27 нояб. 2025 г.·7 мин
Долговременные воркфлоу: повторы, dead-letter и видимость
Долговременные воркфлоу могут ломаться сложно. Узнайте про понятные состояния, счётчики повторов, обработку dead‑letter и дашборды, которым операторы доверяют.
Что ломается в долговременной автоматизации
Долговременные воркфлоу ломаются иначе, чем быстрые запросы. Короткий API‑вызов либо сразу успешен, либо сразу возвращает ошибку. Воркфлоу, который работает часы или дни, может пройти 9 из 10 шагов и всё равно оставить беспорядок: полусозданные записи, запутанный статус и отсутствие ясного следующего шага.
Отсюда и фраза «вчера работало». Воркфлоу не изменился, но изменилось окружение. Долговременные процессы зависят от здоровья других сервисов, срока действия учётных данных и от того, что данные остаются в том виде, в котором воркфлоу их ожидает.
Частые режимы отказа выглядят так: тайм‑аута и замедления зависимостей (партнёрский API доступен, но отвечает 40 секунд), частичные обновления (запись A создана, запись B — нет, и безопасно перезапустить нельзя), простои зависимостей (почта/SMS, платежные шлюзы, окна обслуживания), потерянные колбэки и пропущенные расписания (вебхук не пришёл, таймер не сработал) и человеческие шаги, которые застревают (утверждение ждёт днями, затем возобновляется с устаревшими предположениями).
Сложность — в состоянии. Быстрый запрос может хранить состояние в памяти до завершения. Воркфлоу — нет. Оно должно сохранять состояние между шагами и быть готовым возобновиться после рестарта, деплоя или краша. Также нужно уметь работать с повторными триггерами одного и того же шага (повторы, дублированные вебхуки, воспроизведение оператором).
На практике «надёжность» — это не отсутствие ошибок, а предсказуемость, объяснимость, восстановимость и чёткая ответственность.
Предсказуемость означает, что воркфлоу реагирует одинаково каждый раз при отказе зависимости. Объяснимость — оператор может за минуту ответить: «Где он застрял и почему?» Восстанавливаемость — можно безопасно повторить или продолжить без вреда. Ясная ответственность — у каждой зависшей записи есть очевидное следующее действие: ждать, повторить, исправить данные или передать человеку.
Простой пример: автоматизация онбординга создаёт запись клиента, предоставляет доступ и отправляет приветствие. Если провижининг прошёл, а отправка сообщения не прошла из‑за недоступности почтового провайдера, надёжный воркфлоу сохранит «Provisioned, message pending» и запланирует повтор. Он не будет слепо заново выполнять провижининг.
Инструменты упрощают это, когда логика воркфлоу и персистентные данные находятся рядом. Например, AppMaster позволяет моделировать состояние воркфлоу в данных (через Data Designer) и менять его из визуальных Business Processes. Но надёжность — это паттерн, а не инструмент: рассматривайте долговременную автоматизацию как последовательность долговечных состояний, которые переживают время, сбои и вмешательство людей.
Определяйте состояния, понятные людям
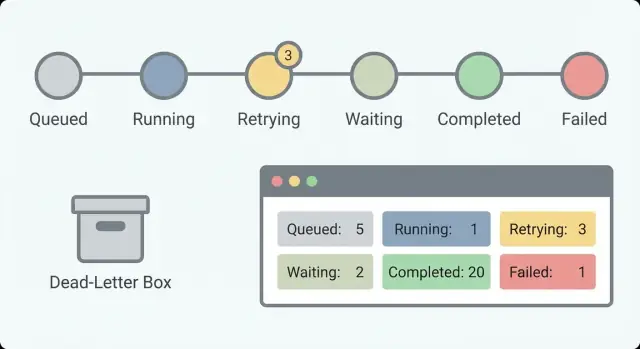
Долговременные воркфлоу склонны к повторяющимся ошибкам: сторонний API замедляется, человек не утвердил запись или задание ждёт в очереди. Ясные состояния делают такие ситуации очевидными и не позволяют путать «занимает время» с «сломалось».
Начните с небольшого набора состояний, которые отвечают на один вопрос: что происходит прямо сейчас? Если у вас 30 состояний, никто их не запомнит. При 5–8 состояниях дежурный может пробежаться глазами и всё понять.
Практичный набор состояний, подходящий для многих воркфлоу:
- Queued (создано, но не начато)
- Running (выполняется)
- Waiting (приостановлено на таймер, колбэк или ввод человека)
- Succeeded (завершено)
- Failed (остановлено с ошибкой)
Разделение Waiting и Running важно. «Ожидает ответа клиента» — это нормальное состояние. «Выполняется 6 часов» может означать зависание. Без такого разделения вы будете гоняться за ложными тревогами и пропускать настоящие.
Что хранить вместе с состоянием
Одного названия состояния недостаточно. Добавьте несколько полей, которые превратят статус в действие:
- Текущее состояние и время последнего изменения
- Предыдущее состояние
- Короткая человекочитаемая причина ожиданий или ошибок
- Дополнительно — счётчик повторов или номер попытки
Пример: поток онбординга может показывать «Waiting» с причиной «Ожидание утверждения менеджера» и временем последнего изменения «2 дня назад». Это подсказывает, что процесс не завис, но, возможно, нужен напоминание.
Стабильность состояний
Относитесь к названиям состояний как к API. Если вы переименовываете их каждый месяц, дашборды, оповещения и playbook‑ы поддержки быстро становятся вводящими в заблуждение. Если нужен новый смысл, добавьте новое состояние и оставьте старое для существующих записей.
В AppMaster вы можете моделировать эти состояния в Data Designer и менять их через Business Process‑логику. Так статус виден и последователен по всему приложению, а не спрятан в логах.
Повторы, которые останавливаются вовремя
Повторы помогают до тех пор, пока не скрывают реальную проблему. Цель не в «никогда не падать», а в «падать так, чтобы люди могли понять и исправить». Всё начинается с чёткого правила, какие ошибки повторять, а какие нет.
Правило, с которым большинство команд может жить: повторяйте ошибки, которые, вероятно, временные (сетевые тайм‑ауты, rate limit, кратковременная недоступность третьей стороны). Не повторяйте ошибки, которые явно постоянны (неверные входные данные, отсутствие прав, «аккаунт закрыт», «карта отклонена»). Если вы не можете понять, к какой категории относится ошибка, считаете её неповторяемой, пока не выясните больше.
Делайте повторы привязанными к шагу, а не ко всему воркфлоу
Отслеживайте счётчики повторов для каждого шага (или для каждого внешнего вызова), а не один общий счётчик для всего воркфлоу. Воркфлоу может содержать десять шагов, и только один из них может быть ненадёжным. Счётчики на уровне шага не позволят позднему шагу «украсть» попытки у раннего.
Например, вызов «Загрузить документ» можно пытаться несколько раз, а «Отправить приветственное письмо» не должен пытаться вечность только потому, что загрузка использовала все попытки ранее.
Backoff, условия остановки и ясные следующие действия
Выберите паттерн backoff, соответствующий риску. Фиксированные задержки подходят для простых недорогих повторов. Экспоненциальный backoff полезен при вероятности столкновения с rate limits. Добавьте ограничение, чтобы задержки не росли бесконечно, и небольшой джиттер, чтобы избежать всплесков повторов.
Затем решите, когда остановиться. Хорошие условия остановки явные: макс. попыток, макс. суммарное время или «бросить для определённых кодов ошибок». Платёжный шлюз, вернувший «invalid card», должен остановиться сразу, даже если обычно вы разрешаете пять попыток.
Операторам нужно знать, что произойдёт дальше. Сохраняйте время следующей попытки и причину (например, «Повтор 3/5 в 14:32 из‑за тайм‑аута»). В AppMaster это можно хранить в записи воркфлоу, чтобы дашборд показывал «ожидание до» без догадок.
Хорошая политика повторов оставляет след: что упало, сколько раз пробовали, когда будет следующая попытка и когда процесс остановится и уйдёт в dead‑letter.
Идемпотентность и защита от дублей
В долгих воркфлоу повторы — нормальная вещь. Риск — повторить шаг, который уже выполнился. Идемпотентность — правило, которое делает это безопасным: шаг идемпотентен, если выполнение его дважды даёт тот же эффект, что и один раз.
Классическая ошибка: вы списали деньги с карты, затем воркфлоу упал до сохранения «платёж успешен». При повторе вы списываете снова. Это проблема двойной записи: внешний мир изменился, а состояние воркфлоу — нет.
Самый безопасный паттерн — создать устойчивый idempotency‑ключ для каждого побочного шага, отправлять его вместе с внешним вызовом и сохранять результат шага сразу по ответу. Многие платёжные провайдеры и приёмники вебхуков поддерживают idempotency‑ключи (например, списание по OrderID). Если шаг повторяется, провайдер вернёт исходный результат, а действие не выполнится повторно.
Внутри движка воркфлоу предполагаете, что любой шаг может быть проигран. В AppMaster это часто означает сохранение выходов шага в базе данных и проверку их в Business Process перед повторным вызовом интеграции. Если «Отправлено приветственное письмо» уже имеет MessageID в записи, повтор должен переиспользовать этот результат и двигаться дальше.
Практический подход, безопасный к дубликатам:
- Генерируйте idempotency‑ключ для шага из стабильных данных (ID воркфлоу + имя шага + ID бизнес‑сущности).
- Записывайте «шаг начат» до внешнего вызова.
- После успеха сохраняйте ответ (ID транзакции, MessageID, статус) и помечайте шаг как «выполнен».
- При повторе ищите сохранённый результат и переиспользуйте его вместо повтора вызова.
- Для неясных случаев добавьте правило окна времени (например, «если начат и нет результата через 10 минут, проверьте статус у провайдера перед повтором»).
Дубли всё равно случаются: входящие вебхуки могут прийти дважды или пользователь нажать кнопку дважды. Решение зависит от типа события: игнорировать точные дубликаты (тот же idempotency‑ключ), сливать совместимые обновления (например, last‑write‑wins для поля профиля) или помечать на ручную проверку, если есть риск денег или соответствия требованиям.
Обработка dead-letter без потери контекста
Сделайте воркфлоу возобновляемыми
Моделируйте долговременные состояния воркфлоу и сохраняйте прогресс после каждого шага без написания кода.
Dead‑letter — это элемент воркфлоу, который не удалось обработать и который вы сознательно выводите из основного пути, чтобы он не блокировал всё остальное. Его сохраняют намеренно. Цель — упростить понимание, можно ли это исправить, и безопасно повторно обработать.
Главная ошибка — сохранять только текст ошибки. Когда кто‑то вернётся к dead‑letter позже, ему нужно достаточно контекста, чтобы воспроизвести проблему без догадок.
Полезная запись в dead‑letter содержит:
- Стабильные идентификаторы (customer ID, order ID, request ID, workflow instance ID)
- Оригинальные входы (или безопасную снимку), плюс ключевые производные значения
- Где упало (имя шага, состояние, последний успешный шаг)
- Попытки (счётчик повторов, метки времени, следующая запланированная попытка, если есть)
- Детали ошибки (сообщение, код, трассировка стека при наличии и полезло ответа от зависимости)
Классификация делает dead‑letter управляемыми. Короткая категория помогает оператору выбрать правильное действие. Типичные группы: постоянная ошибка (бизнес‑правило, неверное состояние), проблема данных (отсутствует поле, неверный формат), зависимость недоступна (тайм‑аут, rate limit, outage) и auth/permission (протухший токен, отклонённые креденшиалы).
Повторную обработку нужно контролировать. Цель — избежать повторного вреда, например двойного списания или спама. Опишите правила: кто может повторять, когда можно повторять, что можно менять (править конкретные поля, прикрепить недостающий документ, обновить токен), а что должно оставаться неизменным (request ID и downstream idempotency‑ключи).
Сделайте записи dead‑letter доступными для поиска по стабильным идентификаторам. Когда оператор может ввести «order 18422» и увидеть точный шаг, входы и историю попыток, исправления идут быстро и последовательно.
Если вы строите это в AppMaster, относитесь к dead‑letter как к полноценной модели в базе: храните состояние, попытки и идентификаторы как поля. Тогда внутренний дашборд сможет фильтровать, искать и запускать контролируемую повторную обработку.
Видимость, помогающая диагностировать
Настройте повторы безопасно
Создавайте повторные попытки на уровне шага, схему backoff и правила остановки в визуальном Business Process.
Долговременные воркфлоу ломаются медленно и запутанно: шаг ждёт ответа по почте, платёжный провайдер тайм‑аутит или вебхук приходит дважды. Если вы не видите, что воркфлоу делает прямо сейчас, вы начинаете гадать. Хорошая видимость превращает «всё сломано» в чёткий ответ: какой воркфлоу, какой шаг, в каком состоянии и что делать дальше.
Начните с того, чтобы каждый шаг эмитировал один и тот же маленький набор полей, которые операторы могут быстро просканировать:
- Workflow ID (и арендатора/клиента, если есть)
- Имя шага и версия шага
- Текущее состояние (running, waiting, retrying, failed, completed)
- Длительность (время в шаге и общее время воркфлоу)
- Корреляционные ID внешних систем (payment ID, message ID, ticket ID)
Эти поля поддерживают базовые счётчики, которые показывают здоровье системы одним взглядом. Для долгих воркфлоу важнее не отдельные ошибки, а тренды: накопление задач, всплеск повторов или ожидания, которые никогда не заканчиваются.
Отслеживайте started, completed, failed, retrying и waiting во времени. Небольшое число в waiting — нормально (человеческие утверждения). Растущий счётчик waiting обычно означает, что что‑то заблокировано. Растущий счётчик retrying часто указывает на проблему провайдера или баг, который постоянно вызывает одну и ту же ошибку.
Оповещения должны соответствовать опыту операторов. Вместо «произошла ошибка» сигнализируйте о симптомах: растущая задолженность (started минус completed постоянно растёт), слишком много воркфлоу в состоянии waiting дольше ожидаемого, высокий уровень повторов для конкретного шага или всплеск ошибок сразу после релиза/изменения конфигурации.
Храните дорожную карту событий для каждого воркфлоу, чтобы вопрос «что произошло?» можно было ответить одним взглядом. Полезный trail включает метки времени, переходы состояний, сводки входов и выходов (не полные чувствительные полезные нагрузки) и причину повтора или ошибки. Пример: «Charge card: retry 3/5, timeout от провайдера, следующая попытка через 10m.»
Корреляционные ID — это клеевая нить. Если клиент говорит «меня списали дважды», вам нужно сопоставить события воркфлоу с ID транзакции платёжного провайдера и внутренним ID заказа. В AppMaster это можно стандартизировать в Business Process‑логике: генерировать и передавать корреляционные ID через API‑вызовы и шаги обмена сообщениями, чтобы дашборд и логи совпадали.
Панели и действия, дружественные к оператору
Когда воркфлоу длится часы или дни, ошибки — нормальная часть работы. Что превращает нормальные ошибки в инциденты — дашборд, который просто пишет «Failed» и больше ничего. Цель — помочь оператору быстро ответить на три вопроса: что происходит, почему это происходит и что безопасно сделать дальше.
Начните со списка воркфлоу, где легко найти несколько критичных записей. Фильтры снижают панику и шум в чате, потому что любой может сузить вид быстро.
Полезные фильтры: состояние, возраст (время старта и время в текущем состоянии), владелец (команда/клиент/ответственный оператор), тип (имя воркфлоу/версия) и приоритет, если у вас есть шаги, видимые клиентам.
Далее показывайте «почему» рядом со статусом, а не прячьте в логах. Статус‑пил только полезен, если рядом есть последнее сообщение об ошибке, краткая категория ошибки и планируемое следующее действие. Два поля делают большую часть работы: last error и next retry time. Если next retry пуст, явно показывайте, ожидается ли человек, приостановлен ли процесс или это окончательная ошибка.
Действия оператора должны быть по умолчанию безопасными. Направляйте людей к низкорисковым действиям первыми и делайте рискованные действия очевидными:
- Retry now (использует те же правила повторов)
- Pause/resume
- Cancel (с обязательной причиной)
- Move to dead‑letter
- Force continue (только если можно чётко указать, что будет пропущено и что может сломаться)
Именно «Force continue» чаще всего приносит вред. Если вы его даёте, опишите риск простым языком: «Это пропустит проверку платежа и может создать неоплаченный заказ.» Также показывайте, какие данные будут записаны при продолжении.
Аудитируйте всё, что делают операторы. Фиксируйте кто, когда, пред/после состояние и причину в заметке. Если вы делаете внутренние инструменты в AppMaster, храните этот аудит как отдельную таблицу и показывайте его на странице детали воркфлоу, чтобы передачи ответственности были чистыми.
Пошагово: простой паттерн надёжного воркфлоу
Добавьте обработку dead-letter
Спроектируйте таблицу dead-letter с полями контекста, чтобы повторная обработка была контролируемой и понятной.
Этот паттерн делает воркфлоу предсказуемым: у каждого элемента всегда ясное состояние, у каждой ошибки — место для обработки, и операторы могут действовать без догадок.
Шаг 1: Определите состояния и допустимые переходы. Зафиксируйте небольшой набор состояний, понятных человеку (например: Queued, Running, Waiting on external, Succeeded, Failed, Dead-letter). Затем решите, какие переходы легальны, чтобы работа не ускользала в лимбо.
Шаг 2: Разбейте работу на небольшие шаги с чёткими входами и выходами. Каждый шаг должен принимать одно определённое входное значение и давать один выход (или явную ошибку). Если нужен человеческий выбор или вызов внешнего API, сделайте из этого отдельный шаг, чтобы его можно было приостановить и возобновить.
Шаг 3: Добавьте политику повторов для каждого шага. Выберите лимит попыток, задержки между ними и причины остановки, которые никогда не повторяются (неверные данные, отказ в правах, отсутствующие обязательные поля). Храните счётчик попыток на уровне шага, чтобы оператор видел, что именно застряло.
Шаг 4: Сохраняйте прогресс после каждого шага. После завершения шага сохраняйте новое состояние и ключевые выходы. При рестарте процесс должен продолжить с последнего подтверждённого шага, а не начинать заново.
Шаг 5: Переводите в dead‑letter и поддерживайте контролируемую повторную обработку. Когда повторы исчерпаны, переводите элемент в dead‑letter и сохраняйте полный контекст: входы, последняя ошибка, имя шага, счётчик попыток и метки времени. Повторная обработка должна быть осознанной: сначала исправьте данные или конфигурацию, затем повторно поставьте в очередь с нужного шага.
Шаг 6: Определите поля дашборда и действия оператора. Хороший дашборд отвечает на вопрос «что упало, где и что я могу сделать дальше?» В AppMaster это можно реализовать как простое админ‑веб‑приложение поверх таблиц воркфлоу.
Ключевые поля и действия для включения:
- Текущее состояние и текущий шаг
- Счётчик повторов и время до следующей попытки
- Короткое сообщение об ошибке и категория ошибки
- «Перезапустить шаг» и «Поставить воркфлоу в очередь заново»
- «Отправить в dead‑letter» и «Отметить как решённое»
Пример: онбординг с шагом одобрения человека
Развёртывайте куда угодно
Разверните инструмент воркфлоу в облаке или экспортируйте исходники, когда нужен полный контроль.
Онбординг сотрудников — хорошая проверка. Там смешиваются утверждения, внешние системы и люди, которые могут быть офлайн. Простой поток: HR заполняет форму нового сотрудника, менеджер утверждает, IT создаёт аккаунты, а новому сотруднику отправляют приветственное сообщение.
Сделайте состояния понятными. Открыв запись, человек должен сразу видеть разницу между «Ожидание утверждения» и «Повторная настройка аккаунтов». Одна строка ясности экономит час угадываний.
Набор состояний для UI:
- Draft (HR редактирует)
- Waiting for manager approval
- Provisioning accounts (с видимым счётчиком повторов)
- Notifying new hire
- Completed (или Canceled)
Повторы уместны для шагов, зависящих от сети или внешних API: provision аккаунтов (почта, SSO, Slack), отправка email/SMS и вызовы внутренних API. Держите счётчик повторов видимым и с ограничением (например, до пяти попыток с возрастающими задержками, затем остановка).
Обработка dead‑letter предназначена для проблем, которые не исправятся сами: нет менеджера в форме, некорректный email или запрос доступа, конфликтующий с политикой. Переведя прогон в dead‑letter, сохраняйте контекст: какое поле провалило валидацию, последний ответ API и кто может одобрить обход.
Операторам нужен небольшой набор простых действий: исправить данные (добавить менеджера, поправить email), перезапустить конкретный неудавшийся шаг (не весь воркфлоу) или аккуратно отменить (и при необходимости откатить частичную настройку).
С AppMaster вы можете смоделировать это в Business Process Editor, хранить счётчики повторов в данных и собрать экран оператора в веб‑UI builder, который показывает состояние, последнее сообщение об ошибке и кнопку для повтора неудавшегося шага.
Чеклист и следующие шаги
Большинство проблем надёжности предсказуемы: шаг выполняется дважды, повторы крутятся в 2 утра или «зависшая» запись не содержит подсказок, что произошло. Чеклист помогает избежать превращения проблемы в угадайку.
Быстрые проверки, которые ловят большинство проблем на раннем этапе:
- Может ли нетехнический человек прочитать каждое состояние и понять его (Ожидание оплаты, Отправка письма, Ожидание утверждения, Завершено, Ошибка)?
- Ограничены ли повторы явными пределами (макс. попыток, макс. время) и виден ли счётчик попыток для каждого шага?
- Сохраняется ли прогресс после каждого шага, чтобы рестарт продолжал с последнего подтверждённого пункта?
- Идемпотентен ли каждый шаг, или защищён от дублей ключом запроса, блокировкой или проверкой «уже сделано»?
- При переводе в dead‑letter сохраняется ли достаточно контекста для безопасного исправления и повторного запуска (входы, имя шага, метки времени, последняя ошибка и управляемое действие повтора)?
Если вы можете улучшить только одно — улучшите видимость. Многие «баги воркфлоу» — это на самом деле «мы не видим, что оно делает». Ваш дашборд должен показывать, что произошло последним, что произойдёт следующим и когда.
Практичный вид оператора включает текущее состояние, последнее сообщение об ошибке, счётчик попыток, время до следующей попытки и одно очевидное действие (повторить сейчас, пометить как решённое или отправить на ручной просмотр). Действия по умолчанию должны быть безопасными: перезапуск одного шага, а не всего воркфлоу.
Следующие шаги:
- Сначала набросайте модель состояний (состояния, переходы и какие из них терминальные).
- Опишите правила повторов для каждого шага: какие ошибки повторять, как долго ждать и когда остановиться.
- Решите, как вы будете предотвращать дубликаты: idempotency‑ключи, уникальные ограничения или «проверить‑и‑действовать» защиты.
- Определите схему записи dead‑letter, чтобы люди могли диагностировать и повторно запускать безопасно.
- Реализуйте поток и панель оператора в инструменте вроде AppMaster, затем тестируйте с принудительными отказами (тайм‑ауты, неверные входы, падение сторонних сервисов).
Относитесь к этому как к живому чеклисту. Каждый раз, добавляя новый шаг, прогоняйте эти проверки перед попаданием в продакшн.
Вопросы и ответы
Долговременные воркфлоу могут функционировать часами и всё же завершиться неудачей в конце, оставив частично применённые изменения. Они зависят от внешних факторов, которые могут измениться в процессе: доступность сторонних сервисов, действительность учётных данных, формат данных и сроки ответа людей.
Держите набор состояний небольшим и понятным, чтобы оператор мог увидеть с первого взгляда, что происходит. Надёжный набор по умолчанию: queued, running, waiting, succeeded и failed, причём «waiting» явно отделено от «running», чтобы отличать здоровые паузы от зависаний.
Храните достаточно информации, чтобы статус стал действующим: текущее состояние, время последнего изменения, предыдущее состояние и короткая человекочитаемая причина ожидания или ошибки. При наличии повторов храните счётчик попыток и время следующей запланированной попытки, чтобы никто не гадал, что произойдёт дальше.
Это предотвращает ложные тревоги и пропущенные инциденты. «Ожидание одобрения» или «ожидание вебхука» может быть нормальным состоянием, тогда как «выполняется 6 часов» — это, вероятно, зависание. Разделение этих состояний улучшает оповещения и решения операторов.
Повторяем ошибки, которые скорее всего временные: тайм‑ауты, превышение лимитов, кратковременные падения сервисов. Не повторяйте очевидно постоянные ошибки: неверные входные данные, отсутствие прав, отклонённые платежи — повторы в таких случаях только усугубят ситуацию.
Повторы, привязанные к шагам, не дают одной ненадёжной интеграции «съесть» все попытки для всего воркфлоу. Они же упрощают диагностирование: видно, какой конкретно шаг падает, сколько раз его пробовали, при этом другие шаги остаются нетронутыми.
Выберите backoff, соответствующий риску: фиксированные задержки хороши для дешёвых вызовов, экспоненциальный backoff — при лимитах. Ограничьте рост задержек капом и добавьте небольшой джиттер. Явно пропишите условия остановки: макс. попыток, макс. время или определённые коды ошибок, после которых повторы не нужны.
Предполагаете, что любой шаг может выполниться дважды: реализуйте идемпотентность. Часто это делается через устойчивый idempotency‑ключ для каждого побочного действия, запись «шаг начат» перед внешним вызовом и сохранение результата сразу после получения ответа, чтобы повтор мог переиспользовать результат, а не повторять действие.
Dead‑letter — это элемент воркфлоу, который вы сознательно переводите вне основного пути после исчерпания повторов, чтобы он не блокировал остальную работу. В запись dead‑letter нужно положить всю контекстную информацию: идентификаторы, входные данные (или безопасную их снимку), где произошёл сбой, историю попыток и ответ зависимости, а не только короткое сообщение об ошибке.
Панель для оператора должна быстро отвечать на три вопроса: что происходит, почему это происходит и что безопасно сделать дальше. Показывайте единообразные поля: идентификатор воркфлоу, текущий шаг, состояние, время в состоянии, последнее сообщение об ошибке и корреляционные ID. По умолчанию предлагайте безопасные действия: повтор одного шага, пауза/возобновление, отправка в dead‑letter — а рискованные действия помечайте явно.