20 janv. 2026·8 min de lecture
Suppression logique vs suppression définitive : choisissez le bon cycle de vie des données
Suppression logique vs suppression définitive : apprenez à conserver l'historique, éviter les références cassées et répondre aux obligations de confidentialité avec des règles claires.
Ce que signifient réellement suppression logique et suppression définitive
« Supprimer » peut vouloir dire deux choses très différentes. Les confondre, c'est la façon dont les équipes perdent de l'historique ou échouent à satisfaire des demandes de confidentialité.
Une suppression définitive est ce que la plupart des gens imaginent : la ligne est retirée de la base de données. On la requête plus tard et elle a disparu. C'est une suppression réelle, mais elle peut aussi casser des références (comme une commande qui pointe vers un client supprimé) à moins que vous ne conceviez le système en conséquence.
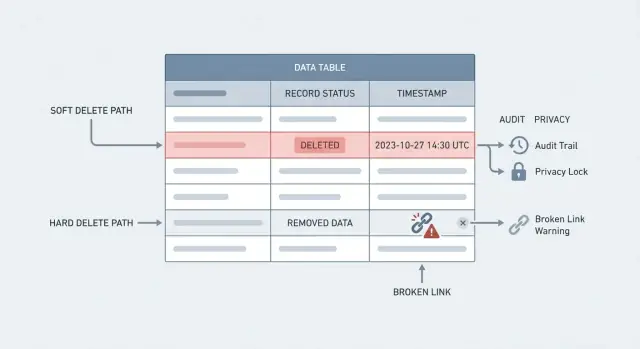
Une suppression logique conserve la ligne, mais la marque comme supprimée, généralement avec un champ comme deleted_at ou is_deleted. Votre appli la traite comme absente, mais les données restent disponibles pour les rapports, le support et les audits.
Le compromis derrière suppression logique vs suppression définitive est simple : historique vs suppression réelle. La suppression logique protège l'historique et rend l'« annulation » possible. La suppression définitive réduit ce que vous stockez, ce qui compte pour la confidentialité, la sécurité et les obligations légales.
Les suppressions affectent plus que le stockage. Elles changent ce que votre équipe peut reconstituer ensuite : un support qui cherche à comprendre une réclamation passée, la finance qui essaie de rapprocher la facturation, ou la conformité qui vérifie qui a changé quoi et quand. Si les données disparaissent trop tôt, les rapports se décalent, les totaux ne correspondent plus et les enquêtes deviennent des conjectures.
Un modèle mental utile :
- La suppression logique masque un enregistrement des vues quotidiennes mais le conserve pour la traçabilité.
- La suppression définitive supprime un enregistrement de façon permanente et minimise les données personnelles stockées.
- De nombreuses applications réelles utilisent les deux : garder les enregistrements métier, supprimer ou anonymiser les identifiants personnels quand nécessaire.
En pratique, vous pouvez mettre en suppression logique un compte utilisateur pour empêcher la connexion et préserver l'historique des commandes, puis supprimer définitivement (ou anonymiser) les champs personnels après une période de rétention ou après une demande vérifiée de droit à l'effacement (RGPD).
Aucun outil ne prend cette décision à votre place. Même si vous construisez avec une plateforme no-code comme AppMaster, le vrai travail consiste à décider, table par table, ce que « supprimé » signifie et à s'assurer que chaque écran, rapport et API suit la même règle.
Les vrais problèmes que causent les suppressions dans les applis quotidiennes
La plupart des équipes ne remarquent les suppressions que lorsque quelque chose tourne mal. Une suppression « simple » peut effacer du contexte, de l'historique et votre capacité à expliquer ce qui s'est passé.
Les suppressions définitives sont risquées car elles sont difficiles à annuler. Quelqu'un clique sur le mauvais bouton, un job automatisé a un bug, ou un agent de support suit le mauvais playbook. Sans sauvegardes propres et sans processus de restauration clair, cette perte devient permanente, et l'impact métier se fait sentir rapidement.
Les références cassées sont la surprise suivante. Vous supprimez un client, mais ses commandes existent toujours. Vous vous retrouvez avec des commandes pointant vers nulle part, des factures sans nom de facturation et un portail qui plante lorsqu'il essaie de charger des données liées. Même avec des contraintes de clé étrangère, la « correction » peut être pire : des suppressions en cascade peuvent effacer bien plus que prévu.
L'analytics et le reporting deviennent aussi compliqués. Quand de vieux enregistrements disparaissent, les métriques changent rétrospectivement. Le taux de conversion du mois dernier se décale, la valeur à vie baisse et les courbes de tendance présentent des trous que personne ne peut expliquer. L'équipe commence à se disputer sur les chiffres au lieu de prendre des décisions.
Support et conformité sont là où ça fait le plus mal. Les clients demandent « Pourquoi ai-je été facturé ? » ou « Qui a changé mon offre ? » Si l'enregistrement a disparu, vous ne pouvez pas reconstruire une chronologie. Vous perdez la piste d'audit qui répondrait à des questions basiques comme quoi a changé, quand et par qui.
Modes d'échec courants derrière le débat suppression logique vs suppression définitive :
- Perte permanente due à des suppressions accidentelles ou à des automatisations boguées
- Enregistrements parents manquants qui laissent des enfants (commandes, tickets) orphelins
- Rapports qui changent parce que des lignes historiques disparaissent
- Cas de support impossibles à résoudre sans historique
Quand la suppression logique est le meilleur choix par défaut
La suppression logique est généralement le choix le plus sûr lorsqu'un enregistrement a une valeur à long terme ou est connecté à d'autres données. Plutôt que de retirer une ligne, vous la marquez comme supprimée (par exemple deleted_at ou is_deleted) et la cachez des vues normales. Dans une décision suppression logique vs suppression définitive, ce défaut tend à réduire les surprises plus tard.
Elle est idéale partout où vous avez besoin d'une piste d'audit dans les bases de données. Les équipes opérations doivent souvent répondre à des questions simples comme « Qui a modifié cette commande ? » ou « Pourquoi cette facture a-t-elle été annulée ? » Si vous supprimez définitivement trop tôt, vous perdez des preuves utiles pour la finance, le support et les rapports de conformité.
La suppression logique rend aussi l'« annulation » possible. Les admins peuvent restaurer un ticket fermé par erreur, réactiver un produit archivé ou récupérer du contenu créé par des utilisateurs après un signalement erroné de spam. Ce type de restauration est difficile à offrir si les données ont été physiquement supprimées.
Les relations sont une autre grande raison. Supprimer définitivement une ligne parente peut casser des contraintes de clé étrangère ou laisser des écarts déroutants dans les rapports. Avec la suppression logique, les jointures restent stables et les totaux historiques demeurent cohérents (revenu quotidien, commandes honorées, statistiques de temps de réponse).
La suppression logique est un bon défaut pour les enregistrements métier comme tickets de support, messages, commandes, factures, logs d'audit, historique d'activité et profils utilisateur (du moins jusqu'à confirmation de suppression définitive).
Exemple : un agent de support « supprime » une note de commande contenant une erreur. Avec la suppression logique, la note disparaît de l'interface normale, mais les supérieurs peuvent la consulter lors d'une plainte, et les rapports financiers restent explicables.
Quand la suppression définitive est requise
La suppression logique est un excellent défaut pour de nombreuses applis, mais il y a des moments où conserver les données (même cachées) est la mauvaise option. La suppression définitive signifie que l'enregistrement est réellement supprimé, et c'est parfois la seule option conforme aux exigences légales, de sécurité ou de coûts.
Le cas le plus clair est celui des obligations de confidentialité et contractuelles. Si une personne invoque le droit à l'effacement (RGPD), ou si votre contrat promet une suppression après une période donnée, « marqué comme supprimé » ne suffit souvent pas. Vous devrez peut-être supprimer la ligne, les copies liées et tout identifiant stocké qui permettrait de la rattacher à la personne.
La sécurité est une autre raison. Certaines données sont trop sensibles pour être conservées : tokens d'accès bruts, codes de réinitialisation de mot de passe, clés privées, codes de vérification à usage unique ou secrets non chiffrés. Les garder pour l'historique vaut rarement le risque.
La suppression définitive peut aussi être le bon choix pour la scalabilité. Si vous avez d'énormes tables d'événements anciens, de logs ou de télémétrie, la suppression logique fait grossir silencieusement la base et ralentit les requêtes. Une politique de purge planifiée maintient le système réactif et les coûts prévisibles.
La suppression définitive convient souvent aux données temporaires (caches, sessions, imports brouillons), artefacts de sécurité éphémères (tokens de réinitialisation, OTP, codes d'invitation), comptes de test/démo et grands ensembles historiques où seules des statistiques agrégées sont nécessaires.
Une approche pratique est de séparer « l'historique métier » des « données personnelles ». Par exemple, conservez les factures pour la comptabilité, mais supprimez définitivement (ou anonymisez) les champs du profil utilisateur qui identifient une personne.
Si votre équipe débat suppression logique vs suppression définitive, appliquez un test simple : si conserver les données crée un risque légal ou de sécurité, la suppression définitive (ou l'anonymisation irréversible) doit l'emporter.
Faites une simulation de suppression
Testez votre scénario “supprimer un utilisateur” de bout en bout avec des écrans et des API réels.
Une suppression logique fonctionne mieux lorsqu'elle est banale et prévisible. L'objectif est simple : l'enregistrement reste dans la base, mais les parties normales de l'appli agissent comme s'il avait disparu.
Choisissez un signal de suppression unique, et définissez clairement sa signification
Vous verrez trois schémas courants : un timestamp deleted_at, un drapeau is_deleted, ou un enum de statut. Beaucoup d'équipes préfèrent deleted_at car il répond à deux questions à la fois : est-ce supprimé, et quand cela s'est-il produit.
Si vous avez déjà plusieurs états de cycle de vie (active, pending, suspended), un enum de statut peut fonctionner, mais gardez « supprimé » séparé de « archivé » et « désactivé ». Ce sont différents :
- Supprimé : ne doit pas apparaître dans les listes normales ni être utilisable.
- Archivé : conservé pour l'historique, mais toujours visible dans les vues « passées ».
- Désactivé : désactivé temporairement, souvent réversible par l'utilisateur.
Gérez les champs uniques avant qu'ils ne vous posent problème
Le débat suppression logique vs suppression définitive se casse souvent sur les champs uniques comme email, username ou numéro de commande. Si un utilisateur est « supprimé » mais que son email est toujours stocké et unique, la même personne ne pourra pas se réinscrire.
Deux solutions courantes : appliquer l'unicité seulement aux lignes non supprimées, ou réécrire la valeur lors de la suppression (par exemple en ajoutant un suffixe aléatoire). Le choix dépend de la confidentialité et des besoins d'audit.
Rendre les règles de filtrage explicites (et cohérentes)
Décidez ce que différents publics peuvent voir. Une règle commune : les utilisateurs réguliers ne voient jamais les enregistrements supprimés, les équipes support/admin peuvent les voir avec une étiquette claire, et les exports/rapports les incluent seulement lorsqu'on le demande.
Ne comptez pas sur « tout le monde se souvient d'ajouter le filtre ». Placez la règle en un seul endroit : vues, requêtes par défaut ou couche d'accès aux données. Si vous construisez dans AppMaster, cela signifie généralement intégrer le filtre dans la façon dont vos endpoints et Business Processes récupèrent les données, pour que les lignes supprimées ne réapparaissent pas accidentellement.
Notez la signification dans une courte note interne (ou en commentaires de schéma). Votre futur vous remerciera quand « supprimé », « archivé » et « désactivé » se retrouveront dans la même réunion.
Préserver les références : parents, enfants et jointures
Les suppressions cassent les applis le plus souvent via les relations. Un enregistrement est rarement seul : les utilisateurs ont des commandes, les tickets ont des commentaires, les projets ont des fichiers. La difficulté dans suppression logique vs suppression définitive est de garder les références cohérentes tout en donnant l'impression produit que l'élément est « disparu ».
Clés étrangères : choisissez volontairement le mode d'échec
Les clés étrangères vous protègent des références cassées, mais chaque option a un sens différent :
- RESTRICT bloque la suppression si des enfants existent.
- SET NULL permet la suppression mais détache les enfants.
- CASCADE supprime automatiquement les enfants.
- NO ACTION est semblable à RESTRICT dans beaucoup de bases, mais le timing peut différer.
Si vous utilisez la suppression logique, RESTRICT est souvent le défaut le plus sûr. Vous conservez la ligne, donc les clés restent valides, et vous évitez que des enfants pointent vers rien.
Suppression logique dans les relations : masquer sans orpheliner
La suppression logique signifie généralement que vous ne changez pas les clés étrangères. Au lieu de cela, vous filtrez les parents supprimés dans l'appli et dans les rapports. Si un client est soft-delete, ses factures devraient toujours se joindre correctement, mais les écrans ne doivent pas montrer le client dans les menus déroulants.
Pour les pièces jointes, commentaires et logs d'activité, décidez ce que « supprimer » signifie pour l'utilisateur. Certaines équipes conservent la coquille mais retirent les parties à risque : remplacer le contenu d'une pièce jointe par un placeholder si la confidentialité l'exige, marquer les commentaires comme provenant d'un utilisateur supprimé (ou anonymiser l'auteur), et garder les logs d'activité immuables.
Les jointures et le reporting nécessitent une règle claire : les lignes supprimées doivent-elles être incluses ? Beaucoup d'équipes conservent deux requêtes standard : une « actives seulement » et une « incluant les supprimés », pour que le support et le reporting ne masquent pas par erreur un historique important.
Étape par étape : concevoir un cycle de vie des données qui utilise les deux
Ajoutez une corbeille et une vue de restauration
Créez des vues admin pour restaurer et examiner, sans exposer les données supprimées aux utilisateurs.
Une politique pratique utilise souvent la suppression logique pour les erreurs quotidiennes et la suppression définitive pour les besoins légaux ou de confidentialité. Si vous traitez cela comme une décision unique (suppression logique vs suppression définitive), vous manquez le terrain du milieu : garder l'historique un temps, puis purger ce qui doit l'être.
Un plan simple en 5 points
Commencez par trier les données en quelques bacs. Les « données de profil utilisateur » sont personnelles, les « transactions » sont des enregistrements financiers, et les « logs » sont de l'historique système. Chaque groupe a des règles différentes.
Un plan court qui fonctionne pour la plupart des équipes :
- Définir les groupes de données et leurs propriétaires, et nommer qui approuve les suppressions.
- Définir les règles de rétention et de restauration.
- Décider ce qui est anonymisé plutôt que supprimé.
- Ajouter une étape de purge programmée (suppression logique d'abord, suppression définitive ensuite).
- Enregistrer un événement d'audit pour chaque suppression, restauration et purge (qui, quand, quoi et pourquoi).
Rendre cela concret avec un scénario
Supposons qu'un client demande la fermeture de son compte. Supprimez logiquement l'enregistrement utilisateur immédiatement afin qu'il ne puisse plus se connecter et que vous ne cassiez pas les références. Puis anonymisez les champs personnels qui ne doivent pas rester (nom, email, téléphone), tout en conservant les faits transactionnels non personnels nécessaires à la comptabilité. Enfin, un job de purge planifié supprime ce qui reste personnel après la période d'attente.
Erreurs courantes et pièges à éviter
Préservez l'intégrité des références
Évitez les enregistrements orphelins en concevant les relations et le comportement de suppression ensemble.
Les équipes se mettent en difficulté non pas parce qu'elles ont choisi la mauvaise approche, mais parce qu'elles l'appliquent de façon inégale. Un schéma courant est « suppression logique vs suppression définitive » sur le papier, mais « masquer dans un écran et oublier le reste » en pratique.
Une erreur fréquente : vous cachez les enregistrements supprimés dans l'UI, mais ils apparaissent toujours via l'API, les exports CSV, les outils admin ou les jobs de synchronisation. Les utilisateurs remarquent vite quand un client “supprimé” réapparaît dans une liste d'emailing ou une recherche mobile.
Les rapports et la recherche sont un autre piège. Si les requêtes de rapport n'appliquent pas systématiquement le filtre sur les lignes supprimées, les totaux dérivent et les tableaux de bord perdent leur confiance. Les pires cas sont des jobs en arrière-plan qui réindexent ou renvoient des éléments supprimés parce qu'ils n'ont pas appliqué les mêmes règles.
Les suppressions définitives peuvent aussi être excessives. Une seule suppression en cascade peut effacer commandes, factures, messages et logs dont vous aviez besoin pour un audit. Si vous devez supprimer définitivement, soyez explicite sur ce qui peut disparaître et ce qui doit être conservé ou anonymisé.
Les contraintes d'unicité causent des douleurs subtiles avec la suppression logique. Si un utilisateur supprime son compte puis tente de se réinscrire avec le même email, l'inscription peut échouer si l'ancienne ligne conserve l'email unique. Prévoyez cela tôt.
Les équipes conformité demanderont : pouvez-vous prouver qu'une suppression a eu lieu, et quand ? « Nous pensons que c'était supprimé » ne passera pas beaucoup de revues de politique de conservation. Conservez un timestamp de suppression, qui/quoi l'a déclenchée et une entrée de log immuable.
Avant de déployer, vérifiez toute la surface : API, exports, recherche, rapports et jobs en arrière-plan. Passez aussi en revue les cascades table par table, et confirmez que les utilisateurs peuvent recréer des données « uniques » comme email ou nom d'utilisateur quand cela fait partie de la promesse produit.
Liste de vérification rapide avant le déploiement
Avant de choisir suppression logique vs suppression définitive, vérifiez le comportement réel de votre appli, pas seulement le schéma.
- La restauration est sûre et prédictible. Si un admin « restaure » un élément, revient-il dans l'état correct sans réactiver des éléments devant rester effacés (tokens révoqués) ?
- Les requêtes masquent les données supprimées par défaut. Nouveaux écrans, exports et API ne devraient pas inclure par erreur des lignes supprimées. Décidez d'une règle et appliquez-la partout.
- Les références ne se cassent pas. Assurez-vous que les clés étrangères et les jointures ne peuvent pas produire d'enregistrements orphelins ou d'écrans partiellement vides.
- La purge a un calendrier et un responsable. La suppression logique n'est que la moitié du plan. Définissez quand les données sont supprimées définitivement, qui exécute la purge et ce qui est exclu (par exemple les litiges actifs).
- La suppression est journalisée comme toute action sensible. Enregistrez qui l'a initiée, quand et pourquoi.
Testez ensuite le chemin de confidentialité de bout en bout. Pouvez-vous satisfaire une demande d'effacement RGPD sur toutes les copies, exports, index de recherche, tables analytiques et intégrations, pas seulement la base principale ?
Une manière pratique de valider cela est de faire une simulation « supprimer utilisateur » en staging et de suivre la piste des données.
Exemple : supprimer un utilisateur tout en conservant l'historique de facturation
Supprimez définitivement les artefacts sensibles
Supprimez correctement tokens, sessions et secrets sans toucher aux enregistrements métier.
Un client écrit : « Veuillez supprimer mon compte. » Vous avez aussi des factures qui doivent rester pour la comptabilité et la gestion des contestations. C'est là que suppression logique vs suppression définitive devient concret : vous pouvez retirer l'accès et les détails personnels tout en conservant les enregistrements financiers que l'entreprise doit garder.
Séparez « le compte » de « l'enregistrement de facturation ». Le compte concerne la connexion et l'identité. La facture concerne une transaction déjà réalisée.
Une approche claire :
- Supprimez logiquement le compte utilisateur pour qu'il ne puisse plus se connecter et que son profil disparaisse des vues normales.
- Conservez les factures et paiements comme enregistrements actifs, mais ne les rattachez plus à des champs personnels.
- Anonymisez les données personnelles (nom, email, téléphone, adresse) en les remplaçant par des valeurs neutres comme « Utilisateur supprimé » plus une référence interne non identifiante.
- Supprimez définitivement les éléments sensibles d'accès comme tokens API, hashes de mot de passe, sessions, refresh tokens et appareils mémorisés.
- Ne conservez que ce qui est vraiment nécessaire pour la conformité et le support, et documentez pourquoi.
Les tickets de support et messages se situent souvent au milieu. Si le contenu du message contient des données personnelles, vous devrez peut-être raturer des parties du texte, supprimer des pièces jointes et garder la coquille du ticket (horodatages, catégorie, résolution) pour le suivi qualité. Si votre produit envoie des messages (email/SMS, Telegram), retirez aussi les identifiants sortants pour que la personne ne soit plus contactée.
Ce que le support peut encore voir : généralement les numéros de facture, dates, montants, statut et une note indiquant que l'utilisateur a été supprimé et quand. Ce qu'il ne peut pas voir : tout ce qui identifie la personne : email de connexion, nom complet, adresses, détails de paiement enregistrés ou sessions actives.
Prochaines étapes : écrivez des règles, puis implémentez-les de façon cohérente
Les décisions de suppression tiennent seulement quand elles sont écrites et appliquées de la même manière à travers le produit. Traitez suppression logique vs suppression définitive comme une question de politique d'abord, pas comme une astuce de code.
Commencez par une politique de conservation des données simple que n'importe qui de l'équipe peut lire. Elle doit dire ce que vous conservez, combien de temps et pourquoi. Le « pourquoi » compte car il indique ce qui doit primer quand deux objectifs se heurtent (par exemple historique support vs demandes de confidentialité).
Un bon défaut est souvent : suppression logique pour les enregistrements métier quotidiens (commandes, tickets, projets), suppression définitive pour les données vraiment sensibles (tokens, secrets) et tout ce que vous ne devriez pas conserver.
Une fois la politique définie, construisez les flux qui l'appliquent : une vue « corbeille » pour la restauration, une « file de purge » pour la suppression irréversible après contrôles, et une vue d'audit montrant qui a fait quoi et quand. Rendez la « purge » plus difficile que la « suppression » pour qu'elle ne soit pas utilisée par accident.
Si vous implémentez cela dans AppMaster (appmaster.io), il est utile de modéliser les champs de soft-delete dans le Data Designer et de centraliser la logique de suppression, restauration et purge dans un Business Process, afin que les mêmes règles s'appliquent à tous les écrans et endpoints API.
FAQ
Une suppression définitive supprime physiquement la ligne de la base de données : les requêtes futures ne la trouveront plus. Une suppression logique conserve la ligne mais la marque comme supprimée (souvent avec deleted_at), de sorte que l'application la masque dans les écrans normaux tout en préservant l'historique pour le support, les audits et les rapports.
Préférez la suppression logique par défaut pour les enregistrements métier que vous pourriez avoir besoin d'expliquer plus tard : commandes, factures, tickets, messages et activité de compte. Elle réduit les pertes accidentelles, maintient les relations et permet un “undo” sans restaurer depuis des sauvegardes.
La suppression définitive est appropriée lorsque conserver les données crée un risque de confidentialité ou de sécurité, ou lorsque les règles de conservation exigent une suppression réelle. Exemples courants : tokens de réinitialisation, codes à usage unique, sessions, tokens API et données personnelles devant être effacées après une demande vérifiée ou à l'issue d'une période de rétention.
Un champ deleted_at est souvent préféré car il indique à la fois que l'enregistrement est supprimé et quand cela s'est produit. Il facilite aussi des workflows pratiques comme une fenêtre de rétention (purge après 30 jours) et répond aux questions d'audit (« quand cela a-t-il été supprimé ? ») sans avoir besoin d'un log séparé pour le timing.
Les champs uniques comme email ou nom d'utilisateur empêchent souvent la réinscription si la ligne « supprimée » contient encore la valeur unique. Deux solutions courantes : n'appliquer l'unicité qu'aux lignes non supprimées, ou réécrire la valeur lors de la suppression (par exemple en ajoutant un suffixe aléatoire). Le choix dépend des besoins de confidentialité et d'audit.
Supprimer définitivement un parent peut orpheliner les enfants (comme les commandes) ou déclencher des suppressions en cascade qui suppriment beaucoup plus que prévu. La suppression logique évite généralement les références cassées car les clés restent valides, mais il faut des filtres cohérents pour que les parents supprimés n'apparaissent pas dans les listes déroulantes ou les jointures visibles par les utilisateurs.
Si vous supprimez définitivement des lignes historiques, les totaux passés peuvent changer, des tendances peuvent présenter des trous et les chiffres financiers peuvent ne plus correspondre à ce que l'on avait vu auparavant. La suppression logique préserve l'historique, à condition que les requêtes de reporting définissent clairement si elles incluent ou non les lignes supprimées et appliquent cette règle systématiquement.
La “suppression logique” n'est souvent pas suffisante pour un droit à l'effacement RGPD, car les données personnelles peuvent encore exister dans la base ou les sauvegardes. Un schéma pratique : retirer l'accès immédiatement, puis supprimer définitivement ou anonymiser irréversiblement les identifiants personnels tout en conservant les faits transactionnels non personnels nécessaires à la comptabilité ou aux litiges.
La restauration doit ramener l'enregistrement à un état sûr et valide sans réactiver des éléments sensibles qui doivent rester supprimés, comme des sessions ou des tokens de réinitialisation. Il faut aussi des règles claires pour les données liées afin de ne pas restaurer un compte sans ses relations requises ou ses permissions.
Centralisez le comportement de suppression, de restauration et de purge pour que chaque API, écran, export et job applique le même filtre. Dans AppMaster (appmaster.io), cela passe généralement par l'ajout des champs de soft-delete dans le Data Designer et l'implémentation de la logique une seule fois dans un Business Process, afin que les nouveaux endpoints n'exposent pas par erreur des données supprimées.