App de reserva de equipamentos: evite conflitos e acompanhe as devoluções
Planeje um app de reserva de equipamentos que evite reservas duplicadas, registre devoluções e danos e coloque itens com problemas em manutenção.
Aprenda alterações de esquema sem tempo de inatividade com migrações aditivas, backfills seguros e rollouts em fases que mantêm clientes antigos funcionando durante releases.
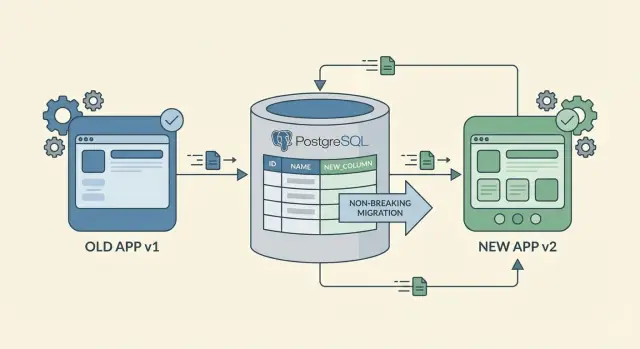
Alterações de esquema sem tempo de inatividade não significam que nada muda. Significam que os usuários podem continuar trabalhando enquanto você atualiza o banco de dados e o app, sem falhas ou fluxos de trabalho bloqueados.
Downtime é qualquer momento em que o sistema para de se comportar normalmente. Isso pode se manifestar como erros 500, timeouts de API, telas que carregam mas mostram valores em branco ou incorretos, jobs em background que caem, ou um banco de dados que aceita leituras mas bloqueia escritas porque uma migração longa está segurando locks.
Uma alteração de esquema pode quebrar mais do que a interface principal do app. Pontos de falha comuns incluem clientes de API que esperam um formato antigo de resposta, jobs em background que leem ou escrevem colunas específicas, relatórios que consultam tabelas diretamente, integrações de terceiros e scripts administrativos internos que "estavam funcionando ontem".
Apps móveis antigos e clientes em cache são um problema frequente porque você não consegue atualizá-los instantaneamente. Alguns usuários mantêm uma versão do app por semanas. Outros têm conectividade intermitente e re-tentam requisições antigas mais tarde. Mesmo clientes web podem se comportar como “versões antigas” quando um service worker, CDN ou proxy cache mantém código ou suposições desatualizadas.
O objetivo real não é “uma grande migração que termine rápido.” É uma sequência de pequenos passos onde cada etapa funciona por si só, mesmo quando clientes diferentes estão em versões distintas.
Uma definição prática: você deve ser capaz de deployar novo código e novo esquema em qualquer ordem, e o sistema ainda funcionar.
Essa mentalidade ajuda a evitar a armadilha clássica: deployar um app novo que espera uma coluna nova antes da coluna existir, ou deployar uma coluna nova que o código antigo não consegue manipular. Planeje mudanças para serem aditivas primeiro, lance-as em fases e remova caminhos antigos só depois de ter certeza de que ninguém os usa.
O caminho mais seguro para alterações de esquema sem downtime é adicionar, não substituir. Adicionar uma coluna nova ou uma tabela raramente quebra algo porque o código existente pode continuar lendo e escrevendo na forma antiga.
Renomeações e exclusões são movimentos arriscados. Renomear é efetivamente “adicionar novo + remover antigo”, e a parte “remover antigo” é onde clientes mais antigos caem. Se precisar renomear, trate como uma mudança em dois passos: adicione o campo novo primeiro, mantenha o campo antigo por um tempo e remova-o somente depois que tiver certeza de que nada mais depende dele.
Ao adicionar colunas, comece com campos nulos. Uma coluna que aceita NULL permite que o código antigo continue inserindo linhas sem saber do novo campo. Se você quiser NOT NULL no fim, adicione-a como nullable primeiro, faça o backfill e então imponha NOT NULL mais tarde. Defaults também ajudam, mas cuidado: adicionar um default pode tocar muitas linhas em alguns bancos, o que pode tornar a mudança lenta.
Índices são outra adição “segura mas não grátis”. Podem acelerar leituras, mas criar e manter um índice pode desacelerar escritas. Adicione índices quando souber exatamente qual consulta os usará e considere aplicá-los em horários de menor movimento se o banco estiver ocupado.
Um conjunto simples de regras para migrações aditivas:
nullable) até que os dados sejam preenchidos.NOT NULL, unique, foreign keys) até depois dos backfills.Trate alterações de esquema sem downtime como um rollout, não um único deploy. O objetivo é deixar versões antigas e novas do app rodando em paralelo enquanto o banco de dados migra gradualmente para a nova forma.
Uma sequência prática:
NULL e evite restrições rígidas que o código antigo não consiga satisfazer. Se precisar de um índice, crie-o de forma que não bloqueie escritas.Exemplo: você introduz full_name mas clientes antigos ainda enviam first_name e last_name. Por um período, o backend pode construir full_name na escrita, fazer o backfill dos usuários existentes e, mais tarde, ler full_name por padrão enquanto ainda suporta payloads antigos. Só depois de a adoção ficar clara é que você remove os campos antigos.
Um backfill popula uma nova coluna ou tabela para linhas existentes. É frequentemente a parte mais arriscada das alterações de esquema sem downtime porque pode criar carga pesada no banco, locks longos e comportamento confuso de “meio migrado”.
Comece escolhendo como executar o backfill. Para conjuntos de dados pequenos, um runbook manual único pode bastar. Para conjuntos grandes, prefira um worker em background ou uma tarefa agendada que possa rodar repetidamente e parar com segurança.
Bataque o trabalho em lotes para controlar a pressão no banco. Não atualize milhões de linhas em uma única transação. Mire em um tamanho de chunk previsível e uma pausa curta entre lotes para que o tráfego normal do usuário permaneça suave.
Um padrão prático:
Torne o job reiniciável. Armazene um marcador simples de progresso em uma tabela dedicada e desenhe o job para que re-execuções não corrompam dados. Atualizações idempotentes (por exemplo, UPDATE WHERE new_field IS NULL) são suas aliadas.
Valide conforme avança. Acompanhe quantas linhas ainda estão sem o novo valor e adicione algumas verificações de sanidade. Por exemplo: saldos não negativos, timestamps dentro do intervalo esperado, status em um conjunto permitido. Faça amostragem de registros reais para checagens pontuais.
Decida o que o app deve fazer enquanto o backfill não estiver completo. Uma opção segura é leituras de fallback: se o campo novo for nulo, calcule ou leia o valor antigo. Exemplo: você adiciona a coluna preferred_language. Até o backfill terminar, a API pode retornar o idioma existente das configurações de perfil quando preferred_language estiver vazio, e só começar a exigir o campo novo após a conclusão.
Quando você lança uma alteração de esquema, raramente controla todos os clientes. Usuários web atualizam rapidamente, enquanto builds móveis antigos podem ficar ativos por semanas. Por isso APIs compatíveis retroativamente importam, mesmo se sua migração de banco for “segura”.
Trate novos dados como opcionais inicialmente. Adicione novos campos a requests e responses, mas não os exija no primeiro dia. Se um cliente antigo não enviar o campo novo, o servidor ainda deve aceitar a requisição e se comportar como antes.
Evite mudar o significado de campos existentes. Renomear um campo pode ser aceitável se você mantiver o nome antigo funcionando também. Reutilizar um campo para um novo significado é onde ocorrem quebras sutis.
Defaults no lado do servidor são sua rede de segurança. Quando introduzir uma nova coluna como preferred_language, defina um default no servidor quando ela estiver ausente. A resposta da API pode incluir o campo novo, e clientes antigos podem simplesmente ignorá-lo.
Regras de compatibilidade que evitam a maioria das quedas:
Exemplo: você adiciona company_size ao fluxo de cadastro. O backend pode definir um default como “desconhecido” quando o campo estiver ausente. Clientes novos enviam o valor real, clientes antigos continuam funcionando e dashboards continuam legíveis.
Se sua plataforma regenera a aplicação, você obtém uma reconstrução limpa do código e da configuração. Isso ajuda com alterações de esquema sem downtime porque você pode fazer passos pequenos e aditivos e redeployar frequentemente em vez de carregar patches por meses.
A chave é uma única fonte de verdade. Se o esquema do banco muda em um lugar e a lógica de negócio muda em outro, o drift acontece rápido. Decida onde as mudanças são definidas e trate todo o resto como saída gerada.
Nomes claros reduzem acidentes durante rollouts em fases. Se introduzir um campo novo, torne óbvio qual é seguro para clientes antigos e qual é o novo caminho. Por exemplo, nomear uma coluna status_v2 é mais seguro do que status_new porque ainda faz sentido seis meses depois.
Mesmo quando mudanças são aditivas, uma rebuild pode revelar acoplamentos ocultos. Depois de cada regeneração e deploy, verifique novamente um pequeno conjunto de fluxos críticos:
Planeje os passos de migração antes de abrir o editor: adicione o novo campo, deploie com ambos os campos suportados, faça o backfill, mude as leituras e, depois, aposente o caminho antigo. Essa sequência mantém esquema, lógica e código gerado andando juntos para que mudanças fiquem pequenas, revisáveis e reversíveis.
A maioria das quedas durante alterações de esquema sem downtime não vem de trabalho “pesado” no banco. Vem de mudar o contrato entre banco, API e clientes na ordem errada.
Armadilhas comuns e movimentos mais seguros:
nullable, envie código que o escreva em todos os lugares, faça o backfill e então imponha NOT NULL com uma migração final.Se você regenera sua app, é tentador “limpar” nomes e restrições de uma vez. Resista: limpeza é o último passo, não o primeiro.
Uma boa regra: se uma mudança não pode ser aplicada de forma segura para frente e para trás, ela não está pronta para produção.
Alterações de esquema sem downtime são decididas por duas coisas: o que você monitora e com que rapidez consegue parar.
Acompanhe sinais que refletem impacto real no usuário, não apenas “o deploy terminou”:
Se estiver fazendo escritas duplas, adicione logging temporário que compare os dois valores. Mantenha enxuto: logue apenas quando os valores diferirem, inclua ID do registro e um código de razão curto, e amostre se o volume for alto. Crie um lembrete para remover esse logging após a migração para que não vire ruído permanente.
Rollback precisa ser realista. Na maioria das vezes, você não reverte o esquema. Você reverte o código e mantém o esquema aditivo no lugar.
Um runbook prático de rollback:
Para backfills, tenha um interruptor que possa ser acionado em segundos (feature flag, valor de configuração, pausa do job). Também comunique as fases antecipadamente: quando começam as escritas duplas, quando o backfill roda, quando as leituras mudam e o que significa “parar” para que ninguém improvisar sob pressão.
Pouco antes de enviar uma alteração de esquema, pare e execute esta checagem rápida. Ela pega suposições pequenas que viram outages com versões de cliente mistas.
Se você usa uma plataforma que regenera, adicione mais uma checagem: gere e deploie um build a partir do modelo exato que está migrando e confirme que a API e a lógica geradas ainda toleram registros antigos. Um erro comum é assumir que o novo esquema implica nova lógica requerida.
Também escreva duas ações rápidas que você tomará se algo estiver errado após o deploy: o que vai monitorar (erros, timeouts, progresso do backfill) e o que vai reverter primeiro (feature flag off, pausar backfill, reverter release do servidor). Isso transforma “vamos reagir rápido” em um plano concreto.
Você roda um app de pedidos. Precisa de um campo novo, delivery_window, que será obrigatório para novas regras de negócio. O problema é que builds antigos de iOS e Android ainda estão em uso e não vão enviar esse campo por dias ou semanas. Se você tornar o banco o exigir imediatamente, esses clientes começarão a falhar.
Um caminho seguro:
nullable, sem restrições. Mantenha leituras e escritas existentes inalteradas.NULL.delivery_window para linhas antigas usando uma regra (inferir pelo método de envio, ou default para “qualquer horário” até o cliente editar).delivery_window primeiro, mas faça fallback para o valor inferido quando estiver ausente.NOT NULL e remova o fallback.O que os usuários sentem em cada fase permanece sem surpresas (esse é o objetivo):
Um gate de monitoramento simples para cada passo: acompanhe a porcentagem de novos pedidos onde delivery_window é não nulo. Quando se mantiver consistentemente alta (e erros de validação por “campo ausente” ficarem perto de zero), geralmente é seguro ir do backfill para impor a restrição.
Um rollout cuidadoso único não é estratégia. Trate alterações de esquema como rotina: mesmos passos, mesma nomenclatura, mesmas aprovações. Assim a próxima mudança aditiva continua sem surpresas, mesmo quando o app está ocupado e clientes estão em versões distintas.
Mantenha o playbook curto. Deve responder: o que adicionamos, como enviamos com segurança e quando removemos as partes antigas.
Um template simples:
Comece com uma tabela de baixo risco (um status opcional novo, um campo de notas) e execute o playbook completo: mudança aditiva, backfill, clientes em versões mistas e depois a limpeza. Esse ensaio expõe lacunas em monitoramento, batching e comunicação antes de você tentar um redesign maior.
Um hábito que evita bagunça de longo prazo: trate itens “remover depois” como trabalho real. Quando adicionar uma coluna temporária, código de compatibilidade ou lógica de escrita dupla, crie imediatamente um ticket de limpeza com dono e data. Mantenha uma nota pequena de “dívida de compatibilidade” nos docs de release para que isso permaneça visível.
Se você constrói com AppMaster, pode tratar a regeneração como parte do processo de segurança: modele o esquema aditivo, atualize a lógica de negócio para lidar com campos antigos e novos durante a transição e regenere para que o código-fonte permaneça limpo conforme os requisitos mudam. AppMaster foi desenhado em torno desse estilo de entrega iterativa e em fases.
O objetivo não é perfeição. É repetibilidade: cada migração tem um plano, uma métrica e uma saída segura.
Zero-downtime significa que os usuários conseguem trabalhar normalmente enquanto você altera o esquema e faz deploy do código. Isso inclui evitar quedas óbvias, mas também evitar falhas silenciosas como telas em branco, valores errados, jobs que caem ou escritas bloqueadas por migrações longas.
Porque muitas partes do sistema dependem da forma do banco de dados, não apenas da interface principal. Jobs em background, relatórios, scripts administrativos, integrações e apps móveis antigos podem continuar enviando ou esperando campos antigos muito depois do deploy do código novo.
Builds móveis antigos podem permanecer em uso por semanas, e alguns clientes re-tentam requisições antigas mais tarde. Sua API precisa aceitar tanto payloads antigos quanto novos por um tempo para que versões mistas coexistam sem erros.
Mudanças aditivas geralmente não quebram o código existente porque o esquema antigo continua presente. Renomeações e deleções são arriscadas porque removem algo que clientes antigos ainda leem ou gravam, causando falhas ou requisições rejeitadas.
Adicione a coluna como nullable primeiro, para que o código antigo continue inserindo linhas. Faça o backfill das linhas existentes em lotes e, somente quando a cobertura estiver alta e as novas escritas forem consistentes, aplique NOT NULL como um passo final.
Trate como um rollout: adicione um esquema compatível, faça deploy do código que suporta ambas as versões, backfill em pequenos lotes, altere as leituras com fallback e remova o campo antigo somente quando puder provar que não é mais usado. Cada etapa deve funcionar isoladamente.
Execute em pequenos lotes com transações curtas para não travar tabelas nem causar picos de carga. Torne o trabalho reiniciável e idempotente — por exemplo, atualize apenas onde new_field IS NULL — e rastreie progresso para poder pausar e retomar com segurança.
Faça novos campos opcionais inicialmente e aplique defaults no servidor quando estiverem ausentes. Mantenha o comportamento antigo estável, evite mudar o significado de campos existentes e teste ambos os caminhos: “cliente novo envia” e “cliente antigo omite”.
Na maioria das vezes você reverte o código da aplicação, não o esquema. Mantenha as colunas/tabelas aditivas, desabilite leituras novas primeiro, depois pare as escritas novas e pause os backfills até os indicadores voltarem ao normal para recuperar rapidamente sem perda de dados.
Acompanhe sinais de impacto real no usuário, como taxa de erros, queries lentas (p95/p99), latência de escrita, profundidade de filas e pressão de CPU/IO do banco. Só avance quando os indicadores estiverem estáveis e a cobertura do novo campo for alta; trate a limpeza como trabalho real, não como “depois”.



Experimente o AppMaster com plano gratuito.
Quando estiver pronto, você poderá escolher a assinatura adequada.


