03 окт. 2025 г.·6 мин
Курсорная и офсетная пагинация для быстрых API админ‑экранов
Изучите курсорную и офсетную пагинацию и согласованный контракт API для сортировки, фильтров и подсчётов, который сохраняет админ‑экраны быстрыми на вебе и в мобильных приложениях.
Почему пагинация может делать админ‑экраны медленными
Админские экраны часто начинаются как простая таблица: загрузить первые 25 строк, добавить поиск — готово. На небольших наборах данных всё кажется мгновенным. Но данные растут, и тот же экран начинает подтормаживать.
Обычно проблема не в UI. Проблема в том, что API должен сделать, прежде чем вернуть страницу 12 с применёнными сортировкой и фильтрами. По мере роста таблицы бэкенду требуется больше времени, чтобы найти подходящие записи, посчитать их и пропустить предыдущие результаты. Если каждый клик запускает более тяжёлый запрос, экран начинает «думать», а не отвечать.
Вы замечаете это в одних и тех же местах: переходы между страницами замедляются, сортировка становится вялой, поиск ведёт себя непоследовательно на разных страницах, а бесконечная прокрутка загружается резкими порциями (быстро, а затем резко медленнее). В загруженных системах можно даже увидеть дубликаты или пропавшие строки, когда данные меняются между запросами.
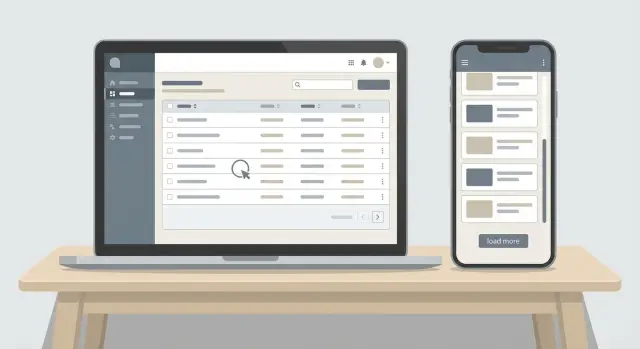
Веб‑ и мобильные интерфейсы тянут пагинацию в разные стороны. Веб‑таблица поощряет прыжки к конкретной странице и сортировку по многим колонкам. Мобильные экраны обычно используют бесконечный список, который загружает следующий кусок, и пользователи ожидают, что каждый подгруз будет одинаково быстрым. Если API построен только вокруг номеров страниц, мобильная часть часто страдает. Если же он построен только на next/after, веб‑таблицы могут выглядеть ограниченными.
Цель — не просто вернуть 25 элементов. Нужно обеспечить быструю и предсказуемую постраничную выдачу, которая остаётся стабильной по мере роста данных, с правилами, одинаковыми для таблиц и бесконечных списков.
Основы пагинации, от которых зависит UI
Пагинация — это разбиение длинного списка на более мелкие куски, чтобы экран мог быстро загрузить и отрисовать данные. Вместо того чтобы просить API вернуть все записи, UI запрашивает следующий срез результатов.
Самый важный параметр — размер страницы (часто называется limit). Меньшие страницы обычно кажутся быстрее, потому что серверу нужно меньше работы, а приложению — отрисовывать меньше строк. Но слишком маленькие страницы дают ощущение дергания, потому что пользователю приходится чаще нажимать или скроллить. Для многих админ‑таблиц практичный диапазон — 25–100 элементов, а мобильные интерфейсы обычно предпочитают нижний предел.
Стабильный порядок сортировки важнее, чем думают многие команды. Если порядок может меняться между запросами, пользователи увидят дубликаты или пропуски при листании. Стабильная сортировка обычно означает сортировку по основному полю (например, created_at) плюс tie‑breaker (например, id). Это важно как для офсетной, так и для курсорной пагинации.
С точки зрения клиента, ответ с пагинацией должен включать элементы, подсказку для следующей страницы (номер страницы или курсор) и только те подсчёты, которые действительно нужны UI. Некоторым экранам нужен точный итог для «1–50 из 12 340». Другим достаточно флага has_more.
Офсетная пагинация: как это работает и где болит
Офсетная пагинация — классический подход со страницей N. Клиент просит фиксированное число строк и говорит API, сколько строк пропустить сначала. Вы увидите это как limit и offset, или как page и pageSize, которые сервер переводит в офсет.
Типичный запрос выглядит так:
GET /tickets?limit=50&offset=950- «Дайте 50 тикетов, пропустив первые 950.»
Это соответствует распространённым потребностям админки: перейти на страницу 20, просмотреть старые записи или экспортировать большой список частями. Это также легко объяснить внутри команды: «Посмотрите страницу 3, и вы увидите её.»
Проблема проявляется на глубоких страницах. Многие СУБД всё ещё вынуждены проходить мимо пропущенных строк, прежде чем вернуть вашу страницу, особенно если порядок сортировки не покрыт тесным индексом. Первая страница может быть быстрой, но страница 200 заметно тормозит — и именно это делает админ‑экраны медленными, когда пользователи листают или прыгают.
Другой момент — согласованность при изменениях данных. Представьте, что менеджер поддержки открыл страницу 5 тикетов, отсортированных по новизне. Пока он смотрит, приходят новые тикеты или старые удаляются. Вставки могут сдвинуть элементы вперёд (дубликаты на соседних страницах). Удаления могут сдвинуть элементы назад (записи «исчезают» из просмотренного пути).
Офсетная пагинация подходит для небольших таблиц, стабильных данных или одноразовых экспортов. В больших активных таблицах краевые случаи проявляются быстро.
Курсорная пагинация: как она работает и почему остаётся стабильной
Курсорная пагинация использует курсор как закладку. Вместо «дайте страницу 7» клиент говорит «продолжите после этой точной записи». Курсор обычно кодирует сортировочные значения последнего элемента (например, created_at и id), чтобы сервер мог продолжить с нужного места.
Обычно запрос содержит просто:
limit: сколько элементов вернутьcursor: непрозрачный токен из предыдущего ответа (часто называется after)
В ответе возвращаются элементы и новый курсор, указывающий на конец этого среза. Практическая разница в том, что курсоры не просят базу считать и пропустить строки. Они просят начать с известной позиции.
Вот почему курсорная пагинация остаётся быстрой для списков с прокруткой вперёд. При хорошем индексе СУБД может перейти к "элементам после X" и прочитать следующие limit строк. При офсете сервер часто вынужден сканировать (или хотя бы пропускать) всё больше строк по мере роста офсета.
Для поведения UI курсорная пагинация делает «Далее» естественным: вы берёте возвращённый курсор и отправляете его в следующем запросе. «Назад» опционален и сложнее. Некоторые API поддерживают курсор before, другие читают в обратном порядке и переворачивают результаты.
Когда выбирать курсор, офсет или гибрид
Make admin screens feel instant
Создайте бэкенд для админки, который остаётся отзывчивым по мере роста данных.
Выбор начинается с того, как люди реально используют список.
Курсорная пагинация лучше всего подходит, когда пользователи в основном идут вперёд и важна скорость: логи активности, чаты, заказы, тикеты, журналы аудита и большинство мобильных бесконечных списков. Она также лучше ведёт себя при вставках и удалениях во время просмотра.
Офсетная пагинация имеет смысл, когда пользователи часто прыгают: классические админ‑таблицы с номерами страниц, переходом на конкретную страницу и частыми переключениями. Это просто объяснить, но на больших наборах данных она может тормозить и давать менее стабильные результаты при изменениях данных.
Практический способ принять решение:
- Выбирайте курсор, когда основное действие — «далее, далее, далее».
- Выбирайте офсет, когда «перейти на страницу N» — реальное требование.
- Считайте итоговые подсчёты опциональными. Точные подсчёты дорогие на огромных таблицах.
Гибриды встречаются часто. Один подход — курсорная навигация next/prev для скорости, плюс опциональный режим прыжка по страницам для небольших отфильтрованных подмножеств, где офсеты остаются быстрыми. Другой — курсорный доступ с номерами страниц, основанными на кэшированном снимке, чтобы интерфейс выглядел привычно, не превращая каждый запрос в тяжёлую операцию.
Согласованный контракт API, который работает на вебе и мобильных устройствах
Админ‑интерфейсы кажутся быстрее, когда каждый эндпоинт списка ведёт себя одинаково. UI может меняться (веб‑таблица с номерами страниц, мобильный бесконечный список), но контракт API должен оставаться стабильным, чтобы не приходилось заново изучать правила пагинации для каждого экрана.
Практичный контракт состоит из трёх частей: строки, состояние пагинации и опциональные итоги. Сохраняйте одинаковые имена полей на всех эндпоинтах (tickets, users, orders), даже если внутренний режим пагинации отличается.
Ниже — форма ответа, которая хорошо работает и для веба, и для мобильных:
{
"data": [ { "id": "...", "createdAt": "..." } ],
"page": {
"mode": "cursor",
"limit": 50,
"nextCursor": "...",
"prevCursor": null,
"hasNext": true,
"hasPrev": false
},
"totals": {
"count": 12345,
"filteredCount": 120
}
}
Пара деталей, которые упрощают повторное использование:
page.mode говорит клиенту, что делает сервер, не меняя имён полей.limit всегда — запрошенный размер страницы.nextCursor и prevCursor присутствуют даже если один из них равен null.totals — опционально. Если оно дорого, возвращайте только по запросу.
Веб‑таблица всё ещё может показывать «Страница 3», ведя собственный индекс страниц и вызывая API повторно. Мобильный список может игнорировать номера страниц и просто запрашивать следующий кусок.
Если вы строите веб и мобильные админ‑интерфейсы в AppMaster, стабильный контракт быстро окупается. То же поведение списка можно использовать в разных экранах без кастомной логики пагинации для каждого эндпоинта.
Правила сортировки, которые сохраняют стабильность пагинации
Change requirements safely
Безопасно менять требования: регенерируйте чистый исходный код без накопления техдолга.
Сортировка — место, где пагинация чаще всего ломается. Если порядок может измениться между запросами, пользователи увидят дубликаты, пропуски или «потерянные» строки.
Сделайте сортировку контрактом, а не рекомендацией. Публикуйте допустимые поля сортировки и направления и отклоняйте всё остальное. Это делает API предсказуемым и предотвращает запросы медленных сортировок, которые в разработке выглядели безобидно.
Стабильная сортировка требует уникального tie‑breaker. Если вы сортируете по created_at, и две записи имеют одинаковую метку времени, добавьте id (или другой уникальный столбец) в качестве последнего ключа сортировки. Без этого база может возвращать равные значения в любом порядке.
Практические правила, которые работают:
- Разрешайте сортировку только по индексированным, чётко определённым полям (например,
created_at, updated_at, status, priority).
- Всегда добавляйте уникальный tie‑breaker как финальный ключ (например,
id ASC).
- Определите сортировку по умолчанию (например,
created_at DESC, id DESC) и соблюдайте её между клиентами.
- Документируйте поведение при NULL (например, «nulls last» для дат и чисел).
Сортировка также определяет генерацию курсора. Курсор должен кодировать значения сортировки последнего элемента в порядке их применения, включая tie‑breaker, чтобы следующая страница могла запросить «after» этот кортеж. Если сортировка меняется, старые курсоры становятся недействительными. Считайте параметры сортировки частью контракта курсора.
Фильтры и итоги без нарушения контракта
Фильтры должны быть независимы от пагинации. UI говорит «покажи другой набор строк», и только затем запрашивает «листай по этому набору». Если смешивать поля фильтра в токене пагинации или делать фильтры необязательными и невалидированными, вы получите трудноотлаживаемое поведение: пустые страницы, дубликаты или курсор, который вдруг указывает в другой набор данных.
Простое правило: фильтры живут в обычных параметрах запроса (или в теле POST), а курсор — непрозрачен и действителен только для точной комбинации фильтров и сортировки. Если пользователь меняет любой фильтр (status, диапазон дат, assignee), клиент должен отбросить старый курсор и начать сначала.
Будьте строги в отношении допустимых фильтров. Это защищает производительность и делает поведение предсказуемым:
- Отклоняйте неизвестные поля фильтра (не игнорируйте их молча).
- Валидируйте типы и диапазоны (даты, enum‑ы, ID).
- Лимитируйте широкие фильтры (например, максимум 50 ID в
IN).
- Применяйте одни и те же фильтры к данным и к подсчётам (без рассинхронизации чисел).
Итоги — место, где многие API тормозят. Точные подсчёты могут быть дорогими на больших таблицах, особенно с множественными фильтрами. Обычно есть три варианта: точный, оценочный или без подсчёта. Точный полезен для небольших наборов или когда пользователю действительно нужно «1–25 из 12 431». Оценка часто достаточна для админских экранов. Отсутствие подсчётов подходит, когда нужен только «Загрузить ещё».
Чтобы не замедлять каждый запрос, делайте totals опциональным: вычисляйте их только по запросу (например, флаг includeTotal=true), кешируйте недолго по набору фильтров или возвращайте totals только на первой странице.
По шагам: проектируем и реализуем эндпоинт
Fix pagination edge cases
Продумайте фильтры, правила сортировки и защитные меры, чтобы интерфейс перестал видеть дубликаты.
Начните с дефолтов. Эндпоинт списка нуждается в стабильном порядке сортировки и tie‑breaker для строк, которые имеют одинаковое значение. Например: createdAt DESC, id DESC. Tie‑breaker (id) предотвращает дубликаты и разрывы при добавлении новых записей.
Определите одну форму запроса и держите её простой. Типичные параметры: limit, cursor (или offset), sort и filters. Если вы поддерживаете оба режима, сделайте их взаимоисключающими: клиент либо отправляет cursor, либо offset, но не оба сразу.
Сохраняйте единый ответ, чтобы веб и мобильные клиенты могли использовать одну логику списка:
items: страница записейnextCursor: курсор для следующей страницы (или null)hasMore: булево, чтобы UI решил, показывать ли «Загрузить ещё»total: общее число совпадающих записей (null, если подсчёт дорогой и не запрошен)
Реализация — место, где подходы расходятся.
Офсетные запросы обычно выглядят как ORDER BY ... LIMIT ... OFFSET ..., что замедляется на больших таблицах.
Курсорные запросы используют условия поиска по последнему элементу: «верните элементы, где (createdAt, id) меньше последнего (createdAt, id)». Это держит производительность стабильнее, потому что СУБД может использовать индексы.
Перед выпуском добавьте защитные меры:
- Ограничьте
limit (например, максимум 100) и установите дефолт.
- Валидируйте
sort по allowlist.
- Валидируйте фильтры по типу и отклоняйте неизвестные ключи.
- Делайте
cursor непрозрачным (кодируйте последние значения сортировки) и отклоняйте плохие курсоры.
- Решите, как запрашивается
total.
Тестируйте с изменяющимися данными. Создавайте и удаляйте записи между запросами, обновляйте поля, влияющие на сортировку, и проверяйте, что не появляются дубликаты и пропуски.
Пример: список тикетов, который остаётся быстрым на вебе и мобильных
Cursor paging without complexity
Реализуйте логики курсорной пагинации визуально с drag-and-drop бизнес-процессами.
Команда поддержки открывает админ‑экран, чтобы просматривать самые новые тикеты. Ей нужно, чтобы список казался мгновенным, даже когда приходят новые тикеты и агенты обновляют старые.
В веб‑версии UI — таблица. Сортировка по умолчанию — updated_at (сначала новые), команда часто фильтрует по Open или Pending. Тот же эндпоинт может поддерживать оба сценария с устойчивой сортировкой и курсорным токеном.
GET /tickets?status=open&sort=-updated_at&limit=50&cursor=eyJ1cGRhdGVkX2F0IjoiMjAyNi0wMS0yNVQxMTo0NTo0MloiLCJpZCI6IjE2OTMifQ==
Ответ остаётся предсказуемым для UI:
{
"items": [{"id": 1693, "subject": "Login issue", "status": "open", "updated_at": "2026-01-25T11:45:42Z"}],
"page": {"next_cursor": "...", "has_more": true},
"meta": {"total": 128}
}
На мобильном телефоне тот же эндпоинт питает бесконечную прокрутку. Приложение грузит по 20 тикетов, затем отправляет next_cursor, чтобы получить следующий блок. Никакой логики с номерами страниц, и меньше сюрпризов при изменениях записей.
Ключ в том, что курсор кодирует последнюю увиденную позицию (например, updated_at плюс id как tie‑breaker). Если тикет обновляется пока агент прокручивает, он может переместиться вверх при следующем обновлении, но это не вызовет дубликатов или пропусков в уже прокрученном фиде.
Итоги полезны, но дороги на больших наборах. Простое правило — возвращать meta.total только когда пользователь применил фильтр (например, status=open) или явно попросил его.
Частые ошибки, которые приводят к дубликатам, пропускам и лагам
Большинство багов пагинации не в базе. Они происходят из небольших решений в API, которые выглядят нормальными в тестах, но разваливаются, когда данные меняются между запросами.
Самая частая причина дубликатов (или пропавших строк) — сортировка по полю, которое не уникально. Если сортировать по created_at и две записи имеют одинаковую метку времени, порядок может меняться между запросами. Решение простое: всегда добавляйте стабильный tie‑breaker, обычно первичный ключ, и рассматривайте сортировку как пару, например (created_at desc, id desc).
Ещё одна распространённая проблема — позволять клиентам запрашивать любой размер страницы. Один большой запрос может поднять загрузку CPU, память и время ответа, что замедлит все админ‑экраны. Выберите разумный дефолт и жёсткий максимум и возвращайте ошибку, если клиент просит больше.
Итоги тоже могут навредить. Подсчёт всех совпадающих строк при каждом запросе может стать самым медленным элементом эндпоинта, особенно с фильтрами. Если UI нужен total, запрашивайте его только по требованию (или возвращайте оценку), и не блокируйте скролл полным подсчётом.
Ошибки, наиболее часто приводящие к проблемам:
- Сортировка без уникального tie‑breaker (нестабильный порядок)
- Неограниченные размеры страниц (перегрузка сервера)
- Возврат totals при каждом запросе (медленные запросы)
- Смешивание правил offset и cursor в одном эндпоинте (путает клиента)
- Повторное использование курсора при изменении фильтров или сортировки (неправильные результаты)
Сбрасывайте пагинацию при каждом изменении фильтров или сортировки. Рассматривайте новый фильтр как новый поиск: очистите курсор/offset и начните с первой страницы.
Быстрый чеклист перед релизом
Ship the backend first
Смоделируйте данные в PostgreSQL и сгенерируйте production-ready бэкенд на Go.
Пройдитесь по этому списку вместе с API и UI. Большинство проблем происходит в контракте между экраном списка и сервером.
- Сортировка по умолчанию стабильна и включает уникальный tie‑breaker (например,
created_at DESC, id DESC).
- Поля сортировки и направления находятся в белом списке.
- Есть максимальный размер страницы и разумный дефолт.
- Курсорные токены непрозрачны, и некорректные курсоры обрабатываются предсказуемо.
- Любое изменение фильтра или сортировки сбрасывает состояние пагинации.
- Поведение с totals явно: точный, оценочный или пропущенный.
- Один и тот же контракт поддерживает и таблицу, и бесконечный скролл без специальных случаев.
Следующие шаги: стандартизируйте списки и сохраняйте их консистентность
Выберите один список админки, которым люди пользуются ежедневно, и сделайте его золотым стандартом. Занятная таблица вроде Tickets, Orders или Users — хорошая отправная точка. Как только этот эндпоинт станет быстрым и предсказуемым, примените тот же контракт ко всем остальным спискам.
Запишите контракт, даже кратко. Ясно укажите, что API принимает и что он возвращает, чтобы команда UI не гадала и не придумывала разные правила для каждого эндпоинта.
Простой стандарт для каждого эндпоинта списка:
- Разрешённые сортировки: точные имена полей, направление и явный дефолт (плюс tie‑breaker типа
id).
- Разрешённые фильтры: какие поля можно фильтровать, форматы значений и поведение при невалидных фильтрах.
- Поведение с totals: когда возвращать count, когда возвращать «неизвестно» и когда пропускать.
- Форма ответа: единые ключи (
items, информация о пагинации, применённые sort/filters, totals).
- Правила ошибок: предсказуемые коды статуса и понятные сообщения валидации.
Если вы строите админские экраны с AppMaster (appmaster.io), полезно стандартизировать контракт пагинации на ранней стадии. Так одно и то же поведение списка можно будет переиспользовать в веб‑ и нативных мобильных приложениях, и вы потратите меньше времени на исправление краевых случаев пагинации.
Вопросы и ответы
Offset-пагинация использует limit плюс offset (или page/pageSize) чтобы пропустить строки, поэтому на глубоких страницах база часто становится медленнее, так как нужно пройтись по большему числу записей. Курсорная пагинация использует токен after, основанный на значениях сортировки последнего элемента, благодаря чему сервер может перейти к известной позиции и оставаться быстрым по мере движения вперёд.
Потому что первая страница обычно дешёвая, а, например, страница 200 требует, чтобы СУБД пропустила огромное количество строк прежде чем вернуть результат. Если к тому же идут сортировка и фильтры, объём работы растёт, и каждый клик начинает ощущаться как тяжёлый запрос.
Всегда используйте стабильную сортировку с уникальным дополнительным ключом, например created_at DESC, id DESC или updated_at DESC, id DESC. Без такого tie-breaker записи с одинаковыми метками времени могут менять порядок между запросами — это частая причина дубликатов и «пропавших» строк.
Предпочитайте курсорную пагинацию для списков, где люди в основном движутся вперёд и важна скорость: логи активности, тикеты, заказы и мобильный infinite scroll. Она остаётся последовательной при вставках или удалениях, потому что курсор фиксирует точную последнюю увиденную позицию.
Офсетная пагинация имеет смысл, когда в интерфейсе реально нужна возможность «перейти на страницу N» и пользователи часто прыгают между страницами. Также она удобна для небольших таблиц или стабильных наборов данных, где замедление на глубоких страницах и сдвиги результатов маловероятны.
Единообразная форма ответа помогает переиспользовать клиентскую логику. Включайте items, объект page (с limit, nextCursor/prevCursor или offset) и лёгкий флаг типа hasNext, чтобы и веб-таблицы, и мобильные списки могли использовать один и тот же код.
Точный COUNT(*) по большим отфильтрованным таблицам может стать самым медленным компонентом запроса и замедлить смену страниц. Безопасный подход — делать подсчёт опциональным: возвращать только по запросу, отдавать оценку или вместо точного числа возвращать has_more когда нужен только «Загрузить ещё».
Считайте фильтры частью набора данных, а курсор — действительным только для точной комбинации фильтров и сортировки. При любом изменении фильтра или сортировки клиент должен сбросить старый курсор и начинать с первой страницы; повторное использование старого курсора после изменений — частая причина пустых страниц и странного поведения.
Ограничьте поля сортировки белым списком и отклоняйте всё остальное, чтобы клиенты не могли случайно запросить медленную или нестабильную сортировку. Предпочитайте сортировку по индексированным полям и всегда добавляйте уникальный tie-breaker, например id, чтобы порядок был детерминирован.
Вводите ограничение на limit, валидируйте фильтры и параметры сортировки, делайте курсоры непрозрачными и строго проверяемыми. Если вы используете AppMaster, единообразие этих правил на всех эндпоинтах списков упрощает поддержку и повторное использование поведения таблиц и бесконечных списков.