
機器予約アプリで競合を防ぎ、返却を追跡する
二重予約を防ぎ、返却と破損を記録し、故障した機器を保守対象にする機器予約アプリの設計方法を紹介します。
Firebase の NoSQL データベース ソリューションである Firestore を詳しく調べ、その機能、利点、ユースケースを探ります。他のデータベースとの比較や、アプリ開発プロセスをどのように改善できるかを学びましょう。

Cloud Firestore とも呼ばれる Firestore は、最新の Web およびモバイル アプリケーションを構築するためのスケーラブルで汎用性の高いプラットフォームを開発者に提供するように設計された Google Firebase の NoSQL データベース ソリューションです。 Firestore は、リアルタイムのデータ同期、保存、取得を可能にすると同時に、オフライン サポート、階層型データ編成、包括的なクエリ機能セットなどの強力な機能を提供します。
Google が提供する開発プラットフォームである Firebase は、アプリケーションを簡単に構築、管理、デプロイするための一連のツールを提供します。 Firestore はこのスイートの一部であり、アプリケーションでのデータの永続化と管理のプロセスを簡素化する強力で信頼性の高いデータベース ソリューションとして機能します。
Firestore は開発者にさまざまな利点を提供し、Web アプリケーションやモバイル アプリケーションでデータを管理するための魅力的な選択肢となっています。 Firestore の重要な利点には次のようなものがあります。
Firestore のリアルタイム同期機能により、複数のデバイスやプラットフォーム間でのデータ配信が容易になり、関連する更新や変更がすべてのユーザーに即座に反映されます。この同期機能は、開発者が最小限の労力で高度にインタラクティブで協調的なアプリケーションを構築するのに役立ちます。
Firestore は、Web アプリケーションとモバイル アプリケーションの両方にオフライン サポートを組み込み、開発者がユーザーがインターネットに接続していない場合でもシームレスに機能するアプリを作成できるようにします。 Firestore はデータをデバイス上でローカルにキャッシュし、接続が復元されると更新をサーバーと同期します。
Firestore は豊富なクエリ API を提供しており、開発者はデータを簡単にフィルタリング、並べ替え、操作する複雑なクエリを作成できます。 Firestore はカーソルベースのページネーションもサポートしているため、アプリケーションは大規模なデータセットを効率的に読み込んで表示できます。
Firestore は、コレクションとドキュメント内のデータを整理する階層データ モデルを使用し、複雑でネストされたデータ構造に対応します。このアプローチにより、高い柔軟性と拡張性を提供しながら、データの構造化と管理が容易になります。
Firestore は高スケール向けに設計されており、パフォーマンスを損なうことなく数百万の同時接続を処理し、広範なデータセットを管理します。この機能により、Firestore は、要求の厳しいパフォーマンス要件を持つ高トラフィック アプリケーションにとって実行可能な選択肢になります。
Firestore のデータ モデルは、データの階層的な編成と管理を提供するコレクションとドキュメントの概念に基づいています。このセクションでは、Firestore のデータ モデルの主要な要素の概要を説明し、それらがどのように機能するかを説明します。
Firestore では、コレクションはドキュメントを保持するコンテナです。コレクションは、クエリと管理を容易にする方法でデータを整理するのに役立ちます。コレクションにはサブコレクションを含めることもでき、関連データの論理グループをさらに細分化できます。
ドキュメントは、実際のデータ値を保持する Firestore 内の個々のレコードです。一般に、ドキュメントはフィールドと呼ばれるキーと値のペアで構成され、それぞれに名前と対応する値が付いています。 Firestore は、文字列、数値、ブール値、配列、マップなどを含む、フィールドのさまざまなデータ型をサポートしています。 Firestore のドキュメントは、データとサブコレクションの両方を含むコンテナーと考えることができます。この入れ子構造により、アプリケーション内の複雑なデータ構造を設計および管理する際の柔軟性が向上します。
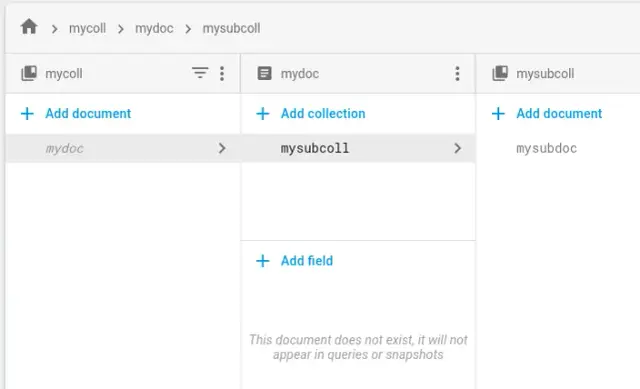
画像ソース: Firebase ドキュメント
Firestore の階層データ モデルにより、開発者はデータを効率的かつ直感的に構造化および整理できます。たとえば、 e コマース アプリは、 次の構造でデータを Firestore に保存する場合があります。
この構造では、Products コレクションに Product ドキュメントが含まれており、それぞれが個別の製品を表します。これらの文書には、名前、価格、カテゴリ情報のフィールドが含まれています。各製品ドキュメントには、ユーザーが作成した製品レビューのレビュー ドキュメントを含むレビュー サブコレクションがあります。 Firestore の階層データ モデルを利用することで、開発者は複雑なデータ構造を簡単に作成および管理でき、アプリケーションのパフォーマンス、スケーラビリティ、保守性を確保できます。
アプリケーションでの Firestore のセットアップは簡単なプロセスです。最初のステップは、すべての Firebase 製品とサービスを管理するための一元的なスペースを提供する Firebase プロジェクトを作成することです。 Firestore を設定するための重要な手順は次のとおりです。
Firebase プロジェクトを作成する: Firebase アカウントにサインアップし、新しいプロジェクトを作成するか、すでにプロジェクトを持っている場合は既存のプロジェクトを使用します。 Firebase コンソールに移動し、画面上の指示に従います。
Firestore をプロジェクトに追加する: プロジェクトが設定されたら、左側のメニューの [データベース] セクションをクリックします。 「データベースの作成」を選択し、ポップアップウィンドウで「Firestore」を選択します。セットアップ オプションに従って、Firebase プロジェクト内に新しい Firestore データベース インスタンスを作成します。
Firebase SDK を構成する: ウェブアプリまたはモバイルアプリで Firestore を使用するには、Firebase SDK をプロジェクトに追加する必要があります。 SDK 設定コード スニペットは、Firebase コンソールの「プロジェクト設定」にあります。設定コードには、プロジェクトの一意の API キー、認証ドメイン、プロジェクト ID、および Firebase サービスに接続するために必要なその他の設定が含まれます。コード スニペットをアプリケーションの HTML、JavaScript、Android、または iOS プロジェクトに追加します。
Firestore を初期化する: Firebase SDK をプロジェクトに追加した後、次のコード スニペットを使用して Firestore を初期化します。
JavaScript の場合:
import { initializeApp } from 'firebase/app'; import { getFirestore } from 'firebase/firestore'; const firebaseApp = initializeApp({ apiKey: "[API_KEY]", authDomain: "[AUTH_DOMAIN]", projectId: "[PROJECT_ID]", ... }); const db = getFirestore(firebaseApp);
Android (Kotlin) の場合:
import com.google.firebase.FirebaseApp import com.google.firebase.firestore.FirebaseFirestore val firebaseApp = FirebaseApp.initializeApp(this) val db = FirebaseFirestore.getInstance()
iOS (Swift) の場合:
import FirebaseFirestore let db = Firestore.firestore()
Firestore の使用を開始する: Firestore を初期化すると、Firestore を使用してデータの読み取りと書き込み、リアルタイム リスナーの設定、データに対するさまざまな操作を実行できるようになります。
Firebase は、Firebase Realtime Database と Firestore という 2 つのデータベース ソリューションを提供します。どちらのデータベースもリアルタイムのデータ同期と、Web およびモバイル プラットフォーム用のクライアント SDK を提供しますが、いくつかの点で異なります。 2 つのデータベースを比較してみましょう。
Firebase Realtime Database は、ノードの大きなツリーである JSON のようなデータ モデルを使用します。このデータ モデルでは、特に階層データやネストされた配列の場合、複雑なデータのクエリと構造化が困難になる可能性があります。一方、Firestore はコレクションとドキュメントを含む階層データ モデルを使用し、データの構造化とクエリのより直感的な方法を提供します。 Firestore データ モデルでは、ネストされたサブコレクションが可能であり、複雑でネストされたデータをより効率的に管理するのに役立ちます。
Firestore は、Realtime Database と比較して、より包括的なクエリ機能を提供します。 Firestore を使用すると、開発者は複数の orderBy 句や where 句の連鎖、配列操作の実行、結果のページ分割などの複雑なクエリを実行できます。対照的に、Realtime Database のクエリ機能はより制限されているため、追加の計算コストやクライアント側またはサーバー側のロジックの複雑さを伴わずに、複雑なクエリやページネーションを実行することが困難になります。
Firestore は、強力な水平スケーラビリティと、数百万の同時ユーザーと数十億のドキュメントを処理できる機能を備えた、世界規模のアプリ向けに設計されています。リアルタイム データベースは、特定のケースには適していますが、データ シャーディング戦略に依存せずに拡張するのが難しい場合があります。 Firestore は、低レイテンシのアクセスと自動マルチリージョン レプリケーションを保証して高可用性と耐久性を維持し、エンタープライズや高トラフィックのユースケースに適しています。
Firestore と Realtime Database の価格構造は異なります。 Firestore の料金は、ドキュメントの読み取り、書き込み、削除、データ ストレージとネットワークの使用量に基づいて計算されます。 Realtime Database の料金は、保存されているデータの量、データベース接続の数、およびネットワークの使用量に基づいています。アプリケーションのデータ アクセス パターンと使用状況によっては、1 つのデータベースの方がコスト効率が高い場合があります。
Firestore と Realtime Database はリアルタイム データ同期機能を提供しますが、Firestore は複雑なクエリ、階層データ構造、グローバル スケールのパフォーマンスを必要とするアプリケーションにより適しています。 Realtime Database は、JSON のようなデータ モデルと低コストの価格体系がより合理的である、より単純なユースケースに適している可能性があります。
Firestore は包括的なクエリ機能のセットを提供し、開発者がデータを効果的に取得およびフィルタリングできるようにします。基本的なクエリには、単一のドキュメントの取得、ドキュメントのコレクションの取得、フィールド値に基づくドキュメントのフィルタリングが含まれます。より高度なクエリには、結果の並べ替え、制限、ページ分割が含まれます。一般的な Firestore クエリをいくつか見てみましょう。
ID によって単一のドキュメントをフェッチするには、次のコード スニペットを使用できます。
// JavaScript import { getDoc, doc } from 'firebase/firestore'; async function getDocument(documentId) { const documentRef = doc(db, 'collection_name', documentId); const documentSnapshot = await getDoc(documentRef); if (documentSnapshot.exists()) { console.log('Document data:', documentSnapshot.data()); } else { console.log('No such document'); } }
コレクション内のすべてのドキュメントを取得するには、次のコード スニペットを使用します。
// JavaScript import { getDocs, collection } from 'firebase/firestore'; async function getAllDocuments() { const collectionRef = collection(db, 'collection_name'); const querySnapshot = await getDocs(collectionRef); querySnapshot.forEach((doc) => { console.log(doc.id, '=>', doc.data()); }); }
Firestore を使用すると、1 つまたは複数のフィールド条件に基づいてドキュメントをフィルタリングできます。次のコード スニペットは、単一フィールドに基づいてドキュメントをフィルタリングする方法を示しています。
// JavaScript import { query, where, getDocs, collection } from 'firebase/firestore'; async function getFilteredDocuments() { const collectionRef = collection(db, 'collection_name'); const q = query(collectionRef, where('field_name', '==', 'value')); const querySnapshot = await getDocs(q); querySnapshot.forEach((doc) => { console.log(doc.id, '=>', doc.data()); }); }
結果を並べ替えたりページ番号を付けたりするには、orderBy、limit、startAfter または startAt メソッドを使用できます。ドキュメントを並べ替えてページ付けする方法は次のとおりです。
// JavaScript import { query, orderBy, limit, getDocs, collection, startAfter } from 'firebase/firestore'; async function getSortedAndPaginatedDocuments(lastVisible) { const collectionRef = collection(db, 'collection_name'); const q = query( collectionRef, orderBy('field_name', 'asc'), startAfter(lastVisible), limit(10) ); const querySnapshot = await getDocs(q); querySnapshot.forEach((doc) => { console.log(doc.id, '=>', doc.data()); }); }
これらは、Firestore が開発者に提供するクエリ機能のほんの一例であり、さまざまなアプリケーションの必要に応じてデータに簡単かつ効率的にアクセスしてフィルタリングできるようになります。
Firestore セキュリティ ルールは、ユーザー認証とカスタム条件に基づいて Firestore データへのアクセスを制御する強力な方法です。セキュリティ ルールを作成して構成することで、ユーザーが必要なリソースにのみアクセスできるようにし、機密情報を保護し、意図しないデータ変更を防ぐことができます。
Firestore のセキュリティ ルールは Firebase コンソールに保存され、Firestore データベースとともにデプロイされます。これらはカスタム構文を使用し、Firebase コンソール内またはローカル開発環境を使用して作成およびテストできます。 Firestore セキュリティ ルールの使用を開始するには、いくつかの一般的なシナリオとその実装方法を見てみましょう。
rules_version = '2'; service cloud.firestore { match /databases/{database}/documents { match /public_data/{document=**} { allow read; } } }request.auth オブジェクトを使用してユーザーの認証ステータスを確認できます。 rules_version = '2'; service cloud.firestore { match /databases/{database}/documents { match /private_data/{document=**} { allow read: if request.auth != null; } } }rules_version = '2'; service cloud.firestore { match /databases/{database}/documents { match /user_data/{userId}/{document=**} { allow write: if request.auth.uid == userId; } } }rules_version = '2'; service cloud.firestore { match /databases/{database}/documents { match /user_profiles/{userId} { allow create, update: if request.auth.uid == userId && request.resource.data.displayName.size() < 30; } } }これらの例は、Firestore セキュリティ ルールの一般的な使用例をいくつか示していますが、可能性はほぼ無限です。表現力豊かな構文と強力なマッチング機能を使用して、Firestore データを保護し、安全な環境を維持する複雑なセキュリティ ルールを作成できます。
Firestore は、高速で信頼性の高いリアルタイム データ同期を提供するように設計されていますが、最高のユーザー エクスペリエンスを確保するには、Firestore データベースのパフォーマンスを最適化することが不可欠です。 Firestore を最大限に活用するためのヒントをいくつか紹介します。
これらのパフォーマンス最適化のヒントに従い、Firestore の使用状況を監視することで、Firestore ベースのアプリケーションが可能な限り最高のエクスペリエンスをユーザーに提供できるようになります。
Firestore は従量課金制の価格モデルで動作し、コストは次のようなさまざまなリソースの使用量によって決まります。
これらの従量課金制の料金に加えて、Firestore は Firebase 無料プランの一部として次のような豊富な無料枠を提供しています。
Firestore の価格モデルでは、アプリケーションの要件の進化に応じた柔軟性と拡張性が可能になります。パフォーマンスとコスト効率のバランスをとるために、使用状況を監視し、Firestore 実装を最適化することが重要です。
Firestore セキュリティ ルールを理解し、パフォーマンスを最適化し、コストを効果的に管理することで、この強力な NoSQL データベース ソリューションを Firebase アプリケーションで最大限に活用できます。効率的な ノーコード アプリ構築エクスペリエンスを実現するには、Firestore と AppMaster の統合を忘れずに検討してください。
Firestore の強力な機能、リアルタイムのデータ同期、スケーラブルなアーキテクチャにより、幅広いアプリケーションや業界にとって理想的なソリューションとなります。
アプリの構築とメンテナンスをさらに簡素化および迅速化するために、 AppMasterアプリケーションのプライマリ データ ストア ソリューションとして Firestore をシームレスに統合できます。 AppMaster 、ユーザーがコード行を記述せずにバックエンド、Web、 モバイル アプリ を構築できるno-codeプラットフォームを提供します。
Firestore との統合は REST API および WSS エンドポイントを通じて実現できるため、開発者はAppMasterプラットフォームを使用して Firestore データに効率的にアクセスして管理できます。 Firestore の強力なリアルタイム データ同期をAppMasterのdrag-and-dropインターフェイス、柔軟な データ モデル、ビジュアル デザイン システムと組み合わせることで、プロフェッショナルでユーザーフレンドリーな Web アプリやモバイル アプリを 10 倍の速度で 3 倍のコストで作成できます。従来の開発方法よりも効果的です。
さらに、 AppMasterには Business Process (BP) Designer が搭載されており、ユーザーは手動でコーディングすることなく、バックエンド、Web、またはモバイル アプリケーションのロジックを視覚的に作成できます。 Firestore とAppMasterを組み合わせることで、リアルタイム同期が可能になり、技術的負債が排除され、コストのかかる手動コーディングへの依存が排除され、Firestore はこれまで以上に多用途になります。
Google Firestore は、リアルタイムのデータ同期やオフライン サポートなど、最新のアプリ開発に役立つ強力でスケーラブルかつ柔軟な NoSQL データベース ソリューションです。その階層データ モデル、強力なクエリ機能、セキュリティ ルールにより、Web およびモバイル アプリケーション用の包括的なデータ ソリューションを求める開発者にとって魅力的な選択肢となります。
Firestore をAppMasterno-codeプラットフォームと統合することで、その高度な機能を活用しながら、 no-code開発環境のシンプルさ、スピード、費用対効果の恩恵を受けることができます。 Firestore のパワーをAppMasterのビジュアル デザイン システム、柔軟なデータ モデル、ビジネス プロセス デザイナーと組み合わせることで、今日の進化し続けるデジタル領域に対応する高性能アプリケーションを効率的に構築できます。
Firestore は Google Firebase の NoSQL データベース ソリューションであり、最新の Web およびモバイル アプリケーションを構築するためのスケーラブルなリアルタイム データ同期と管理を提供するように設計されています。
Firestore は、リアルタイム同期、オフライン サポート、包括的なクエリ サポート、階層データ構造、強力なスケーラビリティ、および堅牢なセキュリティ ルールをアプリ開発者に提供します。
Firestore は、Firebase Realtime Database と比較して、より柔軟なデータ モデル、優れたクエリ サポート、および向上したスケーラビリティを提供します。ただし、特定の使用例では、Realtime Database の方がシンプルでコスト効率が高い場合があります。
Firestore はデータをコレクションとドキュメントに整理し、階層構造を提供します。コレクションにはドキュメントが含まれ、ドキュメントにはサブコレクションが含まれる場合があるため、開発者は複雑なネストされたデータを効率的に保存できます。
はい。Firestore は、Web アプリケーションとモバイル アプリケーションの両方に強力なスケーラビリティを提供するように設計されており、要求の厳しいパフォーマンス要件を持つ高トラフィック アプリケーションにとって理想的な選択肢となります。
Firestore は、REST API と WSS エンドポイントを使用してAppMasterプラットフォームと簡単に統合でき、開発者はno-codeバックエンド、Web、モバイル アプリケーションで Firestore データに効率的にアクセスして管理できるようになります。
Firestore をアプリケーションに設定するには、Firebase 経由で接続し、Firestore ライブラリを初期化し、アプリの環境内で動作するように必要なオプションを構成します。
Firestore セキュリティ ルールは、Firestore データへのアクセスを管理するのに役立つ構成設定であり、さまざまな条件に基づいてデータ アクセスと変更を保護および検証できるようになります。
Firestore の価格は従量課金制モデルに基づいており、ドキュメント ストレージ、ドキュメントの読み取り、書き込み、削除、ネットワーク使用量のコストが含まれます。無料利用枠は、Firebase の無料枠を通じて利用できます。




