App de reserva de equipamentos: evite conflitos e acompanhe as devoluções
Planeje um app de reserva de equipamentos que evite reservas duplicadas, registre devoluções e danos e coloque itens com problemas em manutenção.
Aprenda a desenhar políticas de retenção de dados para apps empresariais com janelas claras, arquivamento e fluxos de exclusão ou anonimização que mantêm os relatórios úteis.
Uma política de retenção é um conjunto claro de regras que seu app segue sobre dados: o que você guarda, por quanto tempo guarda, onde eles vivem e o que acontece quando o tempo acaba. O objetivo não é “apagar tudo”. É manter o que você precisa para operar o negócio e explicar eventos passados, enquanto remove o que não é mais necessário.
Sem um plano, três problemas aparecem rapidamente. O armazenamento cresce silenciosamente até começar a custar de verdade. O risco de privacidade e segurança aumenta a cada cópia extra de dados pessoais. E os relatórios ficam pouco confiáveis quando registros antigos não batem com a lógica atual, ou quando pessoas apagam coisas ad hoc e dashboards mudam de repente.
Uma política prática de retenção equilibra operações do dia a dia, evidência e proteção do cliente:
A maioria dos apps empresariais tem as mesmas áreas de dados, mesmo usando nomes diferentes: perfis de usuário, transações, trilhas de auditoria, mensagens e arquivos enviados.
Uma política é parte regras, parte fluxo de trabalho e parte ferramentas. A regra pode dizer “manter tickets de suporte por 2 anos”. O fluxo de trabalho define o que isso significa na prática: mover tickets antigos para uma área de arquivo, anonimizar campos do cliente e registrar o que aconteceu. A ferramenta torna isso repetível e auditável.
Se você constrói seu app no AppMaster, trate retenção como comportamento do produto, não como uma limpeza pontual. Business Processes agendados podem arquivar, excluir ou anonimizar dados da mesma forma todas as vezes, para que os relatórios permaneçam consistentes e as pessoas confiem nos números.
Antes de definir datas, esclareça por que você está guardando os dados. Decisões de retenção costumam ser moldadas por leis de privacidade, contratos com clientes e regras de auditoria ou fiscal. Pule essa etapa e você ou guarda demais (maior risco e custo) ou apaga algo que depois precisa.
Comece separando “é preciso guardar” de “é bom ter”. Dados que precisam ser mantidos frequentemente incluem faturas, lançamentos contábeis e logs de auditoria necessários para provar quem fez o quê e quando. Dados “bom ter” podem ser transcrições antigas de chat, histórico de cliques detalhado ou logs brutos de eventos usados só ocasionalmente para análise.
Requisitos também variam por país e setor. Um portal de suporte para um provedor de saúde tem restrições muito diferentes de uma ferramenta administrativa B2B. Mesmo dentro de uma empresa, usuários em vários países podem significar regras distintas para o mesmo tipo de registro.
Escreva decisões em linguagem simples e atribua um responsável. “Mantemos tickets por 24 meses” não é suficiente. Defina o que está incluído, o que está excluído e o que acontece quando a janela termina (arquivar, anonimizar, excluir). Coloque uma pessoa ou equipe responsável para que atualizações não empacem quando produtos ou leis mudarem.
Consiga aprovações cedo, antes da engenharia construir qualquer coisa. Jurídico confirma os mínimos e obrigações de exclusão. Segurança confirma riscos, controles de acesso e logging. Produto confirma o que os usuários ainda precisam ver. Finanças confirma necessidades de registro.
Exemplo: você pode manter registros de cobrança por 7 anos, tickets por 2 anos e anonimizar campos do perfil de usuário após o fechamento da conta, mantendo métricas agregadas. No AppMaster, essas regras escritas podem mapear limpamente para processos agendados e controle de acesso baseado em papéis, com menos adivinhação depois.
Políticas de retenção falham quando equipes decidem “manter por 2 anos” sem saber o que “isso” inclui. Construa um mapa simples dos dados que você tem. Não vise perfeição. Mire em algo que um líder de suporte e um líder de finanças consigam entender.
Um conjunto prático inicial:
Depois marque a sensibilidade em termos simples: dados pessoais (nome, email), financeiros (dados bancários, tokens de pagamento), credenciais (hashes de senha, chaves de API) ou dados regulados (por exemplo, informações de saúde). Se tiver dúvida, rotule como “potencialmente sensível” e trate com cautela até confirmar.
“Onde eles ficam” geralmente é mais do que seu banco de dados principal. Anote o local exato: tabelas do banco, armazenamento de arquivos, logs de email/SMS, ferramentas de analytics ou data warehouses. Observe também quem depende de cada conjunto de dados (suporte, vendas, finanças, liderança) e com que frequência. Isso indica o que quebra se você excluir de forma agressiva.
Um hábito útil: documente o propósito de cada conjunto de dados em uma frase. Exemplo: “Tickets de suporte são mantidos para resolver disputas e acompanhar tendências de tempo de resposta.”
Se você constrói com AppMaster, alinhe esse inventário com o que está realmente implantado revisando seus modelos no Data Designer, o tratamento de arquivos e integrações habilitadas.
Uma vez que o mapa exista, retenção vira uma série de pequenas escolhas claras ao invés de um grande palpite.
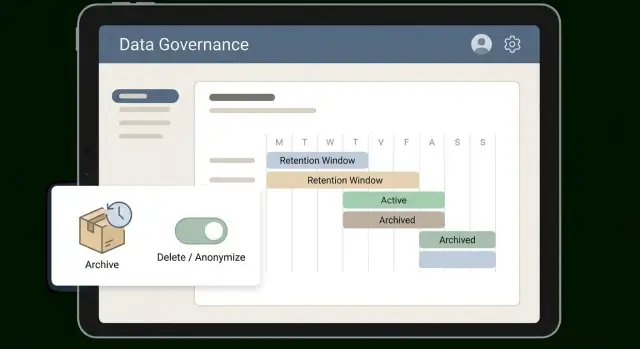
Uma janela só funciona se for fácil de explicar e ainda mais fácil de aplicar. Muitas equipes vão bem com camadas simples que correspondem ao uso dos dados: quente (usado diariamente), morno (usado às vezes), frio (mantido como prova) e depois excluído ou anonimizado. As camadas transformam uma política abstrata em rotina.
Defina janelas por categoria, não um número global. Faturas e registros de pagamento geralmente precisam de um longo período frio para impostos e auditorias. Transcrições de chat de suporte costumam perder valor rapidamente.
Também decida o que inicia a contagem. “Manter por 2 anos” é inútil a menos que você defina “2 anos a partir de quê”. Escolha um gatilho por categoria, como data de criação, última atividade do cliente, data de fechamento do ticket ou encerramento da conta. Se os gatilhos variarem sem regras claras, as pessoas vão chutar e a retenção derivará.
Escreva exceções desde o início para que as equipes não improvisem depois. Exceções comuns incluem retenção legal, estornos e investigações de fraude. Essas devem pausar a exclusão. Não devem gerar cópias escondidas.
Mantenha as regras finais curtas e testáveis:
legal_hold=true: não excluir até liberadoUm arquivo não é um backup. Backups servem para recuperação após erros ou quedas. Arquivos são deliberados: dados antigos saem das suas tabelas quentes e vão para armazenamento mais barato, mas continuam disponíveis para auditorias, disputas e questões históricas.
A maioria dos apps precisa de ambos. Backups são frequentes e abrangentes. Arquivos são seletivos e controlados, e você normalmente recupera só o que precisa.
Armazenamento mais barato só ajuda se as pessoas conseguirem encontrar o que precisam. Muitas equipes usam um banco separado ou um schema ajustado para consultas de leitura, ou exportam para arquivos mais um índice para lookup. Se seu app se baseia em PostgreSQL (incluindo no AppMaster), um schema de “archive” ou um banco separado pode manter as tabelas de produção rápidas enquanto permite relatórios permitidos sobre dados arquivados.
Antes de escolher o formato, defina o que “pesquisável” significa para seu negócio. Suporte pode precisar buscar por email ou ID do ticket. Finanças pode precisar de totais por mês. Auditoria pode precisar de rastreio por ID de pedido.
Registros completos preservam detalhe, mas custam mais e aumentam o risco de privacidade. Resumos (totais mensais, contagens, mudanças de status chave) são mais baratos e frequentemente suficientes para relatórios.
Uma abordagem prática:
Planeje campos de índice desde o início. Comuns: ID primário, ID do usuário/cliente, um bucket de data (mês), região e status. Sem isso, o dado arquivado existe, mas é doloroso de recuperar.
Defina regras de restauração também: quem pode solicitar restauração, quem aprova, para onde os dados restaurados vão e o tempo esperado. Restaurações podem ser lentas de propósito se isso reduzir risco, mas precisam ser previsíveis.
Políticas de retenção geralmente forçam uma escolha: excluir registros ou mantê-los removendo detalhes pessoais. Ambos podem estar certos, mas resolvem problemas diferentes.
Uma exclusão dura (hard delete) remove fisicamente o registro. Ela se encaixa quando você não tem razão legal ou de negócio para manter os dados e mantê-los cria risco (por exemplo, transcrições antigas de chat com detalhes sensíveis).
Uma exclusão suave (soft delete) mantém a linha mas marca como excluída (frequentemente com um timestamp deleted_at) e a esconde de telas e APIs normais. Soft delete é útil quando usuários esperam restauração, ou quando sistemas downstream ainda podem referenciar o registro. A desvantagem é que dados soft-deletados ainda existem, ocupam espaço e podem vazar em exports se você não tomar cuidado.
Anonimização mantém o evento ou transação, mas remove ou substitui tudo que identifica uma pessoa. Feita corretamente, não é reversível. Pseudonimização é diferente: você substitui identificadores (como email) por um token, mas mantém um mapeamento separado que permite reidentificar a pessoa. Isso ajuda em investigações de fraude, mas não é o mesmo que ser anônimo.
Seja explícito sobre dados relacionados, porque é aí que as políticas quebram. Excluir um registro e deixar anexos, thumbnails, caches, índices de busca ou cópias em analytics pode derrotar silenciosamente o propósito todo.
Você também precisa de prova de que a exclusão aconteceu. Mantenha um recibo simples de exclusão: o que foi removido ou anonimizado, quando a rotina rodou, qual workflow a executou e se completou com sucesso. No AppMaster, isso pode ser tão simples quanto um Business Process escrevendo uma entrada de auditoria quando o job termina.
Relatórios quebram quando você apaga ou anonimiza registros que seus dashboards esperam juntar ao longo do tempo. Antes de mudar qualquer coisa, liste quais números devem permanecer comparáveis mês a mês. Caso contrário você ficará depurando “por que o gráfico do ano passado mudou?” depois do fato.
Comece com uma lista curta de métricas que devem continuar precisas:
Depois redesenhe o que você armazena para relatórios de forma que não precise de identificadores pessoais. A abordagem mais segura é agregação. Em vez de manter toda linha bruta para sempre, mantenha totais diários, coortes semanais e contagens que não possam ser rastreadas a uma pessoa. Por exemplo, você pode reter “tickets criados por dia por categoria” e “mediana do tempo de primeira resposta por semana” mesmo se depois remover o conteúdo original do ticket.
Alguns relatórios ainda precisam de uma forma estável de agrupar comportamento ao longo do tempo. Use uma chave analítica substituta que não seja identificável diretamente (por exemplo, um UUID aleatório usado apenas para analytics) e remova ou proteja qualquer mapeamento para o ID real do usuário quando a janela de retenção terminar.
Também separe tabelas operacionais das tabelas de relatório quando possível. Dados operacionais mudam e são deletados. Tabelas de relatório devem ser snapshots append-only ou agregados.
Anonimizar tem consequências. Documente o que mudará para que equipes não se surpreendam:
Se você constrói no AppMaster, trate anonimização como um workflow: escreva agregados primeiro, verifique os resultados dos relatórios e então anonimze campos nas fontes.
Uma política de retenção funciona só quando vira comportamento normal do software. Trate-a como qualquer outra funcionalidade: defina entradas, defina ações e torne os resultados visíveis.
Comece com uma matriz de uma página. Para cada tipo de dado, registre a janela de retenção, o gatilho e o que acontece em seguida (manter, arquivar, excluir, anonimizar). Se pessoas não conseguirem explicar em um minuto, não será seguida.
Adicione estados claros de ciclo de vida para que registros não “sumam misteriosamente”. A maioria dos apps se vira com três: ativo, arquivado e pendente de exclusão. Armazene o estado no próprio registro, não apenas em uma planilha.
Uma sequência prática de implementação:
archived_at e delete_after) e atualize telas e APIs para respeitá-los.Exemplo: tickets de suporte podem ficar ativos por 90 dias, depois entrar em arquivo por 18 meses e então serem anonimizados. O workflow marca tickets como arquivados, move anexos grandes para armazenamento mais barato, mantém IDs e timestamps e substitui nomes e emails por valores anônimos.
No AppMaster, estados de ciclo de vida podem viver no Data Designer, e lógica de arquivar/purgar pode rodar como Business Processes agendados. O objetivo é execuções repetíveis com logs claros e fáceis de auditar.
A maior parte das falhas de retenção não é sobre a janela escolhida. Acontece quando a exclusão atinge tabelas erradas, perde arquivos relacionados ou altera chaves que os relatórios dependem.
Um cenário comum: a equipe de suporte apaga “tickets antigos” mas esquece anexos armazenados em tabela ou sistema de arquivos separado. Depois, um auditor pede evidência por trás de um reembolso. O texto do ticket existe, mas as capturas sumiram.
Outras armadilhas comuns:
user_id) sem atualizar dashboards, joins e consultas salvasOutro problema frequente é relatórios construídos sobre chaves baseadas em pessoa. Sobrescrever email e nome normalmente é ok. Substituir o ID interno pode dividir silenciosamente o histórico de uma pessoa em várias identidades, e métricas como usuários ativos mensais ou lifetime value vão derivar.
Duas correções ajudam a maioria das equipes. Primeiro, defina chaves de relatório que nunca mudem (por exemplo, um ID interno de conta) e mantenha-as separadas de campos pessoais que serão anonimizados ou deletados. Segundo, implemente exclusão como um workflow completo que percorre todos os dados relacionados, incluindo arquivos e logs. No AppMaster, isso costuma mapear bem para um Business Process que começa por um usuário ou conta, coleta dependências e então exclui ou anonimiza em ordem segura.
Por fim, decida quem pode pausar exclusão por retenção legal e como essa pausa é registrada. Se ninguém for dono das exceções, a política será aplicada de forma inconsistente.
Antes de rodar jobs de exclusão ou arquivamento, faça uma checagem de realidade. A maioria das falhas acontece porque ninguém sabe quem é dono dos dados, onde existem cópias ou como os relatórios dependem deles.
Uma política de retenção precisa de responsabilidade clara e um plano testável, não apenas um documento.
Uma validação simples é um dry run: pegue um lote pequeno (por exemplo, casos antigos de um cliente), execute o workflow em ambiente de teste e compare relatórios-chave antes e depois.
Armazene prova sem reintroduzir dados pessoais:
Se você constrói sobre AppMaster, essas checagens mapeiam diretamente para implementação: campos de retenção no Data Designer, jobs agendados no Business Process Editor e saídas de auditoria claras.
Imagine um portal do cliente que guarda tickets de suporte, faturas e reembolsos, e logs de atividade brutos (logins, visualizações de página, chamadas de API). O objetivo é reduzir risco e custo de armazenamento sem quebrar faturamento, auditorias ou relatórios de tendência.
Comece separando o que você precisa manter do que é usado apenas para suporte diário.
Um cronograma simples de retenção poderia ser:
Adicione uma etapa de arquivamento para tickets mais antigos. Em vez de manter cada mensagem para sempre nas tabelas principais, mova tickets fechados com mais de 18 meses para uma área de arquivo com um pequeno resumo pesquisável: ID do ticket, datas, área do produto, tags, código de resolução e um curto trecho da última nota do agente. Isso mantém contexto sem manter detalhes pessoais completos.
Para contas encerradas, prefira anonimização à exclusão quando você ainda precisar de tendências. Substitua identificadores pessoais (nome, email, endereço) por tokens aleatórios, mas mantenha campos não identificadores como tipo de plano e totais mensais. Armazene métricas de uso agregadas (contagens diárias de usuários ativos, tickets por mês, receita por mês) em uma tabela de relatório separada que nunca contenha dados pessoais.
O reporting mensal vai mudar, mas não deve piorar se você planejar:
No AppMaster, passos de arquivamento e anonimização podem rodar como Business Processes agendados, para que a política seja executada da mesma forma sempre.
Uma política de retenção funciona quando as pessoas conseguem segui-la e o sistema a aplica de forma consistente. Comece com uma matriz simples de retenção: cada conjunto de dados, dono, janela, gatilho, próxima ação (arquivar, excluir, anonimizar) e aprovação. Reveja com jurídico, segurança, finanças e a equipe que trata tickets de cliente.
Não automatize tudo de uma vez. Escolha um conjunto de dados fim a fim, idealmente algo comum como tickets de suporte ou logs de login. Torne o fluxo real, rode por uma semana e confirme que os relatórios batem com o que o negócio espera. Depois expanda para o próximo conjunto usando o mesmo padrão.
Mantenha a automação observável. Monitoramento básico costuma cobrir:
Planeje também a face voltada ao usuário. Decida o que usuários podem solicitar (export, exclusão, correção), quem aprova e o que o sistema faz. Dê ao suporte um script interno curto: que dados são afetados, quanto tempo leva e o que não pode ser recuperado depois da exclusão.
Se você quer implementar isso sem escrever código customizado, AppMaster (appmaster.io) é uma opção prática para automação de retenção porque você pode modelar campos de ciclo de vida no Data Designer e executar Business Processes agendados de arquivamento e anonimização com logging de auditoria. Comece por um conjunto de dados, torne-o previsível e confiável, e depois repita o padrão pelo resto do app.
Uma política de retenção evita crescimento descontrolado de dados e o hábito arriscado de “guardar tudo”. Ela define regras previsíveis sobre o que manter, por quanto tempo e o que acontece no fim, para que custos, riscos de privacidade e surpresas em relatórios não cresçam com o tempo.
Comece pelo motivo da existência dos dados e por quem precisa deles: operações, auditoria/tributos e proteção ao cliente. Escolha janelas simples por tipo de dado (faturas, tickets, logs, arquivos) e obtenha aprovação antecipada de jurídico, segurança, finanças e produto para não ter de desfazer fluxos depois.
Defina um gatilho claro por categoria, como data de fechamento do ticket, última atividade ou encerramento da conta. Se o gatilho ficar vago, equipes interpretarão de formas diferentes e a retenção irá divergir — é assim que “2 anos” vira cinco coisas distintas na prática.
Use uma flag ou estado de retenção legal que pause arquivamento/anonimização/exclusão para registros específicos, e faça essa pausa visível e auditável. O objetivo é pausar o fluxo normal sem criar cópias ocultas que ninguém consegue rastrear.
Um backup serve para recuperação depois de falhas ou erros humanos; é amplo e frequente. Um arquivo (archive) é uma ação deliberada que move dados antigos para armazenamento mais barato e controlado, ainda recuperável para auditorias, disputas e perguntas históricas.
Exclua quando não houver razão legal ou de negócio para manter os dados e sua existência traz risco. Anonimize quando você ainda precisar do evento ou transação para tendências ou prova, mas puder remover permanentemente os campos pessoais para que não seja mais vinculável a uma pessoa.
Soft delete é útil para restauração ou para evitar referências quebradas, mas não representa remoção real. Linhas com soft delete ainda ocupam espaço e podem vazar em exportações, analytics ou vistas administrativas se todas as consultas e fluxos não filtrarem consistentemente.
Proteja relatórios armazenando métricas de longo prazo como agregados ou snapshots que não dependam de identificadores pessoais. Se dashboards fazem joins em campos que você planeja sobrescrever (como email), redesenhe o modelo de relatórios antes para que gráficos históricos não mudem depois dos processos de retenção.
Trate retenção como recurso de produto: campos de ciclo de vida nos registros, jobs agendados para arquivar e depois purgar/anonimizar, e entradas de auditoria que provem o que aconteceu. Em AppMaster, isso mapeia diretamente para campos no Data Designer e Business Processes agendados que executam o mesmo fluxo sempre.
Faça um dry run em um ambiente de teste ou cópia parecida com produção e compare os totais-chave antes e depois. Confirme também que você consegue rastrear o mesmo registro por todos os lugares onde existe (tabelas, armazenamento de arquivos, exports, logs) e capture um recibo de exclusão/anonimização com timestamps, nome da regra e contagens.



Experimente o AppMaster com plano gratuito.
Quando estiver pronto, você poderá escolher a assinatura adequada.


