App de reserva de equipamentos: evite conflitos e acompanhe as devoluções
Planeje um app de reserva de equipamentos que evite reservas duplicadas, registre devoluções e danos e coloque itens com problemas em manutenção.
Exclusão suave vs exclusão definitiva: aprenda a manter o histórico, evitar referências quebradas e ainda cumprir requisitos de privacidade com regras claras.
“Excluir” pode significar duas coisas bem diferentes. Confundi-las é como times perdem histórico ou deixam de atender pedidos de privacidade.
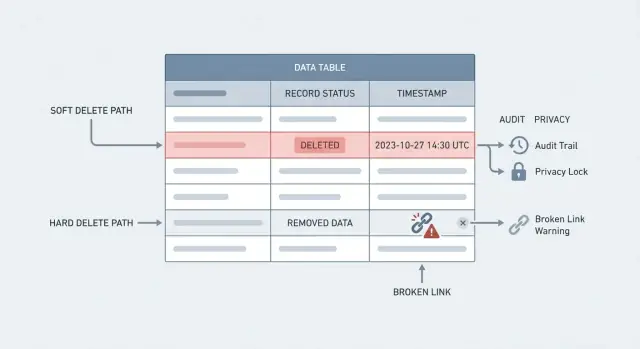
Uma exclusão definitiva é o que a maioria imagina: a linha é removida do banco de dados. Consulta depois e ela sumiu. É remoção de verdade, mas também pode quebrar referências (como um pedido que aponta para um cliente deletado) a menos que você desenhe em volta disso.
Uma exclusão suave mantém a linha, mas marca ela como deletada, normalmente com um campo como deleted_at ou is_deleted. Seu app trata como se tivesse sumido, mas os dados ainda existem para relatórios, suporte e auditoria.
A troca por trás de exclusão suave vs exclusão definitiva é simples: histórico vs remoção real. Soft delete protege o histórico e torna o “desfazer” possível. Hard delete reduz o que você armazena, o que importa para privacidade, segurança e regras legais.
Exclusões afetam mais que armazenamento. Elas mudam o que seu time pode responder depois: um agente de suporte tentando entender uma reclamação passada, financeiro tentando reconciliar cobranças, ou compliance checando quem mudou o quê e quando. Se os dados desaparecem cedo demais, relatórios mudam, totais deixam de bater e investigações viram suposições.
Um modelo mental útil:
Na prática, você pode soft deletear uma conta de usuário para impedir login e manter o histórico de pedidos intacto, e então hard deletear (ou anonimizar) campos pessoais após um período de retenção ou um pedido verificado de direito de eliminação (GDPR).
Nenhuma ferramenta decide isso por você. Mesmo que esteja construindo com uma plataforma no-code como AppMaster, o trabalho real é decidir, por tabela, o que “deletado” significa e garantir que toda tela, relatório e API siga a mesma regra.
A maioria dos times só nota exclusões quando algo dá errado. Um delete “simples” pode apagar contexto, histórico e sua capacidade de explicar o que aconteceu.
Hard deletes são arriscados porque são difíceis de reverter. Alguém clica no botão errado, um job automático tem um bug, ou um agente de suporte segue o playbook equivocado. Sem backups limpos e um processo de restauração definido, essa perda vira permanente e o impacto aparece rápido no negócio.
Referências quebradas são a próxima surpresa. Você deleta um cliente, mas os pedidos dele ainda existem. Agora há pedidos apontando para nada, faturas que não mostram o nome do pagador e um portal que dá erro ao carregar dados relacionados. Mesmo com foreign key constraints, a “correção” pode ser pior: deletes em cascata podem apagar bem mais do que você esperava.
Analytics e relatórios também ficam bagunçados. Quando registros antigos somem, métricas mudam retroativamente. A taxa de conversão do mês anterior desloca, o lifetime value cai e linhas de tendência desenvolvem lacunas que ninguém explica. O time começa a discutir números em vez de tomar decisões.
Suporte e compliance é onde dói mais. Clientes perguntam “Por que fui cobrado?” ou “Quem mudou meu plano?” Se o registro sumiu, você não reconstrói a linha do tempo. Você perde a trilha de auditoria que responderia perguntas básicas como o que mudou, quando e por quem.
Modos de falha comuns na discussão soft delete vs hard delete:
Soft delete costuma ser a escolha mais segura quando um registro tem valor de longo prazo ou está conectado a outros dados. Em vez de remover a linha, você marca como deletada (por exemplo, deleted_at ou is_deleted) e a esconde das vistas normais. Nesse tipo de decisão, esse padrão tende a reduzir surpresas depois.
Ele brilha onde você precisa de uma trilha de auditoria em bancos de dados. Times de operações frequentemente precisam responder perguntas simples como “Quem alterou esse pedido?” ou “Por que essa fatura foi cancelada?” Se você hard deletear cedo demais, perde evidência importante para financeiro, suporte e relatórios de compliance.
Soft delete também torna o “desfazer” possível. Admins podem restaurar um ticket fechado por engano, trazer de volta um produto arquivado ou recuperar conteúdo gerado por usuários após um falso relatório de spam. Esse tipo de fluxo de restauração é difícil se os dados foram removidos fisicamente.
Relacionamentos são outra grande razão. Hard deletar uma linha pai pode quebrar foreign keys ou deixar lacunas confusas nos relatórios. Com soft delete, joins permanecem estáveis e totais históricos continuam consistentes (receita diária, pedidos atendidos, estatísticas de tempo de resposta).
Soft delete é um bom padrão para registros de negócio como tickets de suporte, mensagens, pedidos, faturas, logs de auditoria, histórico de atividade e perfis de usuário (pelo menos até confirmar exclusão final).
Exemplo: um agente de suporte “deleta” uma nota de pedido que contém um erro. Com soft delete, a nota some da UI normal, mas supervisores ainda podem revisá-la em caso de reclamação, e relatórios financeiros continuam explicáveis.
Soft delete é um ótimo padrão para muitos apps, mas há momentos em que manter dados (mesmo ocultos) é a escolha errada. Hard delete remove o registro de vez, e às vezes é a única opção que atende a requisitos legais, de segurança ou de custo.
O caso mais claro é privacidade e obrigações contratuais. Se uma pessoa invoca o direito de eliminação (GDPR), ou seu contrato promete exclusão após um período, “marcar como deletado” muitas vezes não é suficiente. Pode ser necessário remover a linha, cópias relacionadas e quaisquer identificadores que remetam à pessoa.
Segurança é outra razão. Alguns dados são sensíveis demais para manter: tokens de acesso crus, códigos de reset de senha, chaves privadas, códigos de verificação one-time ou segredos não criptografados. Mantê-los por histórico raramente vale o risco.
Hard delete também pode ser a escolha certa por escala. Se você tem tabelas massivas de eventos antigos, logs ou telemetria, soft delete faz o banco crescer silenciosamente e deixa consultas mais lentas. Uma política de purge planejada mantém o sistema responsivo e os custos previsíveis.
Hard delete costuma ser apropriado para dados temporários (cache, sessões, imports de rascunho), artefatos de segurança de curta duração (tokens de reset, OTPs, códigos de convite), contas de teste/demo e grandes conjuntos históricos onde só estatísticas agregadas são necessárias.
Uma abordagem prática é separar “histórico de negócio” de “dados pessoais”. Por exemplo, mantenha faturas para contabilidade, mas apague (ou anonimize) os campos de perfil que identificam uma pessoa.
Se seu time debate soft delete vs hard delete, use um teste simples: se manter os dados cria risco legal ou de segurança, hard delete (ou anonimização irreversível) deve prevalecer.
Um soft delete funciona melhor quando é chato e previsível. O objetivo é simples: o registro fica no banco, mas as partes normais do app agem como se ele tivesse sumido.
Você verá três padrões comuns: um deleted_at timestamp, um flag is_deleted ou um enum de status. Muitos times preferem deleted_at porque responde duas perguntas ao mesmo tempo: está deletado e quando aconteceu.
Se você já tem vários estados de ciclo de vida (ativo, pendente, suspenso), um enum de status ainda pode funcionar, mas mantenha “deletado” separado de “arquivado” e “desativado”. Esses são diferentes:
Soft delete vs hard delete muitas vezes falha em campos únicos como email, username ou número de pedido. Se um usuário está “deletado” mas o email ainda está armazenado e único, a mesma pessoa não pode se cadastrar novamente.
Duas soluções comuns: aplicar unicidade apenas a linhas não deletadas, ou reescrever o valor no momento da exclusão (por exemplo, anexar um sufixo aleatório). A escolha depende de privacidade e necessidades de auditoria.
Decida quem vê o quê. Uma regra comum: usuários normais nunca veem registros deletados, suporte/admin vê com um rótulo claro, e exports/relatórios os incluem só quando solicitado.
Não confie em “todo mundo lembra de adicionar o filtro”. Coloque a regra em um lugar só: views, queries padrão ou na sua camada de acesso a dados. Se estiver no AppMaster, isso normalmente significa embutir o filtro em como seus endpoints e Business Processes buscam dados, para que linhas deletadas não reapareçam por acidente em uma nova tela.
Escreva os significados em uma nota interna curta (ou comentários de schema). O você do futuro agradecerá quando “deletado”, “arquivado” e “desativado” aparecerem na mesma reunião.
Exclusões quebram apps mais frequentemente por causa de relacionamentos. Um registro raramente está sozinho: usuários têm pedidos, tickets têm comentários, projetos têm arquivos. A parte complicada em soft delete vs hard delete é manter referências consistentes enquanto o produto se comporta como se o item tivesse “sumido”.
Foreign keys te protegem de referências quebradas, mas cada opção tem um significado diferente:
Se você usa soft delete, RESTRICT costuma ser o padrão mais seguro. Você mantém a linha, as chaves continuam válidas e evita filhos apontando para nada.
Soft delete normalmente não altera foreign keys. Em vez disso, você filtra pais deletados no app e nos relatórios. Se um cliente está soft-deleted, suas faturas ainda devem fazer join corretamente, mas telas não devem mostrar o cliente em dropdowns.
Para anexos, comentários e logs de atividade, decida o que “deletar” significa para o usuário. Alguns times mantêm o invólucro mas removem partes de risco: substituem o conteúdo do anexo por um placeholder se a privacidade exigir, marcam comentários como de um usuário deletado (ou anonimizam o autor) e mantêm logs imutáveis.
Joins e relatórios precisam de uma regra clara: linhas deletadas devem ser incluídas? Muitos times mantêm duas queries padrão: uma “apenas ativas” e outra “incluindo deletadas”, para que suporte e relatórios não escondam histórico importante por acidente.
Uma política prática frequentemente usa soft delete para erros do dia a dia e hard delete para necessidades legais ou de privacidade. Se você tratar isso como uma decisão única (soft delete vs hard delete), perde o meio-termo: mantenha histórico por um tempo, depois purgue o que precisa ir.
Comece classificando dados em alguns grupos. “Perfil de usuário” é pessoal, “transações” são registros financeiros e “logs” são histórico do sistema. Cada grupo precisa de regras diferentes.
Um plano curto que funciona para a maioria dos times:
Um cliente solicita encerrar a conta. Faça soft delete no registro do usuário imediatamente para que não possa mais entrar e você não quebre referências. Depois anonimize campos pessoais que não devem permanecer (nome, email, telefone), mantendo fatos não pessoais de transações necessários para contabilidade. Finalmente, um job agendado remove o que ainda for pessoal após o período de espera.
Times se complicam não porque escolheram a abordagem errada, mas porque aplicam de forma desigual. Um padrão comum é “soft delete vs hard delete” no papel, mas “esconde numa tela e esquece do resto” na prática.
Um erro fácil: você oculta registros deletados na UI, mas eles ainda aparecem via API, CSVs, ferramentas admin ou jobs de sincronização. Usuários percebem rápido quando um cliente “deletado” aparece numa lista de e-mail ou numa busca móvel.
Relatórios e busca são outra armadilha. Se queries de relatório não filtram consistentemente linhas deletadas, totais se desviam e dashboards perdem confiança. Os piores casos são jobs em background que reindexam ou reenviam itens deletados porque não aplicaram as mesmas regras.
Hard deletes também podem ir longe demais. Um único delete em cascata pode apagar pedidos, faturas, mensagens e logs que você precisava para auditoria. Se precisa fazer hard delete, seja explícito sobre o que pode desaparecer e o que deve ser retido ou anonimizad0.
Restrições únicas causam dor sutil com soft delete. Se um usuário deleta a conta e depois tenta se cadastrar com o mesmo email, o cadastro pode falhar se a linha antiga ainda contém o email único. Planeje isso cedo.
Times de compliance vão perguntar: você consegue provar que a exclusão aconteceu e quando? “Achamos que foi deletado” não passa em muitas revisões de política de retenção. Mantenha timestamp de exclusão, quem/que o acionou e um registro imutável.
Antes de liberar, verifique a superfície completa: API, exports, busca, relatórios e jobs em background. Revise cascatas tabela por tabela e confirme que usuários podem recriar dados “únicos” como email ou username quando isso fizer parte da promessa do produto.
Antes de escolher soft delete vs hard delete, verifique o comportamento real do app, não apenas o schema.
Depois, teste o caminho de privacidade de ponta a ponta. Você consegue cumprir um pedido de eliminação do GDPR em cópias, exports, índices de busca, tabelas analíticas e integrações, não só no banco principal?
Uma forma prática de validar é rodar um “delete user” em staging e seguir a trilha dos dados.
Um cliente pede: “Por favor, exclua minha conta.” Você também tem faturas que devem permanecer para contabilidade e checagens de chargeback. Aqui é onde a discussão soft delete vs hard delete vira prática: você pode remover acesso e detalhes pessoais enquanto mantém registros financeiros que o negócio precisa.
Separe “a conta” do “registro de cobrança”. A conta trata de login e identidade. O registro de cobrança é sobre uma transação que já aconteceu.
Uma abordagem limpa:
Tickets de suporte e mensagens muitas vezes ficam no meio. Se o conteúdo da mensagem inclui dados pessoais, talvez precise redigir partes do texto, remover anexos e manter o invólucro do ticket (timestamps, categoria, resolução) para controle de qualidade. Se seu produto envia mensagens (email/SMS, Telegram), remova identificadores de envio também, para que a pessoa não seja contatada novamente.
O que o suporte ainda pode ver? Normalmente números de fatura, datas, valores, status e uma nota indicando que o usuário foi deletado e quando. O que não pode ver é qualquer coisa que identifique a pessoa: email de login, nome completo, endereços, dados de pagamento salvos ou sessões ativas.
Decisões sobre exclusão só ficam quando estão escritas e implementadas do mesmo jeito pelo produto. Trate exclusão suave vs exclusão definitiva como uma questão de política primeiro, não um truque de código.
Comece com uma política de retenção de dados simples que qualquer pessoa do time possa ler. Deve dizer o que você guarda, por quanto tempo e por quê. O “por quê” importa porque indica o que vence quando objetivos conflitam (por exemplo, histórico de suporte vs pedidos de privacidade).
Um bom padrão costuma ser: soft delete para registros de negócio do dia a dia (pedidos, tickets, projetos), hard delete para dados verdadeiramente sensíveis (tokens, segredos) e qualquer coisa que não deva ser retida.
Quando a política estiver clara, construa os fluxos que a aplicam: uma vista de “lixeira” para restauração, uma fila de purge para exclusão irreversível após checagens, e uma vista de auditoria mostrando quem fez o quê e quando. Faça o “purge” mais difícil que o “delete” para evitar uso acidental.
Se estiver implementando no AppMaster (appmaster.io), ajuda modelar campos de soft-delete no Data Designer e centralizar lógica de delete, restore e purge em um Business Process, assim as mesmas regras valem para telas e endpoints.
Uma hard delete remove fisicamente a linha do banco de dados, então consultas futuras não a encontram. Uma soft delete mantém a linha, mas a marca como deletada (frequentemente com deleted_at), de modo que o app a esconde nas telas normais enquanto preserva o histórico para suporte, auditoria e relatórios.
Use soft delete por padrão para registros de negócio que você pode precisar explicar depois, como pedidos, faturas, tickets, mensagens e atividade de conta. Isso reduz perda acidental de dados, mantém relacionamentos intactos e possibilita um “desfazer” sem recorrer a backups.
Hard delete é indicado quando manter os dados cria risco de privacidade ou segurança, ou quando regras de retenção exigem remoção definitiva. Exemplos comuns: tokens de reset de senha, códigos one-time, sessões, API tokens e dados pessoais que devem ser apagados após uma solicitação verificada ou após o período de retenção.
Um campo deleted_at é uma escolha comum porque indica tanto que o registro foi deletado quanto quando isso ocorreu. Suporta janelas de retenção práticas (por exemplo, purge após 30 dias) e responde a perguntas de auditoria (“quando isso foi removido?”) sem precisar de um log separado apenas para o momento da exclusão.
Campos únicos como email ou username podem impedir que a pessoa se registre novamente se a linha “deletada” ainda mantiver o valor único. Uma solução típica é aplicar unicidade apenas a linhas não deletadas, ou reescrever o valor no momento da exclusão (por exemplo, adicionando um sufixo aleatório). A escolha depende de necessidades de privacidade e auditoria.
Hard deletar um registro pai pode orfanejar filhos (como pedidos) ou disparar cascatas que apagam bem mais do que o pretendido. Soft delete geralmente evita referências quebradas porque as chaves permanecem válidas, mas ainda é preciso filtrar consistentemente para que pais deletados não apareçam em dropdowns ou junções voltadas ao usuário.
Se você hard delete linhas históricas, totais passados podem mudar, tendências ganham lacunas e números financeiros podem deixar de bater com o que era mostrado antes. Soft delete ajuda a preservar o histórico, mas só se relatórios e queries deixarem claro se incluem ou não linhas deletadas e aplicarem essa regra de forma consistente.
“Soft deleted” muitas vezes não é suficiente para pedidos de exclusão (right-to-erasure) porque os dados pessoais ainda existem no banco ou backups. Um padrão prático é bloquear o acesso imediatamente, depois hard delete ou anonimizar irreversivelmente os identificadores pessoais, mantendo apenas os dados não pessoais necessários para contabilidade ou disputas.
A restauração deve devolver o registro a um estado seguro e válido sem reviver itens sensíveis que devem permanecer apagados, como sessões ou tokens de reset. Também precisa de regras claras para dados relacionados, para não restaurar uma conta sem as permissões ou relacionamentos necessários.
Centralize comportamento de delete, restore e purge para que todas as APIs, telas, exports e jobs de background apliquem o mesmo filtro. No AppMaster, isso normalmente significa adicionar campos de soft-delete no Data Designer e implementar a lógica uma vez em um Business Process, evitando que novos endpoints exponham dados deletados por acidente.



Experimente o AppMaster com plano gratuito.
Quando estiver pronto, você poderá escolher a assinatura adequada.


