17 февр. 2025 г.·7 мин
CI/CD для Go‑бэкендов: сборка, тесты, миграции и деплой
CI/CD для Go‑бэкендов: практические шаги конвейера для сборки, тестов, миграций и безопасного деплоя в Kubernetes или на ВМ с предсказуемыми окружениями.
Почему CI/CD важен для Go-бэкендов
Ручные деплои терпят неудачи по скучным, повторяемым причинам. Кто‑то собирает на ноутбуке с другой версией Go, забывает переменную окружения, пропускает миграцию или перезапускает не тот сервис. Релиз «работает у меня», но не в проде — и вы это узнаёте только после жалоб пользователей.
Сгенерированный код не отменяет дисциплины релизов. Если вы регенерируете бэкенд после изменения требований, можно добавить новые эндпойнты, изменить форму данных или подтянуть новые зависимости, даже не правя код вручную. Именно поэтому конвейер должен работать как страховочная ограда: каждое изменение проходит одни и те же проверки, всегда.
Предсказуемые окружения означают, что шаги сборки и деплоя выполняются в условиях, которые вы можете назвать и воспроизвести. Несколько правил покрывают большую часть проблем:
- Закрепляйте версии (Go toolchain, базовые образы, системные пакеты).
- Собирайте один раз, деплойте тот же артефакт везде.
- Держите конфигурацию вне бинарника (env vars или файлы конфигурации для каждого окружения).
- Используйте один и тот же инструмент миграций и процесс везде.
- Делайте откаты реальными: сохраняйте предыдущий артефакт и знайте, что происходит с базой данных.
Смысл CI/CD для Go‑бэкендов не в автоматизации ради автоматизации. Это повторяемые релизы с меньшим стрессом: регенерируйте, прогоняйте конвейер и доверяйте тому, что выходит пригодным к деплою.
Если вы используете генератор вроде AppMaster, это становится ещё важнее. Регенерация — удобная фича, но она безопасна лишь тогда, когда путь от изменения до продакшена последовательный, протестированный и предсказуемый.
Выберите runtime и заранее определите, что значит «предсказуемо»
«Предсказуемо» значит: одинаковый вход даёт одинаковый результат, где бы вы ни запускали. Для CI/CD Go‑бэкендов это начинается с согласования того, что должно быть идентичным в dev, staging и prod.
Обычно не подлежит обсуждению: версия Go, базовый OS-образ, флаги сборки и способ загрузки конфигурации. Если что‑то из этого меняется между окружениями, вы получите сюрпризы: другое поведение TLS, отсутствующие системные пакеты или баги, проявляющиеся только в проде.
Дрейф окружений чаще всего проявляется здесь:
- ОС и системные библиотеки (разные версии дистрибутива, отсутствующие CA‑сертификаты, различия временных зон)
- Значения конфигурации (feature flags, таймауты, allowed origins, URL внешних сервисов)
- Форма и настройки БД (миграции, расширения, колляция, лимиты соединений)
- Обращение с секретами (где хранятся, как вращаются, кто имеет доступ)
- Сетевые допущения (DNS, firewall, сервис-дискавери)
Выбор между Kubernetes и ВМ — не столько про «что лучше», сколько про то, что ваша команда сможет поддерживать спокойно.
Kubernetes подходит, когда нужны autoscaling, rolling updates и стандартный способ запуска многих сервисов. Он помогает обеспечить консистентность, потому что поды запускаются из одних и тех же образов. ВМ‑подход уместен, если у вас несколько сервисов, маленькая команда и вы хотите меньше движущихся частей.
Можно сохранить одинаковый конвейер даже при разных рантаймах, стандартизировав артефакт и контракт вокруг него. Например: в CI всегда собирайте один и тот же контейнерный образ, прогоняйте одни и те же тесты и публикуйте один и тот же пакет миграций. Тогда меняется только шаг деплоя: Kubernetes применяет новый тег образа, а ВМ тянет образ и перезапускает сервис.
Практический пример: команда регенерирует бэкенд из AppMaster и деплоит в staging на Kubernetes, а в проде пока использует ВМ. Если оба окружения тянут точно тот же образ и загружают конфигурацию из одного типа хранилища секретов, «разный рантайм» перестаёт быть причиной багов. Если вы используете AppMaster (appmaster.io), такая модель хорошо ложится: можно деплоить в управляемые облачные цели или экспортировать исходники и запускать тот же конвейер на собственной инфраструктуре.
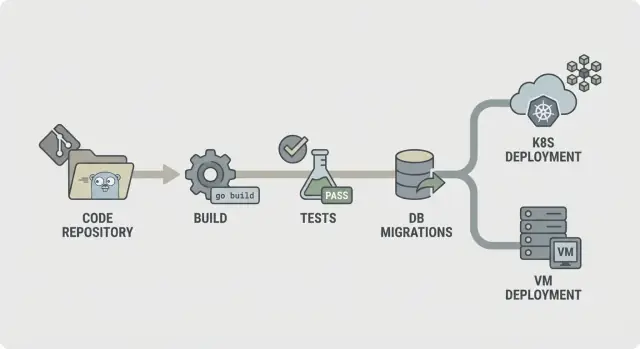
Простой план конвейера, который понятно объяснить каждому
Предсказуемый конвейер легко описать: проверить код, собрать, доказать, что он работает, отгрузить именно то, что тестировали, и деплоить одинаково каждый раз. Такая ясность особенно важна при регенерации бэкенда (например, из AppMaster), потому что изменения могут затрагивать много файлов и нужна быстрая, последовательная обратная связь.
Прямолинейный CI/CD для Go‑бэкендов выглядит так:
- Lint и базовые проверки
- Сборка
- Unit‑тесты
- Интеграционные проверки
- Упаковка (неизменяемые артефакты)
- Миграции (контролируемый шаг)
- Деплой
Структурируйте конвейер так, чтобы ошибки останавливались рано. Если lint падает, ничего не должно идти дальше. Если сборка падает, не тратьте время на поднятие БД для интеграционных тестов. Это экономит ресурсы и делает конвейер быстрым.
Не каждый шаг должен запускаться на каждом коммите. Распространённое разделение:
- Каждый коммит/PR: lint, сборка, unit‑тесты
- Ветка main: интеграционные проверки, упаковка
- Теги релиза: миграции, деплой
Решите, что хранить как артефакты. Обычно это скомпилированный бинарь или контейнерный образ (то, что деплоится), плюс логи миграций и отчёты тестов. Это упрощает откаты и аудиты, потому что можно указать, что именно было протестировано и промотировано.
Пошагово: стадия сборки, стабильная и воспроизводимая
Стадия сборки должна отвечать на один вопрос: можем ли мы произвести тот же бинарник сегодня, завтра и на другом раннере. Если нет, все последующие шаги (тесты, миграции, деплой) теряют доверие.
Начните с фиксации окружения. Используйте фиксированную версию Go (например, 1.22.x) и фиксированный образ раннера (дистрибутив Linux и версии пакетов). Избегайте тегов типа latest. Маленькие изменения в libc, Git или Go toolchain могут породить ошибки «работает у меня», которые тяжело отлаживать.
Кэширование модулей помогает, но только как ускорение, а не как истина. Кэшируйте Go build cache и модульный кеш, но привязывайте ключ к go.sum (или очищайте кеш на main при изменении зависимостей), чтобы новые зависимости всегда триггерили чистое скачивание.
Добавьте быстрый гейт перед компиляцией. Пусть он будет коротким, чтобы разработчики не обходили его. Типичный набор: проверки gofmt, go vet и (если быстро) staticcheck. Также падайте при отсутствующих или устаревших сгенерированных файлах — это частая проблема в регенерируемых кодовых базах.
Компилируйте воспроизводимо и встраивайте информацию о версии. Флаги вроде -trimpath помогают, а -ldflags можно использовать для внедрения commit SHA и времени сборки. Выпускайте один именованный артефакт на сервис. Это облегчает трассировку того, что запущено в Kubernetes или на ВМ, особенно когда бэкенд регенерируется.
Пошагово: тесты, которые ловят проблемы до деплоя
Добавляйте основы без переработки
Используйте встроенные модули: auth, Stripe-платежи и messaging, чтобы двигаться быстрее с меньшим количеством сюрпризов.
Тесты помогают только если они запускаются одинаково каждый раз. Сначала добейтесь быстрого фидбэка, затем добавляйте более глубокие проверки, которые всё ещё завершаются в предсказуемое время.
Начинайте с unit‑тестов на каждом коммите. Задайте жёсткий таймаут, чтобы зависшие тесты падали явно, а не висели весь конвейер. Решите, какое покрытие считается «достаточным» для вашей команды. Покрытие — не трофей, но минимальный бар помогает избежать постепенного падения качества.
Стабильная стадия тестов обычно включает:
- Запуск
go test ./... с таймаутом на пакет и глобальным таймаутом джоба.
- Обращение с тестами, которые попадают в таймаут, как с реальными багами, а не как с «флейки CI».
- Установку ожиданий по покрытию для критичных пакетов (auth, billing, permissions), а не для всего репозитория.
- Добавление race detector для кода с конкуренцией (очереди, кеши, воркеры).
Race detector полезен, но сильно замедляет сборки. Хороший компромисс — запускать его в pull requests и nightly‑сборках или только для выбранных пакетов.
Флейки‑тесты должны проваливать сборку. Если надо карантинить тест, делайте это прозрачно: в отдельном job’е, который всё ещё запускается и показывает красный статус, с назначенным владельцем и дедлайном на фикc.
Храните вывод тестов, чтобы отладка не требовала повторного прогона. Сохраняйте сырые логи и простой отчёт (прошёл/упал, длительность, самые медленные тесты). Это облегчает поиск регрессий, особенно когда регенерация затрагивает много файлов.
Интеграционные проверки с реальными зависимостями, но без долгих прогонов
Соберите весь стек продукта
Генерируйте бэкенд, веб и нативные мобильные приложения из одной платформы, когда нужно.
Unit‑тесты проверяют код в изоляции. Интеграционные проверки говорят, что сервис корректно ведёт себя при запуске, подключаясь к реальным сервисам и обрабатывая реальные запросы. Это страховочная сеть, которая ловит проблемы, проявляющиеся только при полной сборке.
Используйте эфемерные зависимости, когда сервису нужно что‑то для старта или для ответа на ключевые запросы. Временная PostgreSQL (и Redis, если нужен) обычно достаточно. Держите версии близкими к продакшену, но не копируйте каждую деталь продакшена.
Хорошая интеграционная стадия мала намеренно:
- Запустите сервис с production‑подобными env vars (но с тестовыми секретами)
- Проверите health check (например, /health возвращает 200)
- Вызовите один‑два критичных эндпойнта и проверьте коды статусов и форму ответа
- Подтвердите, что он достаёт до PostgreSQL (и Redis, если нужно)
Для проверки контрактов API фокусируйтесь на эндпойнтах, поломка которых будет самой больной. Не нужен полный E2E‑набор — достаточно нескольких проверок: обязательные поля отвергаются с 400, защищённые ресурсы возвращают 401 без авторизации, а happy‑path возвращает 200 с нужными ключами в JSON.
Чтобы интеграции оставались быстрыми, ограничьте охват и контролируйте время. Предпочитайте одну БД с крошечным набором данных. Выполняйте только несколько запросов. Задайте жёсткие таймауты, чтобы зависший старт падал за секунды, а не за минуты.
Если вы регенерируете бэкенд (например, с AppMaster), эти проверки особенно важны: они подтверждают, что регенерированный сервис стартует и отдает ожидаемый API для веба или мобильного клиента.
Миграции базы данных: порядок, гейты и реальность отката
Начните с выбора, где запускать миграции. Запускать их в CI полезно для раннего обнаружения ошибок, но CI обычно не должен трогать продакшен. Большинство команд запускают миграции во время деплоя (как отдельный шаг) или в отдельном job’е «migrate», который должен завершиться до старта новой версии.
Практическое правило: собирайте и тестируйте в CI, а миграции запускайте максимально близко к продакшену, с прод‑креденшалами и прод‑подобными лимитами. В Kubernetes это часто одноразовый Job. На ВМ это может быть скрипт в шаге релиза.
Порядок важнее, чем кажется. Используйте timestamped файлы (или последовательные номера) и соблюдайте «применять по порядку, ровно один раз». По возможности делайте миграции идемпотентными, чтобы повторная попытка не создала дубликатов и не упала на полпути.
Держите стратегию миграций простой:
- Сначала предпочитайте добавляющие изменения (новые таблицы/колонки, nullable колонки, новые индексы).
- Деплойте код, который умеет работать и со старой, и с новой схемой в одном релизе.
- Только затем удаляйте или ужесточайте ограничения (drop columns, NOT NULL).
- Долгие операции делайте безопасными (например, создавайте индексы concurrently, где это поддерживается).
Добавьте safety‑gate перед запуском. Это может быть блокировка БД, чтобы миграция запускалась в единственном числе, плюс политика «никаких деструктивных изменений без одобрения». Например, падайте, если в миграции присутствует DROP TABLE или DROP COLUMN, пока не одобрено вручную.
Откат — жёсткая реальность: многие изменения схемы нереверсивны. Если вы удалили колонку, вернуть данные невозможно. Планируйте откаты вокруг forward‑фиксов: храните down‑миграцию только когда это безопасно, и опирайтесь на бэкапы и форвард‑миграции, когда это не так.
Парируйте каждую миграцию планом восстановления: что делать при падении на полпути и как поступать, если нужно откатиться по коду. Если вы генерируете Go‑бэкенды (например, с AppMaster), рассматривайте миграции как часть контракта релиза, чтобы регенерированный код и схема оставались синхронизированными.
Упаковка и конфигурация: артефакты, которым можно доверять
Деплойте туда, где работает команда
Деплойте туда, где работает ваша команда: AppMaster Cloud или ваша AWS, Azure, Google Cloud инфраструктура.
Конвейер кажется предсказуемым, когда то, что вы деплоите, всегда то же самое, что тестировали. Это вопрос упаковки и конфигурации. Считайте выход сборки как запечатанный артефакт и держите все различия окружений за его пределами.
Упаковка чаще всего идёт двумя путями. Контейнерный образ — дефолтный выбор при деплое в Kubernetes, потому что он фиксирует OS-слой и делает rollout предсказуемым. Для ВМ бандл может быть так же надёжным, если он включает бинарник и небольшой набор файлов для runtime (CA‑сертификаты, шаблоны, статические ассеты) и деплоится одинаково каждый раз.
Конфигурация должна быть внешней, не запекаться в бинарник. Используйте переменные окружения для большинства настроек (порты, хост БД, feature flags). Файл конфигурации — только для длинных или структурированных значений, и держите его специфичным для окружения. Если вы используете сервис конфигурации, относитесь к нему как к зависимости: фиксируйте права, логируйте аудит и имейте откатный план.
Секреты — это красная линия. Их не кладут в репозиторий, образ или логи CI. Не выводите строки подключения при старте. Храните секреты в секретном сторе CI и инжектируйте при деплое.
Чтобы артефакты были трассируемыми, встраивайте идентификацию в каждую сборку: тегируйте артефакт версией и commit hash, включайте метаданные сборки (версия, commit, время сборки) в info‑эндпоинт и записывайте тег артефакта в лог деплоя. Чтобы ответить на «что сейчас запущено», должно хватать одной команды или панели.
Если вы генерируете Go‑бэкенды (например, с AppMaster), такая дисциплина ещё важнее: регенерация безопасна, когда правила именования артефактов и конфигурации делают каждый релиз воспроизводимым.
Деплой в Kubernetes или на ВМ без сюрпризов
Большинство неудачных деплоев — не про «плохой код». Это несоответствие окружений: другая конфигурация, пропавшие секреты или сервис стартует, но не готов. Цель проста: деплоить один и тот же артефакт везде и менять лишь конфигурацию.
Kubernetes: делайте деплой контролируемым rollout’ом
В Kubernetes стремитесь к контролируемому rollout’у. Используйте rolling updates, чтобы менять поды постепенно, и добавьте readiness и liveness проверки, чтобы платформа знала, когда направлять трафик и когда перезапустить подвисший контейнер. Запросы ресурсов и лимиты тоже важны: Go‑сервис, который работает на большом CI‑раннере, может OOM‑питься на маленьком ноде.
Держите конфигурацию и секреты вне образа. Соберите один образ на коммит, затем инжектируйте окружение при деплое (ConfigMaps, Secrets или ваш secret manager). Так staging и production запускают одни и те же биты.
ВМ: systemd даст всё необходимое
Если деплоите на виртуальные машины, systemd может быть вашим «мини‑оркестратором». Сделайте unit‑файл с понятным рабочим каталогом, env‑файлом и политикой рестартов. Делайте логи предсказуемыми, отправляя stdout/stderr в лог‑коллектор или journald, чтобы инциденты не превращались в SSH‑погоню.
Вы всё ещё можете делать безопасные rollouts без кластера. Простой blue/green подход работает: держите две директории (или две ВМ), переключайте балансировщик и держите предыдущую версию готовой для быстрого отката. Canary похоже: отправляйте небольшой процент трафика новому релизу, прежде чем фиксировать его.
Прежде чем отмечать деплой как «завершённый», запустите одинаковый пост‑деплой смоук‑чек везде:
- Подтвердите, что health‑эндпоинт возвращает OK и зависимости доступны
- Выполните небольшое реальное действие (создать и прочитать тестовую запись)
- Проверьте, что версия/ID сборки соответствует коммиту
- Если чек падает — откат и оповещение
Если вы регенерируете бэкенды (например, AppMaster Go backend), такой подход остаётся стабильным: собрали один раз, деплоите артефакт, а различия задаёт конфигурация, а не ad‑hoc скрипты.
Распространённые ошибки, которые делают конвейеры ненадёжными
Упростите бизнес-логику бэкенда
Добавляйте бизнес-логику через drag-and-drop workflow’ы, а не переписывайте всё вручную.
Большинство сломанных релизов не из‑за «плохого кода». Они происходят, когда конвейер ведёт себя по‑разному в разные запуски. Чтобы CI/CD для Go‑бэкендов был спокойным и предсказуемым, следите за этими паттернами.
Шаблоны ошибок, приводящие к неожиданным падениям
Автоматический запуск миграций при каждом деплое без гейтров — классика. Миграция, которая блокирует таблицу, может положить загруженный сервис. Поставьте миграции за явным шагом, требуйте одобрения для продакшена и убедитесь, что их безопасно перезапускать.
Использование latest тегов или нефиксированных базовых образов — ещё один способ получить непредсказуемые ошибки. Пиньте Docker‑образы и версии Go, чтобы окружение сборки не дрейфовало.
Временное шаринг одной БД между окружениями обычно становится постоянным и приводит к утечке тестовых данных в staging и к тому, что staging‑скрипты бьют по проду. Разделяйте БД и креденшалы по окружениям, даже если схема одинаковая.
Отсутствие health и readiness‑чеков позволяет деплою «успешно» завершиться, в то время как сервис сломан и трафик начинает маршрутизироваться преждевременно. Добавьте проверки, соответствующие реальному поведению: может ли приложение стартовать, подключиться к БД и обслужить запрос.
Наконец, неясная ответственность за секреты, конфигурацию и доступ превращает релизы в угадайку. Нужно, чтобы кто‑то владел процессом создания, ротации и инъекции секретов.
Реалистичный сценарий: команда мерджит изменение, конвейер деплоит, и автоматическая миграция запускается первой. В staging всё проходит (малые данные), а в проде миграция тайм‑аутится (большие данные). С пиннутыми образами, разделением окружений и гейтом миграции деплой остановился бы безопасно.
Если вы генерируете Go‑бэкенды (например, с AppMaster), эти правила особенно важны, потому что регенерация может затронуть много файлов сразу. Предсказуемые входы и явные гейты не дадут «большим» изменениям превратиться в рискованные релизы.
Короткий чеклист для предсказуемого CI/CD
От идеи до Go API
Преобразуйте API, логику и дизайн базы данных в готовый к продакшену Go-исходник.
Используйте это как самопроверку для CI/CD Go‑бэкендов. Если на каждый пункт вы можете уверенно ответить «да», релизы становятся проще.
- Зафиксируйте окружение, а не только код. Пиньте версию Go и образ сборочного контейнера, используйте одинаковую настройку локально и в CI.
- Сделайте конвейер из 3 простых команд. Одна команда собирает, одна запускает тесты, одна производит деплоируемый артефакт.
- Относитесь к миграциям как к коду продакшена. Требуйте логов для каждой миграции и документируйте, что значит «откат» для вашего приложения.
- Производите неизменяемые артефакты, которые можно трассировать. Собирайте один раз, тегируйте commit SHA и продвигайте между окружениями без пересборки.
- Деплойте с проверками, которые падают быстро. Добавьте readiness/liveness и короткий смоук‑тест, который запускается при каждом деплое.
Ограничьте доступ к продакшену и делайте его аудитируемым. CI должен деплоить от имени выделённого сервисного аккаунта, секреты — храниться централизованно, а любые ручные действия в проде — оставлять чёткий след (кто, что, когда).
Реалистичный пример и шаги, которые можно начать уже на этой неделе
Небольшая ops‑команда из четырёх человек выпускает релиз раз в неделю и часто регенерирует Go‑бэкенд, потому что продуктовая команда допиливает рабочие процессы. Их цель проста: меньше ночных фиксов и релизов без сюрпризов.
Типичное изменение в пятницу: добавляют новое поле в customers (изменение схемы) и обновляют API, который его пишет (изменение кода). Конвейер обрабатывает это как единый релиз. Он собирает один артефакт, запускает тесты против этого же артефакта и только затем применяет миграции и деплоит. Так база не оказывается впереди кода, а код не деплоится без соответствующей схемы.
Когда в релизе есть изменение схемы, конвейер добавляет safety‑gate. Он проверяет, что миграция добавляющая (например, nullable‑поле), и помечает рискованные действия (drop column, переработка огромной таблицы). Если миграция рискованна, релиз останавливается перед продом. Команда либо переписывает миграцию безопаснее, либо планирует окно релиза.
Если тесты падают, ничего не идёт дальше. То же и для проваленных миграций в пред‑проде. Конвейер не должен пытаться «пробить» изменения «на этот раз».
Простые шаги, которые работают для большинства команд:
- Начните с одного окружения (dev‑деплой, который можно легко сбросить).
- Заставьте конвейер всегда производить один версионированный артефакт.
- В dev запускайте миграции автоматически, а в проде требуйте одобрения.
- Добавляйте staging только после стабилизации dev в течение нескольких недель.
- Добавьте прод‑гейт, требующий зелёных тестов и успешного деплоя в staging.
Если вы генерируете бэкенды с AppMaster, держите регенерацию в тех же этапах конвейера: регенерация, сборка, тесты, миграция в безопасном окружении, затем деплой. Обращайтесь с сгенерированным исходником как с обычным исходником: каждый релиз должен воспроизводиться из тегированной версии теми же шагами.
Вопросы и ответы
Зафиксируйте версию Go и окружение сборки, чтобы одни и те же входные данные всегда дали одинаковый бинарник или образ. Это убирает разницу «у меня работает» и облегчает воспроизведение и починку ошибок.
Регенерация может менять эндпойнты, модели данных и зависимости, даже если никто не трогал код вручную. Конвейер пропускает такие изменения через те же проверки каждый раз, чтобы регенерация была безопасной, а не рискованной.
Собирайте один артефакт и продвигайте его через dev, staging и prod. Пересборка для каждого окружения увеличивает риск отправить в прод то, что вы не тестировали.
На каждое pull request запускайте быстрые проверки: форматирование, базовый статический анализ, сборка и unit-тесты с таймаутами. Пусть они будут достаточно быстрыми, чтобы разработчики не обходили их, и достаточно строгими, чтобы ломать ранние ошибки.
Сделайте небольшой интеграционный этап, который поднимает сервис с production-подобными настройками и общается с реальными зависимостями, например PostgreSQL. Цель — поймать «компилируется, но не стартует» и явные нарушения контракта, не превращая CI в многочасовой full E2E прогон.
Рассматривайте миграции как контролируемый этап релиза, а не как то, что запускается автоматически при каждом деплое. Запускайте их с понятными логами и блокировкой на один запуск, и честно подходите к откату: многие изменения схемы нельзя просто «откатить» обратно.
Добавьте readiness-проверки, чтобы трафик шел только к реально готовым подам, и liveness-проверки, чтобы платформа могла перезапустить зависшие контейнеры. Также задайте реальные requests/limits — сервис, прошедший CI, может быть OOM-killed в проде при малых ресурсах.
Простой systemd-юнит и предсказуемый сценарий релиза часто дают спокойные деплои на ВМ. По возможности используйте ту же модель артефактов, что и для контейнеров, и добавьте короткий пост-деплой смоук-чек, чтобы «успешный рестарт» не скрывал поломку.
Ни в коем случае не храните секреты в репозитории, артефакте сборки или логах CI. Инжектируйте секреты во время деплоя из управляемого хранилища секретов, ограничивайте доступ и делайте регулярную ротацию рутинной операцией.
Включите регенерацию в те же этапы, что и любые изменения: регенерация, сборка, тестирование, упаковка, затем миграция и деплой с необходимыми гейтами. Если вы используете AppMaster, такой подход позволяет быстро регенерировать и уверенно выпускать изменения без догадок, что именно изменилось.
Фиксируйте окружение (версия Go, образ раннера), собирайте один именованный артефакт, прогоняйте тесты и храните логи миграций — так проще понять, что именно попало в прод и как откатиться при проблеме.