под давлением, наложение обработки исключений в виде вложенных условий, возвраты к ранним шагам вместо создания переиспользуемого субпроцесса или смешение бизнес-правил, форматирования данных и уведомлений в одном блоке.
Типичный пример — онбординг. Он начинается чисто, затем появляются отдельные ветки для бесплатных триалов, рефералов партнёров, ручной проверки и обработки VIP. Через несколько спринтов диаграмма имеет несколько обратных ссылок к «Собрать документы» и несколько мест, откуда отправляется welcome-письмо.
Более здоровая цель — простота: одна основная ветка для обычного случая и явные боковые пути для исключений. В инструментах вроде AppMaster’s Business Process Editor это часто значит вынести повторяющуюся логику в переиспользуемый субпроцесс, назвать ветки по смыслу («Требуется ручная проверка») и держать циклы явными и ограниченными.
Перегрузка решений и дублирование правил
Типовой паттерн — длинная цепочка узлов условий: проверить A, потом снова A, затем B в трёх разных местах. Это начинается как «ещё одно правило», а потом воркфлоу превращается в лабиринт, где маленькие изменения дают большие побочные эффекты.
Более опасно — рассредоточенные правила, которые со временем расходятся. По одному пути заявление одобряют из-за высокого кредитного рейтинга. По другому — блокируют за «отсутствие номера телефона», потому что старый шаг считает это критичной ошибкой. Оба решения могут быть «логичными» локально, но вместе дают непоследовательные результаты.
Почему дублирующиеся проверки вызывают конфликты
Когда одно и то же правило повторяется по диаграмме, люди обновляют одну копию и пропускают другие. Со временем проверки выглядят похоже, но не совпадают: одна говорит «country = US», другая «country in (US, CA)», третья использует «currency = USD» как прокси. Воркфлоу всё ещё выполняется, но перестаёт быть предсказуемым.
Хороший рефакторинг — консолидировать решения в одном явно именованном блоке, который выдаёт небольшой набор исходов. В инструментах типа AppMaster’s Business Process Editor это часто значит сгруппировать связанные проверки в один decision-блок и сделать ветви осмысленными.
Держите результаты простыми, например:
- Approved
- Needs info
- Rejected
- Manual review
А затем направляйте всё через единую точку принятия решения вместо рассыпать мини-решения по всему потоку. Если правило меняется, вы обновляете его один раз.
Конкретный пример: workflow верификации регистрации проверяет формат email в трёх местах (до OTP, после OTP и перед созданием аккаунта). Перенесите валидацию в один шаг «Validate request». Если это «Needs info», направьте в одно сообщение, которое точно скажет пользователю, чего не хватает, вместо позднего отказа с общей ошибкой.
Отсутствие компенсаций после частичного успеха
Keep workflows safe to change
Use AppMaster to keep business logic readable as requirements change.
Одна из самых дорогих ошибок — думать, что воркфлоу либо полностью успешен, либо полностью провален. На практике процессы часто проходят наполовину. Если последующий шаг ломается, остаётся бардак: деньги сняты, сообщения отправлены, записи созданы, но нет аккуратного способа откатиться.
Пример: вы списали деньги с карты клиента, затем пытаетесь создать заказ. Платёж прошёл, но создание заказа упало из-за тайм-аута сервисa инвентаря. Теперь поддержка получает злые письма, финансы видят платёж, а системе не хватает соответствующего заказа для выполнения.
Компенсация — это путь «отмены» (или «сделать безопасным»), который выполняется, когда что-то падает после частичного успеха. Она не обязана быть идеальной, но должна быть намеренной. Типичные подходы: обратить действие (refund, cancel, удалить черновик), перевести результат в безопасное состояние (отметить «Payment captured, fulfillment pending»), направить на ручную проверку с контекстом и использовать идемпотентные проверки, чтобы повторные попытки не удвоили списание или отправку.
Где размещать компенсации — важно. Не прячьте всю уборку в одном «error»-боксе в конце диаграммы. Поместите её рядом с рискованным шагом, пока у вас ещё есть нужные данные (payment ID, reservation token, external request ID). В AppMaster это обычно значит сохранять эти ID сразу после вызова, а затем ветвиться по успеху/ошибке.
Полезное правило: каждый шаг, который общается с внешней системой, должен ответить на два вопроса прежде чем двигаться дальше: «Что мы изменили?» и «Как отозвать или локализовать это, если следующий шаг упадёт?»
Слабая обработка ошибок при внешних вызовах
Многие ошибки появляются в тот момент, когда воркфлоу выходит за пределы вашей системы. Внешние вызовы ломаются по-разному: медленные ответы, временные ауты, дублированные запросы и частичные успехи. Если диаграмма предполагает «вызов успешен» и продолжает, пользователи рано или поздно увидят недостающие данные, двойные списания или уведомления не в том порядке.
Начните с пометки шагов, которые могут падать по причинам, от вас не зависящим: внешние API, платежи и возвраты (например, Stripe), сообщения (email/SMS, Telegram), операции с файлами и облачные сервисы.
Две распространённые ловушки: отсутствие таймаутов и «слепые» повторные попытки. Без таймаута один медленный запрос может заморозить весь процесс. С повторными попытками без правил можно сделать хуже: отправить одно и то же сообщение три раза или создать дубликаты в третьей системе.
Здесь важна идемпотентность. Проще говоря, идемпотентное действие безопасно выполнять повторно. Если воркфлоу повторяет шаг, он не должен создавать второе списание, второй заказ или второе «welcome»-сообщение.
Практическое исправление — сохранить ключ запроса и статус перед вызовом. В AppMaster’s Business Process Editor это может быть просто запись вроде «payment_attempt: key=XYZ, status=pending», затем обновление в «success» или «failed» после ответа. Если шаг повторится, сначала смотрим эту запись и решаем, что делать.
Надёжный паттерн выглядит так:
- Установите таймаут и лимиты повторов (и определите, какие ошибки стоит ретраить)
- Сохраните ключ запроса и текущий статус перед вызовом
- Сделайте внешний вызов
- При успехе сохраните результат и отметьте статус как completed
- При ошибке залогируйте причину и направьте на понятный путь восстановления для пользователя
Перегруженные шаги и неясные ответственности
Go from prototype to production
Deploy your solution to the cloud or export source code when you need full control.
Распространённая ошибка — один шаг, который тихо делает четыре задачи: валидирует ввод, считает значения, пишет в БД и уведомляет людей. Кажется эффективно, но изменения становятся рискованными. Когда что-то ломается, непонятно, какая часть виновата, и нельзя безопасно переиспользовать этот шаг в другом месте.
Как заметить перегруженный шаг
Шаг перегружен, когда его имя расплывчато (например, «Handle order») и вы не можете описать его выход в одном предложении. Другой тревожный знак — длинный список входов, которые используются только «в какой-то части» шага.
Перегруженные шаги часто смешивают:
- Валидацию и мутирование (save/update)
- Бизнес-правила и презентацию (форматирование сообщений)
- Несколько внешних вызовов в одном месте
- Несколько побочных эффектов без явного порядка
- Неясные критерии успеха (что значит «готово»?)
Рефакторинг в маленькие блоки с явными контрактами
Разделите большой шаг на маленькие, именованные блоки, где каждый блок делает одну задачу и имеет чёткий вход и выход. Простая схема именования помогает: глаголы для шагов (Validate Address, Calculate Total, Create Invoice, Send Confirmation) и существительные для объектов данных.
Используйте консистентные имена для входов и выходов. Например, выбирайте «OrderDraft» (до сохранения) и «OrderRecord» (после сохранения), а не «order1/order2» или «payload/result». Это делает диаграмму читаемой и через месяцы.
Когда паттерн повторяется, выносите его в переиспользуемый субфлоу. В AppMaster’s Business Process Editor это часто выглядит как перенос «Validate -> Normalize -> Persist» в общий блок, используемый в нескольких воркфлоу.
Пример: онбординг, который «создаёт пользователя, назначает права, отправляет письмо и логирует аудит», можно превратить в четыре шага плюс переиспользуемый субфлоу «Write Audit Event». Так проще тестировать, правки безопаснее, а сюрпризов меньше.
Как поэтапно рефакторить запутанный воркфлоу
Make state impossible to miss
Design business processes with explicit inputs, outputs, and failure paths.
Большинство проблем с воркфлоу появляются от добавления «ещё одного» правила или соединителя до тех пор, пока никто не может предсказать поведение. Рефакторинг — это сделать поток снова читабельным и показать каждый побочный эффект и случай ошибки.
Начните с того, чтобы нарисовать happy path как одну чёткую линию от начала до конца. Если главная цель — «одобрить заказ», эта линия должна показывать только необходимые шаги, когда всё идёт хорошо.
Далее действуйте мелкими проходами:
- Перерисуйте happy path как один прямой путь с согласованными именами шагов (глагол + объект)
- Перечислите каждый побочный эффект (отправка писем, списание денег, создание записей) и сделайте каждый отдельным явным шагом
- Для каждого побочного эффекта добавьте путь ошибки рядом с ним, включая компенсацию, если вы уже что-то изменили
- Замените повторяющиеся условия одной точкой решения и маршрутизируйте оттуда
- Вынесите повторяющиеся куски в субфлоу и переименуйте переменные так, чтобы их смысл был очевиден (
payment_status лучше чем flag2)
Быстрый способ найти скрытую сложность — спросить: «Если этот шаг выполнится дважды, что сломается?» Если ответ «может произойти двойное списание» или «мы можем отправить два письма», вам нужны явное состояние и идемпотентное поведение.
Пример: онбординг создаёт аккаунт, присваивает план, снимает плату через Stripe и отправляет welcome. Если платёж прошёл, а отправка письма — упала, вы не хотите, чтобы платный пользователь остался без доступа. Добавьте рядом компенсационную ветку: пометить пользователя как pending_welcome, повторить отправку, а при неудаче — вернуть деньги и откатить план.
В AppMaster эта уборка проще, когда Business Process Editor остаётся неглубоким: маленькие шаги, понятные имена переменных и субфлоу «Charge payment» или «Send notification», которые можно переиспользовать.
Распространённые ловушки рефакторинга, которых стоит избегать
Рефакторинг визуальных воркфлоу должен упростить процесс и сделать его безопасным для изменений. Но некоторые фиксы добавляют новую сложность, особенно под давлением времени.
Одна ловушка — оставлять старые пути «на всякий случай» без явного переключателя, маркера версии или даты удаления. Люди продолжают тестировать старый маршрут, поддержка ссылается на него, и вскоре вы поддерживаете два процесса. Если нужен поэтапный релиз, сделайте его очевидным: назовите новый путь, зага́тируйте его одним видимым решением и запланируйте удаление старого.
Временные флаги — ещё одна медленная утечка. Флаг, созданный для отладки или миграции на неделю, часто остаётся навсегда; каждая следующая правка должна помнить о нём. Обращайтесь с флагами как с скоропортящимися: документируйте причину, назначьте владельца и укажите дату удаления.
Третья ловушка — добавление одноразовых исключений вместо изменения модели. Если вы всё время вставляете «особые случаи», диаграмма растёт в ширину, и правила становятся непредсказуемыми. Когда одно и то же исключение появляется дважды, это обычно знак, что нужно обновить модель данных или состояния процесса.
Наконец, не прячьте бизнес-правила внутри не связанных узлов только чтобы «чтобы работало». Визуальные редакторы особенно располагают к этому, но потом никто не может найти правило.
Сигналы тревоги:
- Два пути делают одно и то же с небольшими отличиями
- Флаги с непонятным смыслом (например, «temp2» или «useNewLogic»)
- Исключения, которые может объяснить только один человек
- Правила разбросаны по множеству узлов без единого источника истины
- Узлы «фиксации», добавленные после сбоев вместо улучшения предыдущего шага
Пример: если VIP-клиенты требуют другой одобрения, не добавляйте скрытые проверки в три места. Добавьте явное решение «Customer type» один раз и маршрутизируйте оттуда.
Быстрая чек-лист перед релизом
Handle partial success safely
Add compensation paths near risky calls like payments and messaging.
Большинство проблем проявляется прямо перед запуском: кто-то прогоняет поток на реальных данных, и диаграмма делает что-то, что никто не может объяснить.
Пройдитесь вслух по сценарию. Если happy path требует длинного рассказа, значит в потоке, вероятно, есть скрытое состояние, дублирующиеся правила или слишком много веток, которые стоило бы сгруппировать.
Быстрая проверка перед релизом
- Объясните happy path одним предложением: триггер, основные шаги, финиш
- Сделайте каждый побочный эффект отдельным видимым шагом (списание, отправка сообщений, обновление записей, создание тикетов)
- Для каждого побочного эффекта решите, что происходит при ошибке и как вы откатываете частичный успех (refund, cancel, rollback или пометка для ручной проверки)
- Проверьте переменные и флаги: понятные имена, одно очевидное место установки и никаких загадочных значений по умолчанию
- Поиск копипаст-логики: одно и то же условие в нескольких ветках или одинаковые маппинги с небольшими различиями
Один простой тест, который ловит большинство ошибок
Запустите поток с тремя кейсами: обычный успешный, вероятный провал (например, отказ платежа) и странный пограничный случай (отсутствие опциональных данных). Следите за шагами, которые «вроде бы сработали» и оставили систему наполовину готовой.
В инструментах вроде AppMaster’s Business Process Editor это часто приводит к чистому рефактору: вынести повторяющиеся проверки в общий шаг, сделать побочные эффекты явными узлами и добавить рядом компенсацию для каждого рискованного вызова.
Реалистичный пример: рефактор онбординга
Представьте воркфлоу онбординга, который делает три вещи: верифицирует идентичность пользователя, создаёт аккаунт и запускает платную подписку. Звучит просто, но часто превращается в поток, который «обычно работает», пока что-то не сломается.
Мешанина
Первая версия растёт шаг за шагом. Появляется чекбокс «Verified», затем флаг «NeedsReview», потом ещё флаги. Проверки вроде «if verified» появляются в нескольких местах, потому что каждая новая фича добавляет свою ветку.
Вскоре диаграмма выглядит так: verify identity, create user, charge card, send welcome email, create workspace, затем прыжок назад, чтобы повторно проверить верификацию, потому что более поздний шаг от неё зависит. Если плата прошла, а создание воркспейса упало, отката нет. Клиент списан, но аккаунт наполовину создан — идут тикеты в поддержку.
Рефактор
Более чистый дизайн начинается с видимого и контролируемого состояния. Замените разбросанные флаги одним явным статусом онбординга (например: Draft, Verified, Subscribed, Active, Failed). Поместите логику «продолжать или нет» в одну точку решения.
Цели рефакторинга, которые обычно быстро убирают боль:
- Один шлюз-решение, которое читает явный статус и маршрутизирует следующий шаг
- Нет повторных проверок по диаграмме, только переиспользуемые валидационные блоки
- Компенсации для частичных успехов (refund payment, cancel subscription, delete workspace draft)
- Явный путь failure, который сохраняет причину и останавливается безопасно
После этого смоделируйте данные и процесс вместе. Если Subscribed true, сохраните subscription ID, payment ID и ответ провайдера в одном месте, чтобы компенсация могла запуститься без догадок.
Наконец, тестируйте кейсы отказов намеренно: тайм-ауты верификации, платёж успешен, но письмо не ушло, ошибки создания воркспейса и дублированные вебхуки.
Если вы строите эти воркфлоу в AppMaster, полезно держать бизнес-логику в переиспользуемых Business Processes и позволять платформе генерировать чистый код по мере изменений, чтобы старые ветки не застревали. Если хотите быстро прототипировать рефактор (с бэкендом, вебом и мобильной частью в одном месте), AppMaster на appmaster.io как раз заточен под такого рода end-to-end сборку.