App de reserva de equipamentos: evite conflitos e acompanhe as devoluções
Planeje um app de reserva de equipamentos que evite reservas duplicadas, registre devoluções e danos e coloque itens com problemas em manutenção.
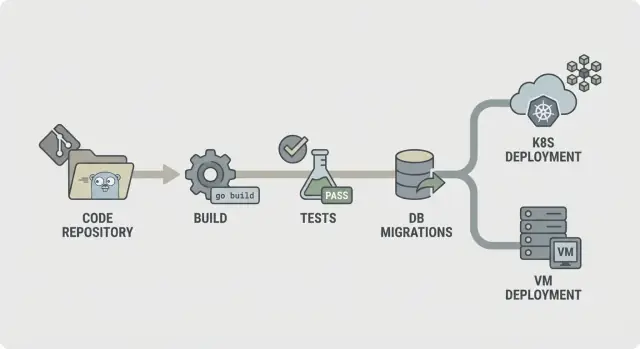
CI/CD para backends Go: passos práticos de pipeline para builds, testes, migrações e deploys seguros em Kubernetes ou VMs com ambientes previsíveis.
go test ./... com timeout por pacote e timeout global do job.\n- Trate qualquer teste que atinja timeout como bug real a ser corrigido, não como “CI instável”.\n- Defina expectativas de cobertura para pacotes críticos (auth, billing, permissions), não necessariamente para todo o repositório.\n- Adicione o race detector para código que lida com concorrência (filas, caches, workers).\n\nO race detector é valioso, mas pode deixar builds bem mais lentos. Um bom compromisso é rodá-lo em pull requests e builds noturnos, ou apenas em pacotes selecionados, em vez de em todo push.\n\nTestes flaky devem falhar o build. Se precisar isolar um teste, mantenha-o visível: mova para um job separado que ainda rode e reporte vermelho, exigindo um dono e prazo para correção.\n\nArmazene a saída dos testes para que depurar não exija rerodar tudo. Salve logs brutos mais um relatório simples (pass/fail, duração e testes mais lentos). Isso facilita identificar regressões, especialmente quando mudanças regeneradas tocam muitos arquivos.\n\n## Cheques de integração com dependências reais, sem builds lentos\n\nTestes unitários dizem que seu código funciona isoladamente. Cheques de integração dizem que o serviço inteiro ainda se comporta quando sobe, conecta a serviços reais e atende requisições. Essa é a rede de segurança que pega problemas só visíveis quando tudo está ligado.\n\nUse dependências efêmeras quando seu código precisar delas para iniciar ou responder requisições chave. Um PostgreSQL temporário (e Redis, se usado) rodando só para o job costuma ser suficiente. Mantenha versões próximas da produção, mas não tente copiar todos os detalhes de produção.\n\nUma boa etapa de integração é propositalmente pequena:\n\n- Inicie o serviço com vars de ambiente parecidas com produção (mas segredos de teste)\n- Verifique um health check (por exemplo, /health retorna 200)\n- Chame um ou dois endpoints críticos e verifique códigos de status e formato da resposta\n- Confirme que consegue alcançar o PostgreSQL (e o Redis, se necessário)\n\nPara cheques de contrato de API, foque nos endpoints que mais causariam dano se quebrassem. Você não precisa de uma suíte end-to-end completa. Algumas verdades de requisição/resposta bastam: campos obrigatórios rejeitados com 400, autenticação exigida retorna 401, e um caminho feliz retorna 200 com as chaves JSON esperadas.\n\nPara manter integrações rápidas o suficiente para rodar com frequência, limite o escopo e controle o tempo. Prefira um banco com dataset minúsculo. Execute só algumas requisições. Defina timeouts rígidos para que um boot travado falhe em segundos, não minutos.\n\nSe você regenera seu backend (por exemplo com AppMaster), esses cheques têm peso extra. Eles confirmam que o serviço regenerado ainda sobe limpo e fala a API que seu app web ou mobile espera.\n\n## Migrações de banco: ordenação segura, gates e a realidade do rollback\n\nComece escolhendo onde as migrações rodam. Rodá-las no CI é bom para pegar erros cedo, mas CI geralmente não deve tocar produção. A maioria das equipes roda migrações durante o deploy (como uma etapa dedicada) ou como um job de “migrate” separado que deve terminar antes da nova versão iniciar.\n\nUma regra prática: construa e teste no CI, depois rode migrações o mais próximo possível da produção, com credenciais e limites parecidos com os de produção. No Kubernetes, isso costuma ser um Job one-off. Em VMs, pode ser um comando scriptado na etapa de release.\n\nA ordem importa mais do que se espera. Use arquivos com timestamp (ou números sequenciais) e imponha “aplicar em ordem, exatamente uma vez”. Faça migrações idempotentes quando possível, para que uma tentativa de retry não crie duplicados ou trave no meio.\n\nMantenha a estratégia de migração simples:\n\n- Prefira mudanças aditivas primeiro (novas tabelas/colunas, colunas nullable, novos índices).\n- Faça deploy do código que consegue lidar tanto com o esquema antigo quanto com o novo por uma release.\n- Só então remova ou aperte constraints (dropar colunas, tornar colunas NOT NULL).\n- Torne operações longas seguras (por exemplo, crie índices concurrentemente quando suportado).\n\nAdicione um gate de segurança antes de qualquer execução. Pode ser um lock no banco para que só uma migração rode por vez, mais uma política como “sem mudanças destrutivas sem aprovação”. Por exemplo, falhe o pipeline se uma migração contiver DROP TABLE ou DROP COLUMN a menos que um gate manual seja aprovado.\n\nRollback é a verdade dura: muitas mudanças no esquema não são reversíveis. Se você droppa uma coluna, os dados não voltam. Planeje rollbacks pensando em correções pra frente: mantenha um down migration somente quando for realmente seguro, e confie em backups mais uma migração corretiva quando não for.\n\nAcompanhe cada migração com um plano de recuperação: o que fazer se falhar no meio, e o que fazer se a aplicação precisar reverter. Se você gera backends Go (por exemplo, com AppMaster), trate migrações como parte do contrato de release para que código regenerado e esquema permaneçam sincronizados.\n\n## Empacotamento e configuração: artefatos em que se pode confiar\n\nUm pipeline só parece previsível quando o que você deploya é sempre o que testou. Isso depende de empacotamento e configuração. Trate o output do build como um artefato selado e mantenha todas as diferenças de ambiente fora dele.\n\nEmpacotamento normalmente segue dois caminhos. Imagem de container é o padrão se você faz deploy em Kubernetes, porque prende a camada do SO e torna rollouts consistentes. Um bundle para VM pode ser igualmente confiável quando necessário, desde que inclua o binário compilado mais o pequeno conjunto de arquivos necessários em runtime (por exemplo: CA certs, templates ou assets estáticos), e você faça o deploy do mesmo jeito cada vez.\n\nConfiguração deve ser externa, não embutida no binário. Use variáveis de ambiente para a maioria das configurações (portas, host do DB, feature flags). Use arquivo de configuração apenas quando valores forem longos ou estruturados, e mantenha-o específico por ambiente. Se usar um serviço de configuração, trate-o como uma dependência: permissões travadas, logs de auditoria e plano de fallback claro.\n\nSegredos são a linha que você não cruza. Não vão no repo, na imagem ou nos logs do CI. Evite imprimir connection strings no startup. Guarde segredos no cofre do CI e injete-os no deploy.\n\nPara tornar artefatos rastreáveis, embuta identidade em cada build: tagueie artefatos com versão + commit hash, inclua metadados do build (versão, commit, hora do build) em um endpoint de info e registre a tag do artefato no log de deploy. Facilite responder “o que está rodando” com um comando ou dashboard.\n\nSe você gera backends Go (por exemplo com AppMaster), essa disciplina importa ainda mais: regeneração é segura quando suas regras de nomeação de artefatos e configuração tornam cada release fácil de reproduzir.\n\n## Deploy para Kubernetes ou VMs sem surpresas\n\nA maioria das falhas de deploy não é “código ruim”. São ambientes desencontrados: configuração diferente, segredos faltando ou um serviço que inicia mas não está pronto. O objetivo é simples: deployar o mesmo artefato em todo lugar e mudar apenas a configuração.\n\n### Kubernetes: trate deploys como rollouts controlados\n\nNo Kubernetes, mire em rollout controlado. Use rolling updates para substituir pods gradualmente e adicione readiness e liveness checks para que a plataforma saiba quando enviar tráfego e quando reiniciar um container travado. Requests e limits importam também, porque um serviço Go que funciona num runner grande pode ser OOM-killed num nó pequeno.\n\nMantenha config e segredos fora da imagem. Construa uma imagem por commit e injete configurações específicas do ambiente no deploy (ConfigMaps, Secrets ou seu secret manager). Assim, staging e produção rodam os mesmos bits.\n\n### VMs: systemd dá o que você precisa na maioria dos casos\n\nSe você faz deploy em máquinas virtuais, o systemd pode ser seu “mini-orquestrador”. Crie um unit file com diretório de trabalho claro, arquivo de ambiente e política de restart. Torne logs previsíveis enviando stdout/stderr para seu coletor de logs ou journald, para que incidentes não virem caçadas por SSH.\n\nVocê ainda pode fazer rollouts seguros sem cluster. Um setup simples blue/green funciona: mantenha dois diretórios (ou duas VMs), troque o load balancer e mantenha a versão anterior pronta para rollback rápido. Canary é similar: envie uma pequena fatia de tráfego para a nova versão antes de confirmar.\n\nAntes de marcar um deploy como “feito”, rode o mesmo smoke check pós-deploy em todo lugar:\n\n- Confirme que o endpoint de health retorna OK e que dependências são alcançáveis\n- Execute uma pequena ação real (por exemplo, criar e ler um registro de teste)\n- Verifique que a versão/build ID do serviço bate com o commit\n- Se o cheque falhar, reverta e alerte\n\nSe você regenera backends (por exemplo, um backend Go do AppMaster), essa abordagem se mantém estável: construa uma vez, deploy o artefato e deixe a configuração de ambiente guiar diferenças, não scripts ad-hoc.\n\n## Erros comuns que tornam pipelines não confiáveis\n\nA maioria dos releases quebrados não vem de “código ruim”. Acontecem quando o pipeline se comporta de forma diferente a cada execução. Se você quer CI/CD para backends Go calmo e previsível, cuidado com esses padrões.\n\n### Padrões de erro que causam surpresas\n\nRodar migrações automaticamente em cada deploy sem guardrails é clássico. Uma migração que tranca uma tabela pode derrubar um serviço movimentado. Coloque migrações atrás de uma etapa explícita, exija aprovação para produção e assegure que dá para rerodar com segurança.\n\nUsar tags latest ou imagens base sem pinagem é outra forma fácil de criar falhas misteriosas. Prenda imagens Docker e versões do Go para que seu ambiente de build não drifte.\n\nCompartilhar um banco entre ambientes “temporariamente” tende a virar permanente, e é assim que dados de teste vazam para staging e scripts de staging atingem produção. Separe bancos (e credenciais) por ambiente, mesmo que o esquema seja o mesmo.\n\nCheques de health e readiness faltando permitem que um deploy “suceda” enquanto o serviço está quebrado, e o tráfego é roteado cedo demais. Adicione cheques que reflitam comportamento real: o app inicia, conecta ao banco e serve uma requisição.\n\nPor fim, propriedade obscura de segredos, configuração e acesso transforma releases em adivinhação. Alguém precisa ser dono de como segredos são criados, rotacionados e injetados.\n\nUm fracasso realístico: um time faz merge, o pipeline deploya e uma migração automática roda primeiro. Ela completa em staging (poucos dados), mas dá timeout em produção (dados grandes). Com imagens pinadas, separação de ambientes e um passo de migração gateado, o deploy teria parado com segurança.\n\nSe você gera backends Go (por exemplo, com AppMaster), essas regras importam ainda mais porque a regeneração pode tocar muitos arquivos ao mesmo tempo. Entradas previsíveis e gates explícitos evitam que mudanças grandes virem releases arriscados.\n\n## Checklist rápido para um CI/CD previsível\n\nUse isto como checagem intuitiva para CI/CD de backends Go. Se você consegue responder cada ponto com um “sim” claro, os releases ficam mais fáceis.\n\n- Trave o ambiente, não só o código. Prenda a versão do Go e a imagem do container de build, e use a mesma configuração local e no CI.\n- Faça o pipeline rodar com 3 comandos simples. Um comando builda, outro roda testes, outro produz o artefato deployável.\n- Trate migrações como código de produção. Exija logs para cada execução de migração e documente o que “rollback” significa para sua app.\n- Produza artefatos imutáveis e rastreáveis. Construa uma vez, tagueie com o commit SHA e promova entre ambientes sem rebuild.\n- Faça deploys com cheques que falhem rápido. Adicione readiness/liveness e um pequeno smoke test que rode em cada deploy.\n\nLimite e audite acesso a produção. O CI deve deployar usando uma service account dedicada, segredos devem ser gerenciados centralmente e qualquer ação manual em produção deve deixar rastro claro (quem, o quê, quando).\n\n## Exemplo realista e próximos passos que você pode começar esta semana\n\nUm pequeno time de ops de quatro pessoas envia releases uma vez por semana. Eles frequentemente regeneram o backend Go porque o time de produto refina fluxos. O objetivo é simples: menos consertos à noite e releases que não pegam ninguém de surpresa.\n\nUma mudança típica de sexta: adicionam um novo campo em customers (mudança de esquema) e atualizam a API que grava esse campo (mudança de código). O pipeline trata isso como um único release. Ele builda um artefato, roda testes contra esse exato artefato e só então aplica migrações e faz o deploy. Assim, o banco nunca fica à frente do código que espera o esquema, e o código não é deployado sem seu esquema correspondente.\n\nQuando há mudança de esquema, o pipeline adiciona um gate de segurança. Verifica que a migração é aditiva (como adicionar coluna nullable) e sinaliza ações arriscadas (dropar coluna ou reescrever tabela grande). Se a migração for arriscada, o release para antes da produção. O time reescreve a migração para ficar mais segura ou agenda uma janela planejada.\n\nSe os testes falham, nada segue adiante. O mesmo vale se migrações falham em ambiente pré-produção. O pipeline não deve tentar “empurrar isso só dessa vez”.\n\nUm conjunto simples de próximos passos que funciona para a maioria dos times:\n\n- Comece com um ambiente (um deploy dev que você pode resetar com segurança).\n- Faça o pipeline sempre produzir um artefato versionado.\n- Rode migrações automaticamente em dev, mas exija aprovação em produção.\n- Adicione staging só depois que dev estiver estável por algumas semanas.\n- Adicione um gate de produção que exija testes verdes e um deploy bem-sucedido em staging.\n\nSe você gera backends com AppMaster, mantenha a regeneração nas mesmas etapas do pipeline: regenere, build, teste, migre em um ambiente seguro e então deploy. Trate o código gerado como qualquer outro source. Todo release deve ser reproduzível a partir de uma versão tagueada, com os mesmos passos sempre.Prenda sua versão do Go e do ambiente de build para que as mesmas entradas sempre produzam o mesmo binário ou imagem. Isso elimina diferenças do tipo “funciona na minha máquina” e facilita reproduzir e corrigir falhas.
Porque a regeneração pode alterar endpoints, modelos de dados e dependências mesmo que ninguém tenha editado o código manualmente. Um pipeline faz essas mudanças passarem pelos mesmos cheques sempre, então regenerar fica seguro em vez de arriscado.
Compile uma vez e promova esse mesmo artefato por dev, staging e produção. Se você recompilar por ambiente, pode acabar enviando algo que nunca foi testado, mesmo partindo do mesmo commit.
Execute gates rápidos em cada pull request: formatação, checagens estáticas básicas, build e testes unitários com timeout. Mantenha isso rápido para que as pessoas não ignorem, e rigoroso o suficiente para que mudanças quebradas parem cedo.
Use uma pequena etapa de integração que sobe o serviço com configuração parecida com a produção e fala com dependências reais como PostgreSQL. O objetivo é pegar “compila mas não inicia” e quebras de contrato óbvias, sem transformar o CI numa suíte end-to-end de horas.
Trate migrações como uma etapa controlada de release, não algo que roda implicitamente a cada deploy. Execute-as com logs claros e bloqueio de execução única, e seja honesto sobre rollback: muitas mudanças no esquema exigem correções pra frente ou backups, não um undo simples.
Use readiness checks para que o tráfego só chegue aos novos pods quando o serviço realmente estiver pronto, e liveness checks para reiniciar containers travados. Também configure requests e limits realistas para evitar OOMs em produção.
Um unit file do systemd bem escrito mais um script de release consistente costuma dar conta dos deploys em VMs sem orquestrador. Mantenha o mesmo modelo de artefato que usaria com containers quando possível e adicione um pequeno smoke check pós-deploy para garantir que um “restart bem-sucedido” não esconda um serviço quebrado.
Nunca coloque segredos no repo, no artefato de build ou nos logs. Injete segredos no momento do deploy a partir de um cofre gerenciado, restrinja quem pode lê-los e torne a rotação uma prática rotineira, não um incêndio.
Coloque a regeneração dentro das mesmas etapas do pipeline: regenere, faça o build, teste, empacote e então migre e faça o deploy com gates. Se você usa AppMaster para gerar o backend Go, isso permite avançar rápido sem adivinhar o que mudou e experimentar o fluxo no-code com mais confiança.



Experimente o AppMaster com plano gratuito.
Quando estiver pronto, você poderá escolher a assinatura adequada.


