App de reserva de equipamentos: evite conflitos e acompanhe as devoluções
Planeje um app de reserva de equipamentos que evite reservas duplicadas, registre devoluções e danos e coloque itens com problemas em manutenção.
Aprenda a projetar um hub de integração para centralizar credenciais, monitorar status de sincronização e tratar erros de forma consistente à medida que sua pilha SaaS cresce.
Uma pilha de SaaS costuma começar simples: um CRM, uma ferramenta de cobrança, uma caixa de suporte. A equipe então adiciona automação de marketing, um data warehouse, um segundo canal de suporte e algumas ferramentas de nicho que "só precisam de uma sincronização rápida." Em pouco tempo você tem uma teia de conexões ponto-a-ponto que ninguém controla totalmente.
O que quebra primeiro geralmente não é os dados. É a cola ao redor deles.
Credenciais acabam espalhadas por contas pessoais, planilhas compartilhadas e variáveis de ambiente aleatórias. Tokens expiram, pessoas saem da empresa e, de repente, "a integração" depende de um login que ninguém encontra. Mesmo quando a segurança é bem tratada, rotacionar segredos vira um pesadelo porque cada conexão tem sua própria configuração e seu próprio lugar para atualizar.
A visibilidade entra em colapso em seguida. Cada integração relata status de forma diferente (ou não relata). Uma ferramenta diz "conectado" enquanto falha silenciosamente na sincronização. Outra envia e-mails vagos que são ignorados. Quando um vendedor pergunta por que um cliente não foi provisionado, a resposta vira uma busca entre logs, painéis e conversas no chat.
A carga de suporte aumenta rápido porque falhas são difíceis de diagnosticar e fáceis de repetir. Pequenos problemas como limites de taxa, mudanças de esquema e retries parciais viram incidentes longos quando ninguém consegue ver o caminho completo de "evento ocorreu" até "dados chegaram".
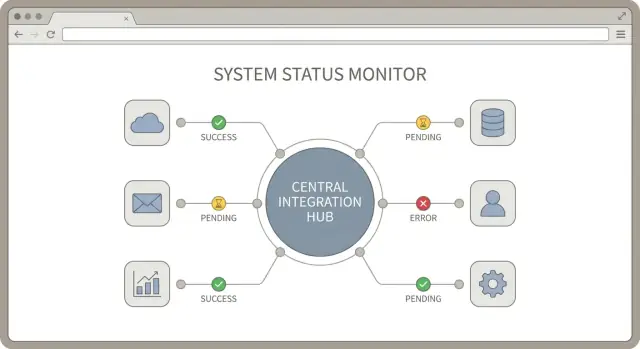
Um hub de integração é uma ideia simples: um lugar central onde suas conexões com serviços de terceiros são gerenciadas, monitoradas e suportadas. Um bom design de hub cria regras consistentes sobre como integrações se autenticam, como reportam status de sincronização e como erros são tratados.
Um hub prático busca quatro resultados: menos falhas (padrões compartilhados de retry e validação), correções mais rápidas (tracing fácil), acesso mais seguro (propriedade central de credenciais) e menos esforço de suporte (alertas e mensagens padronizadas).
Se você constrói sua stack em uma plataforma como AppMaster, o objetivo é o mesmo: manter as operações de integração simples o bastante para que um não-especialista entenda o que está acontecendo e um especialista possa corrigir rápido quando algo der errado.
Antes de tomar decisões grandes sobre integrações, tenha uma imagem clara do que você já conecta (ou planeja conectar). É a parte que as pessoas pulam e que costuma gerar surpresas depois.
Comece listando todo serviço de terceiros na sua pilha, até os "pequenos". Inclua quem o possui (pessoa ou time) e se está em produção, planejado ou experimental.
Em seguida, separe integrações visíveis ao cliente de automações de background. Uma integração voltada ao usuário pode ser "Conecte sua conta do Salesforce." Uma automação interna pode ser "Quando uma fatura for paga no Stripe, marque o cliente como ativo no banco de dados." Elas têm expectativas de confiabilidade diferentes e falham de formas distintas.
Depois, mapeie os fluxos de dados perguntando uma coisa: quem precisa desses dados para fazer seu trabalho? Produto pode precisar de eventos de uso para onboarding. Operações precisa de status de conta e provisionamento. Financeiro precisa de faturas, estornos e campos fiscais. Suporte precisa de tickets, histórico de conversas e correspondência de identidade de usuário. Essas necessidades moldam seu hub de integração mais do que APIs de fornecedores.
Finalmente, defina expectativas de tempo para cada fluxo:
Exemplo: "Fatura paga" pode precisar de quase em tempo real para controle de acesso, mas diário para resumos financeiros. Capture isso cedo e seu monitoramento e tratamento de erros ficam muito mais fáceis de padronizar.
Um bom design de hub começa com limites claros. Se o hub tentar fazer tudo, ele vira gargalo para todos os times. Se fizer pouco, você terá uma dúzia de scripts avulsos que se comportam diferente.
Anote o que o hub possui e o que não possui. Uma divisão prática é:
Escolha um ponto de entrada para todas as integrações e mantenha-o. Esse ponto pode ser uma API (outros sistemas chamam o hub) ou um executor de jobs (o hub roda pulls e pushes agendados). Usar ambos é aceitável, mas somente se eles compartilharem o mesmo pipeline interno para que retries, logs e alertas se comportem igual.
Algumas decisões mantêm o hub focado: padronize como integrações são disparadas (webhook, agendamento, rerun manual), concorde em um formato limite de payload (mesmo que parceiros difiram), decida o que persistir (eventos brutos, registros normalizados, ambos ou nenhum), defina o que significa "pronto" (aceito, entregue, confirmado) e atribua propriedade para peculiaridades específicas de parceiros.
Decida onde ocorrem transformações. Se você normaliza dados no hub, serviços downstream ficam mais simples, mas o hub precisa de versionamento e testes mais robustos. Se mantiver o hub fino e passar payloads brutos adiante, cada serviço downstream precisará entender cada formato de parceiro. Muitas equipes ficam no meio: normalize apenas campos compartilhados (IDs, timestamps, status básico) e deixe regras de domínio para baixo na pilha.
Planeje multi-tenant desde o primeiro dia. Decida se a unidade de isolamento é cliente, workspace ou organização. Essa escolha afeta limites de taxa, armazenamento de credenciais e backfills. Quando o token do Salesforce de um cliente expira, você deve pausar apenas os jobs desse tenant, não todo o pipeline. Ferramentas como AppMaster ajudam a modelar tenants e workflows visualmente, mas os limites ainda precisam estar explícitos antes de construir.
Um cofre de credenciais pode tanto trazer tranquilidade quanto se transformar em risco permanente. O objetivo é simples: um lugar para armazenar acessos sem dar a todo sistema e colega mais poder do que precisam.
OAuth e chaves de API aparecem em lugares diferentes. OAuth é comum em apps voltados ao usuário como Google, Slack, Microsoft e muitos CRMs. O usuário aprova o acesso e você armazena um access token mais um refresh token. Chaves de API são mais comuns para ferramentas servidor-a-servidor e APIs antigas. Elas podem ser de longa duração, o que torna armazenamento seguro e rotação ainda mais importantes.
Armazene tudo criptografado e escopo por tenant. Em um produto multi-cliente, trate credenciais como dados do cliente. Mantenha isolamento estrito para que um token do Tenant A nunca possa ser usado para o Tenant B, nem por engano. Também armazene metadados operacionais que você vai precisar depois, como a qual conexão pertence, quando expira e quais permissões foram concedidas.
Regras práticas que evitam a maioria dos problemas:
Planeje refresh e revogação sem quebrar a sincronização. Para OAuth, o refresh deve acontecer automaticamente em background, e seu hub deve tratar "token expirado" refrescando uma vez e tentando novamente com segurança. Para revogação (um usuário desconecta, a equipe de segurança desabilita um app ou escopos mudam), pare a sincronização, marque a conexão como precisa_de_autenticação e mantenha um rastro de auditoria claro do que aconteceu.
Se você constrói seu hub no AppMaster, trate credenciais como um modelo de dados protegido, mantenha acesso em lógica apenas no backend e exponha à UI apenas o status conectado/desconectado. Operadores podem corrigir uma conexão sem nunca ver o segredo.
Quando você conecta muitas ferramentas, "está funcionando?" vira uma pergunta diária. A solução não é mais logs. É um pequeno conjunto consistente de sinais de sincronização que seja igual para toda integração. Um bom design de hub trata status como feature de primeira classe.
Comece definindo uma lista curta de estados de conexão e use-a em todos os lugares: UI administrativa, alertas e notas de suporte. Use nomes simples para que um colega não técnico saiba o que fazer.
Acompanhe três timestamps por conexão: início do último sync, último sync bem-sucedido e hora do último erro. Eles contam uma história rápida sem precisar cavar.
Uma pequena visão por integração ajuda o suporte a agir rápido. Cada página de conexão deve mostrar o estado atual, esses timestamps e a última mensagem de erro em formato limpo e voltado ao usuário (sem stack traces). Adicione uma linha com ação recomendada, como "Reautenticação necessária" ou "Limite de taxa, tentando novamente."
Adicione alguns sinais de saúde que preveem problemas antes dos usuários notarem: tamanho do backlog, contagem de retries, hits de rate limit e última taxa de throughput bem-sucedida (aproximadamente quantos itens sincronizaram na última execução).
Exemplo: seu sync com o CRM está conectado, mas o backlog cresce e os hits de rate limit disparam. Ainda não é uma queda total, mas é um sinal claro para reduzir a frequência de sync ou agrupar requisições. Se você constrói o hub no AppMaster, esses campos de status se encaixam bem em um modelo do Data Designer e em um dashboard simples que seu time usa diariamente.
Uma sincronização confiável é mais sobre passos repetíveis do que lógica sofisticada. Comece com um modelo de execução claro, depois adicione complexidade só onde for necessário.
A maioria das equipes usa uma mistura, mas cada conector deve ter um gatilho principal para facilitar o raciocínio:
Se você está no AppMaster, isso normalmente mapeia para um endpoint de webhook, um processo background e uma tarefa agendada, todos alimentando o mesmo pipeline interno.
Fornecedores diferentes chamam a mesma coisa de formas distintas (customerId vs contact_id, strings de status, formatos de data). Converta cada payload recebido em um formato interno antes de aplicar regras de negócio. Isso mantém o resto do hub mais simples e torna mudanças em conectores menos dolorosas.
Retries são normais. Seu hub deve ser capaz de rodar a mesma ação duas vezes sem criar duplicatas. Uma abordagem comum é armazenar um ID externo e um "última versão processada" (timestamp, número de sequência ou ID de evento). Se você receber o mesmo item novamente, pule ou atualize com segurança.
APIs de terceiros podem ser lentas ou travar. Coloque tarefas normalizadas em uma fila durável e processe-as com timeouts explícitos. Se uma chamada demora demais, falhe, registre o motivo e tente novamente depois em vez de bloquear todo o resto.
Trate limites com backoff e throttling por conector. Faça backoff em respostas 429/5xx com uma agenda de retries limitada, defina limites de concorrência separados por conector (CRM não é igual a billing) e adicione jitter para evitar surtos de retries.
Exemplo: um "novo pagamento de fatura" chega do billing via webhook, é normalizado e enfileirado, então cria ou atualiza a conta correspondente no CRM. Se o CRM aplicar rate limit, esse conector desacelera sem atrasar syncs de tickets de suporte.
Um hub que "às vezes falha" é pior do que nenhum hub. A solução é uma forma compartilhada de descrever erros, decidir o que acontece em seguida e dizer a admins não técnicos o que fazer.
Comece com uma forma de erro padrão que todo conector retorna, mesmo que os payloads de terceiros variem. Isso mantém UI, alertas e playbooks de suporte consistentes.
RATE_LIMIT)Depois, classifique falhas em alguns grupos (mantenha pequeno): auth, validação, timeout, rate limit e outage.
Anexe regras claras de retry a cada grupo. Rate limits recebem retries com atraso e backoff. Timeouts podem tentar de novo rapidamente um pequeno número de vezes. Validação exige intervenção manual até que os dados sejam corrigidos. Auth pausa a integração e pede que um admin reconecte.
Guarde respostas brutas de terceiros, mas armazene-as com segurança. Reduza segredos (tokens, chaves de API, dados completos de cartão) antes de salvar. Se o conteúdo pode conceder acesso, não pertence a logs.
Escreva duas mensagens por erro: uma para admins e outra para engenheiros. Uma mensagem para admin pode ser: "Conexão com Salesforce expirada. Reconecte para retomar a sincronização." A visão de engenharia pode incluir a resposta sanitizada, request ID e a etapa que falhou. É aqui que um hub consistente compensa, seja implementando fluxos em código ou com uma ferramenta visual como o Business Process Editor do AppMaster.
Muitos projetos de integração falham por motivos triviais. O hub funciona na demo e depois desanda quando você adiciona mais tenants, mais tipos de dados e mais casos de borda.
Uma grande armadilha é misturar lógica de conexão com lógica de negócio. Quando "como falar com a API" está no mesmo caminho que "o que um registro de cliente significa", toda nova regra corre o risco de quebrar o conector. Mantenha adaptadores focados em auth, paginação, rate limits e mapeamento. Mantenha regras de negócio em uma camada separada que você possa testar sem bater em APIs de terceiros.
Outro problema comum é tratar estado de tenant como global. Em um produto B2B, cada tenant precisa de seus próprios tokens, cursores e checkpoints de sync. Se você armazenar "último sync" em um lugar compartilhado, um cliente pode sobrescrever outro e você terá updates faltando ou vazamentos de dados entre tenants.
Cinco armadilhas que reaparecem, com a correção simples:
Retries merecem atenção especial. Se uma chamada de create estoura por timeout, tentar novamente pode criar duplicatas a menos que você use chaves de idempotência ou uma estratégia forte de upsert. Se a API de terceiros não suporta idempotência, rastreie um ledger local de escritas para detectar e evitar gravações repetidas.
Não pule logs de auditoria. Quando o suporte pergunta por que um registro está faltando, você precisa responder em minutos, não chutar. Mesmo que construa seu hub com uma ferramenta visual como AppMaster, faça logs e estado por tenant prioridades.
Um bom hub de integração é chato no melhor sentido: conecta, reporta saúde claramente e falha de maneiras que sua equipe entende.
Comece verificando como cada integração autentica e o que você faz com essas credenciais. Peça o menor conjunto de permissões que permite rodar o job (apenas leitura quando possível). Armazene segredos em um cofre dedicado ou vault criptografado e rotacione sem mudanças de código. Garanta que logs e mensagens de erro nunca incluam tokens, chaves de API, refresh tokens ou headers brutos.
Depois que as credenciais estiverem seguras, confirme que cada conexão de cliente tem uma única fonte de verdade.
Clareza operacional é o que mantém integrações gerenciáveis quando você tem dezenas de clientes e muitos serviços de terceiros.
Acompanhe o estado de conexão por cliente (conectado, precisa_de_autenticação, pausado, com_falhas) e exponha isso na UI administrativa. Registre um timestamp de último sync bem-sucedido por objeto ou por job de sync, não apenas "rodamos algo ontem". Torne o último erro fácil de encontrar com contexto: qual cliente, qual integração, qual etapa, qual requisição externa e o que aconteceu em seguida.
Mantenha retries limitados (máx. tentativas e uma janela de corte) e projete escritas idempotentes para que reruns não criem duplicatas. Defina uma meta de suporte: alguém da equipe deve localizar a última falha e seus detalhes em menos de dois minutos sem ler código.
Se você está construindo UI e rastreamento de status rapidamente, uma plataforma como AppMaster pode ajudar a entregar um dashboard interno e lógica de workflow rápido, gerando código pronto para produção.
Imagine um produto SaaS que precisa de três integrações comuns: Stripe para eventos de cobrança, HubSpot para repasses de vendas e Zendesk para tickets de suporte. Em vez de ligar cada ferramenta diretamente ao app, roteie tudo por um hub de integração.
O onboarding começa no painel admin. Um admin clica em "Conectar Stripe", "Conectar HubSpot" e "Conectar Zendesk". Cada conector armazena credenciais no hub, não em scripts aleatórios ou laptops de funcionários. Então o hub executa uma importação inicial:
Após a importação, o primeiro sync dá início. O hub grava um registro de sync para cada conector para que todos vejam a mesma história. Uma visão administrativa simples responde a maioria das perguntas: estado da conexão, último sync bem-sucedido, job atual (importando, sincronizando, ocioso), resumo de erro e código, e próxima execução agendada.
Agora é uma hora movimentada e o Stripe aplica rate limits nas suas chamadas. Em vez de falhar todo o sistema, o conector do Stripe marca o job como tentando novamente, salva progresso parcial (por exemplo, "invoices até 10:40") e dá backoff. HubSpot e Zendesk continuam sincronizando.
O suporte recebe um ticket: "Cobrança parece desatualizada." Eles abrem o hub e veem Stripe em com_falhas por um erro de rate limit. A resolução é procedural:
Se você constrói sobre AppMaster, esse fluxo mapeia claramente para lógica visual (estados de job, retries, telas admin) enquanto ainda gera código de backend real para produção.
Um bom design de hub é menos sobre construir tudo de uma vez e mais sobre tornar cada nova conexão previsível. Comece com um pequeno conjunto de regras compartilhadas que todo conector deve seguir, mesmo que a primeira versão pareça "simples demais."
Comece pela consistência: estados padrão para jobs de sync (pending, running, succeeded, failed), um conjunto curto de categorias de erro (auth, rate limit, validação, outage upstream, desconhecido) e logs de auditoria que respondam quem fez o quê, quando e por qual motivo. Se você não confia em status e logs, dashboards e alertas só vão gerar ruído.
Adicione conectores um por um usando os mesmos templates e convenções. Cada conector deve reutilizar o mesmo fluxo de credenciais, as mesmas regras de retry e a mesma forma de escrever atualizações de status. Essa repetição é o que mantém o hub suportável quando você tem dez integrações em vez de três.
Um plano de rollout prático:
Introduza dashboards e alertas apenas depois que os dados de status estiverem corretos. Comece com uma tela que mostre último sync, último resultado, próxima execução e a mensagem de erro mais recente com categoria.
Se preferir uma abordagem no-code, você pode modelar os dados, construir a lógica de sync e expor telas de status no AppMaster, então deployar na sua nuvem ou exportar o código-fonte. Mantenha a primeira versão chata e observável, depois melhore performance e casos de borda quando as operações estiverem estáveis.
Comece por um inventário simples: liste todas as ferramentas de terceiros, quem as gerencia e se estão em produção ou planejadas. Em seguida, documente quais dados circulam entre sistemas e por que são importantes para cada time (suporte, financeiro, operações). Esse mapa indicará o que precisa ser em tempo real, o que pode rodar diariamente e o que exige monitoramento mais rígido.
O hub deve gerenciar a infraestrutura compartilhada: configuração de conexão, armazenamento de credenciais, agendamento/gatilhos, relatório consistente de status e tratamento padronizado de erros. Decisões de negócio (quem deve ser cobrado, o que é um lead qualificado etc.) devem permanecer fora do hub. Essa separação evita que você precise alterar código de conectores sempre que regras de produto mudarem.
Escolha um ponto de entrada primário por conector para facilitar o raciocínio sobre falhas. Webhooks são ideais para atualizações quase em tempo real, pulls agendados servem quando o provedor não envia eventos, e workflows por job funcionam bem quando é necessário executar passos em sequência. Independente do gatilho, mantenha retries, logs e atualizações de status uniformes entre todos eles.
Trate credenciais como dados do cliente: armazene tudo criptografado com forte isolamento por tenant. Não exponha tokens em logs, telas ou capturas de suporte, e não reutilize segredos de produção em staging. Guarde metadados operacionais úteis (expiração, escopos, a qual tenant/conexão pertence) para permitir rotações e auditoria segura.
OAuth é ideal quando clientes conectam suas próprias contas e você precisa de acesso revogável e com escopos. Chaves de API são práticas para integrações server-to-server, mas geralmente são de longa duração, então exigem rotação e controle de acesso mais rígidos. Quando possível, prefira OAuth para conexões voltadas ao usuário.
Separe o estado do tenant em tudo: tokens, cursores, checkpoints de sync, contadores de retry e progresso de backfill. Uma falha de um cliente deve pausar apenas os jobs desse cliente, não todo o conector. Esse isolamento evita vazamentos entre clientes e facilita a contenção de problemas.
Mostre um pequeno conjunto de estados claros para cada conector, por exemplo: conectado, precisa de autenticação, pausado e com falhas. Armazene três timestamps por conexão: início do último sync, último sync bem-sucedido e hora do último erro. Com esses sinais, a maioria das perguntas “está funcionando?” pode ser respondida sem vasculhar logs.
Torne cada escrita idempotente para que retries não criem duplicatas. Normalmente isso envolve armazenar um ID externo e um marcador de “última versão processada” (timestamp, número de sequência ou ID de evento) e usar upserts em vez de creates cegos. Se o provedor não suporta idempotência, mantenha um ledger local de escritas para detectar tentativas repetidas antes de gravar novamente.
Trate limites de taxa de forma deliberada: aplique throttling por conector, faça backoff em respostas 429 e erros transitórios, e adicione jitter para evitar picos de retries simultâneos. Use uma fila durável com timeouts para que chamadas lentas não bloqueiem outras integrações. A ideia é desacelerar um conector sem paralisar todo o hub.
Em uma abordagem no-code como AppMaster, modele conexões, tenants e campos de status no Data Designer e implemente fluxos de sync no Business Process Editor. Mantenha credenciais em lógica apenas no backend e exponha à UI apenas status seguros e ações recomendadas. Assim você entrega rapidamente um painel interno operacional sem perder capacidade de exportar código para produção.



Experimente o AppMaster com plano gratuito.
Quando estiver pronto, você poderá escolher a assinatura adequada.


