App de reserva de equipamentos: evite conflitos e acompanhe as devoluções
Planeje um app de reserva de equipamentos que evite reservas duplicadas, registre devoluções e danos e coloque itens com problemas em manutenção.
Aprenda padrões práticos para tarefas em background com atualizações de progresso: filas, modelo de status, mensagens de UI, ações de cancelar/repetir e relatório de erros.
Ações longas não devem bloquear a UI. As pessoas trocam de aba, perdem conexão, fecham o laptop ou simplesmente se perguntam se algo está acontecendo. Quando a tela fica congelada, o usuário tenta adivinhar, e adivinhar vira cliques repetidos, envios duplicados e tickets para suporte.
Um bom trabalho em background é, acima de tudo, sobre confiança. Usuários querem três coisas:
Sem isso, o job pode estar rodando bem, mas a experiência parece quebrada.
Uma confusão comum é tratar uma requisição lenta como trabalho em background. Uma requisição lenta ainda é uma chamada web que faz o usuário esperar. Trabalho em background é diferente: você inicia um job, recebe uma confirmação imediata e o processamento pesado acontece em outro lugar enquanto a UI continua utilizável.
Exemplo: um usuário faz upload de um CSV para importar clientes. Se a UI bloquear, ele pode dar refresh, enviar novamente e criar duplicatas. Se a importação rodar em background e a UI mostrar um cartão de job com progresso e uma opção segura de Cancelar, ele pode continuar trabalhando e retornar a um resultado claro.
Quando falamos de tarefas em background com atualizações de progresso, geralmente são quatro partes trabalhando juntas.
Um job é a unidade de trabalho: “importar este CSV”, “gerar este relatório” ou “enviar 5.000 e-mails”. Uma fila é a linha de espera onde jobs ficam até serem processados. Um worker pega jobs da fila e faz o trabalho (um por vez ou em paralelo).
Para a UI, a peça mais importante é o estado do ciclo de vida do job. Mantenha poucos estados e previsíveis:
Todo job precisa de um ID de job (uma referência única). Quando o usuário clica num botão, retorne esse ID imediatamente e mostre uma linha “Tarefa iniciada” em um painel de tarefas.
Depois você precisa de um jeito de perguntar “O que está acontecendo agora?” Normalmente é um endpoint de status (ou qualquer método de leitura) que recebe o ID do job e retorna o estado mais detalhes de progresso. A UI o usa para mostrar percentual concluído, etapa atual e quaisquer mensagens.
Finalmente, o status deve viver em um armazenamento durável, não apenas em memória. Workers caem, apps reiniciam e usuários atualizam páginas. O armazenamento durável é o que torna progresso e resultados confiáveis. No mínimo, armazene:
Se você está construindo numa plataforma como AppMaster, trate a tabela de status como qualquer outro modelo de dados: a UI lê por ID do job e o worker atualiza conforme avança.
O padrão de fila que você escolher muda como o app se comporta em termos de “justiça” e previsibilidade. Se uma tarefa fica enfileirada atrás de muito trabalho, os usuários percebem atrasos aleatórios, mesmo com o sistema saudável. Isso transforma a escolha da fila numa decisão de UX, não só de infra.
Uma fila simples baseada em banco de dados costuma bastar quando o volume é baixo, jobs são curtos e você tolera algumas tentativas. É fácil de configurar, fácil de inspecionar e tudo pode ficar num só lugar. Exemplo: um admin roda um relatório noturno para uma equipe pequena. Se houver uma tentativa a mais, ninguém entra em pânico.
Geralmente você precisa de um sistema de fila dedicado quando a taxa sobe, jobs ficam pesados ou confiabilidade vira ponto crítico. Imports, processamento de vídeo, notificações em massa e qualquer workflow que precise continuar entre reinícios se beneficiam de maior isolamento, visibilidade e retries mais seguros. Isso importa para o progresso visível porque as pessoas notam atualizações ausentes e estados travados.
A estrutura da fila também afeta prioridades. Uma fila única é mais simples, mas misturar trabalhos rápidos e lentos pode deixar ações rápidas com cara de lentas. Filas separadas ajudam quando você tem trabalho acionado pelo usuário que precisa ser instantâneo ao lado de batches agendados que podem esperar.
Defina limites de concorrência de forma intencional. Paralelismo excessivo pode sobrecarregar seu banco e fazer o progresso parecer irregular. Pouco paralelismo torna o sistema lento. Comece com concorrência pequena e previsível por fila e aumente só quando conseguir manter tempos de conclusão estáveis.
Se seu modelo de progresso for vago, a UI também ficará vaga. Decida o que o sistema consegue reportar honestamente, com que frequência muda e o que os usuários devem fazer com essa informação.
Um esquema simples de status que a maioria dos jobs suporta fica assim:
A seguir, defina o que “progresso” significa.
Percentual funciona quando há um denominador real (linhas num arquivo, e-mails a enviar). É enganoso quando o trabalho é imprevisível (espera por terceiros, compute variável, consultas caras). Nesses casos, progresso por etapas passa mais confiança porque avança em blocos claros.
Uma regra prática:
Armazene resultados parciais enquanto o job roda. Isso permite que a UI mostre algo útil antes do fim, como a contagem de erros ao vivo ou uma prévia do que mudou. Para importação CSV, salve rows_read, rows_created, rows_updated, rows_rejected, além das últimas mensagens de erro.
Essa é a base para tarefas em background com atualizações de progresso em que os usuários confiam: a UI fica calma, os números andam e o resumo “o que aconteceu?” está pronto no fim.
Levar progresso do backend para a tela é onde muitas implementações falham. Escolha um método de entrega que combine com a frequência de mudanças e com quantos usuários você espera observando.
Polling é o mais simples: a UI pergunta pelo status a cada N segundos. Um bom padrão é 2 a 5 segundos enquanto o usuário está ativamente vendo a página, depois desacelerar com o tempo. Se o job durar mais de um minuto, passe para 10 a 30 segundos. Se a aba estiver em background, reduza ainda mais.
Atualizações por push (WebSockets, server-sent events ou notificações mobile) ajudam quando o progresso muda rápido ou os usuários se importam com “agora”. Push é ótimo para imediatismo, mas você ainda precisa de fallback quando a conexão cair.
Uma abordagem híbrida costuma ser a melhor: poll rápido no início (para ver enfileirado virar em execução), depois desacelere quando o job estabilizar. Se adicionar push, mantenha um poll lento como rede de segurança.
Quando as atualizações param, trate isso como um estado legítimo. Mostre “Última atualização há 2 minutos” e ofereça refresh. No backend, marque jobs como obsoletos se não receberem heartbeat.
Clareza vem de duas coisas: um pequeno conjunto de estados previsíveis e textos que digam ao usuário o que acontece depois.
Nomeie os estados na UI, não só no backend. Um job pode estar enfileirado (esperando a vez), em execução (fazendo trabalho), aguardando input (precisa de uma escolha), concluído, concluído com erros ou falhado. Se usuários não conseguem diferenciar, vão assumir que o app travou.
Use copy simples e útil junto ao indicador de progresso. “Importando 3.200 linhas (1.140 processadas)” é melhor que “Processando.” Adicione uma frase que responda: posso sair? o que acontece? Por exemplo: “Você pode fechar esta janela. Continuaremos a importar em background e avisaremos quando estiver pronto.”
Onde o progresso aparece deve combinar com o contexto do usuário:
Para qualquer coisa acima de um minuto, adicione uma página de Jobs (ou painel de Atividade) para que as pessoas possam encontrar o trabalho depois.
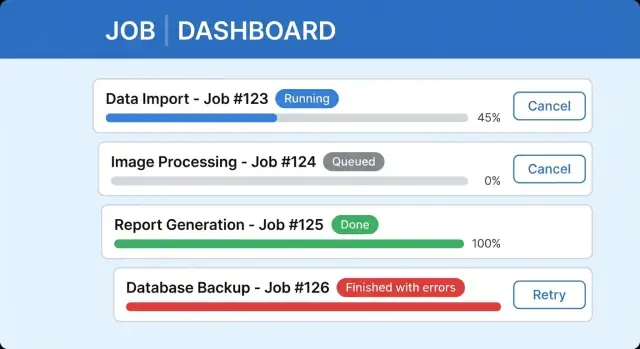
Uma UI clara para tarefas longas costuma incluir um rótulo de status com última atualização, uma barra de progresso (ou etapas) com uma linha de detalhe, comportamento seguro de Cancelar e uma área de resultados com resumo e próximo passo. Mantenha jobs concluídos descobríveis para que usuários não se sintam obrigados a esperar numa tela só.
“Concluído” nem sempre é vitória total. Quando um job em background processa 9.500 registros e 120 falham, os usuários precisam entender o que aconteceu sem ler logs.
Trate sucesso parcial como um resultado legítimo. Na linha principal, mostre os dois lados: “Importados 9.380 de 9.500. 120 falharam.” Isso mantém a confiança porque o sistema é honesto e confirma que trabalho foi salvo.
Mostre então um pequeno resumo de erros que o usuário possa agir: “Campo obrigatório ausente (63)” e “Formato de data inválido (41).” No estado final, “Concluído com problemas” costuma ser mais claro que “Falhou”, porque não implica que nada funcionou.
Um relatório de erros exportável transforma confusão numa lista de tarefas. Mantenha simples: número da linha ou identificador do item, categoria do erro, uma mensagem humana e o nome do campo quando relevante.
Deixe a próxima ação óbvia e perto do resumo: consertar dados e reexecutar os itens falhados, baixar o relatório de erros ou contatar suporte se parecer problema do sistema.
Cancelar e reexecutar parecem simples, mas quebram confiança rápido quando a UI diz uma coisa e o sistema faz outra. Defina o que Cancel significa para cada tipo de job e reflita isso honestamente na interface.
Geralmente há dois modos válidos de cancelamento:
Na UI, mostre um estado intermediário como “Cancelamento solicitado” para que os usuários não continuem clicando.
Torne o cancelamento seguro projetando o trabalho para ser repetível. Se um job grava dados, prefira operações idempotentes (seguem seguras para rodar duas vezes) e faça limpeza quando necessário. Exemplo: numa importação CSV que cria registros, armazene um ID de execução do job para revisar o que mudou na execução #123.
Retry precisa da mesma clareza. Reexecutar a mesma instância de job faz sentido quando dá para retomar. Criar uma nova instância é mais seguro quando você quer uma execução limpa com novo timestamp e trilha de auditoria. De qualquer forma, explique o que será refeito e o que não será.
Guardrails que mantêm cancelar e retry previsíveis:
Um bom fluxo começa com uma regra: a UI nunca deve esperar pelo trabalho em si. Deve esperar apenas por um ID de job.
Usuário inicia a tarefa, a API responde rápido. Quando o usuário clica em Importar ou Gerar relatório, seu servidor cria imediatamente um registro de job e retorna um ID único.
Enfileire o trabalho e defina o primeiro status. Coloque o ID do job na fila e marque o status como enfileirado com progresso 0%. Isso dá à UI algo real para mostrar antes mesmo de um worker pegá-lo.
Worker roda e reporta progresso. Quando um worker inicia, marque o status como em execução, salve a hora de início e atualize o progresso em saltos pequenos e honestos. Se não for possível medir percentual, mostre etapas como Parsing, Validating, Saving.
A UI mantém o usuário orientado. A UI faz polling ou se inscreve em atualizações e renderiza estados claros. Mostre uma mensagem curta (o que está acontecendo agora) e apenas as ações que fazem sentido no momento.
Finalize com um resultado durável. No término, salve o tempo de finalização, a saída (referência para download, IDs criados, contagens resumo) e detalhes de erro. Suporte “concluído com erros” como resultado próprio, não como sucesso vago.
Cancel deve ser explícito: requisições de cancelamento pedem o término, então o worker reconhece e marca como cancelado. Retry deve criar um novo ID de job, mantendo o original como histórico, e explicar o que será reprocessado.
Um lugar comum onde tarefas em background com progresso importam é a importação CSV. Imagine um CRM onde um analista carrega customers.csv com 8.420 linhas.
Logo após o upload, a UI deve mudar de “Cliquei no botão” para “existe um job e você pode sair.” Um cartão simples de job numa página de Imports funciona bem:
Enquanto roda, mostre um número de progresso confiável (linhas processadas) e uma linha de status curta (o que está fazendo agora). Se o usuário navegar, mantenha o job visível numa área de Recentes.
Agora adicione falhas parciais. Quando o job terminar, evite uma faixa assustadora de Falha se a maioria das linhas estiver ok. Use Finalizado com problemas e mostre uma divisão clara:
Importados 8.102 clientes. Ignoradas 318 linhas.
Explique as principais razões em palavras simples: formato de email inválido, campos obrigatórios ausentes como company, ou IDs externos duplicados. Permita baixar ou ver uma tabela de erros com número da linha, nome do cliente e o campo exato que precisa ser corrigido.
Retry deve parecer seguro e específico. A ação principal pode ser Reexecutar linhas falhadas, criando um novo job que só reprocessa as 318 linhas ignoradas depois que o usuário ajustar o CSV. Mantenha o job original somente leitura para preservar histórico.
Por fim, facilite encontrar resultados depois. Cada import deve ter um resumo estável: quem rodou, quando, nome do arquivo, contagens (importados, ignorados) e um jeito de abrir o relatório de erros.
A forma mais rápida de perder confiança é mostrar números que não são reais. Uma barra de progresso parada em 0% por dois minutos e pulando para 90% parece chute. Se você não conhece o percentual real, mostre etapas (Enfileirado, Processando, Finalizando) ou “X de Y itens processados.”
Outro problema comum é manter progresso só em memória. Se o worker reinicia, a UI “esquece” o job ou zera o progresso. Salve o estado do job em armazenamento durável e faça a UI ler dessa única fonte da verdade.
A UX de retry também quebra quando usuários conseguem iniciar o mesmo job várias vezes. Se o botão Importar CSV continua ativo, alguém clica duas vezes e cria duplicatas. Aí os retries ficam confusos porque não é óbvio qual execução corrigir.
Erros que aparecem repetidamente:
Um detalhe pequeno mas importante: separe a mensagem para o usuário do detalhe para desenvolvedor. Mostre “12 linhas falharam na validação” ao usuário e mantenha o trace técnico nos logs.
Antes de lançar, faça uma checagem nas partes que os usuários notam: clareza, confiança e recuperação.
Todo job deve expor um snapshot que você possa mostrar em qualquer lugar: estado (enfileirado, em execução, sucedido, falhado, cancelado), progresso (0–100 ou etapas), uma mensagem curta, timestamps (criado, iniciado, finalizado) e um ponteiro de resultado (onde a saída ou relatório está).
Torne os estados de UI óbvios e consistentes. Usuários precisam de um lugar confiável para encontrar jobs atuais e passados, além de rótulos claros ao voltar ("Concluído ontem", "Ainda em execução"). Um painel de Recentes frequentemente evita cliques repetidos e trabalhos duplicados.
Defina regras de cancel e retry em termos claros. Decida o que Cancel significa para cada job, se retry é permitido e o que será reaproveitado (mesmos inputs, novo ID de job). Teste casos de borda como cancelar pouco antes da conclusão.
Trate falhas parciais como resultado real. Mostre um resumo curto ("Importados 97, ignorados 3") e forneça um relatório acionável que o usuário possa usar imediatamente.
Planeje recuperação. Jobs devem sobreviver a reinícios, e jobs travados devem expirar para um estado claro com orientação ("Tentar novamente" ou "Contatar suporte com o ID do job").
Escolha um fluxo que os usuários já reclamam: imports CSV, exports de relatórios, envios em massa de e-mail ou processamento de imagens. Comece pequeno e comprove o básico: um job é criado, roda, reporta status e o usuário consegue encontrá-lo depois.
Uma tela de histórico de jobs simples costuma ser o maior salto de qualidade. Dá às pessoas um lugar para voltar, em vez de olhar para um spinner.
Escolha um método de entrega de progresso primeiro. Polling serve bem para a versão 1. Ajuste o intervalo para ser gentil com seu backend, mas rápido o suficiente para parecer vivo.
Uma ordem de construção prática que evita retrabalho:
Se você estiver construindo sem escrever código, uma plataforma no-code como AppMaster pode ajudar permitindo modelar uma tabela de status de job (PostgreSQL) e atualizá-la a partir de workflows, então renderizar esse status em web e mobile UI. Para times que querem um lugar único para construir backend, UI e lógica de background, AppMaster (appmaster.io) foi desenhado para apps completos, não apenas formulários ou páginas.
Um job em background é criado rapidamente e retorna um ID de job imediatamente, então a UI pode continuar responsiva. Uma requisição lenta mantém o usuário esperando pela mesma chamada web terminar, o que leva a refreshes, cliques duplos e envios duplicados.
Mantenha simples: enfileirado, em execução, concluído e falhou, além de cancelado se você oferecer cancelamento. Adicione um resultado separado como “concluído com problemas” quando a maior parte do trabalho tiver sucesso mas alguns itens falharem, para que os usuários não pensem que tudo foi perdido.
Retorne um ID de job único imediatamente após o usuário iniciar a ação e renderize uma linha ou cartão de tarefa usando esse ID. A UI deve ler o status pelo ID do job para que os usuários possam atualizar a página, trocar de aba ou voltar depois sem perder o rastreio.
Armazene o status do job em uma tabela de banco de dados durável, não apenas em memória. Salve o estado atual, timestamps, valor de progresso, uma mensagem curta para o usuário e um resumo de resultado ou erro para que a UI sempre consiga reconstruir a mesma visão após reinícios.
Use percentuais apenas quando você puder honestamente reportar “X de Y” itens processados. Se não houver um denominador real, mostre progresso por etapas como Validando, Importando, Finalizando e mantenha a mensagem atualizada para que o usuário perceba avanço.
Polling é o método mais simples e funciona bem para a maioria das aplicações; comece em torno de 2–5 segundos enquanto o usuário estiver olhando, e desacelere para trabalhos longos ou abas em segundo plano. Push dá uma sensação de imediatismo, mas você ainda precisa de fallback porque conexões caem e usuários mudam de tela.
Exiba que as atualizações estão desatualizadas em vez de fingir que o job continua ativo — por exemplo, mostrando “Última atualização há 2 minutos” e oferecendo um refresh manual. No backend, detecte ausências de heartbeat e mova o job para um estado claro com orientação, como re-executar ou contatar o suporte com o ID do job.
Deixe claro se o usuário pode continuar trabalhando, sair da página ou cancelar com segurança. Para tarefas acima de um minuto, uma visão de Jobs ou Atividades ajuda o usuário a encontrar resultados depois em vez de ficar preso a um spinner.
Trate como um resultado importante e mostre os dois lados claramente, por exemplo: “Importados 9.380 de 9.500. 120 falharam.” Em seguida, forneça um pequeno resumo de erros acionável que o usuário possa corrigir sem ler logs, mantendo detalhes técnicos nos logs internos.
Defina o que Cancel significa para cada tipo de job e reflita isso honestamente na UI, incluindo um estado intermediário “cancelamento solicitado” para evitar cliques repetidos. Faça o trabalho idempotente quando possível, limite retries e decida se retry retoma o mesmo job ou cria um novo ID de job com trilha de auditoria limpa.



Experimente o AppMaster com plano gratuito.
Quando estiver pronto, você poderá escolher a assinatura adequada.


