14 апр. 2025 г.·6 мин
Индексация для админ-панелей: сначала оптимизируйте самые важные фильтры
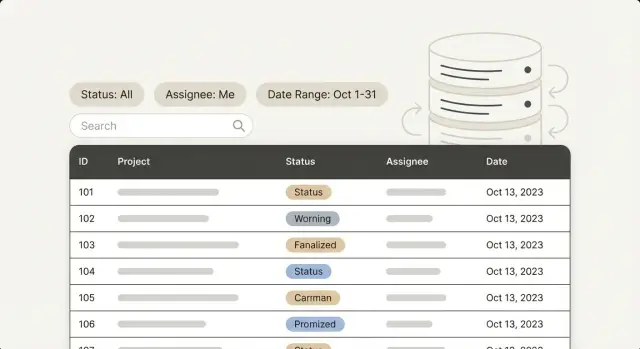
Индексация для админ-панелей: оптимизируйте фильтры, которыми пользуются чаще всего — статус, исполнитель, диапазоны дат и текстовый поиск — исходя из реальных шаблонов запросов.
Почему фильтры в админ-панели становятся медленными
Админ-панели обычно сначала кажутся быстрыми. Вы открываете список, листаете, кликаете запись и идёте дальше. Замедление появляется, когда люди фильтруют так, как они реально работают: "Только открытые тикеты", "Назначено Майе", "Создано на прошлой неделе", "Order ID содержит 1047". Каждый клик вызывает ожидание, и список начинает ощущаться «липким».
Одна и та же таблица может быть быстрой для одного фильтра и болезненно медленной для другого. Фильтр по статусу может затронуть небольшой кусок строк и вернуть результат быстро. Фильтр «создано между двумя датами» может заставить базу прочитать огромный диапазон. Фильтр по исполнителю может быть нормальным сам по себе, но замедляться, когда вы комбинируете его со статусом и сортировкой.
Индексы — это сокращения, которыми база пользуется, чтобы найти подходящие строки без чтения всей таблицы. Но индексами всё не решишь. Они занимают место и делают вставки и обновления чуть медленнее. Добавлять слишком много индексов — значит замедлить записи и при этом не устранить реальную узкую точку.
Вместо индексирования всего подряд приоритизируйте фильтры, которые:
- используются постоянно
- затрагивают много строк
- создают заметное ожидание
- могут быть улучшены простыми, хорошо подобранными индексами
Здесь сознательно узкий фокус. Первые жалобы на производительность в списках админки почти всегда связаны с четырьмя типами фильтров: статус, исполнитель, диапазоны дат и текстовые поля. Как только вы поймёте, почему они ведут себя по-разному, следующие шаги очевидны: смотрите реальные паттерны запросов, добавляйте минимальный индекс, который им соответствует, и проверяйте, что вы ускорили медленный путь, не создав новых проблем.
Паттерны запросов за реальной административной работой
Админ-панели редко тормозят из-за одного гигантского отчёта. Обычно они становятся медленными, потому что несколько экранов используются весь день, и эти экраны запускают много небольших запросов снова и снова.
Операционные команды обычно живут в нескольких рабочих очередях: тикеты, заказы, пользователи, approvals, внутренние запросы. На этих страницах фильтры повторяются:
- Статус, потому что он отражает рабочий процесс (New, Open, Pending, Done)
- Исполнитель, потому что командам нужны «мои элементы» и «не назначено»
- Диапазоны дат, потому что кто-то всегда спрашивает «что произошло на прошлой неделе?»
- Поиск — чтобы прыгнуть к известному элементу (номер заказа, email) или пробежаться по тексту (заметки, превью)
Работа базы зависит от намерения:
- Просмотр новейших — это шаблон сканирования. Обычно выглядит как "показать последние элементы, возможно суженные по статусу, отсортированные по времени создания" и пагинированный.
- Найти конкретный элемент — это шаблон поиска. Админ уже знает ID, email, номер тикета или ссылку и ожидает, что база сразу перейдёт к небольшому набору строк.
Админ-панели также предсказуемо комбинируют фильтры: "Open + Unassigned", "Pending + Assigned to me" или "Completed за последние 30 дней". Индексы работают лучше, когда они соответствуют этим реальным формам запросов, а не просто списку колонок.
Если вы строите админ-инструменты в AppMaster, эти паттерны обычно видны, если посмотреть на самые используемые экраны списков и их дефолтные фильтры. Это облегчает индексацию того, что реально двигает ежедневную работу, а не того, что красиво звучит на бумаге.
Как выбрать, что индексировать в первую очередь
Относитесь к индексированию как к сортировке по приоритетам. Не начинайте с индексирования каждой колонки, которая есть в выпадающем списке фильтров. Начните с тех запросов, которые выполняются постоянно и раздражают людей больше всего.
Найдите фильтры, которые реально используют люди
Оптимизировать фильтр, которым никто не пользуется, — пустая трата времени. Чтобы найти настоящие «горячие пути», комбинируйте сигналы:
- Аналитика UI: какие экраны просматриваются чаще всего, какие фильтры кликают чаще
- Логи базы или API: наиболее частые запросы и самые медленные проценты
- Внутренние отзывы: «поиск медленный» обычно указывает на один конкретный экран
- Дефолтовый список: что выполняется, как только админ открывает панель
Во многих командах дефолтовый вид похож на "Open tickets" или "New orders". Он выполняется каждый раз при обновлении, переключении вкладок или возврате после ответа.
Группируйте запросы по форме, а не по имени поля
Прежде чем добавлять индекс, сгруппируйте распространённые запросы по тому, как они ведут себя. Большинство админских запросов попадает в несколько корзин:
- Фильтры по равенству:
status = 'open', assignee_id = 42
- Диапазонные фильтры:
created_at между двумя датами
- Сортировка и пагинация:
ORDER BY created_at DESC и получение страницы 2
- Текстовые поиска: точное совпадение (номер заказа), префиксный поиск (email начинается с), или contains-поиск
Запишите форму для каждого топового экрана, включая WHERE, ORDER BY и пагинацию. Два запроса, похожих в UI, могут вести себя очень по-разному в базе.
Выберите небольшую первую партию
Начните с одной приоритетной цели: дефолтового запроса списка, который загружается первым. Затем выберите ещё 2–3 частых запроса. Обычно этого достаточно, чтобы убрать основные задержки, не превратив базу в музей индексов.
Пример: служба поддержки открывает список Tickets, отфильтрованный по status = 'open', отсортированный по новизне, с опциональным исполнителем и диапазоном дат. Оптимизируйте именно эту комбинацию сначала. После того как она станет быстрой, переходите к следующему экрану по частоте использования.
Индексация фильтра по статусу без излишков
Статус — один из первых фильтров, которые добавляют, и один из самых простых для некорректной индексации.
Большинство полей статуса имеют низкую кардинальность: всего несколько значений (open, pending, closed). Индекс помогает, когда он действительно сужает результаты до небольшой части таблицы. Если 80–95% строк имеют одинаковый статус, индекс только по status часто мало что даёт. База всё равно должна прочитать большой кусок строк, а индекс добавляет накладные расходы.
Польза обычно видна, когда:
- один статус редок (например, escalated)
- статус комбинируется с другим условием, которое ужимает результат
- статус плюс сортировка совпадают с часто используемым видом списка
Обычный паттерн — "показать открытые элементы, по новизне". В таком случае индекс, покрывающий и фильтр, и сортировку, часто выигрывает по сравнению с индексом только по status.
Комбинации, которые чаще приносят пользу в первую очередь:
status + updated_at (фильтрация по статусу, сортировка по недавним изменениям)status + assignee_id (виды рабочих очередей)status + updated_at + assignee_id (только если этот точный вид очень часто используется)
Частичные индексы — хороший компромисс, когда один статус доминирует. Если «open» — основной вид, индексируйте только open-строки. Индекс остаётся меньше, а стоимость записи снижается.
-- PostgreSQL example: index only open rows, optimized for newest-first lists
CREATE INDEX CONCURRENTLY tickets_open_updated_idx
ON tickets (updated_at DESC)
WHERE status = 'open';
Практический тест: запустите медленный админ-запрос с фильтром по статусу и без него. Если он медленный в обоих случаях, индекс только по статусу не спасёт. Сосредоточьтесь на сортировке и втором фильтре, который действительно сжимает список.
Фильтрация по исполнителю: индексы для равенства и распространённые сочетания
Правильно построенный поиск
Выпустите админ-интерфейс, который поддерживает точные поиски и контролируемый текстовый поиск с первого дня.
В большинстве админ-панелей исполнитель — это ID пользователя, хранящийся в записи: внешняя ссылка вроде assignee_id. Это классический фильтр по равенству, и простой индекс часто даёт быстрый выигрыш.
При этом исполнителя часто комбинируют с другими фильтрами, поскольку так команда работает. Руководитель поддержки может фильтровать «Назначено Алексу», затем сузить до «Open», чтобы увидеть, что осталось сделать. Если такой вид медленный, зачастую нужен не одинарный индекс.
Хорошее начало — составной индекс, который соответствует обычной комбинации:
(assignee_id, status) для «мои открытые элементы»(assignee_id, status, updated_at) если список также сортируется по недавней активности
Порядок имеет значение в составных индексах. Ставьте фильтры по равенству первыми (обычно assignee_id, затем status), а столбец для сортировки или диапазона — последним (updated_at). Это соответствует тому, как база может эффективно использовать индекс.
Неназначенные элементы — частая подлянка. Многие системы представляют «unassigned» как NULL в assignee_id, и менеджеры часто фильтруют по этому. В зависимости от базы и формы запроса NULL может поменять план выполнения так, что индекс, отлично работающий для назначенных, бесполезен для неназначенных.
Если unassigned — важная рабочая очередь, выберите ясный подход и протестируйте его:
- Оставьте
assignee_id nullable, но убедитесь, что WHERE assignee_id IS NULL протестирован и индексирован, если нужно.
- Используйте специального «Unassigned» пользователя, только если это подходит модели данных.
- Добавьте частичный индекс для неназначенных строк, если база поддерживает это.
Если вы строите админ-панель в AppMaster, полезно логировать точные фильтры и сортировки, которые команда использует, и затем зеркалировать эти паттерны небольшим набором хороших индексов вместо индексирования каждого доступного поля.
Диапазоны дат: индексы, соответствующие тому, как люди фильтруют
Преобразуйте фильтры в реальные экраны
Смоделируйте таблицы в PostgreSQL и выпустите списки, которые соответствуют тому, как команды реально работают.
Фильтры по дате чаще всего выглядят как быстрые пресеты типа «последние 7 дней» или «последние 30 дней», плюс пользовательский выбор начала и конца. Они просты на вид, но на больших таблицах могут вызвать очень разную работу базы.
Сначала четко определите, о каком столбце времени идёт речь. Используйте:
created_at для видов «новые элементы»updated_at для видов «недавно изменённые»
Поставьте обычный btree-индекс на этот столбец. Без него каждый клик «последние 30 дней» может превратиться в полный скан таблицы.
Пресеты часто выглядят как created_at >= now() - interval '30 days'. Это условие диапазона, и индекс по created_at может использоваться эффективно. Если UI также сортирует по новизне, совпадение направления сортировки (например, created_at DESC в PostgreSQL) может помочь на сильно нагруженных списках.
Когда диапазоны по дате комбинируются с другими фильтрами (status, assignee), будьте избирательны. Составные индексы хороши, когда комбинация частая. Иначе они добавляют стоимость записи без отдачи.
Практические правила:
- Если большинство видов сначала фильтруют по статусу, а затем по дате,
(status, created_at) может помочь.
- Если статус опционален, а дата есть всегда, держите простой индекс по
created_at и избегайте множества составных индексов.
- Не создавайте все возможные комбинации. Каждый новый индекс увеличивает хранение и замедляет записи.
Часовой пояс и границы дат — частая причина багов с «пропущенными записями». Если пользователи выбирают даты (без времени), решите, как интерпретировать конечную дату. Надёжный паттерн — включающий старт и исключающий конец: created_at >= start и created_at < end_next_day. Храните метки времени в UTC и переводите пользовательский ввод в UTC перед запросом.
Пример: админ выбирает 10–12 января и ожидает увидеть элементы за весь 12 января. Если ваш запрос использует <= '2026-01-12 00:00', вы пропустите почти всё за 12 января. Проблема не в индексе, а в логике границ.
Текстовые поля: точный поиск против contains-поиска
Текстовый поиск — место, где многие админ-панели тормозят, потому что ожидают, что одно поле найдёт всё. Первое исправление — разделить две потребности: точное совпадение (быстро и предсказуемо) и contains-поиск (гибкий, но тяжёлый).
Точные совпадения включают order ID, ticket number, email, телефон или внешний референс. Они идеально подходят для обычных индексов. Если админы часто вставляют ID или email, простой индекс и = сделают поиск мгновенным.
Contains-поиск — когда кто-то вводит фрагмент вроде «refund» или «john» и ожидает совпадения в именах, заметках и описаниях. Часто это реализуют как LIKE %term%. Ведущий подстановочный знак делает обычный btree-индекс бесполезным, и база сканирует много строк.
Практичный путь к поиску без перегрузки базы:
- Сделайте точный поиск первоклассным (ID, email, username) и явно обозначьте его.
- Для «начинается с» (
term%) стандартный индекс часто помогает и обычно достаточно для имён.
- Добавляйте contains-поиск только если логи или жалобы показывают необходимость.
- При добавлении использования contains-поиска выбирайте правильный инструмент (PostgreSQL full-text или триграммные индексы), а не надейтесь, что обычный индекс исправит
LIKE %term%.
Правила обработки ввода важнее, чем многие думают. Они снижают нагрузку и делают результаты консистентными:
- Установите минимальную длину для contains-поиска (например, 3+ символа).
- Нормализуйте регистр или используйте сравнения без учета регистра.
- Обрезайте пробелы и уменьшайте повторяющиеся пробелы.
- Обрабатывайте emails и ID как точные по умолчанию, даже если их вводят в общее поле поиска.
- Если термин слишком широкий, предложите уточнить запрос вместо запуска тяжёлого запроса.
Небольшой пример: менеджер поддержки ищет «ann». Если система выполняет LIKE %ann% по заметкам, именам и адресам, она может просканировать тысячи записей. Если сначала проверять точные поля (email или ID клиента), а затем уже падать на умный текстовый индекс при необходимости, поиск остаётся быстрым, не превращая каждый запрос в тяжёлую работу для БД.
Пошаговый рабочий процесс добавления индексов безопасно
Разворачивайте там, где нужно
Деплойте админ-инструменты в нужное облако или экспортируйте исходный код для self-hosting.
Индексы легко добавить и легко пожалеть о них. Безопасный рабочий процесс держит фокус на фильтрах, от которых зависят админы, и помогает избегать «может быть полезных» индексов, которые потом замедлят записи.
Начните с реального использования. Вытяните топ-запросы двумя способами:
- самые частые запросы
- самые медленные запросы
Для админ-панелей это обычно страницы списков с фильтрами и сортировками.
Далее зафиксируйте форму запроса так, как её видит база. Запишите точные WHERE и ORDER BY, включая направление сортировки и частые комбинации (например: status = 'open' AND assignee_id = 42 ORDER BY created_at DESC). Маленькие отличия могут изменить, какой индекс поможет.
Используйте простой цикл:
- Выберите один медленный запрос и одну индексацию для попытки.
- Добавьте или измените один индекс.
- Перезамерьте с теми же фильтрами и той же сортировкой.
- Проверьте, не стали ли вставки и обновления заметно медленнее.
- Оставляйте изменение только если оно явно улучшает целевой запрос.
Пагинация заслуживает отдельной проверки. Пагинация по смещению (OFFSET 20000) часто тормозит глубже в результатах, даже с индексами. Если пользователи регулярно ходят по очень глубоким страницам, рассмотрите курсорную пагинацию ("показать элементы до этой метки времени/id"), чтобы индекс выполнял стабильную работу на больших таблицах.
Наконец, ведите короткую запись, чтобы через месяцы список индексов оставался понятным: имя индекса, таблица, колонки (и порядок) и запрос, который он поддерживает.
Частые ошибки индексации в админ-панелях
Создайте панель администрирования быстрее
Создайте быструю панель администрирования с реальными рабочими процессами, фильтрацией и пагинацией за считанные минуты.
Самый быстрый способ сделать админ-панель медленной — добавлять индексы, не проверяя, как люди реально фильтруют, сортируют и листают результаты. Индексы стоят места и добавляют работу каждой вставке и обновлению.
Ошибки, которые встречаются чаще всего
Эти паттерны вызывают большинство проблем:
- Индексирование каждой колонки «на всякий случай».
- Создание составного индекса с неправильным порядком колонок.
- Игнорирование сортировки и пагинации.
- Ожидание, что обычный индекс исправит
LIKE '%term%'.
- Оставление старых индексов после изменений в UI.
Типичный сценарий: команда фильтрует тикеты по Status = Open, сортирует по времени обновления и листает страницы. Если вы добавите индекс только по status, базе всё равно придётся собрать все открытые тикеты и отсортировать их. Индекс, совпадающий с фильтром и сортировкой одновременно, вернёт первую страницу быстро.
Быстрые проверки, чтобы поймать проблемы
Перед и после изменений в UI выполните короткий обзор:
- Перечислите топ-фильтры и дефолтовую сортировку, затем подтвердите, что есть индекс, соответствующий паттерну
WHERE + ORDER BY.
- Проверьте ведущие подстановочные знаки (
LIKE '%term%') и решите, нужен ли вообще contains-поиск.
- Ищите дублирующиеся или накладывающиеся индексы.
- Отслеживайте неиспользуемые индексы некоторое время, затем удаляйте их, когда уверены, что они не нужны.
Если вы строите админ-экраны в AppMaster на PostgreSQL, делайте этот обзор частью релиза новых экранов. Правильные индексы обычно вытекают прямо из фильтров и порядков сортировки, которые использует UI.
Быстрые проверки и следующие шаги
Прежде чем добавлять больше индексов, убедитесь, что существующие действительно помогают тем фильтрам, которые люди используют каждый день. Хорошая админ-панель ощущается мгновенной на частых путях, а не на редких одноразовых поисках.
Пара проверок, которые ловят большинство проблем:
- Откройте самые частые комбинации фильтров (status, assignee, диапазон дат и дефолтовая сортировка) и подтвердите, что они остаются быстрыми по мере роста таблицы.
- Для каждого медленного вида убедитесь, что запрос использует индекс, который соответствует и
WHERE, и ORDER BY, а не только одной части.
- Держите список индексов таким, чтобы можно было объяснить назначение каждого в одном предложении.
- Следите за операциями, тяжёлыми по записи (create, update, смена статуса). Если они замедлились после добавления индексов, возможно, индексов слишком много или они перекрываются.
- Решите, что означает "поиск" в вашем UI: точное совпадение, префикс или contains. План индексации должен соответствовать этому выбору.
Практический следующий шаг — записать ваши «золотые пути» простыми предложениями, например: "Агенты поддержки фильтруют открытые тикеты, назначенные мне, за последние 7 дней, отсортированные по новизне." Используйте эти предложения, чтобы спроектировать небольшой набор индексов, которые явно их поддерживают.
Если вы ещё на ранней стадии, полезно смоделировать данные и дефолтовые фильтры до того, как вы создадите слишком много экранов. С AppMaster (appmaster.io) вы можете быстро итеративно создавать админ-виды, а затем добавить несколько индексов, которые соответствуют реальным горячим путям, когда они станут очевидны.
Вопросы и ответы
Начните с запросов, которые выполняются постоянно: дефолтовый список, который видит админ при открытии, плюс 2–3 фильтра, которыми пользуются чаще всего. Измерьте частоту и «боль» (самые медленные и часто используемые), затем индексируйте только то, что явно сокращает время ожидания для этих конкретных форм запросов.
Потому что разные фильтры заставляют базу данных выполнить разный объём работы. Некоторые фильтры сужают набор до небольшого числа строк, другие охватывают большой диапазон или требуют сортировки большого результата — поэтому один запрос может эффективно использовать индекс, а другой всё равно выполнить много чтений и сортировок.
Не обязательно. Если большинство строк имеют один и тот же статус, индекс только по status редко улучшит ситуацию. Индекс полезен, когда статус редок, или когда вы индексируете статус вместе с сортировкой или другим фильтром, который действительно сокращает результат.
Используйте составной индекс, соответствующий реальному виду: фильтрация по status и сортировка по недавним изменениям. В PostgreSQL частичный индекс может быть хорошим решением, если один статус доминирует — индекс остаётся маленьким и сфокусированным на основном сценарии.
Простой индекс по assignee_id часто даёт быстрый выигрыш, потому что это фильтр на равенство. Если «мои открытые задачи» — ключевой сценарий, составной индекс, который начинается с assignee_id, затем включает status (и опционно столбец сортировки), обычно работает лучше, чем набор одиночных индексов.
Unassigned часто хранится как NULL, и WHERE assignee_id IS NULL может выполняться иначе, чем WHERE assignee_id = 123. Если очереди «unassigned» важны, протестируйте этот запрос отдельно и выберите стратегию индексации, например частичный индекс для неназначенных строк, если база поддерживает это.
Добавьте btree-индекс на тот временной столбец, который люди фактически фильтруют — обычно created_at для «новых» и updated_at для «недавно изменённых». Без такого индекса каждый клик «последние 30 дней» может превратиться в полный просмотр таблицы. Если UI сортирует по новизне, совпадение направления сортировки (created_at DESC) может помочь на нагруженных списках.
Большинство проблем с отсутствующими записями — не про индексы, а про границы дат. Надёжный подход: включающий старт и исключающий конец — created_at >= start и created_at < end_next_day. Храните метки времени в UTC и переводите пользовательские даты в UTC перед запросом.
Потому что LIKE %term% с ведущим и/или конечным подстановочным знаком не может эффективно использовать обычный btree-индекс, и база сканирует много строк. Сделайте точные поиски (ID, email, номер заказа) быстрым отдельным путём, а для полнотекстного или «contains» поиска используйте инструменты вроде PostgreSQL full-text или триграммных индексов.
Нет. Много индексов увеличивают объём хранения и замедляют вставки и обновления, и индекс всё равно может не помогать, если он не соответствует паттерну WHERE + ORDER BY. Безопасный цикл: поменять один индекс, переизмерить конкретный медленный запрос и хранить только те изменения, которые явно улучшают горячий путь.
Если вы строите админ-экраны в AppMaster, логируйте точные фильтры и сортировки, которые ваша команда использует чаще всего, и добавляйте небольшой набор индексов, отражающих эти реальные представления, вместо индексирования всех доступных полей.