App de reserva de equipamentos: evite conflitos e acompanhe as devoluções
Planeje um app de reserva de equipamentos que evite reservas duplicadas, registre devoluções e danos e coloque itens com problemas em manutenção.
Aprenda métricas de painel de operações que refletem vazão, backlog e SLA. Decida o que medir, como agregar e quais gráficos levam à ação.
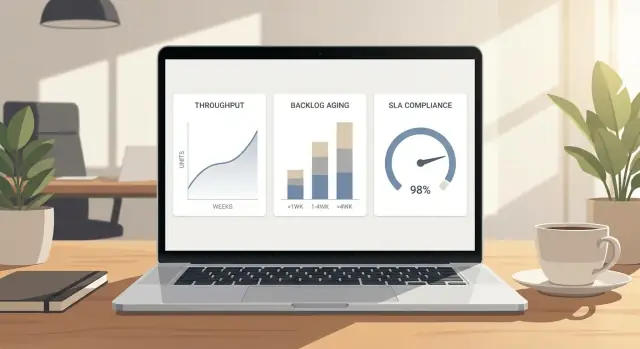
Um painel de operações não é uma parede de gráficos. É uma visão compartilhada que ajuda uma equipe a tomar as mesmas decisões mais rápido, sem discutir sobre quais números são “os certos”. Se não muda o que alguém faz a seguir, é decoração.
O trabalho é suportar um pequeno conjunto de decisões repetidas. A maioria das equipes volta às mesmas toda semana:
Pessoas diferentes usam o mesmo painel de formas diferentes. Um líder da linha de frente pode checar diariamente para decidir o que receberá atenção hoje. Um gerente pode revisar semanalmente para identificar tendências, justificar pessoal e evitar surpresas. Uma visão raramente atende bem aos dois; normalmente você precisa de uma visão para o líder e outra para o gerente.
“Gráficos bonitos” falham de forma simples: mostram atividade, não controle. Um gráfico pode impressionar enquanto esconde a realidade de trabalho se acumulando, envelhecendo e faltando com promessas. O painel deve revelar problemas cedo, não explicá-los depois do fato.
Defina o que é “bom” antes de escolher visuais. Para a maioria das equipes de operações, bom é chato:
Um exemplo simples: um time de suporte vê “tickets fechados” subindo e comemora. Mas o backlog está envelhecendo, e os itens mais antigos estão passando do SLA. Um painel útil mostra essa tensão imediatamente, para que o líder possa pausar novos pedidos, realocar um especialista ou escalar bloqueios.
A maioria das métricas de painel de operações cai em três grupos: o que você finaliza, o que está esperando e se você está cumprindo promessas.
Throughput é quanto trabalho chega em “concluído” em um período. O essencial é que “concluído” seja de verdade, não pela metade. Para um time de suporte, “concluído” pode significar que o ticket foi resolvido e fechado. Para um time de ops, pode significar que a requisição foi entregue, verificada e repassada. Se você contar trabalho que ainda precisa de ajustes, vai superestimar capacidade e perder problemas até que eles prejudiquem.
Backlog é o trabalho esperando para ser iniciado ou finalizado. O tamanho sozinho não é suficiente, porque 40 itens novos que chegaram hoje é muito diferente de 40 itens que estão parados há semanas. O backlog fica útil quando você adiciona idade, como “há quanto tempo os itens estão esperando” ou “quantos têm mais de X dias”. Isso diz se você tem um pico temporário ou um bloqueio crescente.
SLA é a promessa de tempo que você faz. Pode ser interno (para outro time) ou externo (para clientes). SLAs normalmente mapeiam para alguns relógios:
Essas três métricas se conectam diretamente. Throughput é o escoamento. Backlog é a água na banheira. SLA é o que acontece com o tempo de espera enquanto a banheira enche ou esvazia. Se o backlog cresce mais rápido que o throughput, os itens ficam mais tempo esperando e as violações de SLA aumentam. Se a vazão aumenta sem mudar a entrada, o backlog encolhe e o SLA melhora.
Um exemplo simples: seu time fecha cerca de 25 requisições por dia. Por três dias, novas requisições disparam para 40 por dia após uma atualização de produto. O backlog aumenta em cerca de 45 itens, e os itens mais antigos começam a ultrapassar seu SLA de 48 horas. Um bom painel torna essa causa e efeito óbvios para que você aja cedo: pause trabalho não urgente, redirecione um especialista ou ajuste temporariamente a entrada.
Um painel útil começa com as perguntas que as pessoas fazem quando algo parece errado, não com os dados mais fáceis de puxar. Comece escrevendo as decisões que o painel deve suportar.
A maioria das equipes precisa responder isso toda semana:
A partir daí, limite-se a 1 ou 2 medidas primárias por área. Mantém a página legível e torna “o que importa” óbvio.
Adicione um indicador líder para não interpretar mal o gráfico. Queda no throughput pode significar trabalho mais lento, mas também pode significar menos entradas. Meça chegadas (itens novos criados/abertos) ao lado do throughput.
Por fim, decida por quais dimensões você deve fatiar. Fatias transformam uma média em um mapa de onde agir. Comuns são equipe, fila, tier de cliente e prioridade. Mantenha apenas fatias que correspondam a donos e caminhos de escalonamento.
Um exemplo concreto: se o SLA geral parece ok, mas ao fatiar por prioridade você vê que o trabalho P1 viola o SLA duas vezes mais que o resto, isso aponta para outro conserto além de “trabalhar mais rápido”: falhas na cobertura on-call, definições de P1 confusas ou handoffs lentos entre filas.
A maioria das brigas por painel não é sobre números. É sobre palavras. Se dois times entendem “concluído” ou “violado” de formas diferentes, suas métricas parecerão precisas e ainda assim estarão erradas.
Comece definindo os eventos que você mede. Escreva-os como regras simples que qualquer um possa aplicar do mesmo jeito, mesmo num dia corrido.
Escolha um pequeno conjunto de eventos e prenda cada um a um momento claro no sistema, normalmente uma mudança de timestamp:
Também defina o que conta como violado para relatórios de SLA. O relógio do SLA é baseado em “created a primeira resposta”, “created a done” ou “started a done”? Decida se o relógio pausa enquanto está bloqueado e quais razões de bloqueio qualificam.
Retrabalho é onde times acidentalmente manipulam os números. Decida uma abordagem e mantenha-a.
Se um ticket é reaberto, você o conta como o mesmo item (com tempo de ciclo extra) ou como um item novo (nova data de created)? Contar como o mesmo item geralmente dá melhor visibilidade de qualidade, mas pode fazer o throughput parecer menor. Contar como novo pode esconder o custo real de erros.
Um compromisso prático é manter uma unidade de trabalho, mas rastrear separadamente “contagem de reaberturas” e “tempo de retrabalho” para que o fluxo principal permaneça honesto.
Agora concorde sobre sua unidade de trabalho e regras de status. “Ticket”, “pedido”, “requisição” ou “tarefa” podem funcionar, mas só se todo mundo usar o mesmo significado. Por exemplo: se um pedido se divide em três remessas, isso é uma unidade (pedido) ou três unidades (remessas)? Throughput e backlog mudam conforme essa escolha.
Documente os campos mínimos que seu sistema deve capturar, ou o painel ficará cheio de lacunas e suposições:
Agregação é onde painéis úteis frequentemente erram. Você comprime a realidade bagunçada em poucos números e depois se pergunta por que a linha “boa” não bate com o que a equipe sente todo dia. O objetivo não é um gráfico mais bonito. É um resumo honesto que ainda mostra risco.
Comece com janelas de tempo que se encaixem nas decisões que você toma. Visualizações diárias ajudam operadores a notar acúmulos de hoje. Semanais mostram se uma mudança realmente ajudou. Rollups mensais são melhores para planejamento e dimensionamento, mas podem esconder picos curtos que quebram SLAs.
Para medidas baseadas em tempo (tempo de ciclo, tempo para primeira resposta, tempo para resolução), não confie em médias. Alguns casos muito longos podem distorcer, e alguns muito curtos podem fazer as coisas parecerem melhores do que são. Medianas e percentis contam a história que importa às equipes: o que é típico (p50) e o que é doloroso (p90).
Um padrão simples que funciona:
Segmentação é a outra alavanca. Uma linha geral é ok para liderança, mas não deve ser a única vista. Divida por uma ou duas dimensões que correspondam a como o trabalho realmente flui, como fila, prioridade, região, produto ou canal (email, chat, telefone). Mantenha enxuto. Fatiar por cinco dimensões vira grupos minúsculos e gráficos ruidosos.
Casos de borda são onde times mentem para si mesmos. Decida antes como tratar trabalho pausado, “aguardando cliente”, feriados e janelas fora do horário comercial. Se seu relógio de SLA para quando você espera o cliente, seu painel deve refletir a mesma regra ou você perseguirá problemas que não são reais.
Uma abordagem prática é publicar dois relógios lado a lado: tempo calendário e tempo comercial. Tempo calendário bate com a experiência do cliente. Tempo comercial bate com o que sua equipe pode controlar.
Finalmente, verifique cada agregação com uma pequena amostra de tickets ou pedidos reais. Se o p90 parece ótimo mas operadores conseguem citar dez itens travados, seu agrupamento ou regras de relógio estão escondendo a dor.
Boas métricas fazem uma coisa bem: apontam o que fazer em seguida. Se um gráfico faz as pessoas discutir definições ou comemorar um número sem mudar comportamento, provavelmente é vaidade.
Um gráfico de linha do throughput (itens concluídos por dia ou semana) fica mais útil quando você adiciona contexto. Coloque uma banda de meta no gráfico, não uma linha única, para ver quando a performance está realmente fora.
Adicione chegadas (novos itens criados) no mesmo eixo temporal. Se o throughput está ok mas as chegadas disparam, dá para identificar o momento em que o sistema começa a ficar para trás.
Mantenha legível:
Uma contagem única de backlog esconde o problema real: trabalho antigo. Use buckets de envelhecimento que casem com onde a equipe sente dor. Um conjunto comum é 0-2 dias, 3-7, 8-14, 15+.
Um gráfico de barras empilhadas por semana funciona bem porque mostra se o backlog está envelhecendo mesmo se o volume total estiver estável. Se o segmento 15+ está crescendo, você tem problema de priorização ou capacidade, não “apenas uma semana cheia”.
Conformidade de SLA ao longo do tempo (semanal ou mensal) responde “Estamos cumprindo a promessa?” Mas não diz o que fazer hoje.
Combine com uma fila de violações: número de itens abertos que ainda estão dentro da janela de SLA mas próximos de violar. Por exemplo, mostre “itens com vencimento nas próximas 24 horas” e “já violados” como dois contadores pequenos ao lado da tendência. Isso transforma um percentual abstrato em uma lista de ações diárias.
Um cenário prático: após um novo lançamento, chegadas disparam. Throughput se mantém estável, mas o gráfico de envelhecimento do backlog cresce nos buckets 8-14 e 15+. Ao mesmo tempo, a fila de risco de violação salta. Você pode agir imediatamente: reatribuir trabalho, restringir entrada ou ajustar cobertura on-call.
Uma spec de painel deve caber em duas páginas: uma página para o que as pessoas veem, outra para como os números são calculados. Se for mais longa, geralmente está tentando resolver problemas demais ao mesmo tempo.
Esboce o layout no papel primeiro. Para cada painel, escreva uma pergunta diária que ele deve responder. Se você não consegue formular a pergunta, o gráfico vira uma métrica “bonita de olhar”.
Uma estrutura simples que permanece útil:
Em seguida, defina cada métrica em uma frase e liste os campos necessários para calculá-la. Mantenha fórmulas explícitas, por exemplo: “Tempo de ciclo é closed_at menos started_at, medido em horas, excluindo itens no status Waiting.” Anote os valores de status exatos, campos de data e qual tabela ou sistema é a fonte da verdade.
Adicione thresholds e alertas enquanto escreve, não só depois do lançamento. Um gráfico sem ação é só relatório. Para cada threshold, especifique:
Planeje caminhos de drill-down para que as pessoas vão da tendência à causa em menos de um minuto. Um fluxo prático é: linha de tendência (semana) -> visão por fila (hoje) -> lista de itens (principais infratores) -> detalhe do item (histórico e dono). Se você não consegue aprofundar até itens individuais, terá discussões em vez de consertos.
Antes do lançamento, valide com três semanas reais de dados históricos. Pegue uma semana calma e uma semana bagunçada. Verifique se os totais batem com resultados conhecidos e cheque 10 itens ponta a ponta para confirmar timestamps, transições de status e exclusões.
Um time de suporte lança uma grande atualização na segunda. Na quarta, clientes começam a perguntar o mesmo “como eu…” e surgem alguns novos reports de bug. A equipe sente aumento de trabalho, mas ninguém sabe se é um pico temporário ou desastre de SLA.
O painel é simples: uma vista por fila (Billing, Bugs, How-to). Ele acompanha chegadas (novos tickets), throughput (tickets resolvidos), tamanho do backlog, envelhecimento do backlog e risco de SLA (quantos tickets provavelmente vão violar com base na idade e tempo restante).
Após o update, as métricas mostram:
Isso não parece um problema geral de performance. Parece um problema de roteamento e foco. O painel deixa claras três decisões reais:
Eles escolhem um mix: um agente extra em “How-to” no horário de pico, mais resposta pronta e um pequeno artigo de ajuda.
No dia seguinte, revisam. Throughput não sobe dramaticamente, mas os sinais importantes mudam na direção certa. O envelhecimento do backlog para de subir e começa a cair. O gráfico de risco de SLA cai primeiro, e as violações reais diminuem depois. As chegadas a “How-to” começam a cair, confirmando que a correção de causa ajudou.
Um painel deve ajudar a decidir o próximo passo, não deixar o ontem bonito. Muitas equipes acabam com gráficos que escondem risco.
O clássico é “tickets fechados esta semana” sozinho. Pode subir mesmo quando o trabalho piora, pois ignora chegadas, reaberturas e envelhecimento.
Fique atento a padrões como:
Uma correção simples: sempre pareie um número de saída com um número de demanda e um número de tempo. Por exemplo: fechados vs criados, mais tempo de ciclo mediano.
Tempo médio de resolução é uma forma rápida de perder a dor do cliente. Um caso travado de 20 dias pode ficar invisível quando a média é puxada para baixo por muitas resoluções rápidas.
Use medianas e percentis (p75 ou p90) junto com uma visão de envelhecimento. Se só puder escolher um, escolha mediana. Depois acrescente uma pequena tabela “10 piores itens abertos por idade” para manter a cauda longa visível.
Se o Time A conta “concluído” como “primeira resposta enviada” e o Time B conta como “totalmente resolvido”, seus gráficos vão gerar discussões em vez de decisões. Escreva definições em palavras simples e mantenha consistência: o que inicia o relógio, o que o para e quais status o pausam.
Um exemplo realista: suporte muda um status de “Aguardando cliente” para “On hold”, mas engenharia nunca usa esse status. O tempo do SLA pausa para um grupo e não para o outro, então a liderança vê “SLA melhorando” enquanto clientes percebem soluções mais lentas.
Filtros ajudam, mas um painel com 12 filtros e 20 gráficos vira “escolha sua aventura”. Defina uma vista padrão clara (últimas 6-8 semanas, todos clientes, todos canais) e faça exceções intencionais.
Timestamps ausentes, mudanças de status preenchidas retroativamente e nomes de status inconsistentes envenenam resultados silenciosamente. Antes de criar mais gráficos, valide que campos-chave existem e estão na ordem correta.
Antes de chamar de “pronto”, verifique se o painel responde perguntas reais numa manhã de segunda ocupada. Bons painéis de operações ajudam a detectar risco cedo, explicar o que mudou e decidir o próximo passo.
Uma checagem rápida em uma tela:
Se alguma resposta for “não”, faça um pequeno ajuste primeiro. Muitas vezes é tão simples quanto adicionar comparação com a semana passada, dividir uma vista por prioridade ou mostrar uma visão móvel de 7 dias ao lado do total semanal. Se precisar escolher uma melhoria, escolha a que previne surpresas: envelhecimento do backlog por prioridade ou uma visão de contagem regressiva de SLA.
Transforme o checklist em uma spec curta que alguém possa implementar sem adivinhar. Mantenha enxuto e foque em definições e regras de decisão.
Se quiser prototipar rápido o fluxo completo (modelo de dados, regras e UI web), AppMaster (appmaster.io) é feito para criar aplicações completas sem programação manual, gerando ainda código-fonte real por trás. O importante é começar pequeno, lançar e só adicionar métricas que comprovem seu valor mudando decisões.
Comece pelas decisões repetitivas que sua equipe toma (pessoal, prioridade, escalonamento e correções de processo) e então escolha poucas medidas que suportem diretamente essas decisões. Se uma métrica não altera o que alguém faz a seguir, deixe-a de fora.
Monitore três sinais principais juntos: throughput (o que realmente fica concluído), backlog com envelhecimento (o que está esperando e há quanto tempo) e desempenho de SLA (se as promessas estão sendo cumpridas). A maioria dos painéis que dizem “estamos bem” falham pois mostram atividade sem mostrar risco.
Defina “concluído” como o momento em que o trabalho atende sua regra de aceitação, não um status intermediário como “enviado para revisão” ou “aguardando alguém”. Se “concluído” não for consistente, o throughput ficará inflado e você só verá problemas de capacidade quando os SLAs caírem.
O tamanho do backlog sozinho pode ser enganoso porque trabalho novo e trabalho antigo têm impactos diferentes. Adicione pelo menos um sinal de idade, como “quantos itens têm mais de X dias”, para ver se é um pico temporário ou um bloqueio crescente.
SLA é a promessa de tempo que você faz, normalmente ligada a primeira resposta, resolução ou tempo em status-chave. Escolha um relógio claro por promessa e documente quando ele começa, quando para e se pausa em estados bloqueados ou aguardando.
Coloque as chegadas (novos itens criados) ao lado do throughput no mesmo eixo de tempo. Uma queda no throughput pode significar trabalho mais lento, mas também pode significar menos chegadas; ver os dois evita conclusões erradas.
Use medianas e percentis (como p50 e p90) para métricas baseadas em tempo, porque médias são distorcidas por alguns casos extremos. Isso mantém a cauda longa visível, onde mora a maior parte da dor do cliente.
Decida antecipadamente se um item reaberto permanece a mesma unidade de trabalho ou vira um novo item, e mantenha essa regra. Um padrão comum é manter como o mesmo item para visibilidade de qualidade, mas rastrear contagem de reaberturas ou tempo de retrabalho separadamente.
A agregação oculta problemas quando seus buckets não correspondem às decisões ou quando você consolida demais. Use visualizações diárias para controle de hoje, semanais para checar tendências e mensais apenas para planejamento; sempre valide resultados contra uma amostra real de itens.
Construa uma especificação curta: uma página para o que os usuários veem e outra para como as métricas são calculadas, incluindo regras exatas de status e timestamps. Se quiser prototipar rápido, AppMaster pode ajudar a modelar dados, implementar regras de negócio e criar uma UI de dashboard sem programar, gerando código-fonte real por trás.



Experimente o AppMaster com plano gratuito.
Quando estiver pronto, você poderá escolher a assinatura adequada.


