27 nov. 2025·8 min de lecture
Workflows longue durée : reprises, dead-letters et visibilité
Les workflows longue durée échouent de façons compliquées. Apprenez des modèles d'état clairs, les compteurs de reprise, la gestion des dead-letters et des tableaux de bord opérateurs fiables.
Ce qui casse dans l'automatisation longue durée
Les workflows longue durée échouent différemment des requêtes rapides. Un appel API court réussit ou échoue immédiatement. Un workflow qui tourne pendant des heures ou des jours peut enchaîner 9 étapes sur 10 et laisser tout de même un désordre : enregistrements à moitié créés, statut confus et aucune action suivante claire.
C'est pourquoi on entend souvent « ça marchait hier ». Le workflow n'a pas changé, mais son environnement a évolué. Les workflows longue durée reposent sur la santé d'autres services, la validité des identifiants et la stabilité du format des données.
Les modes de défaillance les plus courants ressemblent à ceci : timeouts et dépendances lentes (une API partenaire répond mais en 40 s aujourd'hui), mises à jour partielles (enregistrement A créé, B non créé, et on ne peut pas relancer sans risque), pannes de dépendances (fournisseurs d'email/SMS, passerelles de paiement, fenêtres de maintenance), callbacks perdus et heures planifiées manquées (un webhook n'arrive jamais, un job timer ne s'est pas déclenché), et étapes humaines qui bloquent (une approbation reste en attente pendant des jours puis reprend avec des hypothèses obsolètes).
La difficulté vient de l'état. Une « requête rapide » peut garder l'état en mémoire jusqu'à la fin. Un workflow ne le peut pas. Il doit persister l'état entre les étapes et être prêt à reprendre après un redémarrage, un déploiement ou un crash. Il doit aussi gérer la même étape qui se déclenche deux fois (reprises, webhooks dupliqués, rejouements par un opérateur).
En pratique, « fiable » signifie moins « ne jamais échouer » que « être prévisible, explicable, récupérable et clairement pris en charge ».
Prévisible : le workflow réagit toujours de la même façon à une défaillance d'une dépendance. Explicable : un opérateur sait répondre en une minute « où c'est bloqué et pourquoi ? ». Récupérable : on peut relancer ou continuer sans causer de dégâts. Prise en charge claire : chaque élément bloqué a une action évidente à effectuer : attendre, relancer, corriger les données ou confier à une personne.
Un exemple simple : une automatisation d'onboarding crée un client, provisionne des accès et envoie un message de bienvenue. Si la provision réussit mais l'envoi échoue parce que le fournisseur d'email est indisponible, un workflow fiable enregistre « Provisionné, message en attente » et planifie une reprise. Il ne relance pas aveuglément la provision.
Les outils peuvent aider en rapprochant la logique du workflow et les données persistantes. Par exemple, AppMaster permet de modéliser l'état du workflow dans vos données (via le Data Designer) et de le mettre à jour depuis des Business Processes visuels. Mais la fiabilité vient du modèle, pas de l'outil : traitez l'automatisation longue durée comme une suite d'états durables qui survivent au temps, aux échecs et à l'intervention humaine.
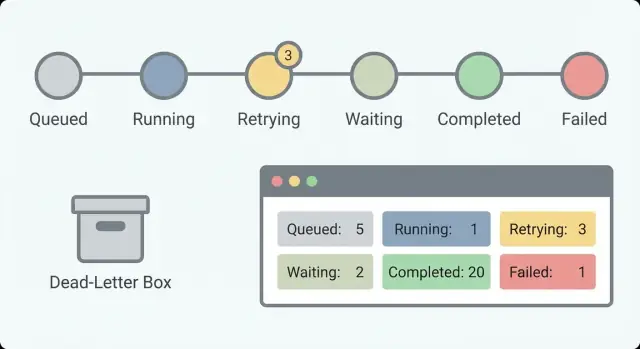
Définir des états lisibles par des humains
Les workflows longue durée échouent de façon répétable : une API tierce ralentit, un humain n'a pas approuvé, ou un job attend dans une file. Des états clairs rendent ces situations évidentes, pour que l'on ne confonde pas « ça prend du temps » et « c'est cassé ».
Commencez par un petit ensemble d'états qui répondent à une question : que se passe-t-il maintenant ? Si vous avez 30 états, personne ne s'en souviendra. Avec 5 à 8, une personne en astreinte peut balayer la liste et comprendre.
Un ensemble pratique d'états qui fonctionne pour beaucoup de workflows :
- En file d'attente (créé mais pas démarré)
- En cours (travail actif)
- En attente (mis en pause sur timer, callback ou intervention humaine)
- Terminé (succès)
- Échoué (arrêté sur une erreur)
Séparer En attente de En cours est important. « En attente d'une réponse client » est sain. « En cours depuis 6 heures » peut être un blocage. Sans cette séparation, vous poursuivrez de fausses alertes et manquerez les vraies.
Que stocker avec chaque état
Un nom d'état ne suffit pas. Ajoutez quelques champs qui transforment un statut en action concrète :
- État courant et date/heure du dernier changement d'état
- État précédent
- Une courte raison lisible par un humain pour les échecs ou pauses
- Un compteur de tentatives optionnel ou un numéro de tentative
Exemple : un flux d'onboarding pourrait afficher « En attente » avec la raison « Approbation manager en cours » et « modifié il y a 2 jours ». Cela indique que ce n'est pas bloqué, mais qu'il peut nécessiter un rappel.
Garder les états stables
Traitez les noms d'état comme une API. Si vous les renommez chaque mois, les tableaux de bord, alertes et playbooks deviennent vite trompeurs. Si vous avez besoin d'une nouvelle sémantique, introduisez un nouvel état et laissez l'ancien pour les enregistrements existants.
Dans AppMaster, vous pouvez modéliser ces états dans le Data Designer et les mettre à jour depuis la logique Business Process. Ainsi le statut reste visible et cohérent dans l'app plutôt que noyé dans les logs.
Reprises qui s'arrêtent au bon moment
Les reprises aident jusqu'à ce qu'elles cachent le vrai problème. L'objectif n'est pas « ne jamais échouer » mais « échouer de façon compréhensible et réparable ». Tout commence par une règle claire sur ce qui est retryable et ce qui ne l'est pas.
Une règle simple : relancez les erreurs probablement temporaires (timeouts réseau, limites de débit, pannes brèves). Ne relancez pas les erreurs clairement permanentes (données invalides, permissions manquantes, « compte fermé », « carte refusée »). Si vous ne savez pas dans quel panier mettre une erreur, traitez-la comme non-retryable jusqu'à en savoir plus.
Faire des retries par étape, pas par workflow
Suivez les compteurs de reprise par étape (ou par appel externe), pas un seul compteur pour tout le workflow. Un workflow peut contenir dix étapes, et une seule peut être instable. Les compteurs par étape évitent qu'une étape ultérieure « vole » les tentatives d'une étape antérieure.
Par exemple, un appel « Téléverser document » peut être retenté quelques fois, alors que « Envoyer email de bienvenue » ne doit pas consommer toutes les tentatives parce que le téléversement a épuisé les essais.
Backoff, conditions d'arrêt et actions suivantes claires
Choisissez un pattern de backoff adapté au risque. Des délais fixes suffisent pour des tentatives simples et peu coûteuses. Un backoff exponentiel aide en cas de limites de débit. Ajoutez un plafond pour que les attentes ne croissent pas indéfiniment et un peu de jitter pour éviter des tempêtes de reprise.
Décidez ensuite quand arrêter. De bonnes conditions d'arrêt sont explicites : nombre maximal de tentatives, durée totale maximale, ou « abandonner pour certains codes d'erreur ». Une passerelle de paiement retournant « carte invalide » doit s'arrêter immédiatement même si vous autorisez normalement cinq tentatives.
Les opérateurs ont aussi besoin de savoir ce qui va se passer ensuite. Enregistrez la date/heure de la prochaine tentative et la raison (par exemple « Reprise 3/5 à 14:32 pour timeout »). Dans AppMaster, vous pouvez stocker cela sur l'enregistrement du workflow pour qu'un tableau de bord affiche « en attente jusqu'à » sans deviner.
Une bonne politique de reprise laisse une trace : ce qui a échoué, combien de fois, quand la prochaine tentative aura lieu et quand on s'arrêtera pour basculer en dead-letter.
Idempotence et protection contre les doublons
Dans des workflows qui durent des heures ou des jours, les reprises sont normales. Le risque est de répéter une étape qui a déjà réussi. L'idempotence rend cela sûr : une étape est idempotente si l'exécuter deux fois a le même effet que l'exécuter une fois.
Un échec classique : on débite une carte, puis le workflow plante avant d'enregistrer « paiement réussi ». À la reprise, la carte est débitée de nouveau. C'est un problème de double écriture : le monde extérieur a changé mais l'état du workflow ne l'a pas fait.
Le pattern le plus sûr est de créer une clé d'idempotence stable pour chaque étape à effet de bord, de l'envoyer avec l'appel externe et d'enregistrer le résultat de l'étape dès réception. De nombreux fournisseurs (paiement, webhooks) supportent des clés d'idempotence (par exemple, débiter une commande par OrderID). Si l'étape est répétée, le fournisseur renverra le résultat original au lieu de rejouer l'action.
À l'intérieur du moteur de workflow, supposez que chaque étape peut être rejouée. Dans AppMaster, cela signifie souvent sauvegarder les sorties d'étape dans votre modèle de données et les vérifier dans votre Business Process avant d'appeler à nouveau une intégration. Si « Envoyer email de bienvenue » a déjà un MessageID enregistré, une reprise doit réutiliser cet enregistrement et passer à la suite.
Une approche pratique anti-duplication :
- Générez une clé d'idempotence par étape à partir de données stables (ID du workflow + nom de l'étape + ID de l'entité métier).
- Écrivez un enregistrement « étape démarrée » avant l'appel externe.
- Après succès, stockez la réponse (transaction ID, message ID, statut) et marquez l'étape « terminée ».
- À la reprise, regardez le résultat stocké et réutilisez-le au lieu de répéter l'appel.
- Pour les cas incertains, ajoutez une règle de fenêtre temporelle (par exemple, « si démarré et pas de résultat après 10 min, vérifier le statut du fournisseur avant de relancer »).
Des doublons subsistent, surtout avec des webhooks entrants ou quand un utilisateur clique deux fois. Décidez d'une politique par type d'événement : ignorer les doublons exacts (même clé d'idempotence), fusionner les mises à jour compatibles (par exemple last-write-wins pour un champ de profil), ou signaler pour revue quand il y a un risque financier ou réglementaire.
Gestion des dead-letters sans perdre le contexte
Turn patterns into software
Generate production-ready backend, web, and native mobile apps from one no-code project.
Un dead-letter est un élément de workflow qui a échoué et qui a été déplacé hors du chemin normal pour ne pas bloquer le reste. Vous le conservez volontairement. L'objectif est de faciliter la compréhension de ce qui s'est passé, décider si c'est réparable et retraiter en sécurité.
La plus grande erreur est de n'enregistrer qu'un message d'erreur. Quand quelqu'un consulte le dead-letter plus tard, il a besoin d'assez de contexte pour reproduire le problème sans supposer.
Un enregistrement dead-letter utile capture :
- Identifiants stables (customer ID, order ID, request ID, workflow instance ID)
- Entrées originales (ou un snapshot sûr), plus les valeurs dérivées clés
- Où ça a échoué (nom de l'étape, état, dernière étape réussie)
- Tentatives (compteur de reprises, timestamps, prochaine reprise planifiée si applicable)
- Détails de l'erreur (message, code, stack trace si disponible, et payload de réponse du dépendant)
La classification rend les dead-letters exploitables. Une courte catégorie aide l'opérateur à choisir la bonne action. Groupes courants : erreur permanente (règle métier, état invalide), problème de données (champ manquant, format incorrect), dépendance down (timeout, rate limit, panne), et auth/permission (token expiré, identifiants rejetés).
Le retraitement doit être contrôlé. L'objectif est d'éviter des dommages répétés, comme débiter deux fois ou spammer des emails. Définissez qui peut relancer, quand relancer, ce qui peut être modifié (corriger des champs précis, joindre un document manquant, rafraîchir un token) et ce qui doit rester inchangé (request ID et clés d'idempotence en aval).
Rendez les dead-letters recherchables par identifiants stables. Quand un opérateur peut taper « order 18422 » et voir l'étape exacte, les entrées et l'historique des tentatives, les corrections deviennent rapides et cohérentes.
Si vous construisez cela dans AppMaster, traitez le dead-letter comme un modèle de données à part entière et stockez état, tentatives et identifiants en champs. Ainsi votre tableau de bord interne peut requêter, filtrer et déclencher une action de retraitement contrôlée.
Visibilité pour diagnostiquer les problèmes
Set retries the safe way
Create step-scoped retries, backoff, and stop rules in a visual Business Process.
Les workflows longue durée peuvent échouer lentement et de manière confuse : une étape attend une réponse par email, une passerelle de paiement met du temps à répondre, ou un webhook arrive deux fois. Si vous ne voyez pas ce que le workflow fait maintenant, vous vous mettez à deviner. Une bonne visibilité transforme « c'est cassé » en réponse claire : quel workflow, quelle étape, quel état et que faire ensuite.
Commencez par faire émettre à chaque étape le même petit ensemble de champs pour que les opérateurs puissent scanner rapidement :
- ID du workflow (et tenant/client si vous en avez un)
- Nom de l'étape et version de l'étape
- État courant (en cours, en attente, en reprise, échoué, terminé)
- Durée (temps dans l'étape et temps total du workflow)
- IDs de corrélation pour les systèmes externes (payment ID, message ID, ticket ID)
Ces champs supportent des compteurs qui montrent la santé en un coup d'œil. Pour les workflows longue durée, les compteurs importent plus que les erreurs isolées parce que vous cherchez des tendances : accumulation de travail, pics de reprises, ou attentes qui ne se terminent jamais.
Suivez démarrés, terminés, échoués, en reprise et en attente dans le temps. Un petit nombre en attente peut être normal (approbations humaines). Un compteur d'attentes qui monte signifie généralement un blocage. Un pic de reprises pointe souvent vers un fournisseur ou un bug répétitif.
Les alertes doivent correspondre à ce que vivent les opérateurs. Plutôt que « une erreur est survenue », alertez sur des symptômes : backlog croissant (démarrés moins terminés augmente), trop de workflows en attente au-delà d'un temps attendu, taux de reprises élevé pour une étape spécifique, ou un pic d'échecs après un déploiement.
Conservez une trace d'événements pour chaque workflow afin que « que s'est-il passé ? » soit répondable en une vue. Une trace utile inclut timestamps, transitions d'état, résumés d'entrées et sorties (pas les payloads sensibles), et la raison des reprises ou de l'échec. Exemple : « Débiter carte : reprise 3/5, timeout fournisseur, prochaine tentative dans 10 min. »
Les IDs de corrélation font le lien. Si un client dit « ma carte a été débitée deux fois », vous devez connecter vos événements de workflow à l'ID de transaction du fournisseur et à votre ID de commande interne. Dans AppMaster, vous pouvez standardiser cela dans la logique Business Process en générant et en passant des IDs de corrélation dans les appels API et les étapes de messagerie pour que tableau de bord et logs s'alignent.
Tableaux de bord et actions pensés pour l'opérateur
Quand un workflow tourne pendant des heures ou des jours, les échecs sont normaux. Ce qui transforme des échecs normaux en incident, c'est un tableau de bord qui ne dit que « Échoué » et rien d'autre. L'objectif est d'aider un opérateur à répondre à trois questions rapidement : que se passe-t-il, pourquoi et que peut-il faire ensuite en toute sécurité ?
Commencez par une liste de workflows qui facilite la mise au point sur les quelques éléments importants. Des filtres réduisent la panique et le bruit car chacun peut restreindre la vue rapidement.
Filtres utiles : état, ancienneté (date de démarrage et temps dans l'état courant), propriétaire (équipe/client/opérateur responsable), type (nom/version du workflow) et priorité si vous avez des étapes visibles par les clients.
Ensuite, affichez le « pourquoi » à côté du statut au lieu de le cacher dans les logs. Une pastille de statut n'aide que si elle est accompagnée du dernier message d'erreur, d'une courte catégorie d'erreur et de ce que le système prévoit de faire ensuite. Deux champs font la majorité du travail : dernière erreur et prochaine tentative. Si la prochaine tentative est vide, indiquez clairement si le workflow attend un humain, est en pause ou est en échec permanent.
Les actions opérateur doivent être sûres par défaut. Guidez les personnes vers des actions à faible risque d'abord et rendez explicites les actions risquées :
- Relancer maintenant (respecte les mêmes règles de reprise)
- Mettre en pause/reprendre
- Annuler (avec une raison obligatoire)
- Envoyer en dead-letter
- Forcer la poursuite (uniquement si vous pouvez préciser ce qui sera ignoré et ce qui risque de casser)
C'est lors d'un « forcer la poursuite » que survient le plus de dégâts. Si vous l'offrez, décrivez le risque en langage simple : « Cela saute la vérification du paiement et peut créer une commande impayée. » Montrez aussi quelles données seront écrites si l'action est validée.
Auditez tout ce que font les opérateurs. Enregistrez qui a fait quoi, quand, l'état avant/après et la note de raison. Si vous construisez des outils internes dans AppMaster, stockez cette piste d'audit dans une table dédiée et affichez-la sur la page de détail du workflow pour que les transferts se fassent proprement.
Pas à pas : un pattern simple et fiable
Automate onboarding reliably
Build an onboarding flow with approval steps that can pause, resume, and stay readable.
Ce pattern garde les workflows prévisibles : chaque élément est toujours dans un état clair, chaque échec a une destination, et les opérateurs peuvent agir sans deviner.
Étape 1 : Définir les états et les transitions autorisées. Écrivez un petit ensemble d'états lisibles par une personne (par exemple : En file d'attente, En cours, En attente sur externe, Succès, Échec, Dead-letter). Puis décidez quels mouvements sont légaux pour que le travail ne dérive pas dans le limbo.
Étape 2 : Décomposer le travail en petites étapes avec entrées/sorties claires. Chaque étape doit accepter une entrée bien définie et produire une sortie ou une erreur claire. Si vous avez besoin d'une décision humaine ou d'un appel API externe, faites-en une étape distincte pour pouvoir mettre en pause et reprendre proprement.
Étape 3 : Ajouter une politique de reprise par étape. Choisissez un nombre de tentatives, un délai entre essais et des raisons d'arrêt qui ne doivent jamais être reprises (données invalides, permission refusée, champs requis manquants). Stockez un compteur de reprise par étape pour que l'opérateur voie exactement ce qui est bloqué.
Étape 4 : Persister la progression après chaque étape. Après la fin d'une étape, sauvegardez le nouvel état et les sorties clés. Si le processus redémarre, il doit poursuivre depuis la dernière étape complétée, pas repartir du début.
Étape 5 : Router vers un dead-letter et supporter le retraitement. Quand les reprises sont épuisées, déplacez l'élément en dead-letter et conservez tout le contexte : entrées, dernière erreur, nom de l'étape, compteur de tentatives et timestamps. Le retraitement doit être délibéré : corrigez les données ou la config d'abord, puis refilez depuis une étape spécifique.
Étape 6 : Définir champs de tableau de bord et actions opérateur. Un bon tableau de bord répond à « quoi a échoué, où, et que puis-je faire ensuite ? » Dans AppMaster, vous pouvez construire cela comme une app admin simple adossée à vos tables de workflow.
Champs et actions clés à inclure :
- État courant et étape courante
- Compteur de reprises et prochaine tentative
- Dernier message d'erreur (court) et catégorie d'erreur
- « Relancer l'étape » et « Re-queue le workflow »
- « Envoyer en dead-letter » et « Marquer comme résolu »
Exemple : workflow d'onboarding avec une étape d'approbation humaine
Deploy where you want
Push your workflow tool to cloud or export source code when you need full control.
L'onboarding met la pression. Il mélange approbations, systèmes externes et personnes parfois hors ligne. Un flux simple : RH soumet un formulaire de nouvelle embauche, le manager approuve, les comptes IT sont créés et le nouvel employé reçoit un message de bienvenue.
Rendez les états lisibles. Quand quelqu'un ouvre l'enregistrement, il doit voir immédiatement la différence entre « En attente d'approbation » et « Relance de configuration des comptes ». Une ligne de clarté peut faire gagner une heure.
Un ensemble d'états clair à afficher dans l'UI :
- Brouillon (RH édite encore)
- En attente d'approbation du manager
- Provision des comptes (avec compteur de tentatives)
- Notification du nouvel employé
- Terminé (ou Annulé)
Les reprises s'appliquent aux étapes dépendantes du réseau ou d'API tierces : provision des comptes (email, SSO, Slack), envoi email/SMS et appels API internes. Gardez le compteur de reprises visible et plafonnez-le (par exemple, jusqu'à cinq tentatives avec des délais croissants, puis arrêter).
La gestion des dead-letters concerne les problèmes qui ne se résoudront pas seuls : aucun manager sur le formulaire, adresse email invalide, ou demande d'accès en conflit avec une politique. Quand vous dead-lettez une exécution, conservez le contexte : quel champ a échoué, la dernière réponse API, et qui peut approuver une dérogation.
Les opérateurs doivent avoir un petit ensemble d'actions simples : corriger les données (ajouter un manager, corriger l'email), relancer une étape échouée (pas tout le workflow), ou annuler proprement (et défaire la configuration partielle si nécessaire).
Avec AppMaster, vous pouvez modéliser cela dans le Business Process Editor, garder les compteurs de reprise en données et construire un écran opérateur dans le web UI builder qui montre l'état, la dernière erreur et un bouton pour relancer l'étape échouée.
Checklist et étapes suivantes
La plupart des problèmes de fiabilité sont prévisibles : une étape s'exécute deux fois, des reprises tournent à 2 h du matin, ou un élément « bloqué » n'a aucune indication de ce qui s'est passé. Une checklist empêche que ça devienne de la devinette.
Vérifications rapides qui attrapent la majorité des problèmes tôt :
- Une personne non technique peut-elle lire chaque état et le comprendre (En attente paiement, Envoi d'email, En attente d'approbation, Terminé, Échoué) ?
- Les reprises sont-elles bornées avec des limites claires (max tentatives, temps max) et chaque tentative incrémente-t-elle un compteur visible ?
- La progression est-elle sauvegardée après chaque étape pour qu'un redémarrage reprenne au dernier point confirmé ?
- Chaque étape est-elle idempotente, ou protégée contre les doublons par une clé de requête, un verrou ou une vérification « déjà fait » ?
- Quand quelque chose va en dead-letter, garde-t-il assez de contexte pour corriger et relancer en sécurité (données d'entrée, nom de l'étape, timestamps, dernière erreur et action de re-run contrôlée) ?
Si vous ne pouvez améliorer qu'une chose, améliorez la visibilité. Beaucoup de « bugs de workflow » sont en réalité des « on ne voit pas ce que ça fait ». Votre tableau de bord devrait montrer ce qui s'est passé dernièrement, ce qui va se passer ensuite et quand.
Une vue opérateur pratique inclut l'état courant, le dernier message d'erreur, le compteur de tentatives, la prochaine tentative et une action claire (relancer maintenant, marquer comme résolu, ou envoyer en revue manuelle). Gardez les actions sûres par défaut : relancer une seule étape, pas tout le workflow.
Étapes suivantes :
- Esquissez d'abord votre modèle d'états (états, transitions et états terminaux).
- Rédigez les règles de reprise par étape : quelles erreurs reprennent, combien attendre et quand arrêter.
- Décidez comment vous empêcherez les doublons : clés d'idempotence, contraintes uniques ou garde « vérifier puis agir ».
- Définissez le schéma de l'enregistrement dead-letter pour que les humains puissent diagnostiquer et relancer en confiance.
- Implémentez le flux et le tableau de bord opérateur dans un outil comme AppMaster, puis testez avec des pannes forcées (timeouts, entrées invalides, pannes de tiers).
Considérez ceci comme une checklist vivante. À chaque ajout d'étape, exécutez ces vérifications avant la mise en production.
FAQ
Les workflows longue durée peuvent réussir pendant des heures puis échouer près de la fin, laissant des changements partiels. Ils dépendent aussi d'éléments qui peuvent changer pendant l'exécution : disponibilité de tiers, validité des identifiants, format des données, et délais de réponse humains.
Gardez l'ensemble d'états petit et lisible pour qu'un opérateur comprenne immédiatement. Un bon défaut est : en file d'attente, en cours, en attente, réussi, et échoué. Séparer « en attente » de « en cours » permet de distinguer une pause saine d'un blocage.
Enregistrez suffisamment d'informations pour rendre le statut exploitable : l'état courant, la date/heure du dernier changement, l'état précédent et une raison courte quand c'est en attente ou en erreur. Si vous faites des reprises, stockez aussi un compteur de tentatives et la date/heure de la prochaine tentative prévue.
Cela évite les fausses alertes et les incidents manqués. « En attente d'approbation » ou « en attente d'un webhook » peut être normal, tandis que « en cours depuis six heures » peut signaler un blocage : les traiter comme des états différents améliore les alertes et les décisions opérateur.
Relancez les erreurs temporaires comme les timeouts, les limites de débit ou les pannes brèves. N'essayez pas de relancer les erreurs manifestement permanentes : données invalides, permissions manquantes, paiement refusé. Si vous ne pouvez pas décider, traitez l'erreur comme non-retryable jusqu'à clarification.
Les compteurs au niveau de l'étape empêchent qu'une intégration instable n'épuise toutes les tentatives du workflow. Ils facilitent aussi le diagnostic : on voit précisément quelle étape échoue, combien elle a été tentée et si les autres étapes sont impactées.
Choisissez un backoff adapté au risque et plafonnez-le pour éviter des délais infinis. Définissez des règles d'arrêt explicites : nombre max de tentatives, durée totale max, ou codes d'erreur pour lesquels on arrête immédiatement. Enregistrez aussi la raison de l'arrêt et la prochaine tentative planifiée.
Supposez qu'une étape puisse s'exécuter deux fois (reprises, replays, webhooks dupliqués) et concevez-la pour que la répétition soit sans conséquence. Une méthode courante : générer une clé d'idempotence stable par étape, écrire un enregistrement « étape démarrée » avant l'appel externe, et sauvegarder le résultat dès qu'il arrive pour réutilisation en cas de nouvelle tentative.
Un enregistrement dead-letter contient le contexte nécessaire pour corriger et retraiter en sécurité : identifiants stables, entrées originales (ou un snapshot sûr), où ça a échoué (nom de l'étape), historique des tentatives, et la réponse d'erreur du dépendant — pas seulement un message vague.
Un bon tableau de bord montre où en est le workflow, pourquoi il y est, et ce qui va se passer ensuite : ID du workflow, étape courante, état, temps dans l'état, dernière erreur et IDs de corrélation. Proposez des actions sûres par défaut (relancer une étape, mettre en pause/reprendre) et marquez clairement les actions risquées.