App de reserva de equipamentos: evite conflitos e acompanhe as devoluções
Planeje um app de reserva de equipamentos que evite reservas duplicadas, registre devoluções e danos e coloque itens com problemas em manutenção.
Fluxos de trabalho de longa duração podem falhar de formas confusas. Aprenda padrões de estado claros, contadores de retentativa, manejo de dead-letter e dashboards que operadores podem confiar.
Fluxos de trabalho de longa duração falham de forma diferente de requisições rápidas. Uma chamada de API curta ou tem sucesso ou retorna erro imediatamente. Um workflow que roda por horas ou dias pode completar 9 de 10 passos e ainda deixar uma bagunça: registros parcialmente criados, status confuso e sem uma ação clara a seguir.
Por isso “funcionou ontem” aparece com tanta frequência. O workflow não mudou, mas o ambiente sim. Fluxos longos dependem de outros serviços continuarem saudáveis, de credenciais válidas e de dados no formato esperado.
Os modos de falha mais comuns são: timeouts e dependências lentas (uma API parceira demora 40s hoje), atualizações parciais (registro A criado, B não criado e não é seguro rerodar), quedas de dependências (provedores de e-mail/SMS, gateways de pagamento, janelas de manutenção), callbacks perdidos e agendamentos que não ocorreram (um webhook que nunca chegou, um job timer que não disparou) e etapas humanas que param (uma aprovação fica dias parada e depois retoma com pressupostos desatualizados).
A parte difícil é o estado. Uma “requisição rápida” pode manter estado em memória até terminar. Um workflow não pode: precisa persistir estado entre passos e estar pronto para retomar após reinícios, deploys ou crashes. Também precisa lidar com o mesmo passo sendo disparado duas vezes (retentativas, webhooks duplicados, replays de operador).
Na prática, “confiável” é menos sobre nunca falhar e mais sobre ser previsível, explicável, recuperável e ter dono claro.
Previsível significa que o workflow reage do mesmo jeito sempre que uma dependência falha. Explicável significa que um operador consegue responder, em um minuto, “onde está preso e por quê?”. Recuperável significa que você pode reintentar ou continuar sem causar dano. Dono claro significa que cada item preso tem uma ação óbvia: esperar, reintentar, corrigir dados ou passar para uma pessoa.
Um exemplo simples: uma automação de onboarding cria um registro de cliente, provisiona acesso e envia uma mensagem de boas-vindas. Se a provisão der certo mas o envio falhar porque o provedor de e-mail está fora, um workflow confiável registra “Provisionado, mensagem pendente” e agenda uma retentativa. Não reexecuta provisão às cegas.
Ferramentas podem facilitar mantendo lógica de workflow e dados persistentes próximos. Por exemplo, o AppMaster permite modelar estado do workflow nos seus dados (via Data Designer) e atualizá-lo a partir de Business Processes visuais. Mas a confiabilidade vem do padrão, não da ferramenta: trate automação de longa duração como uma série de estados duráveis que sobrevivem ao tempo, falhas e intervenção humana.
Workflows longos tendem a falhar de formas repetíveis: uma API de terceiros fica lenta, um humano não aprovou algo, ou um job está esperando na fila. Estados claros tornam essas situações óbvias, para que não se confunda “levando tempo” com “quebrado”.
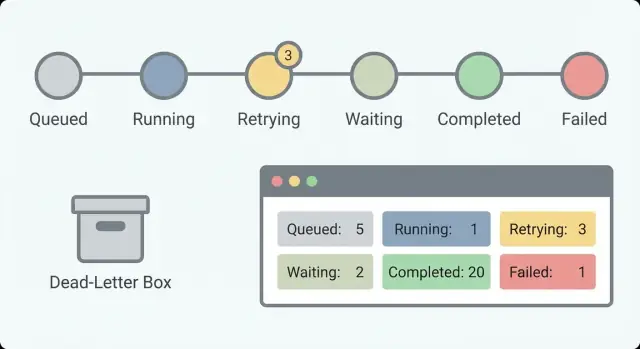
Comece com um conjunto pequeno de estados que respondam a uma pergunta: o que está acontecendo agora? Se tiver 30 estados, ninguém vai lembrar. Com cerca de 5 a 8, um responsável em plantão consegue escanear a lista e entender.
Um conjunto prático de estados que funciona para muitos workflows:
Separar Waiting de Running importa. “Waiting for customer response” é saudável. “Running por 6 horas” pode ser um travamento. Sem essa separação, você vai correr atrás de falsos alarmes e perder os reais.
Um nome de estado não basta. Adicione alguns campos que transformem um status em algo acionável:
Exemplo: um fluxo de onboarding pode mostrar “Waiting” com a razão “Pendência de aprovação do gerente” e última mudança “há 2 dias”. Isso indica que não está travado, mas pode precisar de um lembrete.
Trate nomes de estado como uma API. Se você renomeá-los todo mês, dashboards, alertas e playbooks de suporte ficam enganosos rápido. Se precisar de novo significado, considere introduzir um novo estado e deixar o antigo para registros existentes.
No AppMaster, você pode modelar esses estados no Data Designer e atualizá-los a partir da lógica de Business Process. Isso mantém o status visível e consistente na sua app em vez de enterrado em logs.
Retentativas ajudam até esconder o problema real. O objetivo não é “nunca falhar”. É “falhar de um jeito que pessoas entendam e possam consertar”. Isso começa com uma regra clara do que é retryable e do que não é.
Uma regra que a maioria das equipes aceita: retentar erros provavelmente temporários (time outs de rede, limites de taxa, quedas breves de terceiros). Não retente erros claramente permanentes (entrada inválida, permissões ausentes, “conta fechada”, “cartão recusado”). Se não souber em qual categoria um erro cai, trate como não-retryable até aprender mais.
Rastreie contadores de retentativa por passo (ou por chamada externa), não apenas um contador para todo o workflow. Um workflow pode ter dez passos e apenas um ser instável. Contadores no nível do passo impedem que um passo posterior “roube” tentativas de um passo anterior.
Por exemplo, uma chamada “Upload document” pode ser reintentada algumas vezes, enquanto “Send welcome email” não deve ficar tentando para sempre só porque o upload gastou tentativas antes.
Escolha um padrão de backoff que combine com o risco. Atrasos fixos podem bastar para retentativas simples e de baixo custo. Exponential backoff ajuda quando você pode estar batendo em limites de taxa. Adicione um teto para que as esperas não cresçam sem limites e um pouco de jitter para evitar tempestades de retentativas.
Depois, decida quando parar. Boas condições de parada são explícitas: tentativas máximas, tempo total máximo ou “desistir para certos códigos de erro”. Um gateway de pagamento retornando “cartão inválido” deve parar imediatamente mesmo que você normalmente permita cinco tentativas.
Operadores também precisam saber o que vai acontecer a seguir. Registre o próximo horário de retentativa e a razão (por exemplo, “Retry 3/5 às 14:32 devido a timeout”). No AppMaster, você pode gravar isso no registro do workflow para que um dashboard mostre “esperando até” sem adivinhações.
Uma boa política de retentativa deixa um rastro: o que falhou, quantas vezes foi tentado, quando tentará novamente e quando vai parar e ir para dead-letter.
Em workflows que duram horas ou dias, retentativas são norma. O risco é repetir um passo que já funcionou. Idempotência é a regra que torna isso seguro: um passo é idempotente se rodar duas vezes tem o mesmo efeito que rodar uma vez.
Uma falha clássica: você cobra um cartão e o workflow trava antes de salvar “pagamento realizado”. Na retentativa, cobra de novo. É um problema de dupla gravação: o mundo externo mudou, mas o estado do seu workflow não.
O padrão mais seguro é criar uma chave de idempotência estável para cada passo com efeitos colaterais, enviá-la na chamada externa e salvar o resultado do passo assim que recebê-lo. Muitos provedores de pagamento e receptores de webhooks suportam chaves de idempotência (por exemplo, cobrar um pedido pelo OrderID). Se o passo repetir, o provedor retorna o resultado original em vez de repetir a ação.
Dentro do seu motor de workflow, assuma que todo passo pode ser reexecutado. No AppMaster, isso geralmente significa salvar saídas de passo no modelo de dados e checá-las no Business Process antes de chamar outra integração. Se “Send welcome email” já tem um MessageID registrado, uma retentativa deve reutilizar esse registro e seguir adiante.
Uma abordagem prática à prova de duplicatas:
Duplicatas ainda acontecem, especialmente com webhooks de entrada ou quando um usuário clica no mesmo botão duas vezes. Decida a política por tipo de evento: ignore duplicatas exatas (mesma chave de idempotência), una atualizações compatíveis (por exemplo, last-write-wins para um campo de perfil) ou marque para revisão quando houver risco financeiro ou regulatório.
Uma dead-letter é um item de workflow que falhou e foi movido para fora do caminho normal para não bloquear todo o resto. Você guarda de propósito. O objetivo é facilitar entender o que aconteceu, decidir se é consertável e reprocessar com segurança.
O maior erro é salvar apenas uma mensagem de erro. Quando alguém examina a dead-letter depois, precisa de contexto suficiente para reproduzir o problema sem adivinhar.
Uma entrada útil de dead-letter captura:
Classificação torna dead-letters acionáveis. Uma categoria curta ajuda operadores a escolher o próximo passo. Grupos comuns incluem erro permanente (regra de negócio, estado inválido), problema de dados (campo faltando, formato errado), dependência indisponível (timeout, rate limit, queda) e auth/permissão (token expirado, credenciais rejeitadas).
Reprocessar deve ser controlado. A ideia é evitar danos repetidos, como cobrar duas vezes ou enviar spam de e-mails. Defina regras de quem pode re-tentar, quando re-tentar, o que pode mudar (editar campos específicos, anexar documento faltante, atualizar token) e o que deve permanecer fixo (request ID e chaves de idempotência downstream).
Torne itens de dead-letter pesquisáveis por identificadores estáveis. Quando um operador digita “order 18422” e vê o passo exato, entradas e histórico de tentativas, correções ficam rápidas e consistentes.
Se você constrói isso no AppMaster, trate a dead-letter como um modelo de banco de dados de primeira classe e armazene estado, tentativas e identificadores como campos. Assim seu dashboard interno pode consultar, filtrar e disparar uma ação controlada de reprocessamento.
Workflows longos podem falhar de formas lentas e confusas: um passo espera resposta por e-mail, um provedor de pagamento dá timeout, ou um webhook chega duplicado. Se você não consegue ver o que o workflow está fazendo agora, acaba chutando. Boa visibilidade transforma “está quebrado” em uma resposta clara: qual workflow, qual passo, que estado e o que fazer a seguir.
Comece fazendo cada passo emitir o mesmo pequeno conjunto de campos para que operadores escaneiem rápido:
Esses campos suportam contadores básicos que mostram saúde de relance. Para workflows longos, contagens importam mais que erros isolados porque você busca tendências: acúmulo de trabalho, pico de retentativas ou esperas que nunca terminam.
Acompanhe started, completed, failed, retrying e waiting ao longo do tempo. Um pequeno número em waiting pode ser normal (aprovações humanas). Um número de waiting crescente geralmente significa algo bloqueado. Um número de retrying em alta aponta para problema de provedor ou bug que repete o mesmo erro.
Alertas devem refletir o que operadores vivenciam. Em vez de “erro ocorreu”, alerte sobre sintomas: backlog crescente (started menos completed continua subindo), muitos workflows presos em waiting além do tempo esperado, taxa alta de retentativas em um passo específico ou um pico de falhas logo após um deploy ou mudança de configuração.
Mantenha um rastro de evento para cada workflow para que “o que aconteceu?” seja respondido em uma única visão. Um rastro útil inclui timestamps, transições de estado, resumos de entradas e saídas (não payloads sensíveis), e a razão das retentativas ou falhas. Exemplo: “Charge card: retry 3/5, timeout do provedor, próxima tentativa em 10m.”
IDs de correlação são a cola. Se um cliente diz “me cobraram duas vezes”, você precisa ligar os eventos do workflow ao charge ID do provedor e ao ID do pedido interno. No AppMaster, você pode padronizar isso na lógica de Business Process gerando e passando IDs de correlação por chamadas de API e passos de mensageria para que dashboard e logs batam.
Quando um workflow roda por horas ou dias, falhas são normais. O que transforma falhas normais em incidentes é um dashboard que só diz “Failed” e nada mais. O objetivo é ajudar um operador a responder três perguntas rápido: o que está acontecendo, por que está acontecendo e o que ele pode fazer com segurança a seguir.
Comece com uma lista de workflows que facilite achar os poucos itens que importam. Filtros reduzem pânico e ruído porque qualquer um pode estreitar a visão rapidamente.
Filtros úteis incluem estado, idade (hora de início e tempo no estado atual), dono (time/cliente/operador responsável), tipo (nome/versão do workflow) e prioridade se houver passos voltados ao cliente.
Em seguida, mostre o “porquê” junto ao status em vez de enterrá-lo nos logs. Um status pill só ajuda se vier com a última mensagem de erro, uma categoria curta do erro e o que o sistema planeja fazer a seguir. Dois campos fazem a maior parte do trabalho: última falha e próxima retentativa. Se next retry estiver vazio, deixe claro se o workflow está aguardando humano, pausado ou falhou permanentemente.
Ações de operador devem ser seguras por padrão. Guie as pessoas para ações de baixo risco primeiro e deixe ações arriscadas explícitas:
“Force continue” é onde a maior parte dos danos acontece. Se oferecer essa opção, descreva o risco em linguagem simples: “Isso pula a verificação de pagamento e pode criar um pedido não pago.” Mostre também quais dados serão escritos se prosseguir.
Audite tudo que operadores fazem. Registre quem fez, quando, estado antes/depois e a nota de razão. Se você constrói ferramentas internas no AppMaster, armazene esse rastro de auditoria como tabela de primeira classe e mostre na página de detalhe do workflow para que as trocas de turno fiquem limpas.
Esse padrão mantém workflows previsíveis: todo item está sempre em estado claro, toda falha tem um destino e operadores podem agir sem adivinhar.
Step 1: Define states and allowed transitions. Write down a small set of states a person can understand (for example: Queued, Running, Waiting on external, Succeeded, Failed, Dead-letter). Then decide which moves are legal so work doesn’t drift into limbo.
Step 2: Break work into small steps with clear inputs and outputs. Each step should accept one well-defined input and produce one output (or a clear error). If you need a human decision or an external API call, make it its own step so it can pause and resume cleanly.
Step 3: Add a retry policy per step. Pick an attempt limit, a delay between tries, and stop reasons that should never retry (invalid data, permission denied, missing required fields). Store a retry counter per step so operators can see exactly what’s stuck.
Step 4: Persist progress after every step. After a step finishes, save the new state plus key outputs. If the process restarts, it should continue from the last completed step, not start over.
Step 5: Route to a dead-letter record and support reprocessing. When retries are exhausted, move the item to a dead-letter state and keep full context: inputs, last error, step name, attempt count, and timestamps. Reprocessing should be deliberate: fix data or config first, then re-queue from a specific step.
Step 6: Define dashboard fields and operator actions. A good dashboard answers “what failed, where, and what can I do next?” In AppMaster, you can build this as a simple admin web app backed by your workflow tables.
Campos e ações-chave para incluir:
Onboarding de funcionário é um bom teste de estresse. Mistura aprovações, sistemas externos e pessoas offline. Um fluxo simples: RH submete um formulário de novo funcionário, o gerente aprova, TI cria contas e o novo funcionário recebe uma mensagem de boas-vindas.
Deixe estados legíveis. Quando alguém abre o registro, deve ver imediatamente a diferença entre “Waiting for approval” e “Retrying account setup.” Uma linha de clareza pode salvar uma hora de investigação.
Um conjunto claro de estados para mostrar na UI:
Retentativas pertencem a passos que dependem de redes ou APIs de terceiros. Provisionamento de contas (email, SSO, Slack), envio de e-mail/SMS e chamadas a APIs internas são bons candidatos a retentativa. Mantenha o contador visível e imponha um teto (por exemplo, reintentar até cinco vezes com atrasos crescentes e depois parar).
Dead-letter é para problemas que não se resolvem sozinhos: gerente ausente no formulário, endereço de e-mail inválido ou pedido de acesso em conflito com política. Ao enviar um run para dead-letter, armazene contexto: qual campo falhou na validação, última resposta da API e quem pode autorizar um override.
Operadores devem ter um conjunto pequeno de ações simples: corrigir dados (adicionar gerente, ajustar email), reexecutar um passo falhado (não todo o workflow) ou cancelar de forma limpa (e desfazer setups parciais se necessário).
Com AppMaster, você pode modelar isso no Business Process Editor, manter contadores de retentativa nos dados e construir uma tela de operador no web UI builder que mostra estado, última falha e um botão para reexecutar o passo falhado.
A maioria dos problemas de confiabilidade é previsível: um passo roda duas vezes, retentativas disparam às 2h, ou um item “preso” não tem pista do que aconteceu. Um checklist impede que vire adivinhação.
Verificações rápidas que pegam a maioria dos problemas cedo:
Se só puder melhorar uma coisa, melhore visibilidade. Muitos “bugs de workflow” são na verdade “não conseguimos ver o que está acontecendo”. Seu dashboard deve mostrar o que aconteceu por último, o que vai acontecer a seguir e quando.
Uma visão prática para o operador inclui estado atual, última mensagem de erro, contador de tentativas, próximo horário de retentativa e uma ação clara (retry now, marcar como resolvido ou enviar para revisão manual). Mantenha ações seguras por padrão: reexecute um passo único, não todo o workflow.
Próximos passos:
Trate isso como um checklist vivo. Toda vez que adicionar um novo passo, execute essas verificações antes de chegar à produção.
Workflows de longa duração podem ter sucesso por horas e ainda falhar perto do fim, deixando mudanças parciais. Eles também dependem de coisas que podem mudar enquanto estão em execução, como disponibilidade de terceiros, credenciais, formato dos dados e tempo de resposta humano.
Mantenha o conjunto de estados pequeno e legível para que um operador entenda à primeira vista. Um padrão sólido é algo como queued, running, waiting, succeeded e failed, com “waiting” claramente separado de “running” para distinguir pausas saudáveis de travamentos.
Armazene o suficiente para tornar o status acionável: o estado atual, quando mudou pela última vez, qual era o estado anterior e um motivo curto quando estiver em espera ou com falha. Se houver retentativas, guarde também um contador de tentativas e o próximo horário planejado de nova tentativa para que ninguém precise adivinhar o que vai acontecer.
Evita alarmes falsos e incidentes perdidos. “Waiting for approval” ou “waiting for a webhook” pode ser totalmente saudável, enquanto “running por seis horas” pode ser um passo travado. Tratar esses casos como estados distintos melhora tanto os alertas quanto as decisões dos operadores.
Retente erros que provavelmente são temporários, como timeouts, limites de taxa e quedas breves de provedores. Não retente erros claramente permanentes, como entrada inválida, permissões ausentes ou pagamento recusado — repetir só desperdiça esforços e pode causar efeitos colaterais.
Retentativas por passo evitam que uma integração instável consuma todas as tentativas do workflow. Também facilita o diagnóstico: você vê qual passo está falhando, quantas vezes já tentou e se os demais passos seguem normais.
Use um backoff simples que faça sentido para o risco, e sempre imponha um teto para que as esperas não cresçam indefinidamente. Defina regras explícitas de parada, como número máximo de tentativas ou tempo total máximo, e registre tanto a razão da falha quanto a próxima tentativa agendada para deixar a propriedade clara.
Assuma que qualquer passo pode rodar duas vezes por retentativas, replays ou webhooks duplicados, e projete para que repetir não cause danos. Uma abordagem comum é usar uma chave de idempotência estável por passo com efeitos, salvar “step started” antes da chamada externa e armazenar o resultado assim que ele chegar para que reexecuções reutilizem o resultado em vez de repetir a ação.
Um item em dead-letter é aquele que você move para fora do caminho normal depois que as retentativas se esgotam, para que não bloqueie o restante. Armazene contexto suficiente para corrigir e reprocessar com segurança depois: identificadores, entradas (ou um snapshot seguro), onde falhou, histórico de tentativas e a resposta do serviço dependente — não apenas uma mensagem vaga.
Dashboards que ajudam rapidamente mostram onde está, por que está lá e o que vai acontecer a seguir, usando campos consistentes como workflow ID, passo atual, estado, tempo no estado, última falha e IDs de correlação. Operadores devem ter ações seguras por padrão, como reexecutar um único passo ou pausar/resumir, com ações perigosas claramente sinalizadas.



Experimente o AppMaster com plano gratuito.
Quando estiver pronto, você poderá escolher a assinatura adequada.


