Почему растущие SaaS-стеки быстро становятся хаотичными
SaaS-стек часто начинается просто: одна CRM, один биллинг, один почтовый ящик поддержки. Затем команда добавляет маркетинг-автоматизацию, хранилище данных, второй канал поддержки и пару нишевых инструментов, которые «нужно только быстро синхронизировать». Через некоторое время у вас получается паутина точечных соединений, за которые никто полностью не отвечает.
Первым обычно ломается не данные. Ломается клей вокруг них.
Учётные данные оказываются раскиданы по личным аккаунтам, общим таблицам и случайным переменным окружения. Токены истекают, люди уходят, и внезапно «интеграция» зависит от логина, который никто не может найти. Даже когда безопасность настроена хорошо, ротация секретов становится болезненной, потому что у каждого соединения своя процедура и своё место для обновления.
Дальше тонет видимость. Каждый интегратор сообщает статус по‑разному (или вообще не сообщает). Один инструмент пишет «connected», но молча не синхронизирует. Другой шлёт туманние письма, которые игнорируют. Когда продавец спрашивает, почему клиент не был Provisioned, ответ превращается в охоту за информацией по логам, дашбордам и чат-нитьям.
Нагрузка на поддержку быстро растёт, потому что отказы трудно диагностировать и легко повторить. Небольшие проблемы — лимиты скорости, изменения схемы, частичные повторы — превращаются в долгие инциденты, когда никто не видит полного пути от «событие произошло» до «данные дошли».
Интеграционный хаб — это простая идея: одно центральное место, где управляются, мониторятся и поддерживаются ваши соединения со сторонними сервисами. Хороший дизайн хаба задаёт единые правила для аутентификации интеграций, отчетности о состоянии синхронизации и обработки ошибок.
Практический хаб стремится к четырём результатам: меньше сбоев (общие паттерны повторов и валидации), более быстрые починки (легкая трассировка), более безопасный доступ (централизованная ответственность за учётные данные) и меньшие затраты на поддержку (стандартные оповещения и сообщения).
Если вы строите стек на платформе вроде AppMaster, цель та же: сделать операции по интеграциям достаточно простыми, чтобы неспециалист понимал, что происходит, а специалист мог быстро исправить проблему.
Составьте карту интеграций и потоков данных
Перед крупными решениями по интеграциям получите чёткую картину того, с чем вы уже связаны (или планируете связаться). Это то, что люди пропускают, и именно это обычно создаёт сюрпризы позже.
Начните с перечисления каждого стороннего сервиса в стеке, даже «маленьких». Укажите, кто за него отвечает (человек или команда) и находится ли он в проде, в планах или в эксперименте.
Далее разделите интеграции на видимые для клиентов и фоновые автоматизации. Клиентоориентированная интеграция может быть «Подключите ваш аккаунт Salesforce». Внутренняя автоматизация — «Когда счёт оплачен в Stripe, пометить клиента как активного в базе». У этих типов разные ожидания надёжности и разные способы отказа.
Затем отобразите потоки данных, задав один вопрос: кому нужны данные, чтобы выполнять свою работу? Продукту нужны события использования для онбординга. Операциям нужен статус аккаунта и provision. Финансам — счета, возвраты и налоговые поля. Поддержке — тикеты, история бесед и совпадения идентичностей пользователей. Эти потребности формируют ваш интеграционный хаб сильнее, чем API поставщиков.
Наконец, установите ожидания по времени для каждого потока:
- Реальное время: действия, запущенные пользователем (подключение, отключение, мгновенные обновления)
- Почти в реальном времени: несколько минут допустимы (синхрон статуса, обновления прав)
- Раз в день: отчёты, бэфиллы, экспорт для финансов
- По запросу: инструменты поддержки и админ-действия
Пример: «Оплаченный счёт» может требовать почти реального времени для контроля доступа, но ежедневной выборки для финансовых сводок. Зафиксируйте это заранее, и мониторинг с обработкой ошибок станут гораздо проще стандартизировать.
Решите, что должен делать ваш хаб интеграций
Хороший дизайн начинается с границ. Если хаб пытается делать всё, он станет узким местом для каждой команды. Если делает слишком мало, у вас появится дюжина разрозненных скриптов, которые ведут себя по‑разному.
Запишите, за что отвечает хаб, а что нет. Практический раздел может выглядеть так:
- Хаб отвечает за настройку подключений, хранение учётных данных, планирование и единый контракт для статусов и ошибок.
- Downstream-сервисы отвечают за бизнес-решения: кого выставлять счётом, что считать квалифицированным лидом и т. п.
Выберите одну точку входа для всех интеграций и придерживайтесь её. Точкой входа может быть API (остальные системы вызывают хаб) или планировщик задач (хаб запускает запланированные pull/push). Можно использовать и то, и другое, но только если они разделяют один внутренний pipeline — тогда повторы, логирование и оповещения ведут себя одинаково.
Несколько решений помогут держать хаб в фокусе: стандартизируйте триггеры интеграций (вебхук, расписание, ручной перезапуск), согласуйте форму пограничного payload (даже если у партнёров разные форматы), решите, что сохранять (сырые события, нормализованные записи, оба варианта или ничего), определите, что значит «готово» (accepted, delivered, confirmed), и назначьте владельцев для партнёрских особенных случаев.
Решите, где происходят трансформации. Если вы нормализуете данные в хабе, downstream-сервисы остаются проще, но хаб требует более строгого версионирования и тестирования. Если хаб остаётся тонким и пропускает сырые payload'ы дальше, каждая downstream-служба должна уметь работать с форматом каждого партнёра. Многие команды выбирают компромисс: нормализуют только общие поля (ID, метки времени, базовый статус) и оставляют доменные правила downstream.
Планируйте мультиарендность с первого дня. Решите, единицей изоляции является клиент, workspace или организация. Этот выбор влияет на лимиты скорости, хранение учётных данных и бэфиллы. Когда у одного клиента истекает токен Salesforce, нужно ставить на паузу только его задания, а не весь pipeline. Инструменты вроде AppMaster помогают визуально моделировать арендаторов и рабочие процессы, но границы всё равно должны быть ясны до разработки.
Централизуйте учётные данные, но не создавайте риск для безопасности
Хранилище учётных данных может либо упростить жизнь, либо превратиться в постоянный источник инцидентов. Цель проста: одно место для хранения доступа без предоставления лишней власти системам и людям.
OAuth и API-ключи встречаются в разных местах. OAuth распространён для клиентских приложений вроде Google, Slack, Microsoft и многих CRM: пользователь даёт доступ, вы храните access token и refresh token. API-ключи чаще для сервер‑сервер взаимодействий и старых API. Они могут быть долгоживущими, поэтому безопасное хранение и ротация особенно важны.
Храните всё в зашифрованном виде и привязывайте к нужному арендатору. В мультиклиентском продукте рассматривайте учётные данные как данные клиента. Строго изолируйте их, чтобы токен Tenant A никогда не мог быть использован для Tenant B, даже случайно. Также сохраняйте метаданные, которые понадобятся позже: к какому подключению принадлежит токен, когда он истекает и какие права были предоставлены.
Практические правила, предотвращающие большинство проблем:
- Используйте политики минимально необходимых прав. Запрашивайте только те разрешения, которые нужны сегодня.
- Не сохраняйте учётные данные в логах, сообщениях об ошибках и скриншотах поддержки.
- Проводите ротацию ключей, когда это возможно, и отслеживайте, какие системы ещё используют старый ключ.
- Разделяйте окружения. Никогда не используйте продакшен-учётные данные в стейджинге.
- Ограничьте, кто может просматривать или переавторизовывать подключение в админ-UI.
Планируйте обновление и отзыв без разрыва синхронизаций. Для OAuth обновление должно происходить автоматически в фоне, а хаб должен уметь обработать «token expired», попытавшись обновить токен один раз и безопасно повторить операцию. При отзыве (пользователь отключил доступ, команда безопасности деактивировала приложение или изменились права) остановите синхрон, пометьте соединение как needs_auth и ведите ясный аудит событий.
Если вы строите хаб в AppMaster, рассматривайте учётные данные как защищённую модель данных, держите доступ в логике только бэкенда и показывайте UI только статус connected/disconnected. Операторы смогут исправить подключение, не видя секретов.
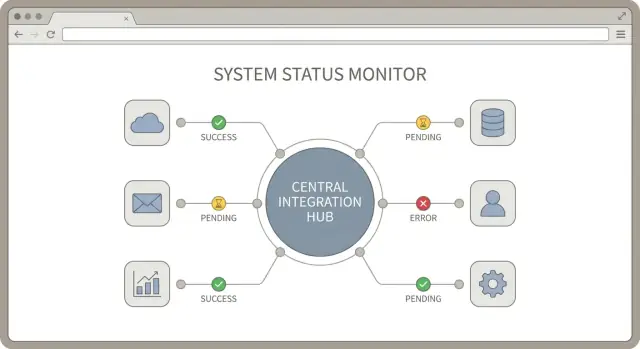
Делайте статус синхронизации видимым и согласованным
Начните с одного пилотного коннектора
Преобразуйте один реальный интегратор в рабочий конвейер перед тем как добавлять следующие десять.
Когда вы подключаете много инструментов, вопрос «это работает?» становится ежедневным. Решение — не больше логов, а небольшой, согласованный набор сигналов состояния, одинаковых для каждой интеграции. Хороший дизайн хаба считает статус первоклассной фичей.
Начните с определения короткого списка состояний подключения и используйте их везде: в админ-UI, в оповещениях и в заметках поддержки. Давайте им простые названия, чтобы неспециалист мог понять, что делать.
- connected: учётные данные валидны и синхронизация идёт
- needs_auth: нужно заново авторизовать (истёк токен, отозван доступ)
- paused: остановлено намеренно (техработы, по запросу клиента)
- failing: повторяющиеся ошибки, требуется внимание человека
Отслеживайте три временные метки для каждого соединения: начало последней синхронизации, время последней успешной синхронизации и время последней ошибки. Они быстро рассказывают историю без копания в логах.
Небольшая страница интеграции помогает службе поддержки действовать быстрее. На ней должно быть текущее состояние, эти метки времени и последнее сообщение об ошибке в удобном для пользователя виде (без stack trace). Добавьте короткую рекомендованную строку действия, например «Требуется повторная аутентификация» или «Rate limit, повторяем».
Добавьте несколько health‑сигналов, которые предсказывают проблемы до того, как их заметят пользователи: размер бэклога, число повторов, попадания в rate limit и последняя успешная пропускная способность (примерно сколько элементов синхронизируется за запуск).
Пример: ваш синк с CRM в состоянии connected, но бэклог растёт и количество попаданий в лимит резко увеличилось. Это ещё не аут, но явный сигнал снизить частоту синков или сгруппировать запросы. Если вы строите хаб в AppMaster, эти поля статуса удобно отобразить в модели Data Designer и в простой админ‑панели для поддержки.
Проектируйте поток синхронизации пошагово
Надёжная синхронизация — это про повторяемые шаги, а не про хитрую логику. Начните с одной понятной модели выполнения, затем добавляйте сложность только там, где это нужно.
1) Выберите, как работа попадает в хаб
Большинство команд использует микс, но у каждого коннектора должен быть основной триггер, чтобы проще было рассуждать о сбоях:
- События (вебхуки) — для почти реального времени
- Джобы — для действий, которые нужно выполнить до конца (например, «создать счёт, затем пометить как оплаченный»)
- Плановые pulls — для систем, которые не умеют пушить, или для безопасных бэфиллов
В AppMaster это часто соответствует webhook endpoint, фоновой задаче и расписанию, которые всё втекают в один и тот же внутренний pipeline.
2) Нормализуйте сначала, затем обрабатывайте
Разные вендоры называют одно и то же по‑разному (customerId vs contact_id, строки статусов, форматы дат). Преобразуйте каждый входящий payload в единый внутренний формат до применения бизнес-правил. Это упрощает остальной хаб и делает изменения коннекторов менее болезненными.
3) Делайте каждую запись идемпотентной
Повторы — нормальное явление. Хаб должен уметь выполнить то же действие дважды без создания дублей. Частый подход — хранить внешний ID и «последнюю обработанную версию» (метка времени, sequence number или event ID). Если приходит тот же элемент, пропускайте или безопасно обновляйте.
4) Помещайте работу в очередь и ставьте потолок ожидания
Сторонние API могут быть медленными или подвисать. Кладите нормализованные задачи в надёжную очередь, затем обрабатывайте их с явными тайм‑аутами. Если вызов занимает слишком много времени, фиксируйте провал, записывайте причину и откладывайте повтор, вместо того чтобы блокировать всё остальное.
5) Уважайте лимиты скорости сознательно
Обрабатывайте лимиты и с помощью backoff, и с помощью троттлинга на уровне коннектора. Давайте backoff при 429/5xx с ограниченным графиком повторов, ставьте отдельные ограничения параллелизма для каждого коннектора (CRM — не то же самое, что биллинг) и добавляйте jitter, чтобы избежать одновременных всплесков повторов.
Пример: «новый оплаченный счёт» пришёл из биллинга вебхуком, нормализован, поставлен в очередь, затем создаёт или обновляет соответствующий аккаунт в CRM. Если CRM наложила rate limit, этот коннектор замедляется, не задерживая синк тикетов поддержки.
Обработка ошибок, которую команда действительно сможет поддерживать
Проектируйте для безопасных повторов
Реализуйте идемпотентные upsert-операции, чтобы повторы не создавали дубликатов между инструментами.
Хаб, который «иногда падает», хуже, чем его отсутствие. Решение — общий способ описать ошибки, решить, что делать дальше, и объяснить нетехническим администраторам, что делать.
Начните со стандартной формы ошибки, которую возвращает каждый коннектор, даже если внешние payload'ы отличаются. Это делает UI, оповещения и playbook'и поддержки согласованными.
- code: стабильный идентификатор (например,
RATE_LIMIT)
- message: короткое понятное резюме
- retryable: true/false
- context: безопасные метаданные (название интеграции, endpoint, ID записи)
- provider_details: очищенный сниппет для отладки
Классифицируйте отказы по нескольким корзинам (держите их мало): auth, validation, timeout, rate limit и outage.
Прикрепляйте явные правила повторов к каждой категории. Rate limit — отложенные повторы с backoff. Таймауты — быстрые повторы небольшое число раз. Validation — вручную, пока данные не исправят. Auth — приостанавливает интеграцию и просит админа переподключить.
Сохраняйте сырые ответы сторонних сервисов, но безопасно. Редактируйте секреты (токены, API‑ключи, полные данные карт) перед сохранением. Если ответ может дать доступ — он не должен быть в логах.
Пишите два сообщения для каждой ошибки: одно для админа, другое для инженеров. Сообщение для админа: «Подключение Salesforce истекло. Переподключите, чтобы возобновить синхронизацию». Вид для инженера может включать очищенный ответ, request ID и шаг, на котором произошёл провал. Именно здесь согласованный хаб окупает себя, будь то кодовая реализация или визуальные процессы в Business Process Editor у AppMaster.
Частые ловушки и как их избегать
Постройте простой хаб интеграций
Постройте первый коннектор и экран статуса с помощью визуальной логики и реального сгенерированного кода.
Многие проекты по интеграциям проваливаются по тривиальным причинам. Хаб работает в демо, а падает при добавлении арендаторов, типов данных и краевых случаев.
Одна большая ловушка — смешивать логику подключения с бизнес-логикой. Когда «как говорить с API» находится в том же кодовом пути, что и «что означает запись клиента», любое новое правило рискует поломать коннектор. Делайте адаптеры, отвечающие за auth, paging, rate limits и маппинг, а бизнес‑правила держите в отдельном слое, который можно тестировать без вызовов сторонних API.
Ещё одна проблема — считать состояние арендатора глобальным. В B2B каждая организация нуждается в собственных токенах, курсорах и контрольных точках синка. Если «время последней синхронизации» хранится в одном общем месте, один клиент может перезаписать другого и вы получите пропущенные обновления или утечки данных между арендаторами.
Пять ловушек и простые исправления:
- Логика подключения и бизнес-логика перепутаны. Решение: создать явную границу адаптера (connect, fetch, push, transform), а бизнес-правила выполнять после адаптера.
- Токены хранятся едино и переиспользуются между арендаторами. Решение: хранить креденшалы и refresh token на арендатора и безопасно их ротировать.
- Повторы работают вечно. Решение: использовать ограниченные попытки с backoff и останавливать после явного лимита.
- Любая ошибка считается повторяемой. Решение: классифицировать ошибки и немедленно показывать проблемы с авторизацией.
- Нет аудита. Решение: писать лог аудита о том, кто синхронизировал что, когда и почему это упало, включая request ID и внешние object ID.
Повторы требуют особого внимания. Если вызов создания таймаутнулся, повтор может создать дубликаты, если не использованы идемпотентные ключи. Если API не поддерживает идемпотентность, ведите локальную книгу записей, чтобы обнаруживать и предотвращать повторные записи.
Не пропускайте аудити‑логи. Когда поддержка спрашивает, почему запись пропала, вам нужен ответ за минуты, а не догадки. Даже если вы строите хаб визуально (в AppMaster), сделайте логи и состояние арендатора первоклассными сущностями.
Быстрый чек‑лист для надёжного интеграционного хаба
Хороший хаб в лучшем смысле — скучный: он подключается, ясно сообщает о здоровье и падает понятным для команды способом.
Безопасность и основы подключений
Проверьте, как каждый интегратор аутентифицируется и что вы делаете с этими учётными данными. Запрашивайте минимальные права (по возможности read‑only). Храните секреты в выделённом секретном хранилище или зашифрованном хранилище и ротируйте их без изменения кода. Убедитесь, что логи и сообщения об ошибках никогда не содержат токенов, ключей, refresh token'ов или сырых заголовков.
После того как креденшалы в безопасности, подтвердите, что у каждого клиентского подключения есть единый и однозначный источник правды.
Видимость, повторы и готовность поддержки
Операционная ясность — то, что удерживает интеграции управляемыми при десятках клиентов и множестве сторонних сервисов.
Отслеживайте состояние подключения на клиента (connected, needs_auth, paused, failing) и показывайте это в админке. Записывайте временную метку последней успешной синхронизации на объект или на задачу синка, а не просто «мы что‑то запускали вчера». Сделайте последнюю ошибку лёгкой для поиска с контекстом: какой клиент, какая интеграция, какой шаг, какой внешний запрос и что произошло дальше.
Ограничивайте повторы (максимум попыток и окно отката) и проектируйте записи идемпотентными, чтобы повторы не создавали дублей. Ставьте цель поддержки: кто‑то из команды должен найти последнюю ошибку и её детали за менее чем две минуты без чтения кода.
Если нужно быстро сделать UI хаба и трекинг статусов, платформа вроде AppMaster поможет выпустить внутреннюю панель и логику рабочих процессов быстро, при этом сгенерировав код, готовый к продакшену.
Реалистичный пример: три интеграции, один хаб
Постройте весь стек продукта
Используйте визуальные инструменты для построения бэкенд-логики, веб-экранов и мобильных приложений вокруг вашего хаба.
Представьте SaaS‑продукт с тремя распространёнными интеграциями: Stripe для событий биллинга, HubSpot для передачи сделок и Zendesk для тикетов поддержки. Вместо того чтобы подключать каждый инструмент напрямую, прокиньте их через один интеграционный хаб.
Онбординг начинается в админ‑панели: админ нажимает «Connect Stripe», «Connect HubSpot», «Connect Zendesk». Каждый коннектор сохраняет креденшалы в хабе, а не в случайных скриптах или на ноутбуках сотрудников. Затем хаб запускает начальный импорт:
- Stripe: клиенты, подписки, счета (и настройка вебхуков для новых событий)
- HubSpot: компании, контакты, сделки
- Zendesk: организации, пользователи, недавние тикеты
После импорта стартует первая синхронизация. Хаб записывает запись синка для каждого коннектора, чтобы все видели одну и ту же историю. Простая админ‑карточка отвечает на большинство вопросов: состояние соединения, время последней успешной синхронизации, текущее задание (импорт, синхронизация, idle), сводка ошибок и код, и следующий запланированный запуск.
Теперь час пик и Stripe начинает ограничивать ваши API‑вызовы. Вместо фейла всей системы, коннектор Stripe помечает джоб как retrying, сохраняет частичный прогресс (например, «invoices до 10:40») и делает backoff. HubSpot и Zendesk продолжают синкить.
Поддержка получает тикет: «Биллинг отстаёт». Они открывают хаб и видят Stripe в failing с ошибкой rate limit. Разрешение по процедуре:
- Переподключать Stripe только если токен действительно недействителен
- Перезапустить последний упавший джоб с сохранённой контрольной точки
- Подтвердить успех, проверив время последней синхронизации и сделав небольшую проверку (один счёт, одна подписка)
Если вы строите на AppMaster, этот поток аккуратно отображается в визуальной логике (состояния задач, повторы, админ‑экраны) и при этом генерирует реальный бэкенд‑код для продакшена.
Следующие шаги: стройте итеративно и держите операции простыми
Хороший дизайн хаба — это не про всё сразу, а про предсказуемость каждого нового соединения. Начните с набора общих правил, которым должен следовать каждый коннектор, даже если первая версия покажется «слишком простой».
Начните с согласованности: стандартные состояния для джобов синхронизации (pending, running, succeeded, failed), небольшой набор категорий ошибок (auth, rate limit, validation, upstream outage, unknown) и аудиt‑логи, которые отвечают кто, что и когда запускал и почему это упало. Если нельзя доверять статусам и логам, дашборды и алерты будут лишь шумом.
Добавляйте коннекторы по одному, используя те же шаблоны и соглашения. Каждый новый коннектор должен переиспользовать тот же поток авторизации, те же правила повторов и тот же способ записи статусов. Повторяемость — вот что делает хаб поддерживаемым, когда у вас десять интеграций вместо трёх.
Практический план развёртывания:
- Выберите 1 пилотного арендатора с реальным использованием и чёткими критериями успеха
- Постройте 1 коннектор полностью, включая статусы и логи
- Запустите неделю, исправьте три главные причины ошибок, затем задокументируйте правила
- Добавьте следующий коннектор, используя те же правила, а не кастомные фиксы
- Масштабируйте на больше арендаторов постепенно, с простым планом отката
Вводите дашборды и оповещения только после того, как базовые данные о статусах корректны. Начните с одного экрана, который показывает время последней синхронизации, последний результат, следующий запуск и последнее сообщение об ошибке с категорией.
Если вы предпочитаете no‑code подход, вы можете смоделировать данные, построить логику синка и открыть экраны статусов в AppMaster, а затем развернуть в облаке или экспортировать исходный код. Держите первую версию скучной и наблюдаемой, затем улучшайте производительность и краевые случаи, когда операции станут стабильными.
Вопросы и ответы
Начните с простой инвентаризации: перечислите все сторонние сервисы, кто за них отвечает и находятся ли они в проде, в планах или в эксперименте. Затем опишите данные, которые передаются между системами, и почему они важны для команд (поддержка, финансы, операционные команды). Эта карта подскажет, какие потоки нужны в реальном времени, какие можно запускать раз в день и какие требуют повышенного мониторинга.
Хаб должен владеть общей «проводкой»: настройкой подключений, хранением учётных данных, планировкой/триггерами, единым отчётом о статусе и согласованной обработкой ошибок. Бизнес-решения (кто выставлять счёт, что считается квалифицированным лидом и т. п.) оставляйте вне хаба, чтобы не менять код коннекторов при каждом изменении продуктовой логики.
Назначьте один основной путь входа для каждого коннектора, чтобы было проще разбираться с ошибками. Вебхуки подходят для почти реального времени, плановые запросы — когда провайдеры не умеют пушить, а джоб-воркфлоу — когда нужно выполнить шаги последовательно. Во всех случаях используйте одинаковые правила повторов, логирования и обновления статусов.
Рассматривайте учётные данные как данные клиента: храните их зашифрованными с жёсткой изоляцией по арендаторам. Не показывайте токены в логах, на экранах UI или в скриншотах поддержки, не используйте продакшен-ключи в стейджинге. Сохраняйте метаданные, которые понадобятся для работы: время истечения, запрошенные права и к какой связи принадлежит токен.
OAuth удобен, когда пользователи сами подключают свои аккаунты и нужен отзывный доступ с ограниченными правами. API-ключи проще для сервер-сервер интеграций, но обычно долгоживущие — поэтому важно регулярно вращать их и ограничивать доступ. По возможности выбирайте OAuth для коннектов, где подключаются пользователи.
Для хаба это означает хранить состояние арендатора отдельно: токены, курсоры, контрольные точки синхронизации, счётчики повторов и прогресс бекфиллов. Ошибка одного арендатора должна ставить на паузу только его задания, а не весь коннектор. Такая изоляция предотвращает утечки данных между арендаторами и упрощает поддержку.
Показывайте небольшой набор простых состояний для каждого коннектора: connected, needs_auth, paused и failing. Записывайте три метки времени на соединение: время начала последней синхронизации, время последней успешной синхронизации и время последней ошибки. Эти сигналы отвечают на большинство вопросов «работает ли это?» без просмотра логов.
Делайте записи идемпотентными: используйте внешний ID объекта и маркер «последней обработки» (метка времени, номер последовательности или ID события). При повторном приходе того же элемента пропускайте или корректно обновляйте запись. Если провайдер не поддерживает идемпотентность, ведите локальный журнал записей, чтобы обнаруживать повторные попытки.
Ограничьте скорость осознанно: троттлинг по каждому коннектору, backoff при 429/5xx с capped-расписанием повторов и добавлением jitter, чтобы избежать волновых перегрузок. Держите задачи в надёжной очереди с тайм-аутами, чтобы медленные вызовы к одному провайдеру не блокировали другие синхронизации.
В AppMaster можно моделировать подключения, арендаторов и поля статусов в Data Designer, а синхронную логику — в Business Process Editor. Держите учётные данные в логике только бэкенда и на UI показывайте лишь безопасный статус и подсказки действий. Так вы быстро выпустите внутреннюю операционную панель и в то же время получите код, годный для продакшена.