App de reserva de equipamentos: evite conflitos e acompanhe as devoluções
Planeje um app de reserva de equipamentos que evite reservas duplicadas, registre devoluções e danos e coloque itens com problemas em manutenção.
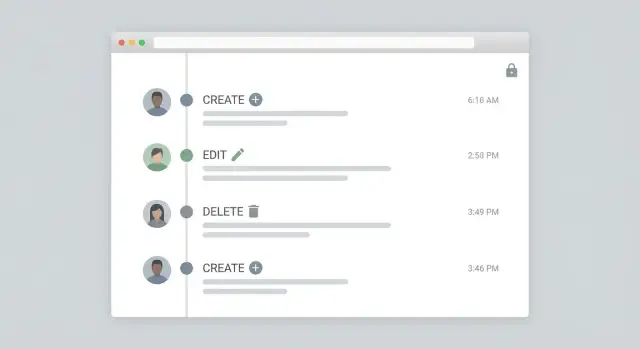
Registro de auditoria para ferramentas internas de forma prática: acompanhe quem fez o quê e quando em cada alteração CRUD, armazene diffs com segurança e exiba um feed de atividade para administradores.
A maioria das equipes só adiciona logs de auditoria depois que algo dá errado. Um cliente contesta uma alteração, um número financeiro muda ou um auditor pergunta: "Quem aprovou isto?" Se você só começa nessa hora, acaba tentando reconstruir o passado a partir de pistas parciais: timestamps no banco, mensagens no Slack e suposições.
Para a maioria dos apps internos, “bom o bastante para conformidade” não significa um sistema forense perfeito. Significa poder responder a um pequeno conjunto de perguntas de forma rápida e consistente: quem fez a mudança, qual registro foi afetado, o que mudou, quando aconteceu e de onde veio (UI, importação, API, automação). Essa clareza é o que faz um log de auditoria ser confiável.
Onde os logs costumam falhar não é no banco de dados — é na cobertura. O histórico parece OK para edições simples, mas aparecem lacunas assim que o trabalho acelera. Os culpados mais comuns são edições em massa, importações, jobs agendados, ações administrativas que contornam telas normais (como reset de senha ou mudança de papéis) e deleções (especialmente deletes permanentes).
Outra falha frequente é confundir logs de debug com logs de auditoria. Logs de debug são feitos para desenvolvedores: ruidosos, técnicos e muitas vezes inconsistentes. Logs de auditoria são para responsabilidade: campos consistentes, linguagem clara e um formato estável que você pode mostrar para não-engenheiros.
Um exemplo prático: um gerente de suporte altera o plano de um cliente, depois uma automação atualiza dados de cobrança. Se você só registrar "cliente atualizado", não dá para saber se foi uma pessoa, um workflow ou uma importação que sobrescreveu.
Um bom log de auditoria começa com um objetivo: uma pessoa deve conseguir ler uma entrada e entender o que aconteceu sem adivinhar.
Armazene um ator claro para cada mudança. A maioria das equipes para em "user id", mas ferramentas internas frequentemente mudam dados por mais de uma porta.
Inclua um tipo de ator e um identificador do ator, para distinguir entre um funcionário, uma conta de serviço ou uma integração externa. Se você tiver equipes ou tenants, também armazene o id da organização ou workspace para que eventos não se misturem.
Capture a ação (create, update, delete, restore) além do alvo. "Alvo" deve ser tanto amigável para humanos quanto preciso: nome da tabela ou entidade, id do registro e, idealmente, um rótulo curto (como um número de pedido) para leitura rápida.
Um conjunto mínimo prático de campos:
Armazene o timestamp em UTC. Sempre. Depois exiba no horário local do visualizador na UI administrativa. Isso evita argumentos de "duas pessoas viram horários diferentes" durante uma revisão.
Se você lida com ações de alto risco como mudanças de papéis, reembolsos ou exportações de dados, adicione um campo "reason". Mesmo uma nota curta como "Aprovado pelo gerente no ticket 1842" pode transformar o trilho de auditoria de ruído em evidência.
A primeira escolha de design é onde mora a "verdade" do histórico de mudanças. A maioria das equipes segue um de dois modelos: um event log append-only, ou tabelas de histórico/versionamento por entidade.
Um event log é uma única tabela que registra cada ação como uma nova linha. Cada linha armazena quem fez, quando aconteceu, qual entidade foi afetada e um payload (frequentemente JSON) descrevendo a mudança.
Esse modelo é simples de adicionar e flexível quando seu modelo de dados evolui. Também mapeia naturalmente para um feed de atividade administrativo porque o feed é basicamente "eventos mais recentes primeiro".
Uma abordagem de histórico versionado cria tabelas de histórico por entidade, como Order_history ou User_versions, onde cada atualização cria um novo snapshot completo (ou um conjunto estruturado de campos alterados) com um número de versão.
Isso facilita relatórios ponto-no-tempo ("como esse registro estava na última terça-feira?"). Pode também parecer mais claro para auditores, porque a linha do tempo de cada registro fica auto-contida.
Uma forma prática de escolher:
Independente da escolha, mantenha as entradas de auditoria imutáveis: nada de updates, nada de deletes. Se algo estiver errado, adicione uma nova entrada explicando a correção.
Considere também adicionar um correlation_id (ou operation id). Uma ação do usuário frequentemente dispara várias mudanças (por exemplo, "Desativar usuário" atualiza o usuário, revoga sessões e cancela tarefas pendentes). Um correlation id compartilhado permite agrupar essas linhas em uma operação legível.
Log confiável começa com uma regra: toda escrita passa por um único caminho que também grava um evento de auditoria. Se algumas atualizações ocorrem em jobs em background, importações ou telas de edição rápida que contornam o fluxo normal de salvamento, seus logs terão buracos.
Para creates, registre o ator e a origem (UI, API, import). Importações são onde as equipes frequentemente perdem o "quem", então armazene um valor explícito de "performed by" mesmo se os dados vieram de um arquivo ou integração. Também é útil salvar os valores iniciais (um snapshot completo ou um conjunto pequeno de campos-chave) para explicar por que um registro existe.
Atualizações são mais complicadas. Você pode registrar apenas os campos que mudaram (pequeno, legível e rápido), ou armazenar um snapshot completo após cada salvamento (simples de consultar depois, mas pesado). Um meio-termo prático é gravar diffs para edições normais e snapshots apenas para objetos sensíveis (como permissões, dados bancários ou regras de precificação).
Deletes não devem apagar evidências. Prefira soft delete (uma flag is_deleted junto com um evento de auditoria). Se for necessário hard delete, escreva o evento de auditoria primeiro e inclua um snapshot do registro para provar o que foi removido.
Trate restauração como uma ação própria. "Restore" não é o mesmo que "Update", e separar isso facilita revisões e verificações de conformidade.
Para edições em massa, evite um único registro vago como "atualizados 500 registros." Você precisa de detalhes suficientes para responder "quais registros mudaram?" depois. Um padrão prático é um evento pai mais eventos filhos por registro:
Exemplo: um líder de suporte encerra em massa 120 tickets. A entrada pai captura o filtro "status=open, older than 30 days" e cada ticket recebe uma entrada filha mostrando status open -> closed.
Logs de auditoria viram lixo rápido quando ou armazenam demais (cada registro completo, para sempre) ou de menos (apenas "usuário editado"). O objetivo é um registro defensável para conformidade e legível por um admin.
Um padrão prático é salvar um diff por campo na maioria das atualizações. Grave somente os campos que mudaram, com valores "before" e "after". Isso reduz armazenamento e torna o feed de atividade fácil de escanear: "Status: Pendente -> Aprovado" é mais claro que um blob enorme.
Mantenha snapshots completos para momentos que importam: criações, deleções e transições de workflow significativas. Um snapshot é mais pesado, mas protege quando alguém pergunta: "Como exatamente era o perfil do cliente antes de ser removido?"
Dados sensíveis precisam de regras de mascaramento, ou sua tabela de auditoria vira um segundo banco cheio de segredos. Regras comuns:
Mudanças de schema também podem quebrar o histórico. Se um campo for renomeado ou removido depois, armazene um fallback seguro como "unknown field" junto com a chave original. Para campos deletados, mantenha o último valor conhecido, mas marque como "campo removido do schema" para que o feed permaneça honesto.
Finalmente, faça as entradas amigáveis para humanos. Armazene rótulos de exibição ("Assigned to") junto com chaves brutas ("assignee_id"), e formate valores (datas, moedas, nomes de status).
Um trilho de auditoria confiável não é registrar mais; é usar um padrão repetível em todo lugar para não acabar com lacunas como "importação em massa não foi registrada" ou "edições mobile parecem anônimas."
Comece no seu modelo de dados e crie um pequeno conjunto de tabelas que descrevam qualquer mudança.
Mantenha simples: uma tabela para o evento, uma para campos alterados e um contexto de ator pequeno.
Crie um sub-processo reutilizável que:
A regra é estrita: todo caminho de escrita deve chamar esse mesmo sub-processo. Isso inclui botões da UI, endpoints da API, automações agendadas e integrações.
Não confie no navegador para "quem" e "quando." Leia o ator da sessão de autenticação e gere timestamps no servidor. Se uma automação rodar, defina actor_type como system e armazene o nome do job como rótulo do ator.
Escolha um registro (por exemplo, um ticket de cliente): crie-o, edite dois campos (status e assignee), delete-o e depois restaure. Seu feed de auditoria deve mostrar cinco eventos, com dois itens de update sob o evento de edição, e ator e timestamp preenchidos da mesma forma cada vez.
Um log de auditoria só é útil se alguém conseguir ler rápido durante uma revisão ou incidente. O objetivo do feed administrativo é simples: responder "o que aconteceu?" à primeira vista, e permitir um olhar mais profundo sem afogar as pessoas em JSON cru.
Comece com um layout em timeline: mais recentes primeiro, uma linha por evento, e verbos claros como Created, Updated, Deleted, Restored. Cada linha deve mostrar o ator (pessoa ou sistema), o alvo (tipo de registro mais um nome amigável) e o horário.
Um formato prático de linha:
Mantenha o "o que mudou" compacto. Mostre 1–3 campos inline e ofereça um painel detalhado (drawer/modal) que revele detalhes completos: valores before/after, origem da requisição (web, mobile, API) e qualquer campo de reason/comentário.
Filtragem é o que torna o feed utilizável depois da primeira semana. Foque em filtros que respondem perguntas reais:
Links importam, mas apenas quando permitidos. Se o visualizador tem acesso ao registro afetado, mostre uma ação "Ver registro". Se não, exiba um placeholder seguro (por exemplo, "Registro restrito") mantendo a entrada de auditoria visível.
Destaque ações do sistema. Rotule jobs agendados e integrações de forma distinta para que admins enxerguem "Dana deletou isso" versus "Nightly billing sync atualizou isso."
Logs de auditoria são evidências, mas também dados sensíveis. Trate o logging como um produto separado dentro do app: regras de acesso claras, limites definidos e manuseio cuidadoso de informações pessoais.
Decida quem pode ver o quê. Uma divisão comum é: admins do sistema veem tudo; gerentes de departamento veem eventos do time deles; donos de registro veem eventos ligados a registros que já têm acesso (e nada além). Se você expõe um feed, aplique as mesmas regras a cada linha, não só na tela.
Visibilidade no nível da linha é crucial em ferramentas multi-tenant ou cross-department. Sua tabela de auditoria deve carregar as mesmas chaves de escopo que os dados de negócio (tenant_id, department_id, project_id) para filtrar consistentemente. Exemplo: um gerente de suporte deve ver mudanças em tickets da sua fila, mas não ajustes salariais de RH, mesmo se ambos ocorrerem no mesmo app.
Uma política simples e prática:
Privacidade é a outra metade. Armazene o suficiente para provar o que aconteceu, mas evite transformar o log numa cópia do seu banco de dados. Para campos sensíveis (SSNs, notas médicas, dados de pagamento), prefira redação: registre que o campo mudou sem armazenar old/new. Você pode logar "email changed" enquanto mascara o valor real, ou armazenar um fingerprint hashed para verificação.
Mantenha eventos de segurança separados de mudanças de registro de negócio. Tentativas de login, resets de MFA, criação de chaves de API e mudanças de papel devem ir para um stream security_audit com acesso mais restrito e retenção possivelmente diferente. Edições de negócio (status, aprovações, mudanças de workflow) podem viver no stream geral de auditoria.
Quando alguém solicita remoção de dados pessoais, não apague todo o histórico de auditoria. Em vez disso:
Um log útil não é apenas "registramos eventos." Para conformidade, você precisa provar três coisas: que manteve os dados tempo suficiente, que eles não foram alterados depois e que consegue recuperá-los rápido quando necessário.
Comece com uma regra simples que combine com seu risco. Muitas equipes escolhem 90 dias para troubleshooting diário, 1 a 3 anos para conformidade interna e mais tempo apenas para registros regulados. Documente o que reinicia o contador (frequentemente: tempo do evento) e o que fica excluído (por exemplo, logs que contenham campos que você não deve manter).
Se tiver múltiplos ambientes, defina retenção diferente por ambiente. Logs de produção geralmente precisam de retenção maior; logs de teste muitas vezes não precisam de nada.
Trate logs de auditoria como append-only. Não atualize linhas e não permita que admins normais as deletem. Se um delete for realmente necessário (pedido legal, limpeza), registre essa ação também como um evento.
Um padrão prático:
Auditores costumam pedir CSV ou JSON. Planeje uma exportação que filtre por intervalo de datas e tipo de objeto (Invoice, User, Ticket) para não ficar consultando o DB no pior momento.
Para performance, indexe para como você busca:
Monitore falhas silenciosas. Se a escrita de auditoria falhar, você perde evidência e muitas vezes não percebe. Adicione um alerta simples: se o app processa writes mas os eventos de auditoria caem a zero por um período, notifique os responsáveis e registre o erro com alto nível de visibilidade.
A maneira mais rápida de perder tempo é coletar muitas linhas que não respondem às perguntas reais: quem mudou o quê, quando e de onde.
Uma armadilha comum é depender apenas de triggers no banco. Triggers podem registrar que uma linha mudou, mas frequentemente perdem o contexto de negócio: qual tela o usuário usou, qual requisição causou, qual papel tinha, e se foi uma edição normal ou uma regra automatizada.
Erros que mais quebram conformidade e usabilidade do dia a dia:
Padronize seu vocabulário de eventos cedo (por exemplo: user.created, user.updated, invoice.voided, access.granted) e exija que todo caminho de escrita emita um evento único. Trate dados de auditoria como write-once: se alguém fez a alteração errada, registre uma ação corretiva em vez de reescrever o histórico.
Antes de considerar pronto, rode alguns testes rápidos. Um bom log de auditoria é, no melhor sentido, entediante: completo, consistente e fácil de ler quando algo dá errado.
Use este checklist em um ambiente de teste com dados realistas:
Se você está construindo ferramentas internas com AppMaster (appmaster.io), uma maneira prática de manter alta cobertura é rotear ações da UI, endpoints da API, importações e automações pelo mesmo padrão Business Process que grava tanto a mudança de dado quanto o evento de auditoria. Assim, seu trilho CRUD fica consistente mesmo quando telas e workflows mudam.
Comece pequeno com um workflow que importe: tickets, aprovações ou mudanças de cobrança. Deixe o feed legível e expanda até que todo caminho de escrita emita um evento de auditoria previsível e pesquisável.
Adicione logs de auditoria assim que a ferramenta puder alterar dados reais. A primeira disputa ou solicitação de auditoria geralmente acontece antes de você estar “pronto”, e reconstruir o histórico depois é em grande parte suposição.
Um registro útil responde quem fez, qual registro foi afetado, o que mudou, quando aconteceu e de onde veio (UI, API, importação ou job). Se não for possível responder uma dessas perguntas rapidamente, o log não será confiável.
Logs de debug são para desenvolvedores e costumam ser ruidosos e inconsistentes. Logs de auditoria são para responsabilidade: precisam de campos estáveis, linguagem clara e um formato que continue legível por não-engenheiros.
A cobertura costuma falhar quando as mudanças ocorrem fora da tela de edição normal. Edições em massa, importações, jobs agendados, atalhos de administrador e deleções são os pontos comuns onde as equipes esquecem de emitir eventos de auditoria.
Armazene um tipo de ator e um identificador do ator, não apenas um user_id. Assim você diferencia claramente um membro da equipe de um job do sistema, conta de serviço ou integração externa e evita a ambiguidade de “alguém fez isso”.
Armazene timestamps em UTC no banco de dados e exiba no horário local do visualizador na UI administrativa. Isso evita disputas de fuso horário e torna as exportações consistentes entre equipes.
Use um event log append-only quando quiser um único lugar para buscar e um feed de atividade simples. Use versioned history por entidade quando precisar de visualizações ponto no tempo frequentes; em muitas aplicações, um event log com diffs por campo cobre a maioria das necessidades com menos armazenamento.
Prefira deleção suave e registre explicitamente a ação de delete. Se precisar apagar de vez, escreva o evento de auditoria primeiro e inclua um snapshot ou campos-chave para provar o que foi removido.
Um padrão prático é salvar diffs por campo nas atualizações e snapshots em criações e deleções. Para campos sensíveis, registre que o valor mudou sem armazenar o segredo, e redija ou masque dados pessoais para que o log não vire uma cópia do banco.
Crie um único caminho compartilhado “write + audit” e obrigue todas as escritas a usá-lo: ações na UI, endpoints da API, importações e jobs em background. Em AppMaster, equipes costumam implementar isso como um Business Process reutilizável que faz a mudança e grava o evento no mesmo fluxo.



Experimente o AppMaster com plano gratuito.
Quando estiver pronto, você poderá escolher a assinatura adequada.


