App de reserva de equipamentos: evite conflitos e acompanhe as devoluções
Planeje um app de reserva de equipamentos que evite reservas duplicadas, registre devoluções e danos e coloque itens com problemas em manutenção.
Planeje e construa um aplicativo de gestão de incidentes para equipes de TI com fluxos de severidade, responsabilidade clara, linhas do tempo e postmortems em uma única ferramenta interna.
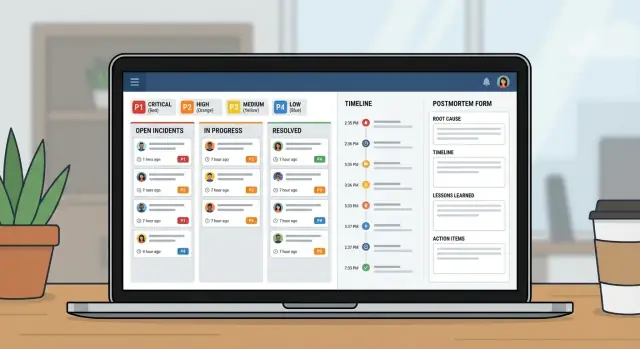
Quando uma queda acontece, a maioria das equipes pega o que estiver aberto: uma thread no chat, uma cadeia de emails, talvez uma planilha que alguém atualiza quando tem um minuto. Sob pressão, esse arranjo falha sempre das mesmas formas: a responsabilidade fica confusa, carimbos de hora somem e decisões desaparecem no scroll.
Um aplicativo simples de gestão de incidentes resolve o básico. Ele oferece um lugar único onde o incidente vive, com um responsável claro, um nível de severidade que todos concordam e uma linha do tempo do que aconteceu e quando. Esse registro único importa porque as mesmas perguntas surgem em todo incidente: quem está liderando? quando começou? qual é o status atual? o que já foi tentado?
Sem esse registro compartilhado, os repasses desperdiçam tempo. Suporte diz aos clientes uma coisa enquanto engenharia faz outra. Gerentes pedem atualizações que desviam os respondedores da correção. Depois, ninguém consegue reconstruir a linha do tempo com confiança, então o postmortem vira chute.
O objetivo não é substituir seu monitoramento, chat ou sistema de tickets. Alertas ainda podem começar em outro lugar. A ideia é capturar a trilha de decisões e manter as pessoas alinhadas.
Operações de TI e engenheiros on-call usam o app para coordenar a resposta. Suporte usa para dar atualizações rápidas e precisas. Gerentes usam para ver progresso sem interromper os respondedores.
Às 9:12, o monitoramento sinaliza um pico de erros 500 no portal do cliente. Um agente de suporte também relata: “Login falha para a maioria dos usuários.” O responsável on-call de TI abre um incidente P1 no app e anexa o primeiro alerta mais uma captura de tela do suporte.
Com um P1, o comportamento muda rápido. O dono do incidente envolve o responsável pelo backend, o dono do banco de dados e um elo com suporte. Trabalho não essencial é pausado. Deploys planejados param. A equipe combina uma cadência de updates (por exemplo, a cada 15 minutos). Começa uma call compartilhada, mas o registro do incidente continua sendo a fonte da verdade.
Às 9:18, alguém pergunta: “O que mudou?” A linha do tempo mostra um deploy às 8:57, mas não diz o que foi deployado. O responsável pelo backend faz rollback mesmo assim. Os erros caem e depois voltam. Agora a equipe suspeita do banco de dados.
A maioria dos atrasos aparece em alguns pontos previsíveis: repasses confusos (“achava que você estava verificando aquilo”), contexto faltando (mudanças recentes, riscos conhecidos, responsável atual) e atualizações espalhadas por chat, tickets e email.
Às 9:41, o dono do banco de dados encontra uma query desenfreada iniciada por um job agendado. Eles desabilitam o job, reiniciam o serviço afetado e confirmam a recuperação. A severidade é rebaixada para P2 para monitoramento.
Um bom encerramento não é “voltou a funcionar”. É um registro limpo: linha do tempo minuto a minuto, causa raiz final, quem tomou qual decisão, o que foi pausado e trabalhos de follow-up com responsáveis e prazos. É assim que um P1 estressante vira aprendizado em vez de dor repetida.
Uma boa ferramenta de incidentes é, na maior parte, um bom modelo de dados. Se os registros são vagos, as pessoas vão discutir o que é o incidente, quando começou e o que ainda está aberto.
Mantenha as entidades centrais próximas de como equipes de TI já falam:
Para evitar confusão depois, dê ao Incident alguns campos estruturados que sempre sejam preenchidos. Texto livre ajuda, mas não deve ser a única fonte da verdade. Um mínimo prático é: título claro, impacto (o que os usuários percebem), serviços afetados, hora de início, status atual e severidade.
Relações valem mais do que campos extras. Um incidente deve ter muitos updates e muitas tasks, além de uma ligação muitos-para-muitos com services (porque quedas frequentemente atingem vários sistemas). Um postmortem deve ser one-to-one com um incidente, para que haja uma história final única.
Exemplo: um incidente “Erros no checkout” liga aos Services “Payments API” e “PostgreSQL”, tem updates a cada 15 minutos e tarefas como “Fazer rollback do deploy” e “Adicionar guard de retry”. Depois, o postmortem captura a causa raiz e cria tarefas de longo prazo.
Quando as pessoas estão estressadas, elas precisam de rótulos simples que signifiquem a mesma coisa para todos. Defina P1 a P4 em linguagem clara e mostre a definição ao lado do campo de severidade.
As metas de resposta devem ler como compromissos. Uma linha de base simples (ajuste à sua realidade):
| Severity | First response (ack) | First update | Update frequency |
|---|---|---|---|
| P1 | 5 min | 15 min | every 30 min |
| P2 | 15 min | 30 min | every 60 min |
| P3 | 4 hours | 1 business day | daily |
| P4 | 2 business days | 1 week | weekly |
Mantenha regras de escalonamento mecânicas. Se um P2 perder sua cadência de updates ou o impacto crescer, o sistema deve sugerir revisar a severidade. Para evitar flutuações desnecessárias, limite quem pode alterar severidade (frequentemente o owner ou incident commander), permitindo ainda que qualquer pessoa peça revisão em um comentário.
Uma matriz rápida de impacto também ajuda equipes a escolher severidade rapidamente. Capture-a como alguns campos obrigatórios: usuários afetados, risco de receita, segurança/complicância, e se existe um workaround.
Durante um incidente, as pessoas não precisam de mais opções. Precisam de um conjunto pequeno de estados que deixem o próximo passo óbvio.
Comece com os passos que você já segue em um dia normal e mantenha a lista curta. Se tiver mais de 6 ou 7 estados, as equipes vão discutir palavras em vez de consertar o problema.
Um conjunto prático:
Cada status precisa de regras claras de entrada e saída. Por exemplo:
Use transições para forçar campos que as pessoas esquecem. Uma regra comum: não se pode fechar um incidente sem um curto resumo da causa raiz e ao menos um item de follow-up. Se “RCA: TBD” for permitido, tende a ficar assim.
A página do incidente deve responder três perguntas de relance: quem é o dono, qual é a próxima ação e quando foi o último update.
Quando um incidente é barulhento, a forma mais rápida de perder tempo é a responsabilidade vaga. Seu app deve deixar uma pessoa claramente responsável, ao mesmo tempo que facilita que outros ajudem.
Um padrão simples que funciona:
Atribuição deve ser explícita e auditável. Registre quem definiu o owner, quem aceitou e cada mudança depois disso. “Aceito” importa, porque atribuir alguém que está dormindo ou offline não é responsabilidade real.
Atribuição por on-call vs por time geralmente depende da severidade. Para P1/P2, o padrão é usar rotação on-call para sempre haver um owner nomeado. Para severidades menores, atribuição por time pode funcionar, mas ainda exija um owner primário em curto prazo.
Planeje férias e indisponibilidades no processo humano, não apenas no sistema. Se a pessoa atribuída estiver marcada como indisponível, direcione automaticamente para um secundário on-call ou líder do time. Mantenha isso automático, mas visível para correções rápidas.
Escalonamento deve disparar por severidade e por silêncio. Um ponto de partida útil:
Uma boa linha do tempo é memória compartilhada. Durante um incidente, o contexto desaparece rápido. Se você capturar os momentos certos em um só lugar, os repasses ficam mais fáceis e o postmortem já estará em grande parte escrito antes de alguém abrir um documento.
Mantenha a linha do tempo opinativa. Não a transforme em um log de chat. A maioria das equipes depende de um conjunto pequeno de entradas: detecção, reconhecimento, passos-chave de mitigação, restauração e encerramento.
Cada entrada precisa de carimbo de hora, autor e uma descrição curta e direta. Alguém que entra tarde deve conseguir ler cinco entradas e entender o que está acontecendo.
Updates diferentes servem públicos diferentes. Ajuda quando as entradas têm um tipo, como nota interna (detalhes brutos), atualização para cliente (redação segura), decisão (por que escolheram a opção A) e repasse (o que a próxima pessoa precisa saber).
Lembretes devem seguir a severidade, não preferência pessoal. Se o timer bater, pingue o owner atual primeiro e escale se for repetidamente ignorado.
As notificações devem ser direcionadas e previsíveis. Um conjunto pequeno de regras costuma bastar: notificar na criação, mudança de severidade, restauração e updates atrasados. Evite notificar a empresa inteira a cada alteração.
Um postmortem deve cumprir dois papéis: explicar o que aconteceu em linguagem simples e tornar a mesma falha menos provável da próxima vez.
Mantenha o texto curto e transforme conclusões em ações. Uma estrutura prática inclui: resumo, impacto ao cliente, causa raiz, correções aplicadas e follow-ups.
Os follow-ups são o ponto. Não os deixe como um parágrafo no fim. Transforme cada follow-up em uma task rastreada com dono e prazo, mesmo que o prazo seja “próxima sprint”. Essa é a diferença entre “devemos melhorar o monitoramento” e “Alex adiciona um alerta de saturação de conexão DB até sexta”.
Tags tornam postmortems úteis depois. Adicione 1 a 3 temas a cada incidente (lacuna de monitoramento, deploy, capacidade, processo). Depois de um mês, você já consegue responder se a maioria dos P1s vem de releases ou de alertas faltantes.
Evidências devem ser fáceis de anexar, não obrigatórias. Permita campos opcionais para screenshots, trechos de log e referências a sistemas externos (IDs de tickets, threads de chat, números de caso de fornecedor). Mantenha leve para que as pessoas realmente preencham.
Trate isso como um pequeno produto, não como uma planilha com colunas extras. Um bom app de incidentes tem, na prática, três visões: o que está acontecendo agora, o que fazer a seguir e o que aprender depois.
Comece esboçando as telas que as pessoas vão abrir sob pressão:
Construa o modelo de dados e as permissões juntos. Se todo mundo pode editar tudo, o histórico fica bagunçado. Uma abordagem comum: acesso amplo de visualização para TI, mudanças controladas de estado/severidade, respondedores podem adicionar updates e um owner claro para aprovação do postmortem.
Depois, adicione regras de workflow que evitem incidentes meio preenchidos. Campos obrigatórios devem depender do estado. Você pode permitir “New” com apenas título e reporter, mas exigir que “Mitigating” inclua um resumo de impacto e que “Resolved” contenha um resumo da causa raiz mais ao menos um follow-up.
Por fim, teste reproduzindo 2 a 3 incidentes passados. Faça uma pessoa agir como incident commander e outra como respondedora. Logo você verá quais status são confusos, quais campos as pessoas pulam e onde precisa de melhores padrões.
A maioria dos sistemas de incidentes falha por motivos simples: as pessoas não lembram das regras quando estão estressadas e o app não captura os fatos necessários depois.
Se você tem seis níveis de severidade e dez estados, as pessoas vão chutar. Mantenha severidades em 3 a 4 e estados focados no que alguém deve fazer a seguir.
Quando todo mundo está “vendo”, ninguém está conduzindo. Exija um owner nomeado antes que o incidente possa avançar e torne as transferências explícitas.
Se “o que aconteceu quando” depende do histórico de chat, os postmortems viram discussões. Capture automaticamente timestamps de abertura, reconhecimento, mitigação e resolução, e mantenha as entradas curtas.
Também evite fechar com notas vagues de causa raiz como “problema de rede.” Exija uma declaração clara da causa e ao menos um próximo passo concreto.
Antes de liberar para toda a organização de TI, estresse os básicos. Se as pessoas não encontrarem o botão certo nos primeiros dois minutos, voltarão a usar chat e planilhas.
Foque em um conjunto curto de checagens de lançamento: papéis e permissões, definições claras de severidade, exigência de ownership, regras de lembrete e um caminho de escalonamento quando metas de resposta forem perdidas.
Pilote com um time e alguns serviços que geram alertas frequentes. Rode por duas semanas e ajuste com base em incidentes reais.
Se quiser construir isso como uma única ferramenta interna sem costurar planilhas e apps separados, AppMaster (appmaster.io) é uma opção. Ele permite criar um modelo de dados, regras de workflow e interfaces web/móveis em um só lugar, o que funciona bem para fila de incidentes, página de incidente e rastreamento de postmortems.
Substitui atualizações espalhadas por um único registro compartilhado que responde rapidamente ao básico: quem é o responsável, o que os usuários estão vendo, o que já foi tentado e qual é o próximo passo. Isso reduz tempo perdido em repasses, mensagens conflitantes e interrupções pedindo resumo.
Abra o incidente assim que houver impacto real ao cliente ou ao negócio, mesmo que a causa ainda não esteja clara. Você pode criá-lo com um título provisório e “impacto desconhecido” e depois ir refinando conforme confirma severidade e escopo.
Mantenha pequeno e estruturado: um título claro, resumo do impacto, serviço(s) afetado(s), hora de início, status atual, severidade e um único responsável. Adicione updates e tarefas conforme o incidente evolui, mas não confie apenas em texto livre para os fatos principais.
Use de 3 a 4 níveis com significados simples que não gerem discussão. Um padrão útil é P1 para indisponibilidade crítica ou risco de perda de dados, P2 para impacto relevante com workaround ou alcance limitado, P3 para impactos menores e P4 para problemas cosméticos ou de baixa prioridade.
Rastreie metas que soem como compromissos: tempo até reconhecer, tempo até a primeira atualização e cadência de atualizações. Dispare lembretes e escalonamentos quando a cadência for perdida — o silêncio costuma ser o problema real durante incidentes.
Vise cerca de seis estados: New, Acknowledged, Investigating, Mitigating, Monitoring e Resolved. Cada estado deve tornar óbvio o próximo passo e as transições devem forçar campos que tendem a ser esquecidos sob estresse, como exigir um responsável antes de Acknowledged ou um resumo de causa antes do fechamento.
Exija um proprietário primário responsável por conduzir a resposta e publicar atualizações. Registre a aceitação explicitamente para não “atribuir” alguém que esteja offline, e torne as transferências de responsabilidade um evento registrado para que o próximo não recomece a investigação do zero.
Capture apenas os momentos que importam: detecção, reconhecimento, decisões-chave, passos de mitigação, restauração e encerramento, cada um com carimbo de hora e autor. Trate a linha do tempo como memória compartilhada, não como um registro de chat longo, para que alguém entrando tarde consiga entender rapidamente.
Mantenha o postmortem curto e focado em ações: o que aconteceu, impacto ao cliente, causa raiz, o que foi alterado durante a mitigação e itens de acompanhamento com responsáveis e prazos. O texto é útil, mas as tarefas rastreadas são o que evita repetir o mesmo incidente.
Sim — se você modelar incidentes, updates, tarefas, serviços e postmortems como dados reais e aplicar regras de fluxo de trabalho no app. Com AppMaster (appmaster.io), times podem construir esse modelo de dados, telas web/móvel e validações por estado num só lugar, evitando que o processo volte a planilhas sob pressão.



Experimente o AppMaster com plano gratuito.
Quando estiver pronto, você poderá escolher a assinatura adequada.


