App de reserva de equipamentos: evite conflitos e acompanhe as devoluções
Planeje um app de reserva de equipamentos que evite reservas duplicadas, registre devoluções e danos e coloque itens com problemas em manutenção.
Aprenda a modelar temporizadores e escalonamentos de SLA com estados claros, regras fáceis de manter e caminhos de escalonamento simples para que apps de workflow continuem fáceis de alterar.
Regras baseadas em tempo normalmente começam simples: “Se um ticket não tiver resposta em 2 horas, notifique alguém.” Depois o fluxo cresce, equipes adicionam exceções e, de repente, ninguém tem certeza do que acontece. É assim que temporizadores de SLA e escalonamentos viram um labirinto.
Ajuda nomear as partes móveis de forma clara.
Um temporizador é o relógio que você inicia (ou agenda) após um evento, como “ticket passou para Waiting for Agent”. Um escalonamento é o que você faz quando esse relógio atinge um limite, como notificar um líder, mudar prioridade ou reatribuir o trabalho. Uma violação é o fato registrado que diz “perdemos o SLA”, usado para relatórios, alertas e follow-up.
Problemas aparecem quando a lógica de tempo fica espalhada pelo app: algumas verificações no fluxo de “atualizar ticket”, mais verificações em um job noturno e regras pontuais adicionadas depois para um cliente especial. Cada peça faz sentido isoladamente, mas juntas criam surpresas.
Sintomas típicos:
O objetivo é comportamento previsível e fácil de alterar depois: uma fonte única de verdade para o tempo de SLA, estados de violação explícitos que você pode reportar e passos de escalonamento que podem ser ajustados sem caçar a lógica visual.
Antes de construir temporizadores, escreva a promessa exata que você está medindo. Muito da lógica confusa vem de tentar cobrir todas as regras de tempo desde o dia 1.
Tipos comuns de SLA parecem semelhantes, mas medem coisas diferentes:
Em seguida, decida o que “tempo” significa. Tempo de calendário conta 24/7. Tempo de trabalho conta apenas horas comerciais definidas (por exemplo, seg-sex, 9h–18h). Se você não precisa realmente de tempo de trabalho, evite-o no início. Ele adiciona casos de borda como feriados, fusos e dias parciais.
Depois, seja específico sobre pausas. Uma pausa não é só “status mudou.” É uma regra com dono. Quem pode pausar (apenas agente, apenas sistema, ação do cliente)? Quais status pausam (Waiting on Customer, On Hold, Pending Approval)? O que retoma? Ao retomar, você continua com o tempo restante ou reinicia o temporizador?
Por fim, defina o que uma violação significa em termos do produto. Uma violação deve ser algo concreto que você possa armazenar e consultar, por exemplo:
Exemplo: “First response SLA breached” pode significar que o ticket ganha um estado Violado, um breached_at timestamp e um nível de escalonamento definido como 1.
Se você quer que temporizadores e escalonamentos de SLA continuem legíveis, trate o SLA como uma pequena máquina de estados. Quando a “verdade” é espalhada por verificações pequenas (se agora > due, se prioridade é alta, se última resposta está vazia), a lógica visual fica confusa rápido e pequenas mudanças quebram coisas.
Comece com um conjunto curto e combinado de estados de SLA que todo passo do fluxo entenda. Para muitas equipes, estes cobrem a maioria dos casos:
Uma única flag breached = true/false raramente é suficiente. Você ainda precisa saber qual SLA violou (primeira resposta vs resolução), se está atualmente pausado e se você já escalou. Sem esse contexto, as pessoas começam a derivar significado de comentários, timestamps e nomes de status. É aí que a lógica fica frágil.
Torne o estado explícito e armazene os timestamps que o expliquem. Então as decisões ficam simples: seu avaliador lê o registro, decide o próximo estado e todo o resto reage a esse estado.
Campos úteis para armazenar junto ao estado:
started_at e due_at (qual relógio estamos rodando e quando vence?)breached_at (quando realmente ultrapassou o prazo?)paused_at e paused_reason (por que o relógio parou?)breach_reason (qual regra disparou a violação, em termos claros)last_escalation_level (para não notificar o mesmo nível duas vezes)Exemplo: um ticket passa para “Waiting on customer.” Defina o estado de SLA para Pausado, registre paused_reason = "waiting_on_customer" e pare o temporizador. Quando o cliente responder, retome definindo um novo started_at (ou despausando e recalculando due_at). Sem caçar muitas condições.
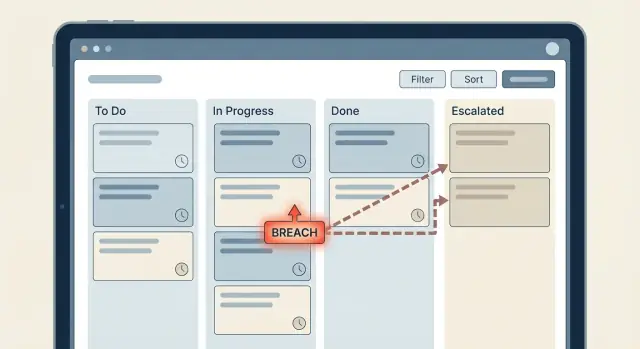
Uma escada de escalonamento é um plano claro do que acontece quando um temporizador de SLA está perto de violar ou já violou. O erro é copiar o organograma para o fluxo. Você quer o menor conjunto de passos que faça o item parado voltar a andar.
Uma escada simples que muitas equipes usam: o agente designado (Nível 0) recebe o primeiro lembrete, depois o líder de equipe (Nível 1) é acionado, e só depois disso vai para um gerente (Nível 2). Funciona porque começa onde o trabalho pode ser feito e só escala a autoridade quando necessário.
Para manter as regras de escalonamento fáceis de manter, armazene limites de escalonamento como dados, não condições codificadas. Coloque-os em uma tabela ou objeto de configurações: “primeiro lembrete após 30 minutos” ou “escalar para líder após 2 horas.” Quando a política mudar, você atualiza um lugar em vez de editar vários fluxos.
Escalonamentos viram spam quando disparam com muita frequência. Adicione salvaguardas para que cada passo tenha um propósito:
Notificações sozinhas não resolvem trabalho parado se a responsabilidade ficar confusa. Defina regras de ownership: o ticket continua atribuído ao agente, é reatribuído ao líder, ou vai para uma fila compartilhada?
Exemplo: após escalonamento Nível 1, reatribua ao líder de equipe e marque o agente original como observador. Isso deixa claro quem deve agir a seguir e evita que o item fique quicando entre pessoas.
A maneira mais fácil de manter temporizadores e escalonamentos de SLA é tratá‑los como um pequeno sistema com três partes: eventos, um avaliador e ações. Isso evita que a lógica de tempo se espalhe por dezenas de verificações “se tempo > X”.
Eventos são fatos simples que não devem conter cálculos de tempo. Eles respondem “o que mudou?” e não “o que devemos fazer sobre isso?” Eventos típicos incluem ticket criado, agente respondeu, cliente respondeu, status alterado, ou pausa/retomada manual.
Armazene-os como timestamps e campos de status (por exemplo: created_at, last_agent_reply_at, last_customer_reply_at, status, paused_at).
Faça um único passo “avaliador de SLA” que rode após qualquer evento e em uma agenda periódica. Esse avaliador é o único lugar que calcula due_at e tempo restante. Ele lê os fatos atuais, recalcula prazos e escreve campos de estado de SLA explícitos como sla_response_state e sla_resolution_state.
É aqui que a modelagem de estado de violação fica limpa: o avaliador define estados como OK, Em risco, Violado, em vez de esconder lógica dentro de notificações.
Notificações, atribuições e escalonamentos devem disparar apenas quando um estado mudar (por exemplo: OK -> Aviso). Mantenha o envio de mensagens separado da atualização do estado de SLA. Assim você pode mudar quem é notificado sem tocar nos cálculos.
Uma configuração de fácil manutenção geralmente se parece com isto: alguns campos no registro, uma pequena tabela de políticas e um avaliador que decide o que acontece a seguir.
Comece com a entidade que possui o SLA (ticket, pedido, requisição). Adicione timestamps explícitos e um único campo “estado atual do SLA”. Mantenha simples e previsível.
Depois, adicione uma pequena tabela de políticas que descreva regras em vez de codificá‑las em muitos fluxos. Uma versão simples é uma linha por prioridade (P1, P2, P3) com colunas para minutos-alvo e limites de escalonamento (por exemplo: aviso em 80%, violação em 100%). A diferença entre mudar um registro e editar cinco fluxos é grande.
Em vez de criar temporizadores separados por todo lado, use um processo agendado que verifique itens periodicamente (a cada minuto para SLAs estritos, a cada 5 minutos para muitas equipes). A agenda chama um avaliador que:
sla_state e next_check_atIsso facilita porque você depura um avaliador, não muitos timers.
O avaliador deve emitir tanto o novo estado quanto se ele mudou. Só dispare mensagens ou crie tarefas quando o estado mudar (por exemplo Em dia -> Aviso, Aviso -> Violado). Se o registro permanecer Violado por uma hora, você não quer 12 notificações repetidas.
Um padrão prático: armazene sla_state e last_escalation_level, compare com os valores recém calculados e só então chame o sistema de mensagens (email/SMS/Telegram) ou crie uma tarefa interna.
Pausas são onde regras de tempo geralmente se complicam. Se você não as modelar claramente, seu SLA ou continua rodando quando não deveria, ou reinicia quando alguém clica no status errado.
Uma regra simples: apenas um status (ou um pequeno conjunto) pausa o relógio. Uma escolha comum é Waiting for customer. Quando um ticket vai para esse status, registre um timestamp pause_started_at. Quando o cliente responde e o ticket sai desse status, feche a pausa escrevendo pause_ended_at e some a duração em paused_total_seconds.
Não mantenha só um contador. Capture cada janela de pausa (início, fim, quem ou o que a desencadeou) para ter trilha de auditoria. Depois, quando alguém perguntar por que um caso violou, você pode mostrar que ficou 19 horas esperando o cliente.
Reatribuição e mudanças normais de status não devem reiniciar o relógio. Mantenha timestamps de SLA separados dos campos de ownership. Por exemplo, sla_started_at e sla_due_at devem ser definidos uma vez (na criação ou quando a política muda), enquanto reassignment só atualiza assignee_id. Seu avaliador então calcula tempo decorrido como: agora menos sla_started_at menos paused_total_seconds.
Regras que mantêm temporizadores e escalonamentos previsíveis:
Uma forma simples de testar seu design é um ticket com dois SLAs: primeira resposta em 30 minutos e resolução completa em 8 horas. É aí que a lógica costuma quebrar se estiver espalhada por telas e botões.
Suponha que cada ticket guarde: state (New, InProgress, WaitingOnCustomer, Resolved), response_status (Pending, Warning, Breached, Met), resolution_status (Pending, Warning, Breached, Met), além de timestamps como created_at, first_agent_reply_at e resolved_at.
Linha do tempo realista:
Para escalonamentos, mantenha uma cadeia clara que dispare em transições de estado. Por exemplo, quando resposta virar Aviso, notifique o agente responsável. Quando virar Violado, notifique o líder de equipe e atualize a prioridade.
Em cada passo, atualize o mesmo pequeno conjunto de campos para ficar fácil de raciocinar:
response_status ou resolution_status para Pending, Warning, Breached ou Met.*_warning_at e *_breach_at timestamps uma vez e nunca os sobrescreva.escalation_level (0, 1, 2) e defina escalated_to (Agent, Lead, Manager).sla_events com o tipo de evento e quem foi notificado.priority e due_at para que UI e relatórios mostrem o escalonamento.A chave é que Aviso e Violado são estados explícitos. Você os vê nos dados, audita e muda a escada depois sem caçar verificações de tempo escondidas.
A lógica de SLA fica bagunçada quando se espalha. Uma verificação rápida de tempo adicionada a um botão aqui, um alerta condicional ali e logo ninguém explica por que um ticket escalou. Mantenha temporizadores e escalonamentos como uma peça pequena e central de lógica que todas as telas e ações consultem.
Uma armadilha comum é embutir checagens de tempo em muitos lugares (telas de UI, handlers de API, ações manuais). A correção é computar o status de SLA em um avaliador e armazenar o resultado no registro. As telas devem ler o status, não inventá‑lo.
Outra armadilha é deixar timers discordarem porque usam relógios diferentes. Se o navegador calcula “minutos desde criado” e o backend usa tempo do servidor, você verá casos de borda com suspensão, fusos e mudanças de horário. Prefira tempo do servidor para qualquer coisa que dispare um escalonamento.
Notificações também podem virar barulho rapidamente. Se você “verifica a cada minuto e envia se atrasado”, as pessoas podem receber spam a cada minuto. Vincule mensagens a transições: “aviso enviado”, “escalado”, “violado”. Assim você envia uma vez por etapa e pode auditar o que aconteceu.
A lógica de horas comerciais é outra fonte de complexidade acidental. Se cada regra tem seu próprio “se for fim de semana então…”, atualizações ficam penosas. Coloque a matemática de horas comerciais em uma função (ou bloco compartilhado) que retorne “minutos de SLA consumidos até agora” e reutilize-a.
Por fim, não confie em recomputar a violação do zero. Armazene o momento em que ocorreu:
breached_at na primeira vez que detectar uma violação e nunca o sobrescreva.escalation_level e last_escalated_at para que ações sejam idempotentes.notified_warning_at (ou similar) para evitar alertas repetidos.Exemplo: um ticket atinge “Response SLA breached” às 10:07. Se você só recomputar, uma mudança de status posterior ou bug de pausa/retomada pode fazer parecer que a violação aconteceu às 10:42. Com breached_at = 10:07, relatórios e postmortems permanecem consistentes.
Antes de adicionar timers e alertas, faça uma passada com o objetivo de tornar as regras legíveis daqui a um mês.
Um teste prático: escolha um ticket perto de violar e reproduza sua linha do tempo. Se você não consegue explicar o que acontecerá a cada mudança de status sem ler todo o fluxo, seu modelo está espalhado demais.
Construa a menor fatia útil primeiro. Escolha um SLA (por exemplo, primeira resposta) e um nível de escalonamento (por exemplo, notificar o líder da equipe). Você vai aprender mais em uma semana de uso real do que em um design perfeito no papel.
Mantenha limites e destinatários como dados, não lógica. Coloque minutos e horas, regras de horas úteis, quem recebe notificações e qual fila possui o caso em tabelas ou registros de configuração. Assim o fluxo fica estável enquanto o negócio ajusta números e roteamento.
Planeje uma visão de dashboard simples desde cedo. Você não precisa de um grande sistema de analytics, apenas uma visão compartilhada do que está acontecendo agora: em dia, aviso, violado, escalado.
Se estiver construindo isso em uma ferramenta no‑code, escolha uma plataforma que permita modelar dados, lógica e avaliadores agendados em um só lugar. Por exemplo, AppMaster (appmaster.io) suporta modelagem de banco, processos visuais e geração de apps prontos para produção, o que se encaixa bem com o padrão “eventos, avaliador, ações”.
Refine com segurança seguindo esta ordem:
Quando estiver pronto, construa uma versão pequena primeiro e cresça com feedback real e tickets reais.
Comece com uma definição clara da promessa que você está medindo, como primeira resposta ou resolução, e escreva exatamente quais são os eventos de início, parada e pausa. Depois, centralize a matemática do tempo em um avaliador que defina estados explícitos de SLA em vez de espalhar verificações “se agora > X” por vários fluxos.
Um temporizador é o relógio que você inicia ou agenda após um evento, como um ticket mudando de status. Um escalonamento é a ação que você toma ao atingir um limite (por exemplo, notificar um líder ou alterar prioridade). Uma violação é o fato armazenado de que o SLA foi perdido, que você pode reportar depois.
Primeira resposta mede o tempo até a primeira resposta humana significativa, enquanto resolução mede até o fechamento real do problema. Eles se comportam de forma diferente em pausas e reaberturas, então modelá-los separadamente mantém as regras e os relatórios mais simples.
Use tempo de calendário por padrão porque é mais simples e mais fácil de depurar. Só adicione regras de horário comercial se realmente precisar, já que horas úteis trazem complexidade extra como feriados, fusos e dias parciais.
Modele pausas como estados explícitos ligados a status específicos, como Waiting on Customer, e registre quando a pausa começou e quando terminou. Ao retomar, continue com o tempo restante ou recalcule o vencimento em um único lugar — não deixe que trocas de status aleatórias reiniciem o relógio.
Um único campo breached = true/false costuma ocultar contexto importante, como qual SLA violou, se está pausado e se já foi escalado. Estados explícitos — Em dia, Aviso, Violado, Pausado, Concluído — tornam o sistema previsível e mais fácil de auditar e alterar.
Armazene timestamps que expliquem o estado, como started_at, due_at, breached_at e campos de pausa como paused_at e paused_reason. Também grave rastreamento de escalonamento como last_escalation_level para evitar notificar o mesmo nível duas vezes.
Crie uma escada pequena que comece por quem pode agir e só escale a um líder, depois a um gerente se necessário. Mantenha limites e destinatários como dados (por exemplo, uma tabela de políticas) para que mudar tempos de escalonamento não exija editar vários fluxos.
Acople notificações a transições de estado, por exemplo OK -> Aviso ou Aviso -> Violado, não a verificações de “ainda atrasado”. Adicione guardrails simples como janelas de cooldown e condições de parada para enviar uma única mensagem por etapa.
Use o padrão eventos → avaliador → ações: eventos gravam fatos, o avaliador calcula prazos e define o estado de SLA, e as ações reagem apenas a mudanças de estado. Em AppMaster (appmaster.io), você pode modelar dados, construir o avaliador como processo visual e acionar notificações a partir das atualizações de estado mantendo a matemática do tempo centralizada.



Experimente o AppMaster com plano gratuito.
Quando estiver pronto, você poderá escolher a assinatura adequada.


