App de reserva de equipamentos: evite conflitos e acompanhe as devoluções
Planeje um app de reserva de equipamentos que evite reservas duplicadas, registre devoluções e danos e coloque itens com problemas em manutenção.
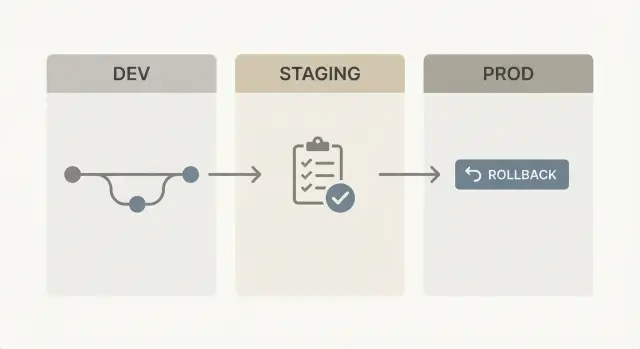
Gerenciamento de releases para apps no-code: configuração prática de ramificações e ambientes, planejamento de reversão e checagens rápidas de regressão após mudanças.
Quando uma plataforma regenera seu app a partir de modelos e lógica visual, um release pode parecer menos como "lançar uma pequena mudança" e mais como "reconstruir a casa". Isso é ótimo para manter o código limpo, mas quebra muitos hábitos que equipes adotaram com código escrito à mão.
Com código regenerado, você não conserta alguns arquivos. Você altera um modelo de dados, um fluxo ou uma tela, e a plataforma produz uma nova versão da aplicação. No AppMaster, backend, web e mobile podem atualizar a partir do mesmo conjunto de mudanças. O lado positivo é não acumular sujeira. A troca é que pequenas edições podem ter efeitos mais amplos do que você espera.
A dor normalmente aparece como:
“Seguro” não significa “nada nunca dará errado”. Significa que os releases são previsíveis, problemas aparecem antes que usuários relatem, e a reversão é rápida e sem drama. Você chega lá com regras claras de promoção (dev → staging → prod), um plano de rollback que funcione sob pressão e checagens de regressão ligadas ao que mudou de fato.
Isto é direcionado para criadores solo e equipes pequenas que entregam com frequência. Se você libera semanalmente ou diariamente, precisa de uma rotina que faça as mudanças parecerem ordinárias, mesmo que a plataforma regenere tudo com um clique.
Mesmo para no-code, a configuração mais segura continua sendo a mais simples: três ambientes com responsabilidades claras.
Dev é onde você constrói e quebra coisas de propósito. No AppMaster, é aqui que você edita o modelo de dados, ajusta processos de negócio e itera rapidamente na UI. Dev é para velocidade, não para estabilidade.
Staging é um ensaio. Deve parecer e se comportar como produção, mas sem clientes reais dependendo dele. Em staging você confirma que um build regenerado ainda funciona ponta a ponta, incluindo integrações como auth, pagamentos Stripe, email/SMS ou mensagens no Telegram.
Prod é onde usuários reais e dados reais vivem. Mudanças em produção devem ser repetíveis e mínimas.
Uma divisão prática que mantém a equipe alinhada:
Promova mudanças com base na confiança, não no calendário. Vá de dev para staging quando a feature for testável como um todo (telas, lógica, permissões e mudanças de dados juntas). Vá de staging para prod somente depois de conseguir rodar os fluxos principais duas vezes sem surpresas: uma em um deploy limpo e outra após uma pequena mudança de configuração.
Uma nomeação simples reduz confusão quando as coisas ficam tensas:
Trate staging como uma cópia do comportamento de produção, não como um estacionamento de trabalho “quase pronto”.
Branching não é sobre proteger o gerador de código. É sobre proteger o comportamento de produção.
Comece com uma branch mainline que corresponde ao que está em produção e esteja sempre liberável. Em termos do AppMaster, essa mainline representa o estado atual do Data Designer, dos processos de negócio e da UI que os usuários usam.
Uma configuração prática:
Mantenha branches de feature pequenas e curtas. Se uma mudança mexe em dados, lógica e UI, divida em dois ou três merges que deixem o app em funcionamento a cada passo (mesmo que a feature fique escondida atrás de um toggle ou visível apenas para administradores).
Use branch de release só quando precisar de tempo para estabilizar sem bloquear novo trabalho, como quando várias equipes entregam na mesma semana. Caso contrário, mescle para main com frequência para evitar deriva.
Algumas regras de merge previnem “surpresas da regeneração”:
Exemplo: se você adiciona uma etapa de aprovação, mescle a lógica do workflow primeiro enquanto o caminho antigo ainda funciona. Depois mescle a UI e permissões. Passos menores facilitam achar regressões.
Consistência não é clonar tudo. É manter as coisas certas idênticas.
A definição do seu app (modelo de dados, lógica, UI) deve avançar de forma segura, enquanto cada ambiente mantém suas próprias configurações. Na prática, dev, staging e prod devem usar o mesmo código gerado e as mesmas regras de esquema, mas valores de ambiente diferentes: domínios, endpoints de terceiros, limites de taxa e feature toggles.
Segredos precisam de um plano antes que você precise deles. Trate chaves de API, segredos OAuth e webhooks como propriedade do ambiente, não do projeto. Uma regra simples funciona bem: desenvolvedores podem ler segredos de dev, um grupo menor pode ler segredos de staging e quase ninguém pode ler segredos de prod. Rode chaves periodicamente e troque imediatamente se uma chave de produção cair numa ferramenta de dev.
Staging deve ser “igual à produção” nas formas que detectam falhas, não nas que criam risco:
Evite copiar dados de produção para staging a menos que seja absolutamente necessário. Se copiar, mascarar dados pessoais e mantenha a cópia por tempo limitado.
Exemplo: você adiciona uma nova etapa de aprovação em um Business Process. Em staging, use uma conta Stripe de teste e um canal Telegram de teste, além de pedidos sintéticos que imitem seu maior pedido real. Você vai pegar condições quebradas e permissões faltantes sem expor clientes.
Se você usa AppMaster, mantenha o design do app consistente entre ambientes e mude apenas configurações e segredos por deployment. Essa disciplina é o que torna os releases previsíveis.
Quando sua plataforma regenera código após cada mudança, o hábito mais seguro é avançar em passos pequenos e fazer cada passo fácil de verificar.
Escreva a mudança como um requisito pequeno e testável. Uma frase que um colega não técnico possa confirmar, por exemplo: “Gerentes podem adicionar uma nota de aprovação, e a solicitação permanece Pendente até que um gerente aprove.” Adicione 2–3 checagens (quem vê, o que acontece em aprovar/rejeitar).
Construa no dev e regenere com frequência. No AppMaster isso geralmente significa atualizar o Data Designer (se os dados mudarem), ajustar a lógica no Business Process e então regenerar e rodar o app. Mantenha as mudanças restritas para ver o que causou uma quebra.
Faça deploy dessa mesma versão para staging para checagens completas. Staging deve ter configurações o mais próximo possível da produção. Confirme integrações usando contas seguras de staging.
Crie um candidato a release e congele por um breve período. Escolha um build como RC. Pare de mesclar novo trabalho por uma janela curta (30–60 minutos já ajuda) para que os resultados dos testes permaneçam válidos. Se algo precisar ser consertado, corrija só isso e corte um novo RC.
Desdobre para prod e verifique os fluxos principais. Logo após o release, faça uma verificação rápida nos 3–5 fluxos que geram receita ou mantêm operações (login, criar solicitação, aprovar, exportar/relatório, notificações).
Se algo parecer incerto em staging, pause. Um atraso calmo sai mais barato que um rollback apressado.
Com código regenerado, “rollback” precisa ter um significado claro. Decida antes se rollback é:
Na maioria dos incidentes reais será preciso ambos: código + reset de configuração que restaure conexões com terceiros e toggles para o último estado conhecido. Mantenha um registro simples para cada ambiente (dev, staging, prod): tag do release, horário do deploy, quem aprovou e o que mudou. No AppMaster, isso significa salvar a versão exata do app que você implantou e as variáveis de ambiente e configurações de integração usadas. Sob estresse, você não deve ficar adivinhando qual build era estável.
Mudanças de banco de dados são o que mais frequentemente bloqueia rollback rápido. Separe mudanças reversíveis de irreversíveis. Adicionar uma coluna nullable costuma ser reversível. Remover uma coluna ou mudar o significado de valores geralmente não é. Para mudanças arriscadas, planeje um caminho de correção para frente (um hotfix que você possa enviar rápido) e, se necessário, um ponto de restauração (backup tirado imediatamente antes do release).
Um plano de rollback fácil de seguir:
Treine em staging. Rode um incidente falso mensalmente para que o rollback vire memória muscular.
As melhores checagens de regressão se relacionam com o que pode quebrar. Um novo campo em um formulário raramente exige re-testar tudo, mas pode afetar validação, permissões e automações a jusante.
Comece nomeando o raio de impacto: quais telas, papéis, tabelas e integrações são afetadas. Teste os caminhos que cruzam esse raio, mais alguns fluxos centrais que sempre devem funcionar.
Caminhos dourados são workflows obrigatórios que você executa a cada release:
Escreva resultados esperados em linguagem simples (o que você deve ver, o que deve ser criado, que status muda). Isso vira sua definição repetível de pronto.
Trate integrações como mini-sistemas. Após uma mudança, faça uma checagem rápida por integração, mesmo que a UI pareça ok. Por exemplo: um pagamento Stripe completa, um template de email é renderizado, uma mensagem Telegram chega e qualquer chamada de IA retorna uma resposta utilizável.
Adicione algumas checagens de sanidade de dados que peguem falhas silenciosas:
Em plataformas como o AppMaster, onde apps podem ser regenerados após edições, checagens focadas ajudam a confirmar que o novo build não mudou comportamento fora do escopo pretendido.
Minutos antes de enviar para produção, o objetivo não é perfeição. É pegar as falhas que mais doem: sinal de login quebrado, permissões erradas, integrações falhando e erros silenciosos em background.
Faça do staging um verdadeiro ensaio. No AppMaster, isso normalmente significa um build fresco e deploy para staging (não um ambiente meio atualizado) para testar o que você vai enviar.
Cinco checagens que cabem em cerca de 10 minutos:
Se seu app usa automações, adicione uma checagem rápida para falhas silenciosas: dispare um job agendado/assíncrono e confirme que ele conclui sem duplicar trabalho (dois registros, duas mensagens, duas cobranças).
Se alguma checagem falhar, pare o release e documente passos exatos para reproduzir. Corrigir um problema claro e repetível é mais rápido do que lançar e torcer.
Seu time de operações usa uma ferramenta interna para aprovar pedidos de compra. Hoje são dois passos: solicitante envia, gerente aprova. O novo requisito: adicionar uma aprovação financeira para qualquer valor acima de $5.000 e enviar uma notificação quando a equipe financeira aprovar ou rejeitar.
Trate como uma mudança contida. Crie uma branch de feature de curta duração a partir da mainline estável (a versão que está em prod). Construa primeiro no dev. No AppMaster, isso geralmente significa atualizar o Data Designer (novo status ou campos), adicionar lógica no Business Process Editor e depois atualizar UI web/mobile para mostrar a nova etapa.
Quando funcionar em dev, promova essa mesma branch para staging (mesmo estilo de configuração, dados diferentes). Tente quebrar de propósito, especialmente em permissões e casos de borda.
Em staging, teste:
Faça deploy para prod em uma janela tranquila. Tenha o release anterior pronto para redeploy se aprovações financeiras falharem ou notificações forem enviadas incorretamente. Se incluiu mudança de dados, decida antes se rollback significa “redeploy da versão antiga” ou “redeploy antigo mais um pequeno ajuste de dados”.
Documente a mudança em poucas linhas: o que foi adicionado, o que testou em staging, a tag/versão do release e o maior risco (normalmente permissões ou notificações). Na próxima vez que os requisitos mudarem, você vai andar mais rápido com menos debate.
Releases dolorosos raramente vêm de um grande bug único. Vêm de atalhos que tornam difícil ver o que mudou, onde mudou e como desfazer.
Uma armadilha comum são branches longos mantidos “até ficar prontos”. Elas derivam. Pessoas consertam em dev, mexem em staging e fazem hotfix em prod. Semanas depois, ninguém sabe qual versão é a real, e mesclar vira um palpite arriscado. Em plataformas como o AppMaster, branches curtas e merges frequentes mantêm as mudanças compreensíveis.
Outro assassino de release é pular o staging porque “é só uma mudança pequena”. Mudanças pequenas frequentemente tocam lógica compartilhada: regras de validação, passos de aprovação, callbacks de pagamento. A mudança de UI parece ínfima, mas os efeitos colaterais aparecem em produção.
Ajustes manuais em produção também custam caro. Se alguém muda variáveis de ambiente, feature flags, chaves de pagamento ou webhooks diretamente em prod “só uma vez”, você perde repetibilidade. O próximo release se comporta diferente e ninguém sabe por quê. Registre cada mudança em produção como parte do release e aplique do mesmo jeito sempre.
Erros de rollback tendem a machucar mais. Times fazem rollback da versão do app e esquecem que dados avançaram. Se seu release incluiu mudança de esquema ou novos campos obrigatórios, código antigo pode falhar contra dados novos.
Alguns hábitos previnem a maioria disso:
Sem um sinal de “pronto”, releases nunca realmente terminam. Eles apenas se misturam com a próxima emergência.
O estresse de release vem de decisões tomadas no dia do deploy. A solução é decidir uma vez, escrever e repetir.
Coloque suas regras de branching em uma página, em linguagem simples que qualquer um possa seguir quando você não estiver. Defina o que significa “pronto” para uma mudança (checagens rodadas, sign-off, o que conta como candidato a release).
Se quiser uma estrutura rígida, uma regra simples é:
Faça os ambientes parecerem diferentes de propósito. Dev é para mudanças rápidas, staging para provar o release, prod para clientes. Restrinja acesso a prod e dê a staging um dono claro do gate de release.
Se você constrói no AppMaster, a abordagem de “regenerar código-fonte limpo” fica mais confortável quando emparelhada com ambientes disciplinados e checagens rápidas de caminhos dourados. Para times avaliando ferramentas, AppMaster (appmaster.io) é feito para aplicações completas (backend, web e mobile), o que torna essa rotina de release especialmente útil.
Entregue menor e com mais frequência. Escolha uma cadência (semanal ou duas vezes por mês) e trate como trabalho normal. Releases menores tornam revisões mais rápidas, rollbacks mais simples e momentos de “espero que funcione” raros.
Use três ambientes: dev para mudanças rápidas, staging para um ensaio parecido com produção e prod para usuários reais. Isso mantém o risco contido e ainda permite entregas frequentes.
Porque a regeneração pode reconstruir mais do que você imagina. Uma pequena mudança em um campo compartilhado, fluxo ou permissão pode se propagar por telas e papéis, então você precisa de um jeito repetível de detectar surpresas antes dos usuários.
Trate staging como um ensaio que replica o comportamento de produção. Mantenha as mesmas regras de esquema e integrações principais, mas use contas de teste e segredos separados para validar ponta a ponta sem arriscar dinheiro ou usuários reais.
Comece com uma branch mainline que corresponde à produção e esteja sempre liberável, mais branches curtas de feature para mudanças únicas. Use branch de release só quando precisar de uma janela de estabilização breve e mantenha hotfixes mínimos e urgentes.
Divida em merges menores que deixem o app em um estado funcional. Por exemplo, faça o merge da lógica de workflow primeiro (mantendo o caminho antigo funcionando), depois UI e permissões, e depois validações mais rígidas. Assim as regressões ficam mais fáceis de localizar e corrigir.
Armazene como propriedade do ambiente e limite quem pode ler, especialmente em produção. Use chaves separadas por ambiente, roteie as chaves periodicamente e troque imediatamente se uma chave de produção vazar para uma ferramenta de dev.
Escolha um build testado como RC e pause novos merges por um curto período para que os testes permaneçam válidos. Se encontrar um problema, corrija apenas esse problema e crie um novo RC, em vez de empilhar mudanças durante os testes.
Decida antes se rollback significa redeploy do build anterior, restaurar a configuração anterior ou ambos. Na maioria dos incidentes você precisará dos dois, e deve verificar rapidamente os 3–5 fluxos críticos após o rollback.
Assuma que mudanças de esquema e validação podem bloquear rollback. Prefira alterações reversíveis (como adicionar colunas nullable) e, para mudanças arriscadas, planeje um caminho de correção para frente e faça um backup imediatamente antes do release.
Execute um conjunto curto de caminhos dourados a cada release e depois teste apenas o que está no raio de impacto da mudança (telas, papéis, tabelas, integrações). Faça também um teste rápido por integração para revelar falhas silenciosas.



Experimente o AppMaster com plano gratuito.
Quando estiver pronto, você poderá escolher a assinatura adequada.


