11 апр. 2025 г.·7 мин
Минимальная настройка наблюдаемости для CRUD‑бэкендов и API
Минимальная настройка наблюдаемости для CRUD‑бэкендов: структурированные логи, ключевые метрики и практичные оповещения, чтобы быстро ловить медленные запросы, ошибки и простои.
Какую проблему решает наблюдаемость в CRUD‑ориентированных приложениях
CRUD‑ориентированные бизнес‑приложения обычно ломаются скучными и дорогими способами. Страница списка с каждым неделей становится медленнее, кнопка сохранения иногда таймаутит, а служба поддержки пишет про «случайные 500», которые вы не можете воспроизвести. В разработке ничего не ломается, но в продакшне ощущается ненадёжность.
Реальная цена — не только сам инцидент. Это время, потраченное на догадки. Без понятных сигналов команды перескакивают между «это база данных», «это сеть» и «это тот эндпоинт», пока пользователи ждут и доверие падает.
Наблюдаемость превращает догадки в ответы. Проще говоря: вы смотрите, что случилось, и понимаете почему. Для этого нужны три типа сигналов:
- Логи: что приложение решило сделать (с полезным контекстом)
- Метрики: как система ведёт себя со временем (латентность, доля ошибок, насыщенность)
- Трейсы (опционально): где именно тратится время между сервисами и БД
Для CRUD‑приложений и API это не про красивые дашборды, а про быструю диагностику. Когда вызов «Create invoice» замедляется, вы должны в течение минут понять: задержка в запросе к базе, во внешнем API или из‑за перегруженного воркера — а не тратить часы.
Минимальная настройка начинается с вопросов, на которые вам нужно ответить в плохой день:
- Какой эндпоинт падает или медлит, и для кого?
- Это всплеск трафика или регрессия после релиза?
- База данных — узкое место, или приложение?
- Это влияет на пользователей прямо сейчас, или просто заполняет логи?
Если вы собираете бэкенды с помощью генератора (например, AppMaster, генерирующий Go‑сервисы), то правило то же самое: начните с малого, держите сигналы последовательными и добавляйте метрики или оповещения только после реального инцидента, который показал бы, что они сэкономили бы время.
Минимальная настройка: что нужно и что можно пропустить
Минимальная наблюдаемость опирается на три столпа: логи, метрики и оповещения. Трейсы полезны, но для большинства CRUD‑сервисов — это бонус.
Цель проста. Вы должны знать (1) когда пользователи терпят неудачу, (2) почему это происходит и (3) где в системе это происходит. Если вы не можете быстро ответить на эти вопросы, вы будете тратить время на догадки и споры о том, что изменилось.
Наименьший набор сигналов, который обычно даёт это, выглядит так:
- Структурированные логи для каждого запроса и фоновой задачи, чтобы можно было искать по
request_id, пользователю, эндпоинту и ошибке.
- Несколько ключевых метрик: скорость запросов, доля ошибок, латентность и время работы БД.
- Оповещения, привязанные к пользовательскому воздействию (всплески ошибок или длительная медленная работа), а не ко всем внутренним предупреждениям.
Полезно разделять симптомы и причины. Симптом — это то, что чувствует пользователь: 500, таймауты, медленные страницы. Причина — то, что это вызвало: блокировки, исчерпанный пул соединений или медленный запрос после добавления фильтра. Оповещайте по симптомам, используйте сигналы‑причины для расследования.
Практическое правило: выберите одно место для просмотра важных сигналов. Переключение контекстов между инструментом логов, инструментом метрик и отдельным почтовым ящиком оповещений замедляет вас в критичный момент.
Структурированные логи, которые читаются под давлением
Когда что‑то ломается, самый быстрый путь к ответу обычно такой: «Какой именно запрос сделал этот пользователь?» Поэтому стабильный корреляционный ID важнее почти любого другого приёма в логах.
Выберите одно имя поля (обычно request_id) и делайте его обязательным. Генерируйте на краю (API‑шлюз или первый handler), пробрасывайте через внутренние вызовы и включайте в каждую строку лога. Для фоновых задач создавайте новый request_id на запуск задачи и храните parent_request_id, если задача была вызвана из API.
Логируйте в JSON, а не в свободном тексте. Это делает логи поисковыми и последовательными, когда вы устаете, нервничаете и быстро просматриваете.
Простой набор полей хватит для большинства CRUD‑API сервисов:
timestamp, level, service, envrequest_id, route, method, statusduration_ms, db_query_counttenant_id или account_id (безопасные идентификаторы, не персональные данные)
Логи должны помогать сузить «какой клиент и какой экран», не превращаясь в утечку данных. Избегайте имён, email, телефонов, адресов, токенов или полных тел запросов по умолчанию. Если нужно больше деталей, логируйте их только по требованию и с редактированием.
Два поля окупают себя быстро в CRUD‑системах: duration_ms и db_query_count. Они ловят медленные обработчики и случайные N+1 ещё до внедрения трейсинга.
Определите уровни логов, чтобы все использовали их одинаково:
info: ожидаемые события (запрос завершён, задача запущена)warn: необычное, но восстанавливаемое (медленный запрос, повтор удался)error: упавший запрос или задача (исключение, таймаут, недоступная зависимость)
Если вы создаёте бэкенды с платформой вроде AppMaster, используйте одни и те же имена полей во всех генерируемых сервисах, чтобы «поиск по request_id» работал повсюду.
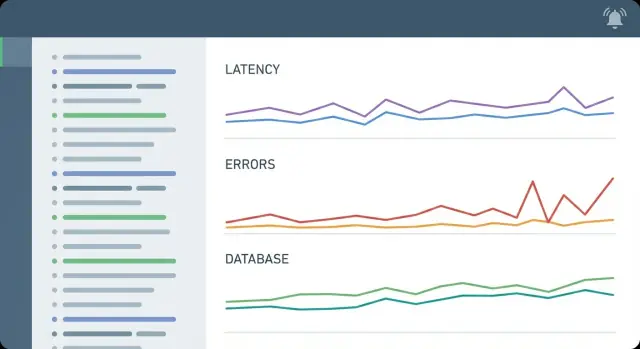
Ключевые метрики, которые важны для CRUD‑бэкендов и API
Большинство инцидентов в CRUD‑серверах имеет знакомую форму: один‑два эндпоинта замедляются, база нагружается, и пользователи видят спиннеры или таймауты. Ваши метрики должны делать эту историю очевидной за минуты.
Минимальный набор обычно охватывает пять областей:
- Трафик: запросы в секунду (по маршруту или хотя бы по сервису) и скорость запросов по классам статусов (2xx, 4xx, 5xx)
- Ошибки: доля 5xx, количество таймаутов и отдельная метрика «бизнес‑ошибки» в виде 4xx (чтобы не будить людей из‑за ошибок пользователей)
- Латентность (процентели): p50 для типичного опыта и p95 (иногда p99) для обнаружения «что‑то не так»
- Насыщенность: CPU и память, плюс специфичная насыщенность (использование воркеров, давление на потоки/goroutine, если вы это экспонируете)
- Нагрузка на базу данных: p95 времени запросов, пул соединений (в использовании vs максимум) и время ожидания блокировок (или счётчики запросов в ожидании)
Две детали делают метрики более действенными.
Во‑первых, отделяйте интерактивные API‑запросы от фоновой работы. Медленный отправитель почты или петля повторных попыток вебхуков может съесть CPU, соединения к БД или исходящую сеть и заставить API казаться «случайно медленным». Отслеживайте очереди, ретраи и длительность задач как отдельные временные ряды, даже если они работают в том же бэкенде.
Во‑вторых, всегда добавляйте метаданные версии/сборки к дашбордам и оповещениям. Когда вы деплоите новый сгенерированный бэкенд (например, после регенерации кода с помощью no‑code инструмента вроде AppMaster), вы должны быстро ответить на вопрос: поднялся ли уровень ошибок или p95 сразу после релиза?
Простое правило: если метрика не подсказывает, что делать дальше (откат, масштабирование, исправить запрос или остановить задачу), её не место в минимальном наборе.
Сигналы базы данных: обычная корневая причина боли в CRUD
Начать с чистого бэкенда
Быстро создайте CRUD‑бэкенд и сохраняйте согласованность логов и метрик с самого начала.
В CRUD‑приложениях база данных часто та точка, где «кажется медленно» превращается в реальную боль для пользователей. Минимальная настройка должна ясно показывать, когда узкое место в PostgreSQL, и какого оно типа.
Что измерять в PostgreSQL в первую очередь
Не нужно множество панелей. Начните с сигналов, которые объясняют большинство инцидентов:
- Частота медленных запросов и p95/p99 времени запросов (и топ медленных запросов)
- Ожидания блокировок и deadlock (кто кого блокирует)
- Использование соединений (активные vs лимит пула, неудачные подключения)
- Давление на диск и I/O (латентность, насыщенность, свободное место)
- Задержка репликации (если у вас read replicas)
Разделяйте время приложения и время базы
Добавьте гистограмму времени запросов в API‑слое и тэгируйте её по эндпоинту или сценарию (например: GET /customers, “search orders”, “update ticket status”). Это показывает, медлит ли эндпоинт из‑за множества мелких запросов или одного большого.
Находите N+1 паттерны ранним
Экраны CRUD часто вызывают N+1: один запрос списка, затем по одному запросу на строку для связанных данных. Следите за эндпоинтами, где число запросов остаётся стабильным, а количество запросов к БД на один запрос растёт. При генерации бэкендов из моделей и бизнес‑логики это часто то место, где меняют паттерн выборки.
Если у вас уже есть кеш, отслеживайте hit rate. Не добавляйте кеш только ради красивых графиков.
Рассматривайте изменения схем и миграции как окно риска. Записывайте время начала и конца и следите за всплесками блокировок, времени запросов и ошибок соединения в этот период.
Оповещения, которые будят нужного человека по нужной причине
Выберите путь деплоя
Разверните в своём облаке или экспортируйте исходники, когда потребуется полный контроль над инструментами наблюдаемости.
Оповещения должны указывать на реальную проблему пользователя, а не на «занятую» диаграмму. Для CRUD‑приложений начните с того, что чувствуют пользователи: ошибки и медлительность.
Если вы добавляете лишь три оповещения сначала, сделайте их такими:
- рост доли 5xx
- длительно высокая p95‑латентность
- резкое падение успешных запросов
После этого добавьте пару оповещений «вероятных причин». CRUD‑бэкенды часто падают предсказуемо: база исчерпала соединения, очередь фоновых задач накапливается, или один эндпоинт начинает таймаутить и тянет весь API вниз.
Пороговые значения: базовая линия + запас, а не догадки
Жёстко задавать числа вроде «p95 > 200ms» редко работает в разных окружениях. Замерьте нормальную неделю, затем установите оповещение чуть выше нормального с запасом. Например, если p95 обычно 350–450ms в рабочие часы, срабатывание на 700ms в течение 10 минут. Если 5xx обычно 0.1–0.3%, будьте на 2% в течение 5 минут.
Держите пороги стабильными. Не перенастраивайте каждый день. Меняйте их после инцидента, когда можно привязать изменения к реальным последствиям.
Пейджинг vs тикеты: решите заранее
Используйте два уровня серьёзности, чтобы люди доверяли сигналу:
- Page когда пользователи заблокированы или данные в риске (высокая доля 5xx, таймауты API, пул соединений БД почти исчерпан)
- Создать тикет когда деградация есть, но не срочная (плавный рост p95, рост очереди задач, тенденция роста диска)
Отключайте оповещения во время ожидаемых событий вроде окон деплоя и плановой поддержки.
Делайте оповещения действенными. Включайте «что проверить первым» (топ‑эндпоинт, соединения БД, последний деплой) и «что изменилось» (новый релиз, изменение схемы). Если вы используете AppMaster, указывайте, какой бэкенд или модуль был недавно регенерирован и задеплоен — это часто самое быстрое подозрение.
Простые SLO для бизнес‑приложений (и как они формируют оповещения)
Минимальная настройка проще, когда вы решаете, что значит «достаточно хорошо». Именно для этого служат SLO: ясные цели, которые превращают размытый мониторинг в конкретные оповещения.
Начните с SLIs, соответствующих тому, что чувствуют пользователи: доступность (могут ли пользователи завершать запросы), латентность (как быстро выполняются действия) и доля ошибок (как часто запросы падают).
Устанавливайте SLO группами эндпоинтов, а не по каждому роуту. Для CRUD‑приложений группировка упрощает: чтение (GET/list/search), запись (create/update/delete) и аутентификация (login/token refresh). Так избегаете сотни мелких SLO, за которыми никто не следит.
Примеры SLO, подходящих типичным ожиданиям:
- Внутреннее CRUD‑приложение (админка): доступность 99.5% в месяц, 95% чтений < 800 ms, 95% записей < 1.5 s, доля ошибок < 0.5%.
- Публичный API: доступность 99.9% в месяц, 99% чтений < 400 ms, 99% записей < 800 ms, доля ошибок < 0.1%.
Бюджет ошибок — это допустимое «плохое время» внутри SLO. SLO 99.9% в месяц ≍ 43 минуты простоя в месяц. Если вы исчерпали бюджет рано — приостаньте рискованные изменения, пока не восстановите стабильность.
Используйте SLO, чтобы решать, что заслуживает оповещения, а что — панель тренда. Оповещайте, когда вы быстро тратите бюджет ошибок (пользователи реально падают), а не когда метрика немного хуже вчера.
Если вы быстро генерируете бэкенды (например, AppMaster генерирует Go‑сервис), SLO помогают сохранять фокус на пользовательском воздействии, даже когда реализация меняется под капотом.
Шаг за шагом: соберите минимальную наблюдаемость за день
Упростите мониторинг API
Генерируйте Go‑сервисы с предсказуемыми эндпоинтами, чтобы панели оставались понятными по мере роста.
Начните с той части системы, которой чаще всего пользуются пользователи. Выберите API‑вызовы и задачи, которые при медленной работе или падении делают приложение неработоспособным.
Запишите свои топ‑эндпоинты и фоновые задачи. Для CRUD‑приложения обычно это логин, list/search, create/update и один экспорт/импорт. Если вы строили бэкенд с AppMaster, включите сгенерированные эндпоинты и любые бизнес‑процессы, запускаемые по расписанию или вебхукам.
План на один день
- Час 1: Выберите топ‑5 эндпоинтов и 1–2 фоновые задачи. Опишите, что значит «хорошо»: типичная латентность, ожидаемая доля ошибок, нормальное время работы БД.
- Часы 2–3: Добавьте структурированные логи с согласованными полями:
request_id, user_id (если есть), endpoint, status_code, latency_ms, db_time_ms и коротким error_code для известных ошибок.
- Часы 3–4: Добавьте базовые метрики: запросы в секунду, p95‑латентность, доля 4xx, доля 5xx и тайминги БД (время запросов и насыщенность пула, если есть).
- Часы 4–6: Постройте три дашборда: обзор (состояние одним взглядом), детали API (по эндпоинтам) и представление базы данных (медленные запросы, блокировки, использование соединений).
- Часы 6–8: Добавьте оповещения, запустите контролируемый сбой и подтвердите, что оповещение действенное.
Держите оповещения небольшим и сфокусированным. Вам нужны оповещения, которые показывают на пользовательское воздействие, а не на «что‑то поменялось».
Оповещения для старта (5–8 штук)
Надёжный стартовый набор: p95‑латентность API слишком высокая, длительная доля 5xx, резкий всплеск 4xx (часто проблемы с аутентификацией или валидацией), ошибки фоновых задач, медленные запросы к БД, соединения БД близки к лимиту и низкий объём свободного диска (если вы сами хостите).
Затем напишите короткий рукбук для каждого оповещения на одну страницу: что проверять первым (панели дашборда и ключевые поля логов), вероятные причины (блокировки в БД, отсутствующий индекс, внешний сбой) и первое безопасное действие (перезапустить зависший воркер, откатить изменение, приостановить тяжёлую задачу).
Частые ошибки, которые делают мониторинг шумным или бесполезным
Самый быстрый способ испортить минимальную наблюдаемость — относиться к мониторингу как к галочке. CRUD‑приложения обычно падают предсказуемо (медленные вызовы к БД, таймауты, плохие релизы), поэтому ваши сигналы должны оставаться сфокусированными на этом.
Самая частая проблема — усталость от оповещений: слишком много алертов, мало действий. Если вы будите людей по каждому всплеску, доверие пропадает за пару недель. Простое правило: оповещение должно указывать на вероятное исправление, а не просто «что‑то изменилось».
Ещё классическая ошибка — отсутствие корреляционных ID. Если вы не можете связать ошибку в логе, медленный запрос и запись БД в рамках одного запроса, вы теряете часы. Убедитесь, что у каждого запроса есть request_id (и включайте его в логи, трейсы, если они есть, и в ответы, когда это безопасно).
Что обычно создаёт шум
Шумные системы часто имеют общие проблемы:
- Одно оповещение смешивает 4xx и 5xx, поэтому ошибки клиента и сервера выглядят одинаково.
- Метрики ведут только средние, скрывая хвостовую латентность (p95 или p99), где пользователи испытывают неудобства.
- Логи случайно содержат чувствительные данные (пароли, токены, полные тела запросов).
- Оповещения срабатывают по симптомам без контекста (высокий CPU) вместо пользовательского воздействия (доля ошибок, латентность).
- Деплои невидимы, поэтому регрессии выглядят как случайные отказы.
CRUD‑приложения особенно уязвимы к «ловушке среднего». Один медленный запрос может сделать 5% запросов мучительными, в то время как среднее выглядит нормально. Хвостовая латентность + доля ошибок дают более точную картину.
Добавьте маркеры деплоев. Независимо от того, шипите вы из CI или регенерируете код в AppMaster, фиксируйте версию и время деплоя как событие и в логах.
Быстрые проверки: минимальный чек‑лист наблюдаемости
Выпускайте CRUD‑приложение, которое живёт долго
Постройте внутренний инструмент или админ‑панель и сохраняйте предсказуемую производительность с согласованным стеком.
Ваша настройка работает, когда вы можете быстро ответить на несколько вопросов, не копаясь по дашбордам 20 минут. Если вы не можете получить «да/нет» быстро, значит, вам не хватает ключевого сигнала или просмотры слишком разрознены.
Быстрые проверки во время инцидента
Вы должны уметь сделать большинство из этого меньше чем за минуту:
- Можете ли вы сказать, терпят ли пользователи неудачи прямо сейчас (да/нет) из одного вида ошибок (5xx, таймауты, упавшие задачи)?
- Можете ли вы увидеть самую медленную группу эндпоинтов и её p95‑латентность и понять, становится ли хуже?
- Можете ли вы отделить время приложения от времени БД для запроса (время хендлера, время запросов к БД, внешние вызовы)?
- Видите ли вы, близка ли база к лимитам соединений или CPU, и стоят ли запросы в очереди?
- Если оповещение сработало, подсказывает ли оно следующее действие (откат, масштаб, проверка соединений БД, изучение одного эндпоинта), а не просто «латентность выросла»?
Логи должны быть одновременно безопасными и полезными. Им нужен достаточный контекст, чтобы проследить один упавший запрос через сервисы, но они не должны утекать персональные данные.
Проверка логов
Выберите недавний провал и откройте его логи. Подтвердите, что есть request_id, эндпоинт, статус‑код, длительность и понятное сообщение об ошибке. Также проверьте, что вы не логируете сырые токены, пароли, полные платёжные данные или персональные поля.
Если вы строите CRUD‑бэкенды с AppMaster, стремитесь к единому «видению инцидента», которое объединяет эти проверки: ошибки, p95 по эндпоинтам и здоровье БД. Это покрывает большинство реальных отказов в бизнес‑приложениях.
Пример: как диагностировать медленный CRUD‑экран с нужными сигналами
Проверить чек‑лист инцидента
Прототипируйте топ‑5 эндпоинтов быстро и проверьте минимальные оповещения на реальном трафике.
Внутренняя админка утром работает нормально, а затем в час пик заметно медлеет. Пользователи жалуются: открытие списка «Orders» и сохранение изменений занимает 10–20 секунд.
Вы начинаете с топ‑уровневых сигналов. Дашборд API показывает, что p95 для чтения вырос с ~300 ms до 4–6 s, тогда как доля ошибок осталась низкой. Одновременно панель базы показывает активные соединения близко к лимиту пула и рост ожиданий блокировок. CPU на нодах бэкенда в норме, значит, это не проблема вычислительной мощности.
Дальше вы выбираете один медленный запрос и идёте по логам. Фильтруете по эндпоинту (GET /orders) и сортируете по длительности. Берёте request_id из 6‑секундного запроса и ищете его по всем сервисам. Видно, что хендлер отработал быстро, но строка лога БД в том же request_id показывает 5.4‑секундный запрос с rows=50 и большим lock_wait_ms.
Теперь вы уверенно заявляете причину: замедление в пути БД (медленный запрос или конкуренция за блокировки), а не сеть или CPU бэкенда. Вот что даёт минимальная настройка: быстрое сужение области поиска.
Типичные исправления, по порядку безопасности:
- Добавить или скорректировать индекс для фильтра/сортировки на странице списка.
- Убрать N+1, объединив выборки связанных данных в один запрос или JOIN.
- Настроить пул соединений, чтобы не голодать по соединениям под нагрузкой.
- Добавлять кеш только для стабильных чтений и документировать правила инвалидирования.
Закройте цикл целевым оповещением. Пэйджить только тогда, когда p95 для группы эндпоинтов остаётся выше порога 10 минут и использование соединений БД выше, например, 80%. Такая комбинация уменьшает шум и ловит проблему раньше в следующий раз.
Следующие шаги: держите минимум, затем улучшайте по реальным инцидентам
Минимальная наблюдаемость должна казаться скучной в первый день. Если вы начинаете с слишком большого количества дашбордов и оповещений, вы будете их вечно перенастраивать и всё равно пропускать реальные проблемы.
Обращайтесь к каждому инциденту как к обратной связи. После фиксирования спросите: что бы позволило заметить и диагностировать это быстрее? Добавляйте только это.
Стандартизируйте заранее, даже если у вас сегодня один сервис. Используйте одни и те же имена полей в логах и метрики везде, чтобы новые сервисы автоматически соответствовали шаблону. Это делает дашборды повторно используемыми.
Небольшая дисциплина релизов быстро окупается:
- Добавляйте маркер деплоя (версия, окружение, commit/build ID), чтобы видеть, начались ли проблемы после релиза.
- Напишите короткий рукбук для топ‑3 оповещений: что это значит, какие первые проверки и кто отвечает.
- Держите «золотой» дашборд с основным набором метрик для каждого сервиса.
Если вы строите бэкенды с AppMaster, полезно заранее спланировать поля наблюдаемости и ключевые метрики до генерации сервисов, чтобы каждый новый API выходил с согласованными структурированными логами и health‑сигналами по умолчанию. Если хотите одно место, где начать такие бэкенды, AppMaster (appmaster.io) создан для генерации production‑готовых бэкендов, веба и мобильных приложений, сохраняя реализацию последовательной по мере изменения требований.
Выберите одно улучшение за раз, исходя из того, что действительно болит:
- Добавить тайминги запросов к базе (и логировать самые медленные запросы с контекстом).
- Уточнить оповещения так, чтобы они указывали на пользовательский эффект, а не на ресурс.
- Сделать один дашборд понятнее (переименовать графики, добавить пороги, убрать неиспользуемые панели).
Повторяйте этот цикл после каждого реального инцидента. За несколько недель у вас будет мониторинг, который подходит под нагрузку вашего CRUD‑приложения и трафик API, а не универсальный шаблон.
Вопросы и ответы
Начинайте внедрять наблюдаемость, когда проблемы в продакшне занимают больше времени на объяснение, чем на исправление. Если вы видите «случайные 500», медленные страницы списков или таймауты, которые не воспроизводятся локально, небольшой набор согласованных логов, метрик и оповещений сэкономит часы домыслов.
Monitoring говорит вам что не так, а наблюдаемость помогает понять почему это произошло, предоставляя контекстные сигналы, которые можно сопоставить. Для CRUD‑API практическая цель — быстрая диагностика: какой эндпоинт, какой пользователь/тенант и где именно было потрачено время — в приложении или в базе данных.
Начните с структурированных логов запросов, нескольких базовых метрик и пары оповещений, влияющих на пользователей. Трейсинг можно отложить для многих CRUD‑приложений, если вы уже логируете duration_ms, db_time_ms (или аналогичные) и стабильный request_id, по которому можно искать везде.
Используйте одно поле‑корреляцию вроде request_id и включайте его в каждую строку лога и каждое выполнение фоновой задачи. Генерируйте его на краю (API‑шлюз или первый handler), пробрасывайте через внутренние вызовы и убедитесь, что по этому ID можно быстро восстановить один медленный или упавший запрос.
Логируйте timestamp, level, service, env, route, method, status, duration_ms и безопасные идентификаторы вроде tenant_id или account_id. По умолчанию избегайте логирования персональных данных, токенов и полного тела запроса; если нужна детальная информация — логируйте её по требованию с редактированием.
Отслеживайте скорость запросов, долю 5xx, процентильные задержки (как минимум p50 и p95) и базовую насыщенность (CPU/память и нагрузка воркеров/очередей). Ранее добавьте время работы БД и использование пула соединений — многие сбои CRUD‑сервисов на деле оказываются проблемой базы данных или исчерпанием соединений.
Потому что именно хвостовые задержки чувствуют пользователи. Средние значения могут выглядеть нормально, в то время как p95 ужасен для значимой доли запросов — именно так экраны CRUD кажутся «случайно медленными» без явных ошибок.
Следите за частотой медленных запросов и процентилями времени выполнения, ожиданиями блокировок/deadlock, и использованием соединений относительно лимита пула. Эти сигналы показывают, является ли база узким местом и связаны ли проблемы с производительностью запросов, конкуренцией или нехваткой соединений под нагрузкой.
Начните с оповещений по симптомам пользователей: длительная повышенная доля 5xx, продолжительно высокая p95‑латентность и резкое падение успешных запросов. Добавляйте оповещения по причинам (например, почти исчерпан пул соединений) только после этого, чтобы сигнал для on‑call оставался надёжным и полезным.
Привязывайте метаданные версии/сборки к логам, панелям и оповещениям, и фиксируйте маркеры деплоя, чтобы видеть, когда были внесены изменения. Для генерируемых бэкендов (например, AppMaster‑generated Go‑сервисов) это особенно важно: регенерация и деплой происходят часто, и нужно быстро понять, началось ли регрессия после релиза.