App de reserva de equipamentos: evite conflitos e acompanhe as devoluções
Planeje um app de reserva de equipamentos que evite reservas duplicadas, registre devoluções e danos e coloque itens com problemas em manutenção.
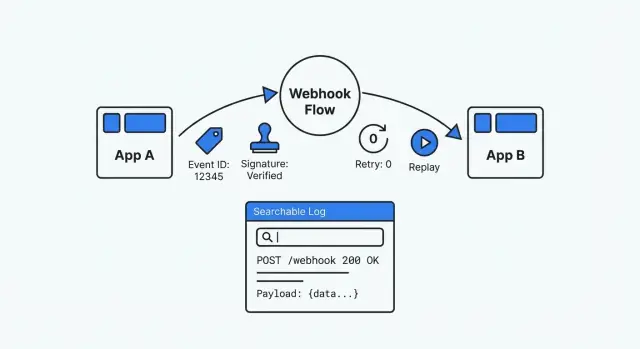
Aprenda a depurar integrações webhook padronizando assinaturas, tratando retentativas com segurança, habilitando replay e mantendo logs de eventos fáceis de pesquisar.
Um webhook é apenas um aplicativo chamando o seu quando algo acontece. Um provedor de pagamentos diz “payment succeeded”, uma ferramenta de formulários informa “new submission” ou um CRM reporta “deal updated”. Parece simples até algo falhar e você perceber que não há nenhuma tela para abrir, nenhum histórico óbvio e nenhuma maneira segura de reenviar o que aconteceu.
Por isso problemas de webhook são tão frustrantes. A requisição chega (ou não). Seu sistema a processa (ou falha). O primeiro sinal costuma ser um tíquete vago como “clientes não conseguem finalizar compra” ou “o status não atualizou”. Se o provedor tentar novamente, você pode receber duplicatas. Se mudarem um campo do payload, seu parser pode quebrar apenas para algumas contas.
Sintomas comuns:
Uma configuração de webhook depurável é o oposto de adivinhação. É rastreável (você encontra cada entrega e o que foi feito com ela), repetível (você pode reenviar um evento antigo com segurança) e verificável (você pode provar autenticidade e resultados do processamento). Quando alguém perguntar “o que aconteceu com este evento?”, você deve ser capaz de responder com evidências em minutos.
Se você constrói apps em uma plataforma como AppMaster, essa mentalidade importa ainda mais. Lógica visual muda rápido, mas você ainda precisa de um histórico claro de eventos e replay seguro para que sistemas externos nunca virem uma caixa preta.
Quando você está depurando sob pressão, precisa das mesmas informações básicas sempre: um registro em que se pode confiar, pesquisar e reenviar. Sem isso, cada webhook vira um mistério isolado.
Decida o que um único “evento” de webhook significa no seu sistema. Trate‑o como um comprovante: uma requisição recebida = um evento armazenado, mesmo que o processamento ocorra depois.
No mínimo, armazene:
received_at separado dos timestamps dentro do payload.Exemplo: um provedor de pagamentos envia “payment_succeeded” mas o cliente ainda aparece como não pago. Se seu log de eventos inclui a requisição bruta, você pode confirmar a assinatura e ver o valor e a moeda exatos. Se também contém invoice_id, o suporte encontra o evento a partir da fatura, vê que está preso em “failed” e entrega ao time de engenharia uma razão de erro clara.
No AppMaster, uma abordagem prática é ter uma tabela “WebhookEvent” no Data Designer, com um Business Process atualizando o status conforme cada etapa completa. A ferramenta não é o ponto — o registro consistente é.
Se cada provedor envia um formato diferente, seus logs sempre vão parecer bagunçados. Um envelope estável de evento torna a depuração mais rápida porque você pode procurar sempre pelos mesmos campos, mesmo quando os dados mudam.
Um envelope útil normalmente inclui:
id (id único do evento)type (nome claro do evento como invoice.paid)created_at (quando o evento ocorreu, não quando você o recebeu)data (o payload de negócio)version (por exemplo v1)Aqui está um exemplo simples que você pode registrar e armazenar como‑está:
{
"id": "evt_01H...",
"type": "payment.failed",
"created_at": "2026-01-25T10:12:30Z",
"version": "v1",
"correlation": {"order_id": "A-10492", "customer_id": "C-883"},
"data": {"amount": 4990, "currency": "USD", "reason": "insufficient_funds"}
}
Escolha um estilo de nomenclatura (snake_case ou camelCase) e mantenha‑o. Seja rígido com tipos também: não deixe amount ser string às vezes e número em outras.
Versionamento é sua rede de segurança. Quando precisar mudar campos, publique v2 enquanto mantém v1 funcionando por um tempo. Isso evita incidentes de suporte e facilita depurar upgrades.
Assinaturas impedem que seu endpoint de webhook vire uma porta aberta. Sem verificação, qualquer um que descubra sua URL pode enviar eventos falsos, e atacantes podem tentar adulterar requisições reais.
O padrão mais comum é uma assinatura HMAC com um segredo compartilhado. O remetente assina o corpo bruto da requisição (melhor) ou uma string canônica. Você recalcula o HMAC e compara. Muitos provedores incluem um timestamp no que assinam para que requisições capturadas não possam ser reenviadas depois.
Uma rotina de verificação deve ser monótona e consistente:
Torne isso testável. Coloque a verificação em uma função pequena e escreva testes com amostras conhecidas boas e ruins. Um erro comum é assinar o JSON parseado em vez dos bytes brutos.
Planeje rotação de segredo desde o primeiro dia. Suporte dois segredos ativos durante transições: tente o mais novo primeiro e, em seguida, o anterior.
Quando a verificação falhar, registre informações suficientes para depurar sem vazar segredos: nome do provedor, timestamp (e se estava muito antigo), versão da assinatura, request/correlation ID e um hash curto do body cru (não o body em si).
Retentativas são normais. Provedores tentam novamente em timeouts, problemas de rede ou respostas 5xx. Mesmo que seu sistema tenha realizado o trabalho, o provedor pode não ter recebido sua resposta a tempo, então o mesmo evento pode aparecer de novo.
Decida desde o início o que significa “tentar de novo” vs “parar”. Muitas equipes usam regras como:
Idempotência significa que você pode tratar o mesmo evento mais de uma vez sem repetir efeitos colaterais (cobrar duas vezes, criar pedidos duplicados, enviar dois e‑mails). Trate webhooks como entrega at‑least‑once.
Um padrão prático é armazenar o ID único de cada evento recebido com o resultado do processamento. Em uma entrega repetida:
Para retentativas internas, use backoff exponencial e limite de tentativas. Depois do limite, mova o evento para um estado “needs review” com o último erro. No AppMaster, isso mapeia bem para uma pequena tabela de event IDs e statuses, mais um Business Process que agenda retentativas e roteia falhas repetidas.
Retentativas são automáticas. Replay é intencional.
Uma ferramenta de replay transforma “achamos que foi enviado” em um teste repetível com o mesmo payload exato. Também só é segura quando duas coisas são verdadeiras: idempotência e trilha de auditoria. Idempotência evita cobranças duplas, envios duplos ou envios de mercadorias duplicadas. A trilha de auditoria mostra o que foi reenviado, por quem e o que aconteceu.
Single‑event replay vs replay por intervalo de tempo
Single‑event replay é o caso comum de suporte: um cliente, um evento falho, reenviar depois de consertar. Replay por intervalo é para incidentes: uma queda do provedor numa janela específica e você precisa reenviar tudo o que falhou.
Mantenha a seleção simples: filtre por tipo de evento, intervalo de tempo e status (failed, timed out ou delivered mas não reconhecido), então reenviar um evento ou um lote.
Salvaguardas que previnem acidentes
Replay deve ser poderoso, mas não perigoso. Algumas salvaguardas ajudam:
Após o replay, mostre os resultados ao lado do evento original: sucesso, ainda falhando (com o erro mais recente) ou ignorado (duplicata detectada via idempotência).
Quando um webhook falha durante um incidente, você precisa de respostas em minutos. Um bom log conta uma história clara: o que chegou, o que você fez com isso e onde parou.
Armazene a requisição bruta exatamente como recebida: timestamp, path, method, headers e body cru. Esse payload bruto é sua verdade fundamental quando provedores mudam campos ou seu parser interpreta errado. Mas masque valores sensíveis antes de salvar (authorization headers, tokens e quaisquer dados pessoais ou de pagamento que você não precise).
Dados brutos sozinhos não bastam. Armazene também uma visão parseada e pesquisável: tipo do evento, ID externo do evento, identificadores de cliente/conta, IDs de objetos relacionados (invoice_id, order_id) e seu ID de correlação interno. Isso permite que o suporte encontre “todos os eventos do cliente 8142” sem abrir cada payload.
Durante o processamento, mantenha uma linha do tempo curta de passos com uma redação consistente, por exemplo: “validated signature”, “mapped fields”, “checked idempotency”, “updated records”, “queued follow-ups”.
Retenção importa. Guarde histórico suficiente para cobrir atrasos reais e disputas, mas não acumule indefinidamente. Considere deletar ou anonimizar payloads brutos primeiro enquanto mantém metadados leves por mais tempo.
Construa o receptor como uma pequena pipeline com checkpoints claros. Cada requisição vira um evento armazenado, cada execução de processamento vira uma tentativa e cada falha vira algo pesquisável.
Receiver pipeline
Trate o endpoint HTTP como intake apenas. Faça o mínimo possível no front, depois mova o processamento para um worker para que timeouts não gerem comportamentos misteriosos.
Na prática, você vai querer dois registros principais: uma linha por evento de webhook e uma linha por tentativa de processamento.
Um modelo sólido de evento inclui: event_id, provider, received_at, signature_status, payload_hash, payload_json (ou payload bruto), current_status, last_error, next_retry_at. Registros de tentativa podem armazenar: attempt_number, started_at, finished_at, http_status (se aplicável), error_code, error_text.
Uma vez que os dados existam, adicione uma pequena página administrativa para que o suporte pesquise por event ID, customer ID ou intervalo de tempo e filtre por status. Mantenha simples e rápida.
Coloque alertas em padrões, não em falhas isoladas. Por exemplo: “provedor falhou 10 vezes em 5 minutos” ou “evento preso em failed”.
Expectativas do remetente
Se você controla o lado que envia, padronize três coisas: sempre inclua um event ID, sempre assine o payload da mesma forma e publique uma política de retentativa em linguagem simples. Isso evita ida e volta quando um parceiro diz “enviamos” e seu sistema não mostra nada.
Um padrão comum é um webhook da Stripe que faz duas coisas: cria um registro Order e depois envia um recibo por email/SMS. Parece simples até um evento falhar e ninguém saber se o cliente foi cobrado, se o pedido existe ou se o recibo foi enviado.
Aqui está uma falha realista: você rotaciona seu segredo de assinatura Stripe. Por alguns minutos, seu endpoint ainda verifica com o segredo antigo, então Stripe entrega eventos mas seu servidor os rejeita com 401/400. O dashboard mostra “webhook failed”, enquanto os logs do app dizem apenas “invalid signature”.
Bons logs tornam a causa óbvia. Para o evento falho, o registro deve mostrar um event ID estável mais detalhe suficiente de verificação para localizar a incompatibilidade: versão da assinatura, timestamp da assinatura, resultado da verificação e uma razão clara de rejeição (segredo errado vs drift de timestamp). Durante a rotação, também ajuda registrar qual segredo foi tentado (por exemplo “current” vs “previous”), não o segredo bruto.
Uma vez corrigido o segredo e aceitos tanto “current” quanto “previous” por uma janela curta, você ainda precisa lidar com o backlog. Uma ferramenta de replay transforma isso em uma tarefa rápida:
A maioria dos problemas com webhooks parece misteriosa porque sistemas só registram o erro final. Trate cada entrega como um pequeno relatório de incidente: o que chegou, o que você decidiu e o que aconteceu depois.
Alguns erros que aparecem repetidamente:
Correções práticas:
Se você usa AppMaster, essas peças se encaixam naturalmente na plataforma: uma tabela de eventos no Data Designer, um Business Process orientado por status para verificação e processamento, e uma UI administrativa para busca e replay.
Almeje as mesmas coisas básicas sempre:
Faltar apenas um desses itens ainda pode transformar uma integração em caixa preta. Se você não armazena o payload bruto, não pode provar o que o provedor enviou. Se falhas de assinatura não são específicas, você perde horas discutindo de quem é a culpa.
Se quiser construir isso rapidamente sem codificar cada componente manualmente, AppMaster (appmaster.io) pode ajudar a montar o modelo de dados, fluxos de processamento e UI administrativa em um só lugar, gerando ainda código fonte real para o app final.



Experimente o AppMaster com plano gratuito.
Quando estiver pronto, você poderá escolher a assinatura adequada.


